用java找出这几个list,所有可能的组合,并且组合结果的list中的数据不允许重复
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用java找出这几个list,所有可能的组合,并且组合结果的list中的数据不允许重复相关的知识,希望对你有一定的参考价值。
public static void main (String args[]) List<Integer> a = new ArrayList<>(); a.add(1); a.add(2); a.add(3); List<Integer> b = new ArrayList<>(); b.add(2); b.add(3); b.add(4); b.add(5); List<Integer> c = new ArrayList<>(); c.add(5); c.add(6); List<Integer> d = new ArrayList<>(); d.add(5); List<Integer> e = new ArrayList<>(); e.add(7); /** 用java找出这几个list,所有可能的组合,并且组合的list中数据不允许重复 组合结果例: a c e a d e b e */

import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.TreeSet;
public class MyCode
static TreeSet<String> ts = new TreeSet<>();
static StringBuffer stb = new StringBuffer();
public static void main(String args[])
List<Integer> a = new ArrayList<>();
a.add(1);
a.add(2);
a.add(3);
List<Integer> b = new ArrayList<>();
b.add(2);
b.add(3);
b.add(4);
b.add(5);
List<Integer> c = new ArrayList<>();
c.add(5);
c.add(6);
List<Integer> d = new ArrayList<>();
d.add(5);
List<Integer> e = new ArrayList<>();
e.add(7);
String arr[];
List<String> names = (Arrays.asList("a,b,c,d,e".split(",")));
ArrayList<List<Integer>> list = new ArrayList<>();
list.add(a);
list.add(b);
list.add(c);
list.add(d);
list.add(e);
for (int i = 0; i < list.size(); i++)
List<Integer> temA = new ArrayList<>(list.get(i));
for (int j = i + 1; j < list.size(); j++)
List<Integer> temB = new ArrayList<>(list.get(j));
temA.retainAll(temB);
if (temA.size() <= 0)
List<Integer> temC = new ArrayList<>(list.get(i));
List<Integer> temD = new ArrayList<>(list.get(j));
temC.addAll(temD);
stb.append(names.get(i) + "," + names.get(j) + ",");
getNameIndex(temC, list, i, j, names);
arr = stb.toString().split(",");
Arrays.sort(arr);
ts.add(Arrays.toString(arr));
stb.delete(0, stb.length());
for (Iterator<String> it = ts.iterator(); it.hasNext();)
System.out.println(it.next());
private static void getNameIndex(List<Integer> listTem, List<List<Integer>> listB, int x, int y,
List<String> names)
for (int i = 0; i < listB.size(); i++)
if (i == x || i == y)
continue;
List<Integer> listN = new ArrayList<>(listTem);
List<Integer> listM = new ArrayList<>(listB.get(i));
listN.retainAll(listM);
if (listN.size() <= 0)
stb.append(names.get(i));
break;
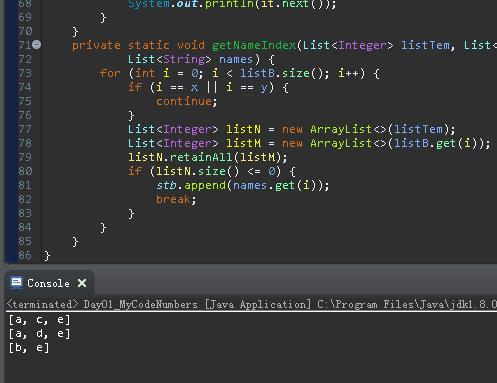
你这个,麻雀虽小,五脏俱全呢,看似一个简单的小玩意,挺费劲的!
主要用的是交集,并集,难点就是因为嵌套,有点饶头..你自己琢磨一下吧!
参考技术A 使用递归方法实现/**
* 排列组合
* eg:a b c的排列有abc,acb,bac,bca,cab,cba
* 方法:递归,第一层循环把n个数中的第i个装入结果的第一个位置
* 接着将剩下的n-1个数循环装入第二个位置
* 把剩下的n-2个数循环装入第三个位置...
*
* @param args
*/
public static void main(String[] args)
//初始数据
ArrayList<String> arrayList = new ArrayList<String>();
arrayList.add("a");
arrayList.add("b");
arrayList.add("c");
arrayList.add("d");
//追加待组合的数据
StringBuffer data = new StringBuffer();
//保存排列好的数据
ArrayList<String> results = new ArrayList<String>();
rank(arrayList, data, results);
//按合适的格式输出排列结果
int k = 0;
for (String s : results)
k++;
System.out.print(s + "、");
if (k == results.size() / arrayList.size())
k = 0;
System.out.println();
//主要算法
public static void rank(ArrayList<String > arrayList, StringBuffer data, ArrayList<String> results)
if (arrayList.size() == 0)
results.add(data.toString());
for (int i = 0; i < arrayList.size(); i++)
data.append(arrayList.get(i));
//必须创建新的list,否则原来的list会被改变
ArrayList<String> newArrayList = new ArrayList<String>(arrayList);
newArrayList.remove(i);
rank(newArrayList, data, results);
//把记录的data最后一个去掉,否则前面的结果会影响循环过程。
if (data.length() != 0)
data.deleteCharAt(data.length() - 1);
追问
兄弟,这不对,和我的问题不相符,我是要找到多个list的组合,并且组合好的多个list中不存在重复数据,比如我写的图中的那种数据,得到的结果应该是 [list a/list c/list e] ,[list a/list b/list e], [list b/list e]
Java开发之高并发编程篇——安全访问的集合
在开发中我们使用比较多的集合就是List、Set和Map了,并且我们也知道大部分用的基本上都是ArrayList、LinkedList、HashMap、HashSet或者TreeSet这几个集合。但是我们在学习使用它们的时候都知道它们这几个在并发处理的时候并不会保证多线程的安全访问,也就是说多线程环境下使用这几个集合不能用于共享数据访问。那有没有一些方法保证这些集合并发安全访问呢?
1.Collections工具类并发的支持
其实java有一个叫做Collections的工具类提供了一些保证List、Set、Map线程安全方法的方法,如下图:

其实通过其名称也不难猜想底层是使用了synchronized关键完成的同步代码块或者同步方法的实现。其任意一个方法的源码如下(以List为例):


2.支持并发安全访问的集合
HashMap原理简介:
我们知道HashMap的底层实现原理是分JDK1.7及其以前版本和JDK1.8版本的,JDK1.7及其以前HashMap是使用“数组+链表”组成的“散列桶”的实现,这个“桶”即为“数组”,默认容量为16,在每一个“桶”中存储了一个链表,但是链表一旦太长就会导致查找速度很慢(链表查找需要遍历),所以在JDK1.8的时候HashMap存储结构改为了当链表长度达到8之后(通过判断TREEIFY_THRESHOLD的值)将链表改为红黑二叉树的存储,这样对于数据操作的效率就大大提高了。JDK8之后的HashMap如图:

部分源码如下:


HashMap对其数据操作并没有做线程安全的处理,HashMap在其插入数据的时候都要进行容量检查看有没有超过设定的thredhold,如果超过,则需要扩容,但是这样一来,就需要对整个HashMap里的节点进行重哈希操作,那么如果现在多个线程访问HashMap数据那可能导致一个线程操作了之后HashMap进行哈希重新计算操作,另外一个线程读取到的就不准确,所以操作过程中并不是线程安全的。
ConcurrentHashMap原理简介:
ConcurrentHashMap是J.U.C(java.util.concurrent包)的重要成员,它是一个线程安全确效率相对高效一些的类似HashMap的实现类。
ConcurrentHashMap 的实现同样也分为JDK7和JDK8版本。
JDK7及其之前底层采用是“数组+链表+Segment分段锁”的实现。其中Segment继承了ReentrantLock,这样ConcurrentHashMap 每个数组中的元素既是一个链表,又是一个Segment锁,使用Segment将访问的数据分成了一段一段的进行存储,因为每一个Segment都是一个锁所以相当于每一段数据也加了锁,这样就可以每一段锁支持一个线程访问,即保证了线程安全又降低了锁的粒度,大大提高了并发操作的效率。

JDK8之后ConcurrentHashMap也同样参考了HashMap的设计,采用了“数组+链表+红黑树”的实现方式,但是却舍弃了“Segment分段锁”的设计(虽然JDK8的源码中还能够看到Segment类但是已经大大简化了代码设计主要为了JDK版本兼容设计)。在JDK8的版本它存储的链表或者红黑树都使用了volatile关键字修饰,但是又因为volatile只是能保证线程的可见性和有序性不能够保证原子性操作,所以在进行put等操作的时候还使用了synchronized代码块处理。部分核心源码如下图所示:

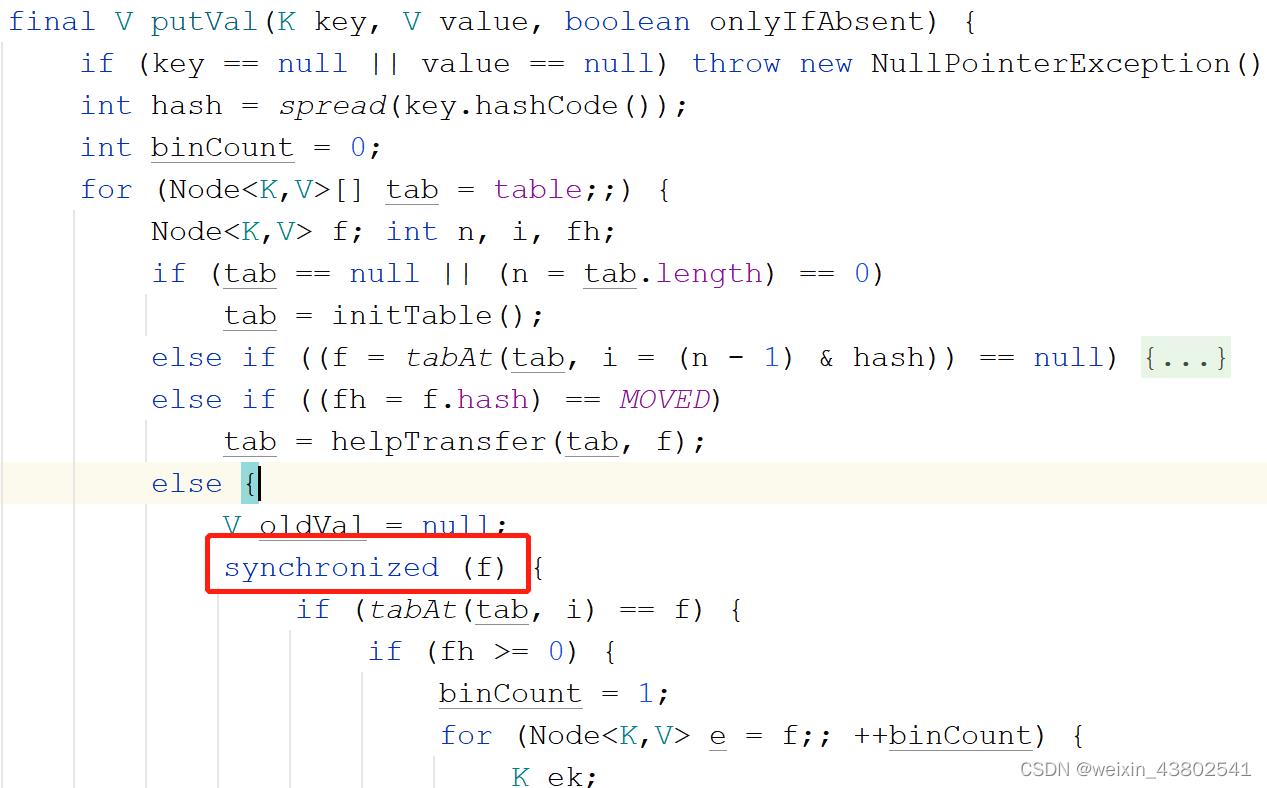

它采用了synchronized和CAS(往期文章中有介绍CAS操作)来替代JDK7的Segment分段锁的实现,JDK8中采用Synchronized关键字也是因为它在JDK6之后做了自旋、锁粗化、锁消除、锁升级等优化,另外对比于JDK7的Segment分段锁的是多个HashEntry,而JDK8锁的是单个的HashEntry粒度更小,效率更高。并且考虑到JDK可能对JVM底层synchronized关键字还会进行不断的优化所以JDK采用了synchronized的设计。
总的来说ConcurrentHashMap是我们在并发访问下的不错的HashMap的替换者。
(未完待续)
以上是关于用java找出这几个list,所有可能的组合,并且组合结果的list中的数据不允许重复的主要内容,如果未能解决你的问题,请参考以下文章