softmax函数与交叉熵函数详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了softmax函数与交叉熵函数详解相关的知识,希望对你有一定的参考价值。
参考技术A 一、二分类以上的任务与二分类任务在网络结构上的区别:在逻辑回归模型中,模型最终输出的是样本属于正例的概率p,用1-p表示反例的概率,该模型在输出端具有单个输出结点。那么,对于多分类任务,输出端可以有多个结点,每个结点代表属于某一类的概率,满足约束条件:所有结点的概率和为1。这个约束条件将输出结点的输出值变成一个概率分布。【概率分布用于表述随机变量取值的概率规律,随机事件的所有可能值(随机变量)+对应的概率值,称为该事件的概率分布】
二、 softmax函数的使用
由一可知,多结点完成多分类任务需要满足的约束条件是:每个结点输出值范围是[0,1] & 所有结点输出值的和等于1。
能够满足这个约束要求的函数就是softmax函数。softmax常作为最后一层的激活函数使用。
softmax包含两部分:soft和max(求数据的最大值),与soft相对的就是hard,hardmax的作用就是直接计算出数据的最大值(唯一性)。softmax会为每个类别计算出一个概率值
softmax的计算原理:
softmax函数表达式:
对softmax的求导:( 对每个输出结点求偏导)
分两种情况:i=j 与 i≠j ,求偏导推导过程如下:
交叉熵损失函数与softmax之间的关系
在执行多分类任务中,经常是使用softmax激活函数和交叉熵损失函数的搭配方式。因为交叉熵描述了两个概率分布的差异,然而神经网络输出的是向量,所以需要softmax激活函数先将一个向量进行’归一化‘成概率分布的形式,然后再采用交叉熵损失函数对计算最终的loss。
softmax损失函数 重点:假设此时第i个输出节点为正确类别对应的输出节点,则 是正确类别对应输出节点的概率值,对 添加log运算,不影响函数的单调性,我们期望 的值越大越好(小于1),通常情况下使用梯度下降法来迭代求解,因此只需要为 添加一个负号就变成损失函数。现在,希望该损失函数越小越好。所以,softmax的损失函数式子为:
交叉熵损失函数与softmax损失函数的转换关系:
softmax损失函数是只针对正确类别对应的输出节点,将这个节点的softmax值最大化;而交叉熵损失函数是直接衡量真实分布和实际输出的分布之间的距离。
交叉熵式子: , 代表真实样本的标签值。 (2)
在分类任务中,样本的真实标签通常表示为one-hot形式,比如三分类,第三个类别表示为[0,0,1],仅正确类别的位置为1,其他位置都为0,将[0,0,1]代入式子(2),最终结果为 。再对照式子(1),可以愉快的发现,(1)和(2)最终表达形式是一样的,那么,接下来计算损失函数的导数使用大家常见的式子(2),接下来将推导这个最终损失函数L对网络输出变量 的偏导数:
模拟一个三分类使用softmax与交叉熵的结果:
softmax+交叉熵损失函数对参数的更新规则,可以分为两步来记,第一步:每个节点的值减去对应的softmax结果;第二步,将真正类别的输出节点处的值加一。
参考以下文章:
多分类问题的交叉熵 一文详解softmax函数
Softmax函数与交叉熵
一般在神经网络中, softmax可以作为分类任务的输出层。
输出n个类别选取的概率,并且概率和为1。
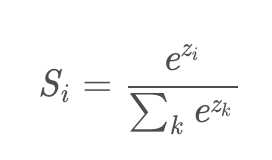
i?代表的是第i个神经元的输出,zi是下面
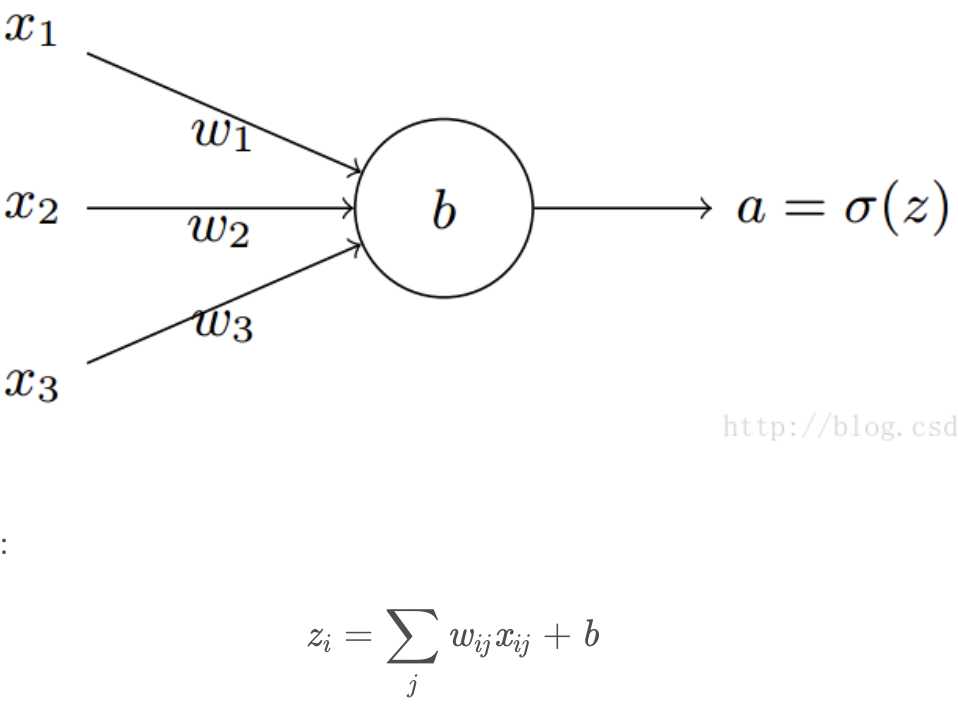
loss function表示的是真实值与网络的估计值的误差。交叉熵的函数是这样的
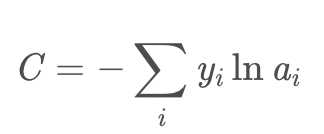
yi?表示真实的分类结果。
求导。首先,我们要明确一下我们要求什么,我们要求的是我们的loss对于神经元输出的梯度。
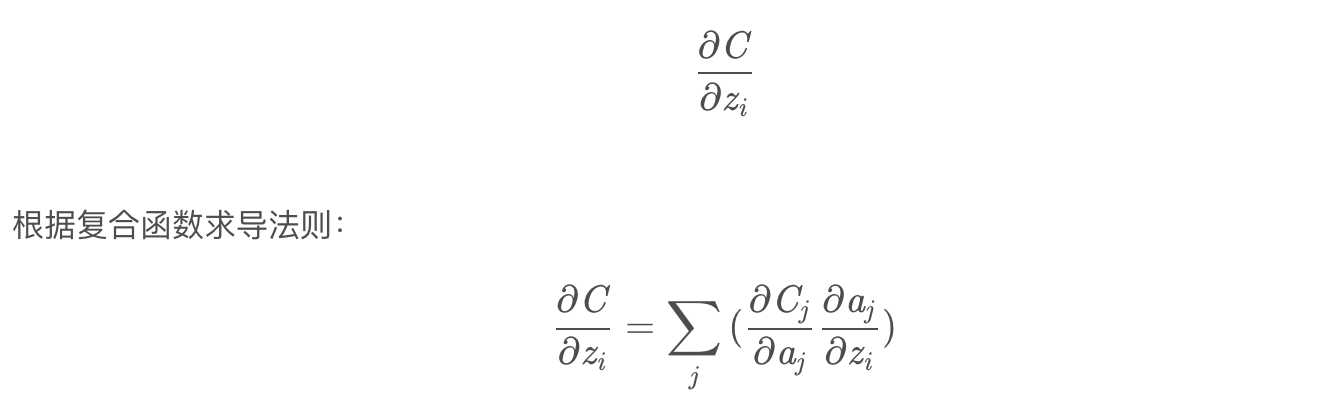
以上是关于softmax函数与交叉熵函数详解的主要内容,如果未能解决你的问题,请参考以下文章