LDA漫游系列(四)-Gibbs Sampling
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LDA漫游系列(四)-Gibbs Sampling相关的知识,希望对你有一定的参考价值。
参考技术A 随机模拟方法有一个很酷的别名是蒙特卡罗方法。这个方法的发展始于20世纪40年代。
统计模拟中有一个很重要的问题就是给定一个概率分布p(x),我们如何在计算机中生成它的样本,一般而言均匀分布的样本是相对容易生成的,通过线性同余发生器可以生成伪随机数,我们用确定性算法生成[0,1]之间的伪随机数序列后,这些序列的各种统计指标和均匀分布Uniform(0,1)的理论计算结果非常接近,这样的伪随机序列就有比较好的统计性质,可以被当成真实的随机数使用。
而我们常见的概率分布,无论是连续的还是离散的分布,都可以基于Uniform(0, 1) 的样本生成,比如正态分布可以通过著名的 Box-Muller变换得到。其他几个著名的连续分布,包括指数分布,Gamma分布,t分布等,都可以通过类似的数学变换得到,不过我们并不是总这么幸运的,当p(x)的形式很复杂,或者p(x)是个高维分布的时候,样本的生成就可能很困难了,此时需要一些更加复杂的随机模拟方法来生成样本,比如MCMC方法和Gibbs采样方法,不过在了解这些方法之前,我们需要首先了解一下马尔可夫链及其平稳分布。
马尔可夫链通俗说就是根据一个转移概率矩阵去转移的随机过程(马尔可夫过程),该随机过程在PageRank算法中也有使用,如下图所示:
通俗解释的话,这里的每个圆环代表一个岛屿,比如i到j的概率是pij,每个节点的出度概率之和=1,现在假设要根据这个图去转移,首先我们要把这个图翻译成如下的矩阵:
上面的矩阵就是状态转移矩阵,我身处的位置用一个向量表示π=(i,k,j,l)假设我第一次的位置位于i岛屿,即π0=(1,0,0,0),第一次转移,我们用π0乘上状态转移矩阵P,也就是π1 = π0 * P = [pii,pij,pik,pil],也就是说,我们有pii的可能性留在原来的岛屿i,有pij的可能性到达岛屿j...第二次转移是,以第一次的位置为基础的到π2 = π1 * P,依次类推下去。
有那么一种情况,我的位置向量在若干次转移后达到了一个稳定的状态,再转移π向量也不变化了,这个状态称之为平稳分布状态π*(stationary distribution),这个情况需要满足一个重要的条件,就是 Detailed Balance 。
那么什么是 Detailed Balance 呢?
假设我们构造如下的转移矩阵:
再假设我们的初始向量为π0=(1,0,0),转移1000次以后达到了平稳状态(0.625,0.3125,0.0625)。
所谓的 Detailed Balance 就是,在平稳状态中:
为什么满足了Detailed Balance条件之后,我们的马尔可夫链就会收敛呢?下面的式子给出了答案:
下一个状态是j的概率,等于从各个状态转移到j的概率之和,在经过Detailed Balance条件变换之后,我们发现下一个状态是j刚好等于当前状态是j的概率,所以马尔可夫链就收敛了。
对于给定的概率分布p(x),我们希望能有便捷的方式生成它对应的样本,由于马尔可夫链能够收敛到平稳分布,于是一个很漂亮的想法是:如果我们能构造一个转移矩阵伪P的马尔可夫链,使得该马尔可夫链的平稳分布恰好是p(x),那么我们从任何一个初始状态x0出发沿着马尔可夫链转移,得到一个转移序列x0,x1,x2,....xn,xn+1,如果马尔可夫链在第n步已经收敛了,于是我们就得到了p(x)的样本xn,xn+1....
好了,有了这样的思想,我们怎么才能构造一个转移矩阵,使得马尔可夫链最终能收敛即平稳分布恰好是我们想要的分布p(x)呢?我们主要使用的还是我们的细致平稳条件(Detailed Balance),再来回顾一下:
假设我们已经又一个转移矩阵为Q的马尔可夫链(q(i,j)表示从状态i转移到状态j的概率),显然通常情况下:
也就是细致平稳条件不成立,所以p(x)不太可能是这个马尔可夫链的平稳分布,我们可否对马尔可夫链做一个改造,使得细致平稳条件成立呢?比如我们引入一个α(i,j),从而使得:
那么问题又来了,取什么样的α(i,j)可以使上等式成立呢?最简单的,按照对称性:
在改造Q的过程中引入的α(i,j)称为接受率,物理意义可以理解为在原来的马尔可夫链上,从状态i以q(i,j)的概率跳转到状态j的时候,我们以α(i,j)的概率接受这个转移,于是得到新的马尔可夫链Q\'的转移概率q(i,j)α(i,j)。
假设我们已经又一个转移矩阵Q,对应的元素为q(i,j),把上面的过程整理一下,我们就得到了如下的用于采样概率分布p(x)的算法:
以上的MCMC算法已经做了很漂亮的工作了,不过它有一个小问题,马尔可夫链Q在转移的过程中接受率α(i,j)可能偏小,这样采样的话容易在原地踏步,拒绝大量的跳转,这是的马尔可夫链便利所有的状态空间要花费太长的时间,收敛到平稳分布p(x)的速度太慢,有没有办法提升一些接受率呢?当然有办法,把α(i,j)和α(j,i)同比例放大,不打破细致平稳条件就好了呀,但是我们又不能无限的放大,我们可以使得上面两个数中最大的一个放大到1,这样我们就提高了采样中的跳转接受率,我们取:
于是经过这么微小的改造,我们就得到了Metropolis-Hastings算法,该算法的步骤如下:
对于高维的情形,由于接受率的存在,Metropolis-Hastings算法的效率不够高,能否找到一个转移矩阵Q使得接受率α=1呢?我们从二维的情形入手,假设有一个概率分布p(x,y),考察x坐标相同的两个点A(x1,y1) ,B(x1,y2),我们发现:
基于以上等式,我们发现,在x=x1这条平行于y轴的直线上,如果使用条件分布p(y|x1)作为任何两个点之间的转移概率,那么任何两个点之间的转移满足细致平稳条件,同样的,在y=y1这条平行于x轴的直线上,如果使用条件分布p(x|y1) 作为,那么任何两个点之间的转移也满足细致平稳条件。于是我们可以构造平面上任意两点之间的转移概率矩阵Q:
有了上面的转移矩阵Q,我们很容易验证对平面上任意两点X,Y,满足细致平稳条件:
由二维的情形我们很容易推广到高维的情形:
所以高维空间中的GIbbs 采样算法如下:
LDA的Gibbs Sampling求解
《LDA数学八卦》对于LDA的Gibbs Sampling求解讲得很详细,在此不在重复在轮子,直接贴上该文这部分内容。
Gibbs Sampling



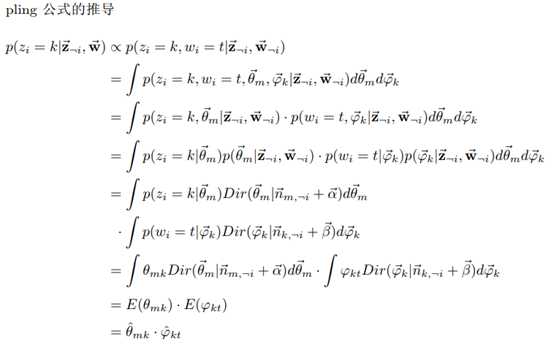
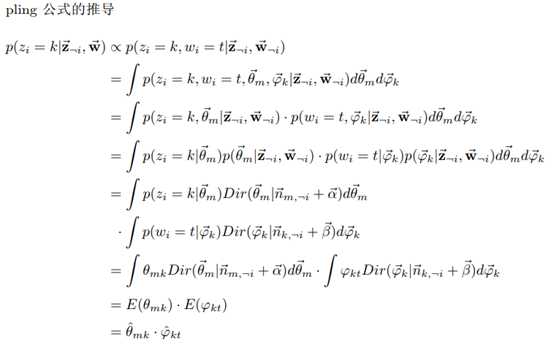
批注:
1、 对于第i个词语,上式k(主题类型)未知,取值范围为[1, K],t(词语类型)已知,即观测值。
2、 由于doc-topic与topic-word独立,所以第i个词语主题为k,类型为t的概率显然是主题k概率在doc m-topic分布上的积分乘以词语t概率在topic k-word分布上的积分。即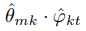 。
。

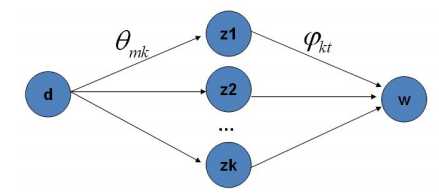
批注:我们已经得到了每个topic-word的边缘分布,通过Gibbs Sampling很容易得到topic-word的完整分布。
Training And Inference



以上是关于LDA漫游系列(四)-Gibbs Sampling的主要内容,如果未能解决你的问题,请参考以下文章