八十二ElasticSearch详解(下)
Posted 象在舞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了八十二ElasticSearch详解(下)相关的知识,希望对你有一定的参考价值。
上一篇文章我们通过搜索原理来看了一下ElasticSearch,本文我们主要从数据结构、Mapping、文档操作入手看一下ElasticSearch是如何使用的。关注专栏《破茧成蝶——大数据篇》,查看更多相关的内容~
目录
4.2 Search API(Request Body Search)
一、ElasticSearch的Mapping
1.1 Mapping的作用
定义数据库中表的结构,通过mapping来控制索引存储数据的设置。
1、定义Index下的字段名(Field Name)。
2、定义字段的类型,比如数值型、字符串型、布尔型等。
3、定义倒排索引相关的配置,比如documentId、记录position、打分等。
1.2 Mapping的使用
1、获取索引Mapping
不进行配置时,自动创建的Mapping。
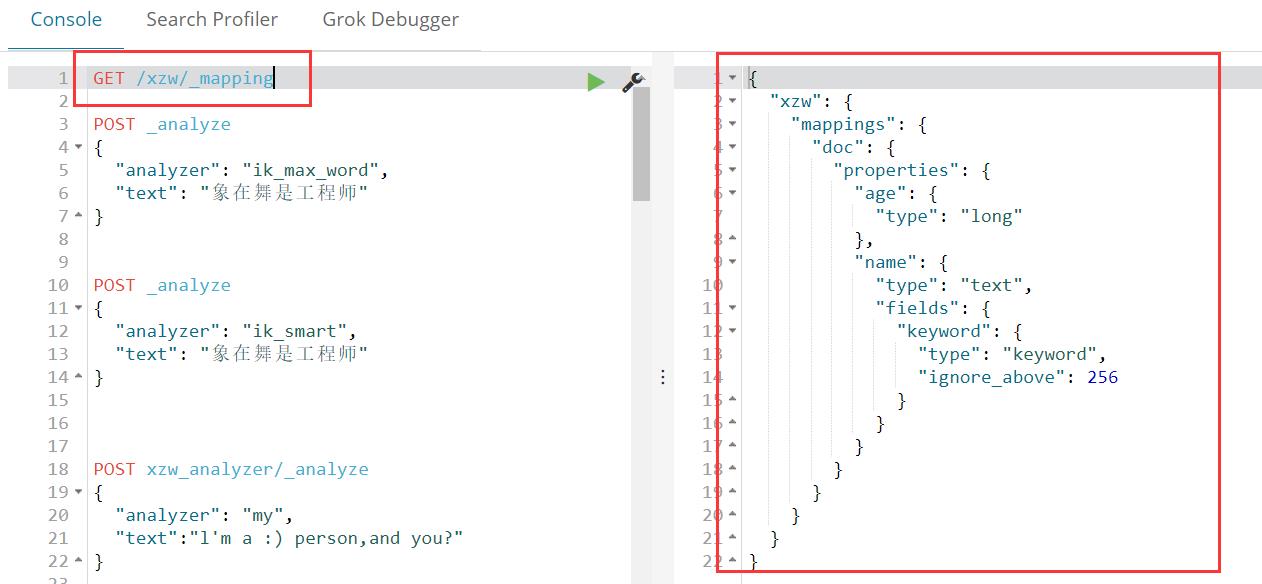
其中,各字段释义如下所示:
"xzw": #索引名称
"mappings": #mapping设置
"doc": #type名称
"properties": #字段属性
"age":
"type": "long" #字段类型,字符串默认类型为text
,
"name":
"type": "text",
"fields": #子字段属性设置
"keyword": #分词类型
"type": "keyword",
"ignore_above": 256
2、自定义mapping
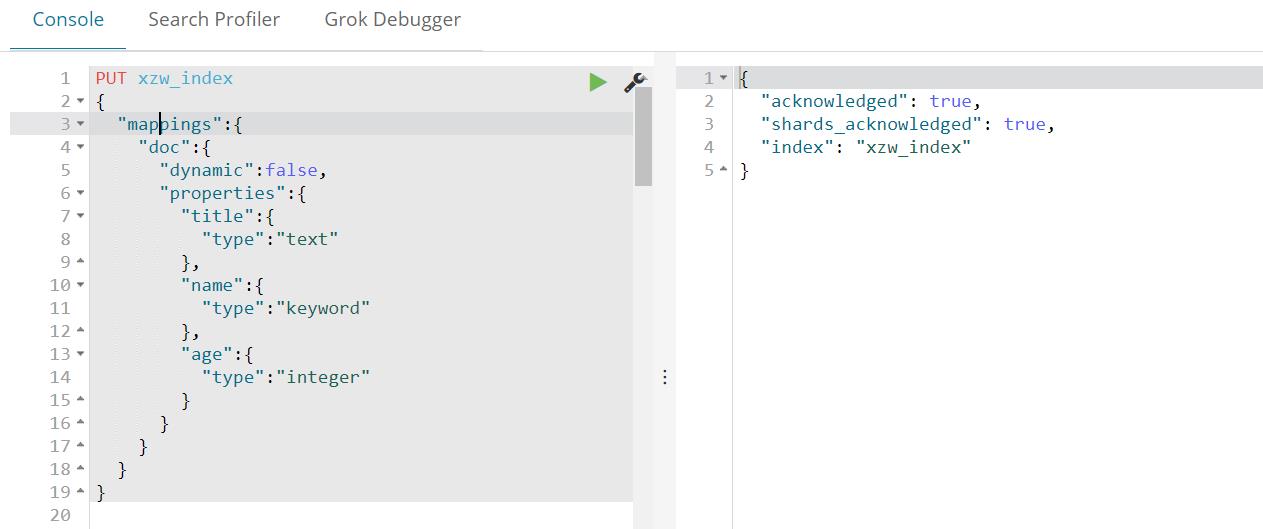
3、Dynamic Mapping
ES依靠json文档字段类型来实现自动识别字段类型,支持的类型如下所示:
| JSON类型 | ES类型 |
|---|---|
| null | 忽略 |
| boolean | boolean |
| 浮点类型 | float |
| 整数 | long |
| object | object |
| array | 由第一个非null值的类型决定 |
| string | 匹配为日期则设为date类型(默认开启);匹配为数字则设为float或long类型(默认关闭)。设为text类型,并附带keyword的子字段。 |
这里需要注意的是:mapping中的字段类型一旦设定后,禁止修改。这是因为:Lucene实现的倒排索引生成后不允许修改,目的是提高效率。如果要修改字段的类型,需要重新建立索引,然后做reindex操作。
dynamic设置如下:
1、true:允许自动新增字段(默认的配置)。
2、False:不允许自动新增字段,但是文档可以正常写入,无法对字段进行查询操作。
3、strict:文档不能写入(如果写入会报错)。
dynamic的设置可以设置在type下也可以设置在字段中。例如:

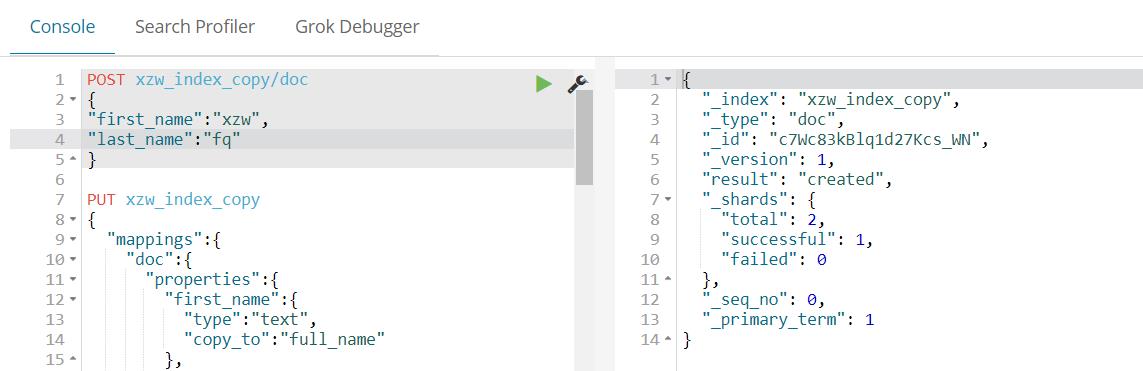
4、copy_to
将该字段的值复制到目标字段,实现_all的作用。不会出现在_source中,只用来搜索。

post数据进行测试:
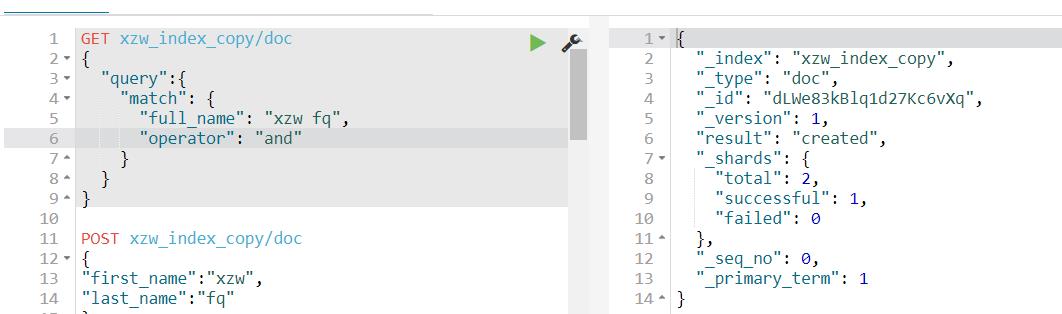
获取数据:
5、Index属性
Index属性,控制当前字段是否索引,默认为true,即记录索引,false不记录,即不可以搜索。例如:
(1)创建mapping
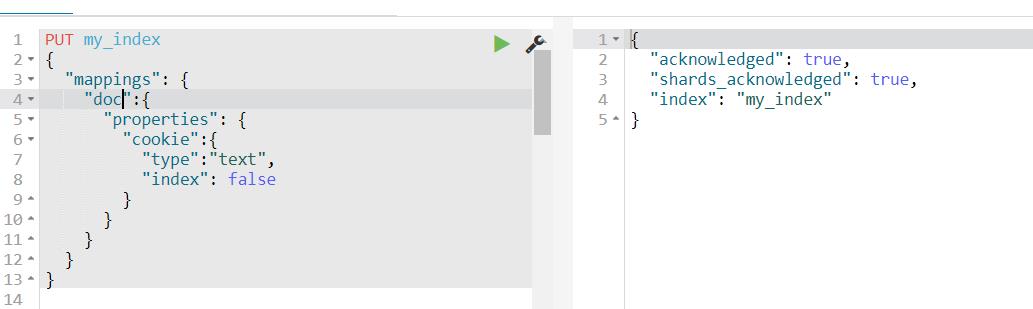
(2)创建文档
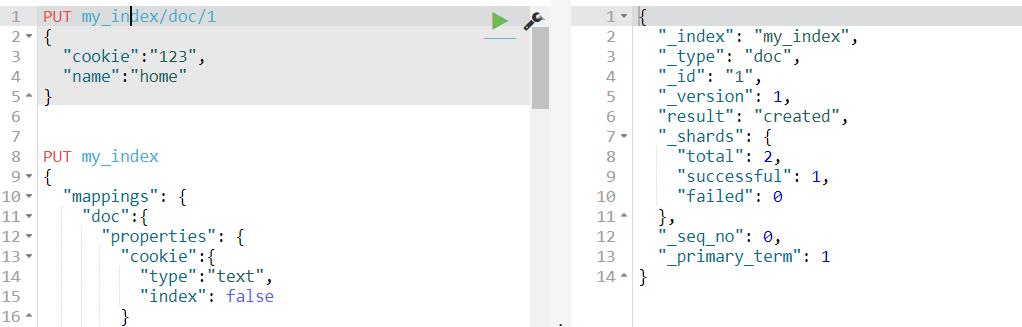
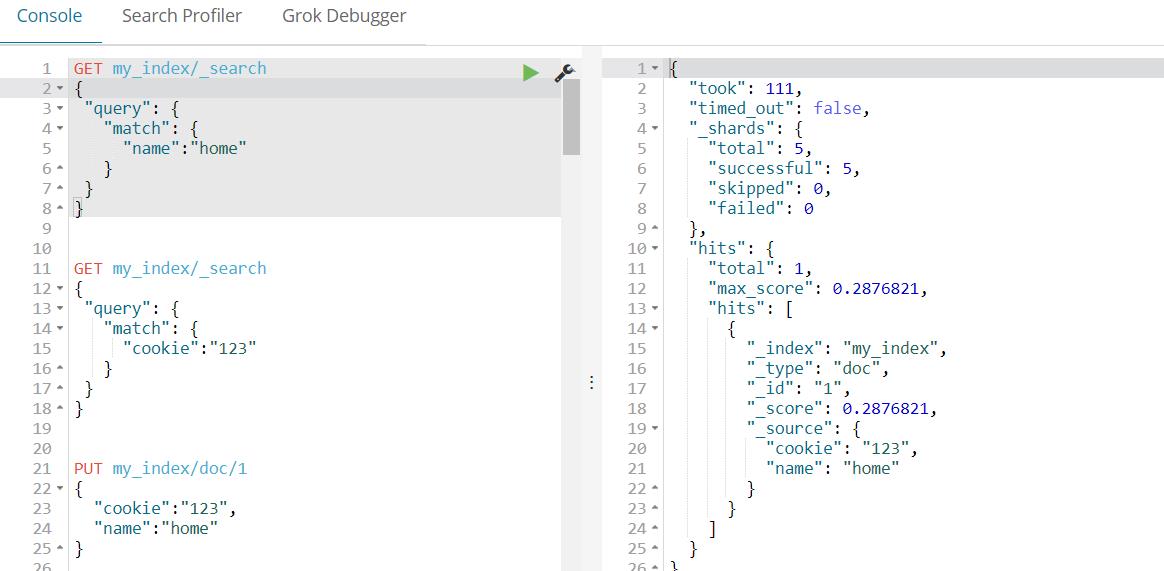
(3)查询

6、Index_options
Index_options用于控制倒排索引记录的内容,有如下4种配置。
1、docs:只记录docid。
2、freqs:记录docid和term frequencies(词频)。
3、position:记录docid、term frequencies、term position。
4、Offsets:记录docid、term frequencies、term position、character offsets。
二、ElasticSearch的数据类型
2.1 核心数据类型
| 字符串型 | text、keyword |
|---|---|
| 数值型 | long、integer、short、byte、double、float、half_float、scaled_float |
| 日期类型 | date |
| 布尔类型 | boolean |
| 二进制类型 | binary |
| 范围类型 | integer_range、float_range、long_range、double_range、date_range |
2.2 复杂数据类型
| 数组类型 | array |
|---|---|
| 对象类型 | object |
| 嵌套类型 | nested object |
2.3 其他
1、地理位置数据类型
geo_point(点)、geo_shape(形状)
2、专用类型
记录IP地址ip
实现自动补全completion
记录分词数:token_count
记录字符串hash值母乳murmur3
3、多字段特性multi-fields
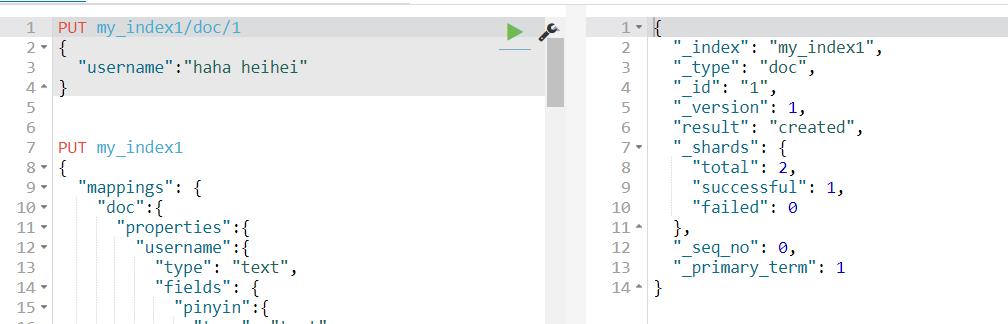
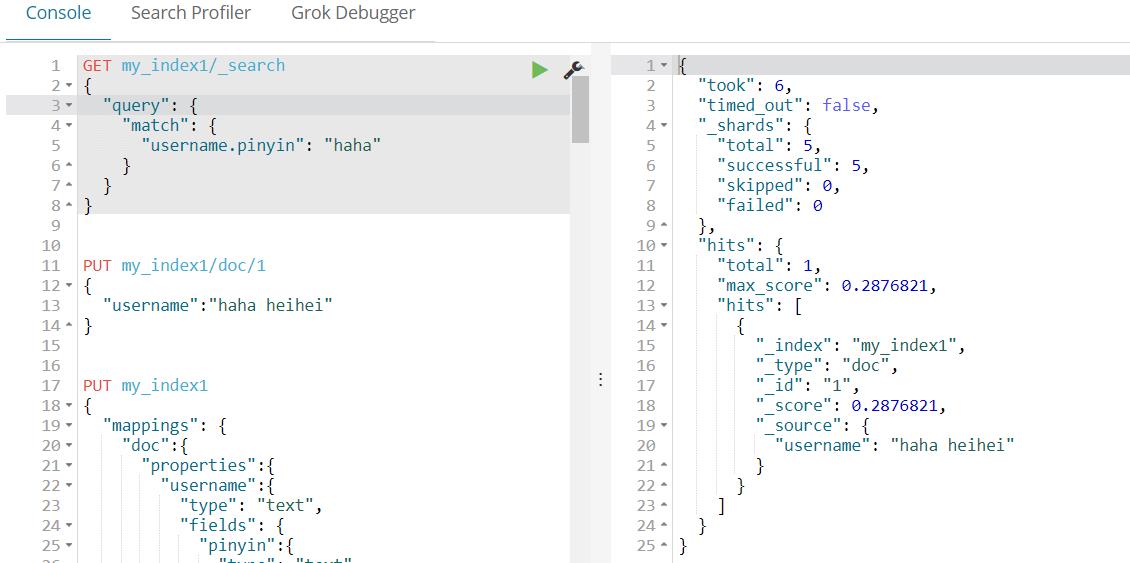
允许对同一个字段采用不同的配置,比如分词,例如对人名实现拼音搜索,只需要在人名中新增一个子字段为pinyin即可。如下所示。
(1)创建mapping
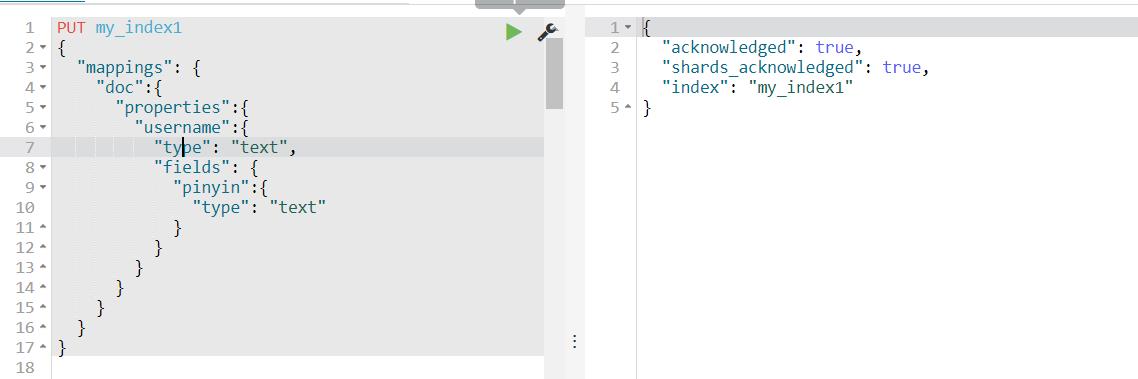
(2)创建文档
(3)查询
三、文档操作
3.1 创建文档
1、索引一个文档
文档通过index API被索引,使数据可以被存储和搜索,但是首先我们需要决定文档所在。正如我们讨论的,文档通过其_index、_type、_id唯一确定。我们可以自己提供一个_id,或者也使用index API为我们生成一个。
PUT index/type/id
“”:””
2、使用自己的ID
如果你的文档有自然的标识符(例如user_account字段或者其他值表示文档),你就可以提供自己的_id,使用这种形式的index API。
PUT /index/type/id
"field": "value",
...
3、自增ID
如果我们的数据没有自然ID,我们可以让ElasticSearch自动为我们生成。
URL现在只包含_index和_type两个字段:
POST /website/blog/
"title": "My second blog entry",
"text": "Still trying this out...",
"date": "2014/01/01"
响应内容与刚才类似,只有_id字段变成了自动生成的值:
"_index": "website",
"_type": "blog",
"_id": "wM0OSFhDQXGZAWDf0-drSA",
"_version": 1,
"created": true
自动生成的ID有22个字符长,URL-safe, Base64-encoded string universally unique identifiers, 或者叫 UUIDs。
3.2 获取文档
1、检索文档
想要从Elasticsearch中获取文档,我们使用同样的_index、_type、_id,但是HTTP方法改为GET。
GET /website/blog/123?pretty2、pretty
在任意的查询字符串中增加pretty参数,类似于上面的例子。会让ElasticSearch美化输出(pretty-print)JSON响应以便更加容易阅读。_source字段不会被美化,它的样子与我们输入的一致。GET请求返回的响应内容包括"found": true。这意味着文档已经找到。如果我们请求一个不存在的文档,依旧会得到一个JSON,不过found值变成了false。此外,HTTP响应状态码也会变成'404 Not Found'代替'200 OK'。我们可以在curl后加-i参数得到响应头:
curl -i -XGET http://localhost:9200/website/blog/124?pretty3、检索文档的一部分
通常,GET请求将返回文档的全部,存储在_source参数中。但是可能你感兴趣的字段只是title,请求个别字段可以使用_source参数。多个字段可以使用逗号分隔。
GET /website/blog/123?_source=title,text3.3 更新

当语句再次被执行的时候我们回发现version的版本增加了,如下所示:

3.4 删除文档
删除文档的语法模式与之前基本一致,只不过要使用DELETE方法:
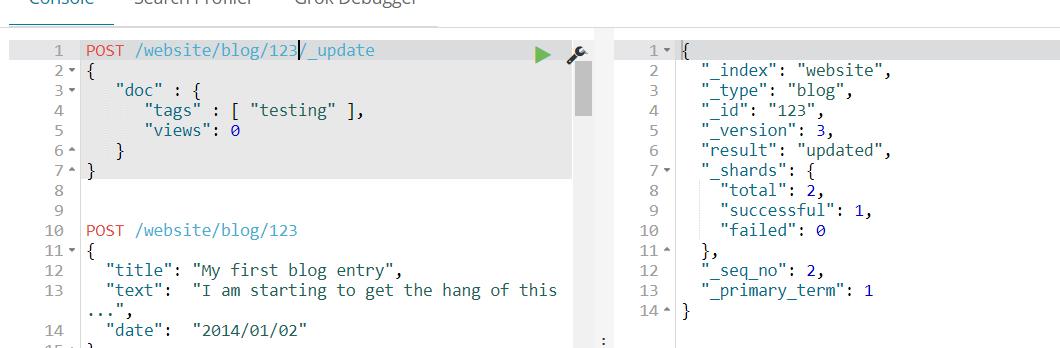
DELETE /website/blog/1233.5 局部更新
如果请求成功,我们将看到类似index请求的响应结果:
3.6 批量插入
POST test_search_index/doc/_bulk
"index":
"_id":1
"username":"alfred way",
"job":"java engineer",
"age":18,
"birth":"1991-12-15",
"isMarried":false
"index":
"_id":2
"username":"alfred",
"job":"java senior engineer and java specialist",
"age":28,
"birth":"1980-05-07",
"isMarried":true
3.7 检索多个文档
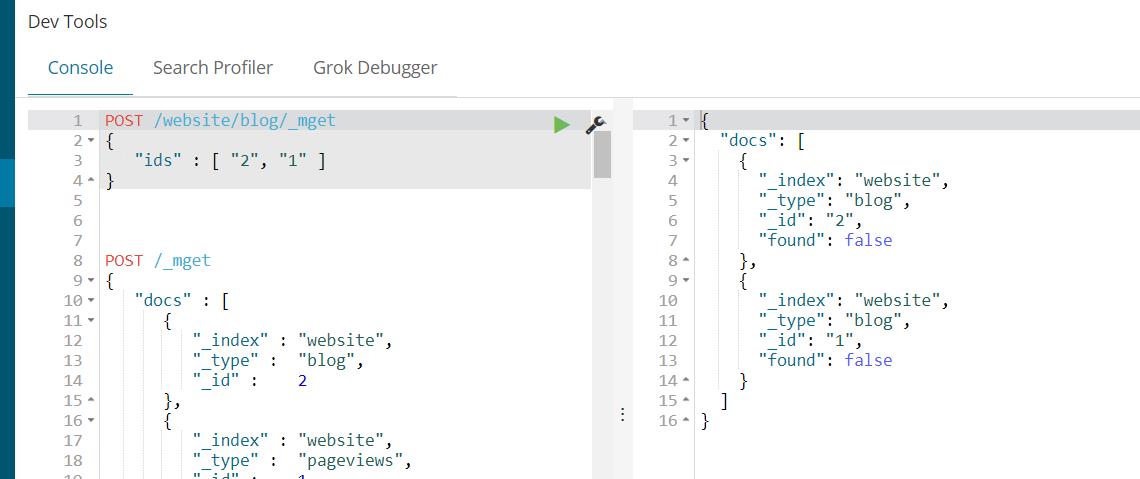
像ElasticSearch一样,检索多个文档依旧非常快,合并多个请求可以避免每个请求单独的网络开销。如果你需要从ElasticSearch中检索多个文档,相对于一个一个的检索,更快的方式是在一个请求中使用multi-get或者mget API。mget API参数是一个docs数组,数组的每个节点定义一个文档的_index、_type、_id元数据。如果你只想检索一个或几个确定的字段,也可以定义一个_source参数:
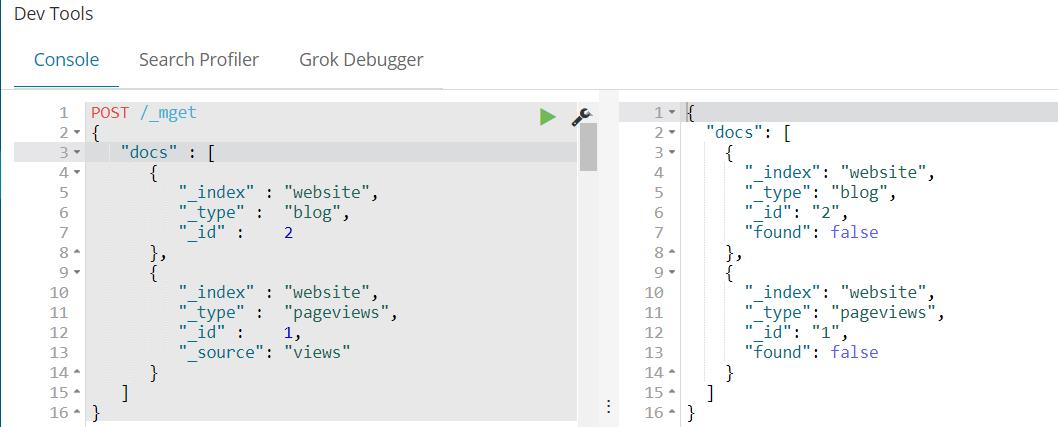
响应体也包含一个docs数组,每个文档还包含一个响应,它们按照请求定义的顺序排列。每个这样的响应与单独使用get request响应体相同。
如果你想检索的文档在同一个_index中(甚至在同一个_type中),你就可以在URL中定义一个默认的/_index或者/_index/_type。
你可以通过简单的ids数组来代替完整的docs数组:
四、Search API
4.1 URI
GET /_search #查询所有索引文档
GET /my_index/_search #查询指定索引文档
GET /my_index1,my_index2/_search #多索引查询
4.1.1 URI查询方式(查询有限制,很多配置不能实现)
GET /my_index/_search?q=user:alfred #指定字段查询
GET /my_index/_search?q=keyword&df=user&sort=age:asc&from=4&size=10&timeout=1s
q:指定查询的语句,例如q=aa或q=user:aa
df:q中不指定字段默认查询的字段,如果不指定,es会查询所有字段
Sort:排序,asc升序,desc降序
timeout:指定超时时间,默认不超时
from,size:用于分页1、批量创建文档

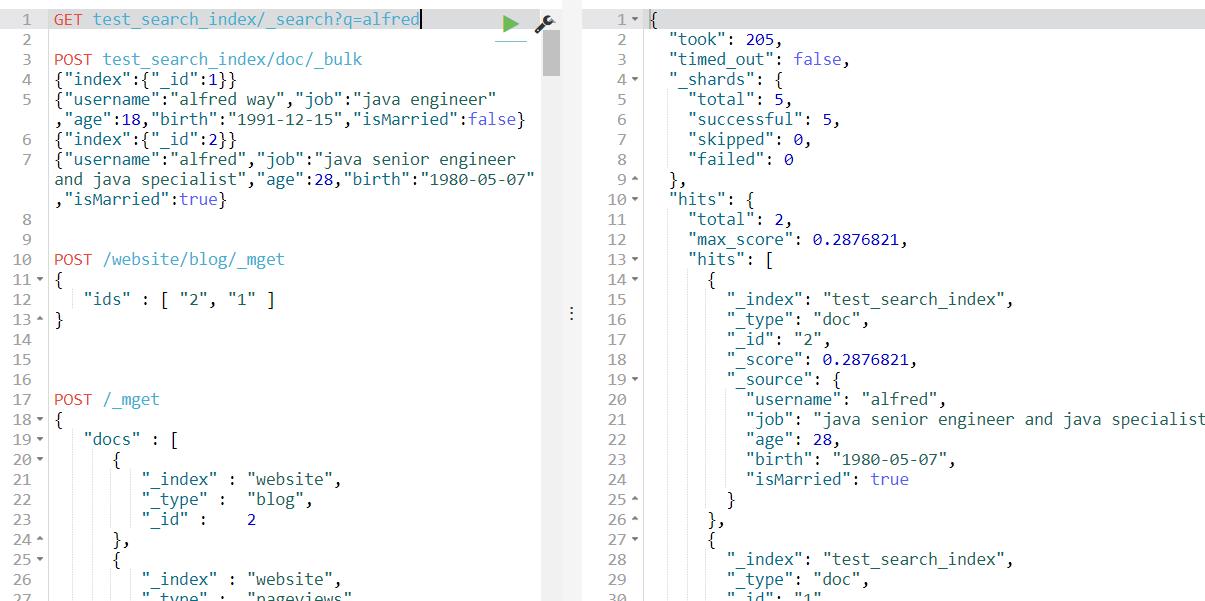
2、泛查询
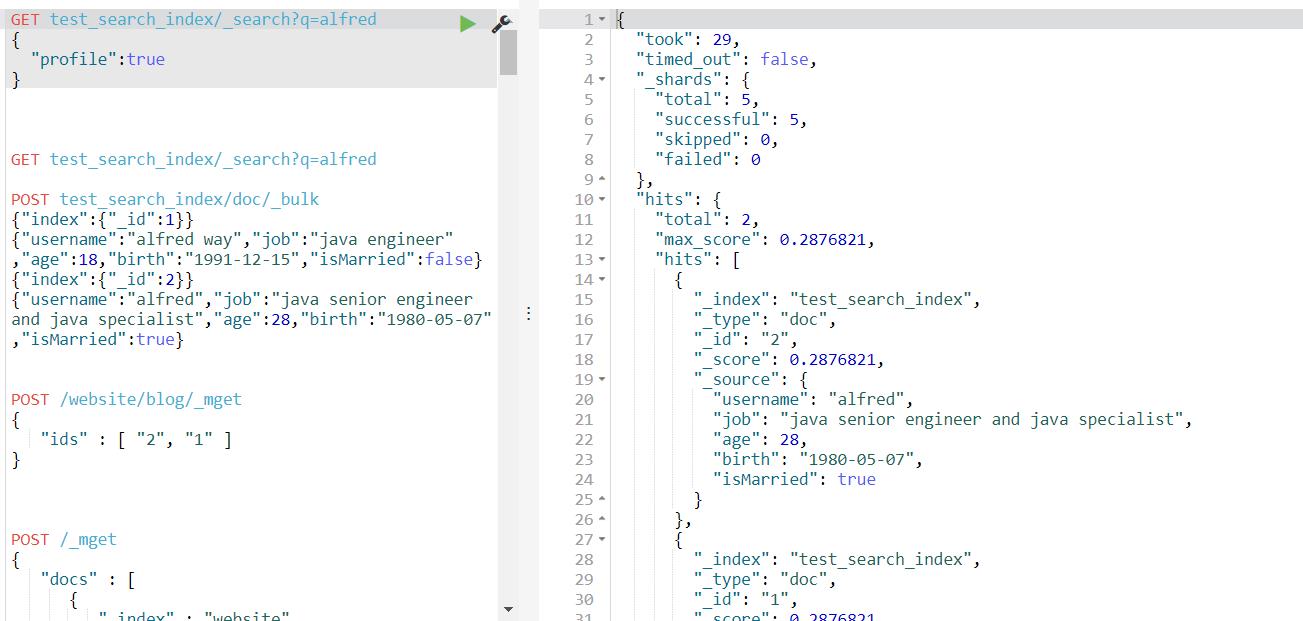
3、查询语句执行计划查看
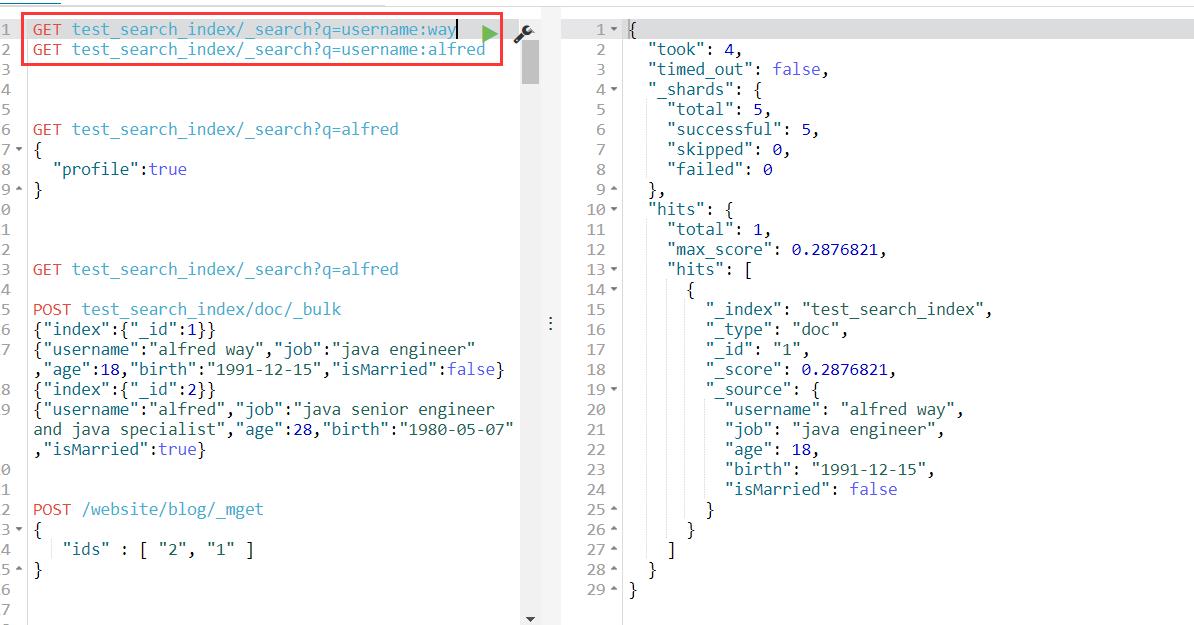
4、term查询
5、phrase查询

6、group查询
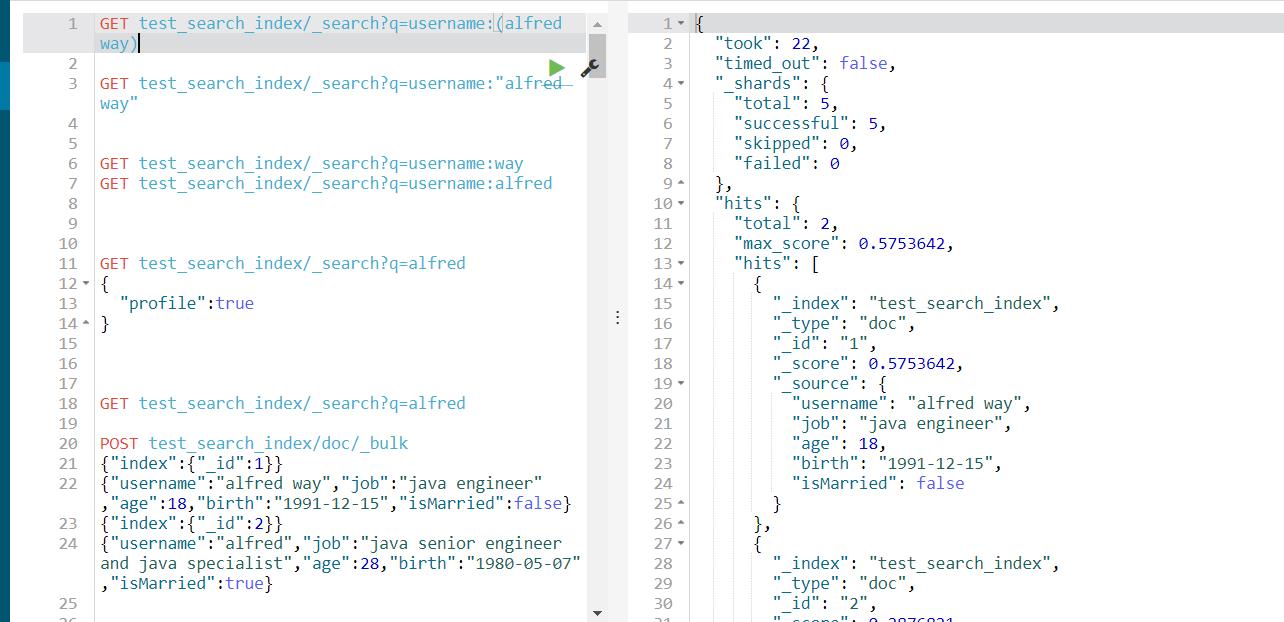
7、布尔操作符
(1)AND(&&),OR(||),NOT(!)
例如:name:(tom NOT lee) #表示name字段中可以包含tom但一定不包含lee。
(2)+、-分别对应must和must_not
例如:name:(tom +lee -alfred) #表示name字段中,一定包含lee,一定不包含alfred,可以包含tom。
注意:+在url中会被解析成空格,要使用encode后的结果才可以,为%2B。

4.1.2 范围查询
需要注意的是,范围查询支持数值和日期。
1、区间:闭区间:[];开区间:
age:[1 TO 10] #1<=age<=10
age:[1 TO 10 #1<=age<10
age:[1 TO ] #1<=age
age:[* TO 10] #age<=102、算术符号写法
age:>=1
age:(>=1&&<=10)或者age:(+>=1 +<=10)4.1.3 通配符查询
?:1个字符
*:0或多个字符例如:name:t?m name:tom* name:t*m等等。
注意:通配符匹配执行效率低,且占用较多内存,不建议使用,如无特殊要求,不要将?/*放在最前面。
4.1.4 正则表达式
name:/[mb]oat/4.1.5 模糊匹配fuzzy query
name:roam~1
匹配与roam差1个character的词,比如foam、roams等
4.1.6 近似度查询proximity search
“fox quick”~5
以term为单位进行差异比较,比如”quick fox” “quick brown fox”4.2 Search API(Request Body Search)
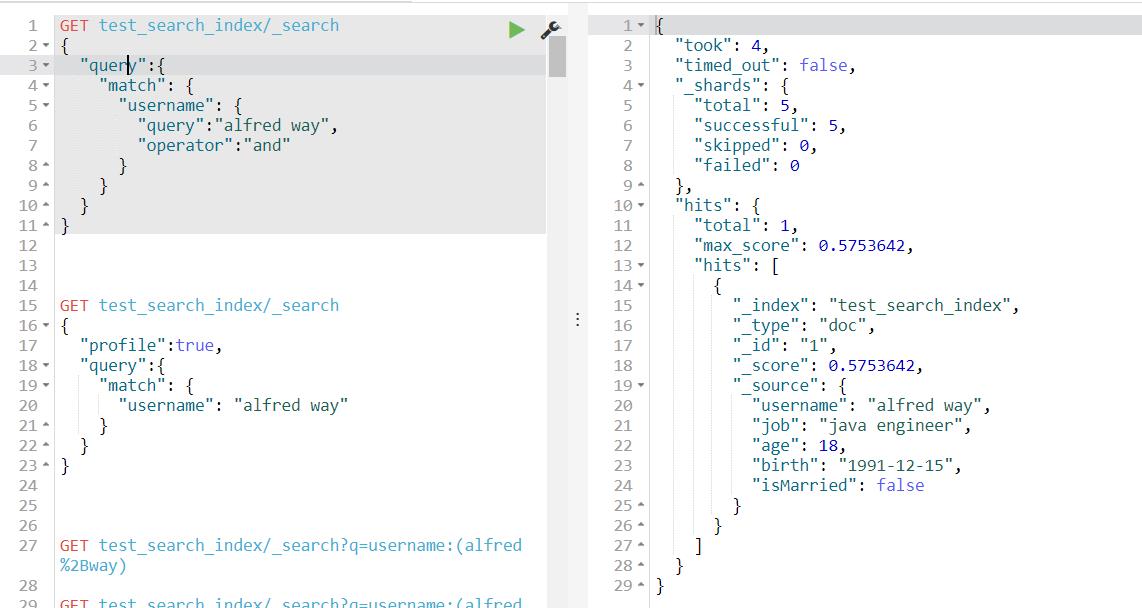
4.2.1 Match Query
对字段作全文检索,是最基本和最常用的查询类型。

通过operator参数可以控制单词间的匹配关系,可选项为or和and。
以上就是本文的所有内容,比较简单。你们在此过程中遇到了什么问题,欢迎留言,让我看看你们都遇到了哪些问题~
以上是关于八十二ElasticSearch详解(下)的主要内容,如果未能解决你的问题,请参考以下文章