潜在语义分析plsa中文档概率p(d)到底是啥?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了潜在语义分析plsa中文档概率p(d)到底是啥?相关的知识,希望对你有一定的参考价值。
如图, 所有的plsa中都会提到这个文档概率p(d), 李航的书中写到p(d)可以直接统计得到.可是p(d)到底是什么?如果一共有M篇文档, 那p(d)不就是1/M吗?有什么好统计的?
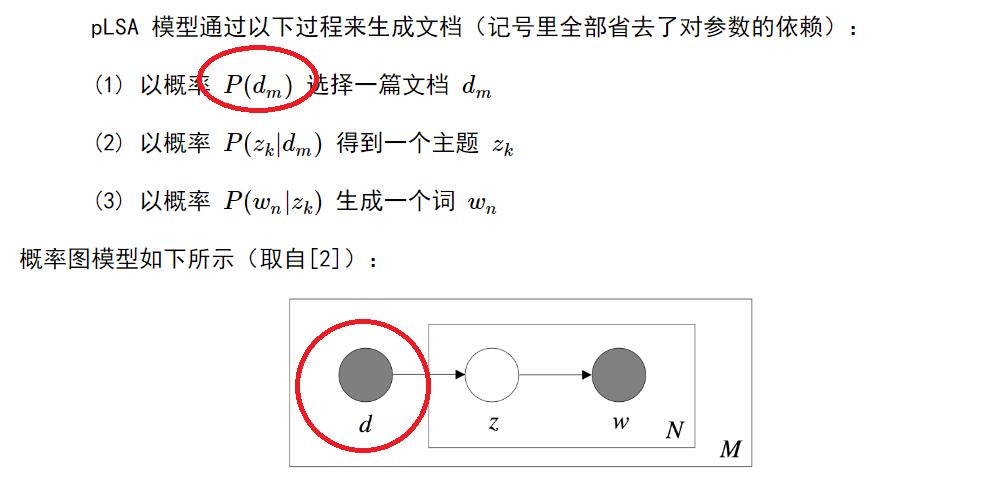
当然不是1/M的概率,你有这个问题,说明你对这个算法的目的都还搞清楚吧,想想PLSA的目的是做什么的?文档是有主题的,某篇文章的概率,是指M篇文章种,某个类型的文章的概率。比如,100篇文章,30篇体育,30篇科技,40篇民生。p(任意一篇体育文章)=30/100。这里的概率=频率。所以说,p(d)是先验可知,能直接统计得到的。追问
那照这种说法的话p(z | d)又是什么呢?
d是文档, z是主题, 如果主题事先就被选定的话似乎不太符合逻辑吧?
p(z | d)按你的说法表达出来就是p(主题=体育 | 任意一篇体育文章) 不应该等于1吗?
你的理解开始上路了
没错,按照我这种粗略的说法,你的理解是对的。那就仔细准确的说下
PLSA解决的问题是文本的多分类问题,属于有监督范畴。
所以,因为是有监督,必然知道训练文档中,每篇文档的类别,而P(d)呢,是指某个文档属于某个类别的概率。这个概率,是先验可知的,因为我们可以直接从训练文档中统计得到。也就是说刚刚说的p(任意一篇体育文章)=30/100。
而主题的提出,是因为大部分文档,含有多个主题,这个主题,是由词来组成的(语言学上的主题和这个主题还是有差异的)。也就是说任意一篇文档,它包含多个主题,每个主题,都有它的概率。想想看,体育里面大部分都是体育概念的词,但不能说它绝对没有其他主题的词。比如,轰炸球门~,所以判断一篇文章属于哪个类别,很自然的,我们需要分析文档下各个主题的“含量”吧,也就是p(z|d),
不好意思,PLSA是典型的非监督学习,是不需要主题作为输入数据的, 这一点从李航的书,或者任何网页都可以查询到. 所以p(d)能通过这种方式统计得到的前提不存在
概率潜在语义分析(Probabilistic Latent Semantic Analysis,PLSA)
概率潜在语义分析(Probabilistic Latent Semantic Analysis,PLSA)
目录
以上是关于潜在语义分析plsa中文档概率p(d)到底是啥?的主要内容,如果未能解决你的问题,请参考以下文章