light-reid:轻量化行人重识别开源工具箱
Posted 等待破茧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了light-reid:轻量化行人重识别开源工具箱相关的知识,希望对你有一定的参考价值。
https://zhuanlan.zhihu.com/p/348214785
GITHUB:wangguanan/light-reid
PAPER: https://arxiv.org/abs/2008.06826
Author HomePage:https://wangguanan.github.io/
本文提出了基于 Pytorch 的轻量化行人重识别(person re-identification, reid)开源工具箱 light-reid。不同于已有开源 reid 工具箱往往关注于精度,该工具箱在保证精度的同时,力求更加快速的 reid 模型推理以及行人搜索。应用于该工具箱的部分加速模块已经被 ECCV2020 接收。(注:本文 reid 特指 person reid,即行人重识别)

框架
什么是 reid,如何实现
简单理解就是,我们需要根据某行人A的图像,在图像候选集中找到该行人A的其他图像。reid 技术在实际场景中有着很重要的作用。
使用 reid 技术,我们便可以在一个监控系统中,构建行人的运动轨迹,并应用到各种下游任务。比如在小区监控系统中,我们在某个时刻锁定犯人A,根据 reid 技术,我们就可以在整个监控系统的中,自动的找出犯人A在整个小区监控中出现的图片,并确定他的运动轨迹,最终辅助警察抓捕。再比如在智慧商业场景中,我们可以根据 reid 技术描绘出每个消费者的商场运动轨迹和区域驻留时间,从而优化客流、辅助商品推荐等。
reid 算法可以分解为以下3步:
- 特征提取:给定一个查询图片(query image)和大量的数据库图片(gallery images),提取出它们的语义特征。在这个特征空间,同一个人的图片距离尽可能小,不同人图片距离尽可能大。目前主流的 reid 算法使用深度卷机神经网络(CNN,如 ResNet50)提取特征。
- 距离计算:得到查询特征(query feature)和数据库特征(gallery features)后,计算查询图片和数据库图片的距离。通常使用欧式(euclidean)、余弦(cosine)距离等。
- 排序返回:得到距离后,我们可以使用排序算法对样本进行排序,通过卡距离阈值或者K近邻的方法,返回最终样本。一般使用快速排序算法,其复杂度是 O(NlogN),N 为数据库图片数量。
回顾已有 reid 工具箱
| 名称 | 作者 | 单位 | 特点 | 年份 |
|---|---|---|---|---|
| torchreid | Kaiyang Zhou | 萨里大学 | 封装完善 | 2018 |
| fastreid | Xingyu Liao | 京东人工智能研究院 | 支持部署 | 2019 |
| open-unreid | mmlab | 香港中文大学 | 无监督场景 | 2020 |
| light-reid (本文框架) | Guan'an Wang | 中国科学院自动化研究所 | 轻量化场景 | 2020 |
截至目前,学术界、工业界已经发布了多个 reid 工具箱,这些工具箱极大的推动了 reid 技术的发展,为 reid 社区做出了重大的贡献。我们简单回顾一下目前已有的 reid 工具箱以:
- torchreid:torchreid 发布于2018年05月,由萨里大学(University of Surrey, UK)的 Kaiyang Zhou 博士发布并维护,是发布最早、最完善、受关注度最高的reid工具箱之一。它提供了良好的模块封装(包括数据、模型、损失函数、训练引擎、测试协议等),部分最新reid模型的实现,预训练模型,结果可视化等。除此之外,它还提供了详细的文档支持,截至目前该库在 github 上已经收获了超过 2.3k 的star,其影响力可见一斑。
- fastreid:fastreid (paper, author: Lingxiao He, Xingyu Liao, Wu Liu, etc.) 发布于2020年6月,由 JDAI-CV 实验室支持并维护。该库是第一个工业级别 reid 工具箱,它不仅具有简单好用的优势,更集成的 ONNX/TensorRT 模块用于工程部署。除此之外,该库提供了YAML文件来轻松定义数据、模型、目标函数等。即使是小白也可以轻松训练自己的 reid 模型。该库在发布短短3个月的时间内,github star 数已经超过 1.5k。
- open-unreid:open-unreid 工具箱主要关注于无监督 reid (即只有训练数据,没有训练标签)。研究无监督 reid (unsupervised reid)的小伙伴们可以多多关注这个工具箱。open-unreid 工具箱主要关注于无监督 reid (即只有训练数据,没有训练标签)。研究无监督 reid (unsupervised reid)的小伙伴们可以多多关注这个工具箱。
除了 reid 工具箱,很多学者也公开了一些简单且高性能的 reid baseline(基础模型)。这些 reid baseline 结构简单,训练推理速度快,且性能也具有一定的竞争力。基于这些 baseline,研究人员可以快速地验证自己的 idea,避免重复刷点等体力劳动。
- reid_baseline:reid_baseline 是一个基于pytorch实现的,小巧、友好并且强大的 reid baseline。它的性能媲美当前最好的公开方法(强大),支持fp16精度用2GB显存进行训练(小巧),并且提供了一个8分钟快速教程入门reid(新手友好)。该 baseline 由 Zhezhong Zheng 博士于2017年发布,至今 github star 数量已经超过 2k。
- bagtricks_reid:bagtricks_reid 在 reid_baseline 中集成了众多简单好用的技巧,并在行人reid,车辆reid等多个任务上。该 baseline 由 Hao Luo 博士发布并维护,发布时间是2019年,目前在 github 上已经获得 star 数超过1.3k。
- agw: agw 相比 bagtricks_reid, 不仅加入了更多的技巧,取得了更高的性能,同时将该模型应用到多模态reid(cross-modality visible-infrared reid) 中,取得了优异的成绩。该方法由起源人工智能研究院(IIAI) 的 Mang Ye 博士提出。
- sbs(stronger_baseline): sbs 由 JDAI-CV 实验室发布,由 fastreid 工具箱实现。该方法基于前三者的基础,同时加入了 circle loss/ arcface 等损失函数,使得其不仅在公开学术数据集上取得了目前最好的性能,更在大规模数据集上得到了验证。
为什么要 light-reid
通过回顾已有的 reid 工具箱我们可以发现,目前的 reid 工具箱/基础模型 全部关注 reid 精度(CMC,mAP)。除了精度,速度也是一个非常重要的指标。尤其是在实际业务场景中,在计算资源有限的情况下,快速的推理、搜索显得尤为重要。为了补齐目前 reid 工具箱的短板,我们提出的 light-reid 工具箱关注精度的同时,更可以加速推理和搜索。
结合以上3个目前已有个 reid 工具箱,我们的 light-reid 可以完善 reid 工具箱的生态,从精度,到速度,再到工业应用,形成良好闭环。这也是我们提出 light-reid 工具箱的初衷与动机。
light-reid 提供了针对 reid 任务的完整的工具箱,包括数据准备、模型搭建、训练、评估、加速等。它具有如下特点:
- 模块化和灵活的设计:方便研究者快速将新的模块插入和替换现有流程中,帮助学界快速验证新思路;
- 众多State-of-the-art预训练模型:我们初步实现了2个 reid baseline,包括 bagtricks 和 agw ,未来将会实现更多 reid baseline;
- 一键加速:轻松的对现有 reid 模型进行轻量化改进,提高其特征提取(feature extraction)速度和图像检索(image retrieval)速度。
什么是 light-reid
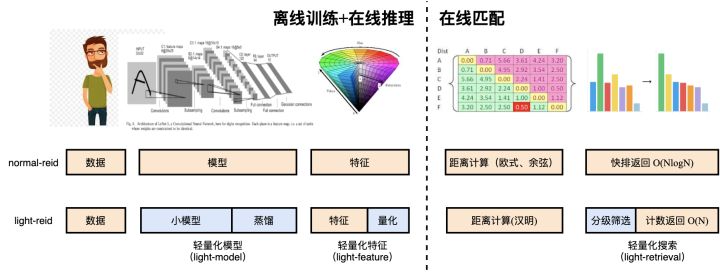
light-reid 框架如上图所示, 一共分为3个模块,分别是 light-model (轻量化模型),light-feature(轻量化特征)以及 light-search(轻量化搜索):
- light-model (轻量化模型):轻量化模型模块通过使用模型蒸馏的方法,学习到性能较好、计算量较小的 reid 模型。实验结果表明,该模块可以对特征提取加速3x(resnet18 v.s. resnet50),且精度(mAP)降低控制在 2% 左右。
- light-feature (轻量化特征):light-feature 通过对实值(real-value)特征进行二值量化(binarization),降低存储空间并加速距离计算。实验结果表明,相比 float64 型实值编码,二值编码存储空间降低64倍,距离计算速度加速 3x,精度损失几乎为零。
- light-search (轻量化搜索):light-search 通过我们在ECCV2020上提出的层级搜索策略,更多的利用短码进行快速粗排,仅对少量候选样本进行精排序。实验结果表明,该方法可以加速搜索 5x 左右,精度降低控制在2%。
以上三个模块可以同时使用,对特征提取加速3x,对搜索加速20x,精度降低仅在4%左右。
4步入门 light-reid
light-reid 提供了简单灵活的模块,方便使用者构建数据集、搭建模型,进行训练、测试以及可视化。
构建训练和测试集
# build dataset
datamanager = lightreid.data.DataManager(
sources=lightreid.data.build_train_dataset([args.dataset]),
target=lightreid.data.build_test_dataset(args.dataset),
transforms_train=lightreid.data.build_transforms(img_size=[256, 128], transforms_list=['randomflip', 'padcrop', 'rea']),
transforms_test=lightreid.data.build_transforms(img_size=[256, 128], transforms_list=[]), sampler='pk', p=16, k=4)构建模型、损失函数和优化器
# build model
backbone = lightreid.models.backbones.resnet50(pretrained=True, last_stride_one=True)
pooling = nn.AdaptiveAvgPool2d(1)
head = lightreid.models.BNHead(in_dim=backbone.dim, class_num=datamanager.class_num)
model = lightreid.models.BaseReIDModel(backbone=backbone, pooling=pooling, head=head)
# build loss
criterion = lightreid.losses.Criterion([
'criterion': lightreid.losses.CrossEntropyLabelSmooth(num_classes=datamanager.class_num), 'weight': 1.0,
'criterion': lightreid.losses.TripletLoss(margin=0.3, metric='euclidean'), 'weight': 1.0,
])
# build optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.00035, weight_decay=5e-4)
lr_scheduler = lightreid.optim.WarmupMultiStepLR(optimizer, milestones=[40, 70], gamma=0.1, warmup_factor=0.01, warmup_epochs=10)
optimizer = lightreid.optim.Optimizer(optimizer=optimizer, lr_scheduler=lr_scheduler, max_epochs=120)构建引擎(可选是否使用 light-reid)
# build engine
solver = lightreid.engine.Engine(
results_dir=args.results_dir, datamanager=datamanager, model=model, criterion=criterion, optimizer=optimizer, use_gpu=True,
light_model=args.lightmodel, light_feat=args.lightfeat, light_search=args.lightsearch)运行(训练、测试、可视化)
# train
solver.train(eval_freq=10)
# test
solver.resume_latest_model()
solver.eval(onebyone=True)
# visualize
solver.visualize()支持 YAML 定义
除了上述手撸代码的比较复杂的操作,我们还支持基于如下格式的YAML文件定义模型配置。
env:
results_dir: './results/duke/resnet50/'
use_gpu: True
data_parallel: True
sync_bn: False
lightreid:
light_model: False
light_feat: False
light_search: False
data:
sources: ['dukemtmcreid']
targets: ['market1501', 'dukemtmcreid']
img_size: [256, 128] # height, width
transforms_train: ['randomflip', 'padcrop', 'rea']
transforms_test: []
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
sampler: 'pk'
p: 16
k: 4
model:
backbone:
name: 'resnet50'
last_stride_one: True
pretrained: True
pooling:
name: 'avgpool'
head:
name: 'bnhead'
classifier:
name: 'linear'
criterion:
loss1:
display_name: 'classification_loss'
criterion:
name: 'cross_entropy_label_smooth'
inputs:
inputs: 'logits'
targets: 'pids'
weight: 1.0
loss2:
display_name: 'triplet_loss'
criterion:
name: 'tripletloss'
margin: 0.35
metric: 'euclidean'
inputs:
emb: 'feats'
label: 'pids'
weight: 1.0
optim:
optimizer:
name: 'adam'
lr: 3.5e-4
weight_decay: 5.0e-4
lr_scheduler:
name: 'warmup_multistep'
milestones: [40, 70]
gamma: 0.1
warmup_factor: 0.01
warmup_epochs: 10
max_epochs: 120并使用如下python脚本进行训练和测试。
import argparse, ast
import sys
sys.path.append('../..')
sys.path.append('.')
import torch
import lightreid
import yaml
import time
parser = argparse.ArgumentParser()
parser.add_argument('--config_file', type=str, default='./configs/base_config.yaml', help='')
args = parser.parse_args()
# load configs from yaml file
with open(args.config_file) as file:
config = yaml.load(file, Loader=yaml.FullLoader)
# init solver
solver = lightreid.build_engine(config)
# train
solver.train(eval_freq=10)
# test
solver.resume_latest_model()
solver.smart_eval(onebyone=True, mode='normal')
# visualize
solver.resume_latest_model()
solver.visualize()实验结果
基于 light-reid 实现的 bagtircks 方法在 Market1501 的数据库上的测试结果如下图所示。light-reid 可以加速搜索 22x,特征提取速度 3x,精度损失大约在 4%. 更多实验结果,请参考链接。
- light model 加速特征提取 3x:特征提取速度从79ms 加速到 23ms,搜索速度从 382ms 加速到 59ms,而精度损失控制在2%左右;
- light feature 加速搜索 4x,精度损失几乎为零:搜索速度从 382ms 加速到 83ms,精度几乎不会降低;
- light search 加速搜索 22x:搜索速度从382ms 加速到 17ms,精度掉点大约在2%;

实验结果
总结
reid 社区目前已经多个工具箱以及 baseline,它们极大的促进了 reid 技术的发展。但美中不足的是,他们主要关注精度,却忽视了速度这个重要指标。我们提出的 light-reid 工具箱在关注精度的同时,提供了一键式的加速算法,提高推理以及搜索速度。结合已有 reid 工具箱,我们的 light-reid 完善了 reid 工具箱的生态,从精度,到速度,再到工业应用,形成良好闭环。
以上是关于light-reid:轻量化行人重识别开源工具箱的主要内容,如果未能解决你的问题,请参考以下文章