关系网络技术与图数据库技术的发展
Posted 咕噜大大
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关系网络技术与图数据库技术的发展相关的知识,希望对你有一定的参考价值。
关系网络技术与图数据库发展
真是好久都没有更新自己在CSDN的博客了,这几年一直在做知识图谱相关的项目开发,主要聚焦在银行金融领域。最近公司的品牌小姐姐希望我帮公司的公众号出一些文章,所以借此机会也更新一下自己的博客吧,先写写自己对知识图谱技术和图数据库的理解吧,前段时间也在挖开源图数据库的代码,过段时间把一些源码阅读的笔记也更新上来。
关系网络技术的发展
随着社交网络和搜索引擎技术的发展,以及人工智能技术领域从感知智能向认知智能的迈进,语义网技术以及其衍生出来的关系网络技术开始得到关注和快速的发展,也顺势推动了社交关系圈分析,个性推荐,智能问答,WEB语义分析,金融风险反欺诈分析以及金融资金关系圈分析等新兴应用的快速增长。
关系网络,又称知识图谱或者大规模语义网(下文全部统一为关系网络),是用关系和节点组成的大规模知识表示形式,包含实体(Entity),概念(Concept)及其之间的各种语义关系。关系网络为真实世界的各个业务场景直观地建模,通过不同的知识关联性形成一个网络状的知识结构。形成关系网络的过程就是在建立认知,理解世界,理解领域,理解客观业务事实的过程,并组织成机器易于读取和分析的结构,让机器形成认知能力,去理解这个世界。
人类的外显记忆用的就是基于语义分析的记忆形式,因此关系网络的数据组织形式更加贴合人类对信息的分析习惯。早在20世纪70年代,因为关系网络数据模型的表达能力强,数据管理领域的研究人员就已经开始尝试使用关系网络模型对客观世界进行建模,非常直观和自然地表达出现实世界的各种客观实体概念以及他们之间的关系。2000年以后,随着互联网数据的井喷式增长,更高效的搜索引擎数据检索,社交网络数据分析以及其它应用需求的推动,再加上大数据技术的逐渐成熟,并以2012年Google公司第一次将“知识图谱”技术带入公众视野中为契机,关系网络技术的研究工作重新成为人工智能领域的研究重点。
 关系网络发展到如今,其内涵已经远远超出语义网络的范畴,它更多代表的是一种技术体系,指代基于大数据技术和人工智能技术等一系列知识工程的技术总和,也是构建现实世界业务客观事实模型的过程。随着近几年关系网络技术在工业界逐渐成熟和落地,关系网络类型也逐步从GKG(General-purpose Knowledge Graph)演化成为领域或者行业的关系网络类型DKG(Domain-specific Knowledge Graph)。
关系网络发展到如今,其内涵已经远远超出语义网络的范畴,它更多代表的是一种技术体系,指代基于大数据技术和人工智能技术等一系列知识工程的技术总和,也是构建现实世界业务客观事实模型的过程。随着近几年关系网络技术在工业界逐渐成熟和落地,关系网络类型也逐步从GKG(General-purpose Knowledge Graph)演化成为领域或者行业的关系网络类型DKG(Domain-specific Knowledge Graph)。
目前在工业界,比如银行金融领域,保险领域,电商领域,社交网络领域,都落地了很多基于DKG的成功项目,并真正为企业带来了巨大的成效,丰富了企业的数据分析维度。而基于GKG类型的项目,更多是在智能问答领域,以及教科研学术界有更多的落地案例。从实际成功落地的项目案例来看,更多的企业倾向于在特定垂直领域构建行业关系网络,基于具体的业务场景的关系网络去做数据挖掘工作。构建整个企业生态的关系网络大图,也就是GKG,然后再从关系网络大图生成特定业务的关系网络子图去做具体的分析应用,也是不少企业正在尝试的实施路径,但同时会面临着更多的挑战,这些挑战不光来自技术层面,还有概念层面如何做到和实际业务的统一并保证完整。
正是因为关系网络技术的发展,工业界在传统的基于统计和概率的数据分析维度上,开始重视数据实体间的关系分析。目前,我们内部对数据挖掘分为三个大方向,一是基于统计和概率分析,二是基于时序分析,三是基于关系数据分析;并采用分类,聚类,关联分析,异常检测等多种技术手段。
图数据库技术发展
关系网络的数据需要完成基本的图结构数据存储,同时也要支持上层应用对关系网络中的数据进行实时查询,知识推理,离线大规模图计算甚至是实时大规模图计算等,所以专门针对关系网络数据存储做了优化的图数据库成了关键的组件。目前工业界的图数据库基本都是基于带标签的属性图表示结构来设计的。
为什么要使用专门的图数据库来对关系网络数据进行存储?这里必须提到图数据库和关系型数据库的区别。关系型数据库存储的是一件客观事实的描述,比如用户购买了某件具体的商品,客户申请了一笔贷款,它根据关系型数据库的四范式设计原则构建在关系模型之上。关系型数据库和图数据库的主要差异是数据存储的方式,关系型数据天然就是表格式的,因此存储在数据表的行和列中。数据表可以彼此关联协作存储,也很容易提取数据,尤其在查找某个区间内的数据组很有优势,但是确无法清晰直观地体现出数据之间包含的潜在关系。关系型数据库是以实体建模这一基础理念设计的。实体之间的关系需要创建一个关联表来维护,当需要描述大量关系时,传统的关系型数据库已经不堪重负; 联系确实存在于关系型数据库自身的术语中,但只出现在建模阶段,作为连接表的手段,但对于关联关系确什么都做不了。所以经过特别设计的数据存储结构,能加快实体之间的关系查询,这也是图数据库的优势所在。
图数据库的发展主要有两个阶段,第一个阶段主要是解决关系网络数据的存储,查询和分析问题,能支持上层应用对关系网络数据的OLTP业务需求以及离线大规模图数据的OLAP业务需求。第二阶段的图数据库不光满足OLTP业务和离线OLAP业务,采用内置的MPP计算引擎,实现实时大规模图数据的OLAP业务。
 【DB-Engines网站2020年图数据库使用率排名】
【DB-Engines网站2020年图数据库使用率排名】
为了满足关系网络数据的存储,查询和大规模图分析的性能,图数据库在其底层数据结构的设计上也尽量贴合关系数据的搜索习惯,减少磁盘的I/O时间。传统关系型数据库的B+树数据结构适合范围数据的检索以及随机数据读取上有优秀的性能,而对于关系数据的遍历则显得相形见绌了。图数据库针对关系网络的数据特点,采用了免索引领接,邻接表,点边数据以KCV的形式组织等等方式存储关系网络数据,其根本目的在于对邻边和邻节点的快速查询遍历,减少随机读写的磁盘寻道时间,提升关系网络数据的I/O性能。原生图数据库不仅在数据存储文件的组织形式上做了优化,在计算机物理存储层面也充分利用内存缓存来减少数据的读取延迟甚至是提升写入效率。
NEO4J是最早在工业界大规模使用的图数据库,也是由NEO4J最早提出原生图数据库的概念,NEO4J认为原生图数据库应该具备原生图存储和免索引领接两个特性。原生图存储是指在存储层面针对关系网络数据的存储和管理而设计优化的;而免索引领接就是上面提到的,在搜索邻边和邻节点时减少磁盘寻道时间提升I/O性能,NEO4J主要通过固定存储单元大小以及双向链表的技术来实现。同时NEO4J也是非分布式的数据存储和处理的图数据库,因为NEO4J认为单机下没有分布式的网络I/O和聚合操作所带来的时间损耗,再加上对磁盘,内存和CPU的优化,查询性能可以达到最优。即使是NEO4J的集群模式,也是数据副本拷贝的形式,如果理解NEO4J存储结构的话也不难明白为什么其单机性能最优。Neo4J同时提供了社区版和商业版。
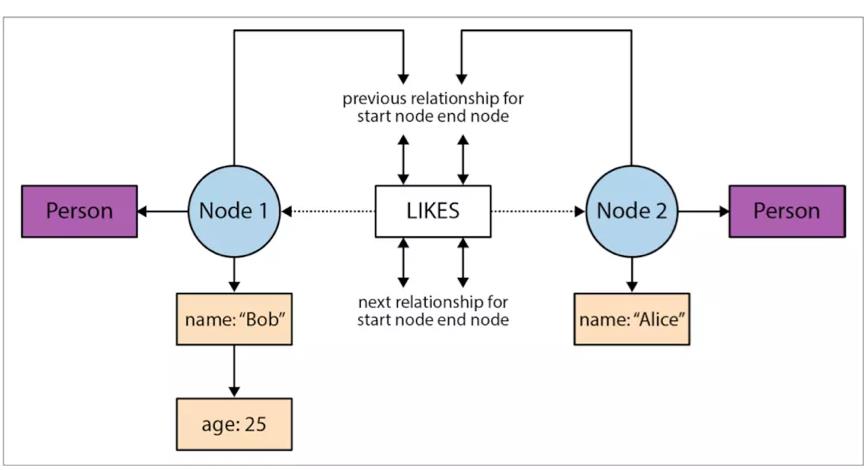 【Neo4J存储端数据结构】
【Neo4J存储端数据结构】
ArangoDB是基于C++的多数据模型数据库,支持Document, K-V, Graph等多种数据模型的存储。ArangoDB和Wikipedia社区都反对了NEO4J提出的原生图数据的定义,他们认为原生图数据库应该是使用具有点,边和属性表示的图数据结构进行存储和语义查询的数据库,而与内部的数据文件存储形式无关,更重要的应该在于数据模型和算法的使用。ArangoDB采用基于HASH和链表的混合索引形式组织图数据,Arango将所有的边数据都存储在一张大的哈希表中,同时将每个节点关联的所有邻边都存储在一个双向链表中。该数据结构在保证图遍历性能的同时,对图数据的修改和删除也提供了很好的性能。同时ArangoDB是支持横向拓展的分布式数据库,并提供了社区版和商业版。
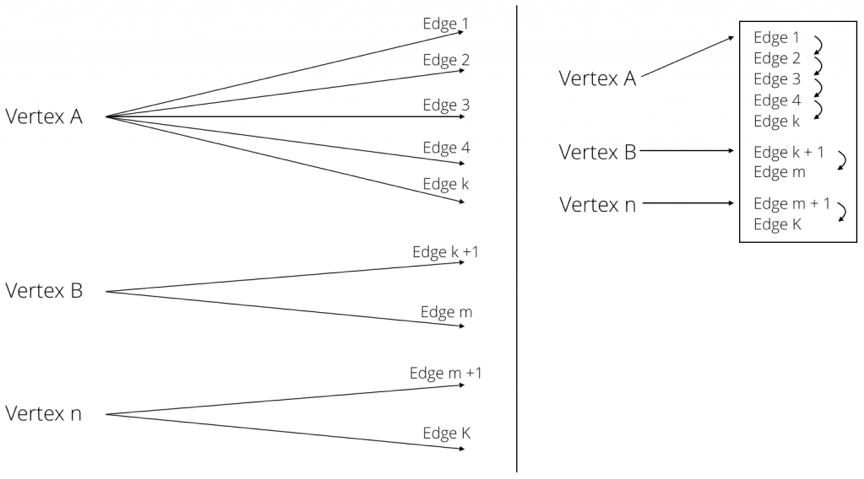 【ArangoDB存储端数据结构】
【ArangoDB存储端数据结构】
Titan是一个开源的分布式图数据存储引擎,向下支持多种基于Google Bigtable 的KCV数据模型的数据库,包括 Apache Cassandra, Apache HBase, Google Cloud Bigtable, Oracle BerkeleyDB;向上支持Gremlin 图查询语言对业务系统提供关系网络数据查询,同时兼容Spark 分布式计算框架,提供对大规模关系网络数据进行离线OLAP 分析。2015年Titan被DataStax公司收购,进行商业化改造,开源社区开发者新fork出一个分支,封装成JanusGraph项目并持续维护。JanusGraph基于Google Bigtable 的KCV数据模型设计,采用边切割的方式存储关系网络数据,将点的属性,边的属性,邻节点key信息存在一起封装成KCV的数据结构,通过key进行索引,减少邻边和邻节点的遍历时间。其关系网络数据处理的时间复杂度还是需要根据其具体的存储层组件来进行分析,如果是采用HBase做为存储端,那显而易见在关系网络数据写入方面会有一定的优势。JanusGraph也是许多国内一线大厂封装自己图数据库的基本开源框架,基于商业敏感性这里也就不一一列举了。国内厂商对于JanusGraph的二次封装优化策略主要在于ID的分配机制,边的索引优化等。
 【JanusGraph存储端数据结构】
【JanusGraph存储端数据结构】
TigerGraph是商业图数据库,其采用C++语言开发,在关系网络数据的存储和查询方面做了物理层的优化,充分使用了计算机的缓存资源,同时也提供了高压缩比的数据存储策略。通过内置图存储引擎和图计算引擎并存的技术,采用MPP计算模型,实现实时的OLAP分析。相比JanusGraph采用Spark框架实现MPP计算,TigerGraph的图中每个顶点和边同时作为存储和计算的并行单元,能提供更高的计算效率和性能。
微软的Azure云计算服务的Cosmos DB,亚马逊云计算服务的Neptune以及阿里云的GDB图数据库,都是各个云厂商推出的云上图数据库服务。目前,图数据库的技术发展还没形成一套完整的工业标准,但是随着关系网络技术的发展和普及,多元化的图数据库共存在市场上的局面还暂时不会改变, 实时大规模关系网络OLAP技术也将是未来发展的趋势。
参考书籍:
[1] 图数据库 lan Robinson, Jim Webber, Emil Eiferm 著 刘璐,梁越译
[2] 知识图谱概念与技术 肖仰华 等编著
参考网络材料:
[1] https://www.arangodb.com/2016/04/index-free-adjacency-hybrid-indexes-graph-databases
[2] https://www.cnblogs.com/zhangzl419/p/9100498.html
[3] https://zhuanlan.zhihu.com/p/36183004
以上是关于关系网络技术与图数据库技术的发展的主要内容,如果未能解决你的问题,请参考以下文章