依存句法分析综述
Posted 2016bits
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了依存句法分析综述相关的知识,希望对你有一定的参考价值。
目录
2、基于转移的依存句法分析(Transition-based)
看了斯坦福大学cs224依存分析的公开课后,对于依存分析仍是一脸茫然,所以查阅相关资料,对自然语言处理的依存分析这一方向做了一个简单的综述。笔者能力有限,如有错误,欢迎指正。
参考:
常宝宝. 基于深度学习的图解码依存分析研究进展[J]. 山西大学学报:自然科学版, 2017(3).
石翠.依存句法分析研究综述[J].智能计算机与应用,2013,3(06):47-49.
杨振鹏.依存句法分析方法综述[J].无线互联科技,2018,15(22):114-116.
一、引言
句法分析(syntactic parsing)是自然语言处理中的关键技术之一,它是对输入的文本句子进行分析得到句法结构的处理过程。对句法结构进行分析,一方面是语言理解的自身需求,句法分析是语言理解的重要一环,另一方面也为其它自然语言处理任务提供支持。例如句法驱动的统计机器翻译需要对源语言或目标语言(或者同时两种语言)进行句法分析;语义分析通常以句法分析的输出结果作为输入以便获得更多的指示信息。
根据句法结构的表示形式不同,常见的句法分析任务分为:
- 句法结构分析(syntactic structure parsing),又称短语结构分析(phrase structure parsing),也叫成分句法分析(constituent syntactic parsing)。作用是识别出句子中的短语结构以及短语之间的层次句法关系。
- 依存关系分析,又称依存句法分析(dependency syntactic parsing),简称依存分析,作用是识别句子中词汇与词汇之间的相互依存关系。
- 深层文法句法分析,即利用深层文法,例如词汇化树邻接文法(Lexicalized Tree Adjoining Grammar, LTAG)、词汇功能文法(Lexical Functional Grammar, LFG)、组合范畴文法(Combinatory Categorial Grammar, CCG)等。作用是对句子进行深层的句法以及语义分析。
下面主要介绍依存句法分析,依存句法分析是针对句子中的词汇以及词汇之间的依存关系。
依存句法分析以谓词为句子的研究中心,其他成分与动词直接或间接地产生联系。“依存”指词与词之间支配与被支配的关系,这是一种偏序关系。处于支配地位的成分称为支配者(governor,regent,head),处于被支配地位的成分属于从属者(modifier,subordinate,dependency)。句子的依存结构有三种表示方式:

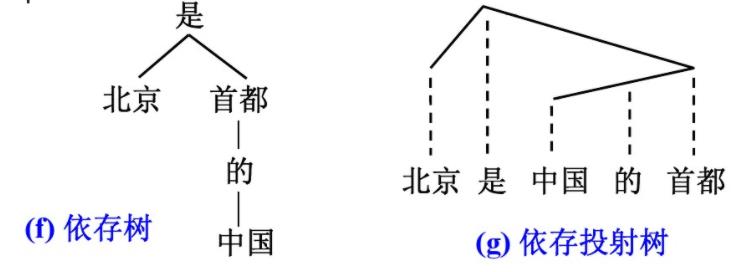
在示例中,对于主谓关系,谓词“是”是支配者,指示代词“北京”是从属者;而“首都”在动宾关系中是从属者,在定中关系中又成了支配者。
依存分析器的性能评价:
- 无标记依存正确率(UAS):测试集中找到其正确支配词的词(包括没有标注支配词的根结点)所占总词数的百分比
- 带标记依存正确率(LAS):测试集中找到其正确支配词的词,并且依存关系类型也标注正确的词(包括没有标注支配词的根结点)占总词数的百分比
- 依存正确率(DA):测试集中找到正确支配词非根结点词所占非根结点词总数的百分比
- 根正确率(RA):有两种定义,一种是测试集中正确根结点的个数与句子个数的百分比。另一种是指测试集中找到正确根结点的句子数所占句子总数的百分比
- 完全匹配率(CM):测试集中无标记依存结构完全正确的句子占句子总数的百分比
二、传统的依存句法分析方法
1、生成式的句法分析模型
生成式模型采用联合概率 (其中,已知序列为x,依存分析结构为y,模型参数为θ),生成一系列依存句法树,并赋予其概率分值,然后采用相关搜索算法找到概率最高的分析结果作为最后输出。
(其中,已知序列为x,依存分析结构为y,模型参数为θ),生成一系列依存句法树,并赋予其概率分值,然后采用相关搜索算法找到概率最高的分析结果作为最后输出。
最终目标:从训练中获取使联合概率 取得最大值的参数θ,得分最高的依存结构树。
取得最大值的参数θ,得分最高的依存结构树。
(1)基于概率的上下文无关文法PCFG方法,是生成式方法的基础。这种方法与由短语结构句法分析算法相似,采用全局搜索,生成多棵依存树,每个句子对应一棵或多棵依存树,最后系统输出概率最高的那棵树
参考PCFG模型

(2)二元词汇亲和模型,该模型加入了词汇信息,将词性与词形联合。一个标记序列由马尔可夫过程产生,链接关系对词汇是敏感的,每一对词是否可以构成链接关系的决策依赖于词汇信息,最终生成词性、词形和链接关系的联合概率模型。

一个标记序列(tags)由马尔可夫(Markov)过程产生,观察每一对词(words)是否可以构成链接关系(link)的决策依赖于[tags, words],即link对词汇是敏感的。最终生成words,tags,links的联合概率模型。
(3)选择偏好模型,该模型加入了词的选择偏好信息,不再穷举所有连接再根据约束进行剪裁,而是限制模型为每个词只选择一个父结点。

对比(2)和(3),二元词汇亲和模型后半部分考虑任意两个词的关系,再根据是否有依存关系来进行剪枝;选择偏好模型则直接根据偏好来为每个词仅选择一个父结点。
(4)递归生成模型,该模型中每个词的左子结点和右子结点分别由各自的马尔可夫模型顺次产生:左子结点的产生方向是自右向左,右子结点的产生方向自左向右的。每一个结点的生成建立在支配词和它前一个子结点上,是自顶向下的递归生成式模型。
生成式句法分析模型优点:
- 准确率较高
缺点:
- 采用联合概率模型,在进行概率乘积分解时做了不合理的假设,不易加入语言特征
- 因为采用全局搜索,算法复杂度较高,一般为O(n^3)或O(n^5)
- 不易处理非投射现象
2、判别式的句法分析模型
判别式模型为了得到正确的分类边界,从非单一样本的数据中抽取出共有的特征。判别式句法分析采用条件概率模型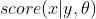 。
。
目标函数:
(1)最大生成树句法分析,基本思想:在点和边组成的生成树中找到加权和分值最高的边的组合。生成树中任意两个由词表示的结点之间都有边,根据特征和权值为每条边打分,求解最佳分析结果转化为搜索打分最高的最大生成树问题
(2)最大熵。在英语的句法分析中,Ratnaparkhi最早引入了最大熵的方法,他利用上下文特征,通过最大熵的方法来预测下一步要执行的操作。其上下文特征主要包括:成分的核心词,核心词的组合,非特定组合信息,以及部分已完成的子树信息。
(3)支持向量机。支持向量机是一种基于统计学习原理的线性分类器,可以使构成的超平面分割训练数据时,能够获得最大的边缘。支持向量机具有良好的应用效果,在自然语言处理中应用较为广泛,常用于文本分类等问题。支持向量机的主要缺点是其训练效率偏低,并且对于输出结果不能准确地给出各个输出结果的概率分布,这就限制了它在概率需求较强的任务中的应用,给一些利用概率结果的处理和应用带来了麻烦。
(4)决策树。决策树是另一种比较典型的判别学习方法。它是一种“问卷表”方式的做法,利用一系列的查询问答来判断和分类某一模式,它将全部问题集用一颗有向树表示,对非度量数据而言效果较好。在英语的句法分析中,决策树的方法在英语的宾州英文树库PTB上取得了83%以上的正确率。决策树学习方法也存在一些问题,例如,在高维问题的处理上效果不够理想。
判别式句法分析模型优点:
- 避开了联合概率模型所要求的独立性假设
- 较好的可计算性,使诸多机器学习和运筹学的方法得以应用,并可处理非投射现象
- 分析准确性较高
缺点:
- 整句内的全局搜索,不易使用动态特征
- 全局搜索使得算法复杂度较高
3、决策式的句法分析模型
基本思想:模仿人的认知过程,按照特定方向每次读入一个词。每读入一个词,都要根据当前状态做出决策(比如判断是否与前一个词存在依存关系)。分析过程可以看作是一步步作用于输入句子之上的分析动作的序列。
决策式句法分析模型的典型代表是移进-归约状态转移模型。移进-归约状态转移模型在分析过程中维护一个堆栈和一个队列,堆栈用以存储到目前为止所有的依存子树,队列存储尚未被分析到的词。堆栈顶端和队列头部确定了当前分析器的状态,依据该状态决定进行移进、归约或建立栈顶元素与队首元素的依存关系的操作,从而转入新状态。


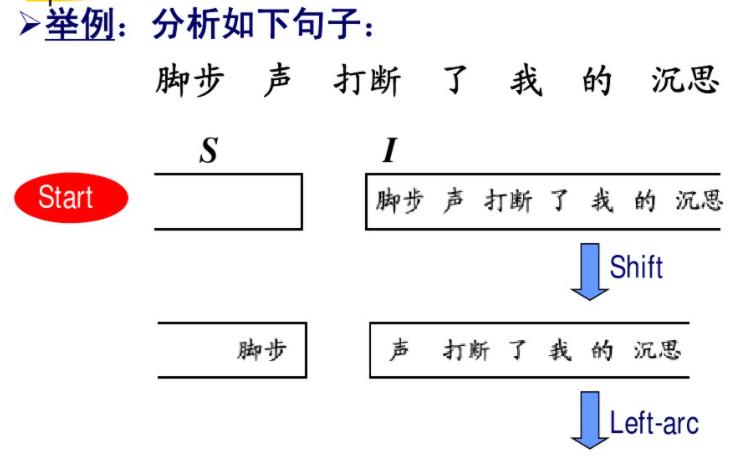






决策式句法分析的优点:
- 算法可以使用之前产生的所有句法结构作为特征
- 可以达到线性复杂度O(n)
缺点:
- 以局部最优的加和代替全局最优,导致错误传递
- 不可处理非投射现象,准确率稍逊于全局最优算法
4、约束满足的句法分析模型
将依存句法分析过程看作可以用约束满足问题(Constraint satisfaction problem,CSP)来描述的有限构造问题(finite configuration problem)。它不像上下文无关文法那样探索性地生成,而是根据已规定好的约束进行裁剪,把不符合约束的分析去掉,直到留下一棵合法的依存树。
存在的问题:可能不存在能满足所有约束的分析树,也可能有多个树满足所有约束,无法消歧。
三、基于深度学习的依存句法分析方法
1、基于图模型的依存句法分析(Graph-based)
基于图解码依存分析方法将依存分析视为一个搜索问题,令x代表由n个词组成的句子 (其中
(其中 代表人为添加的根词ROOT)。若用
代表人为添加的根词ROOT)。若用 代表句子x所有可能的依存树组成的集合,则该搜索问题可以描述为:
代表句子x所有可能的依存树组成的集合,则该搜索问题可以描述为:
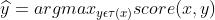
也就是在其所有候选的依存树中,寻找得分最高的依存树 。其中,依存树y的得分需要通过评分函数score(x, y)计算。
。其中,依存树y的得分需要通过评分函数score(x, y)计算。
一个完整的图解码依存分析器由三个部分组成:评分模型、分析算法和学习算法。
评分模型计算候选依存树的得分,评分模型给出得分的高低反映了依存树正确性的高低。
分析算法则根据评分模型给出的得分,从众多候选依存树中找出得分最高的依存树,并把该依存树作为句子的分析结果输出。
在数据驱动的算法中,合理的评分模型需要通过一定的学习算法从作为统计样本的依存树库中学习得到。
在图解码依存分析方法中,评分模型的设计和选择居于核心位置。
深度图解码分析模型采用低维稠密的特征表示,基于神经网络的非线性评分模型,依靠模型的自我特征学习能力,来自动学习远距离依存的特征。
(1)评分模型
深度图解码依存模型基本采用一阶分解策略,因而评分模型形式上可写为:
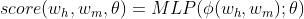
其中,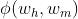 代表依存边
代表依存边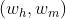 的特征表示,θ代表需要通过训练学习来获取的网络模型参数。
的特征表示,θ代表需要通过训练学习来获取的网络模型参数。
1)Pei等人最早使用多层感知机作评分模型:
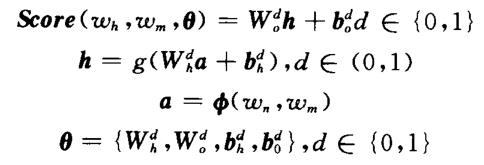
该评分模型是一个单隐层的多层感知机模型,特征向量a首先经过一个非线性的隐层变换得到特征的隐层表示h,再经过一个全连接的线性输出层得到依存边的得分向量。
此时计算出的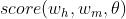 是一个|L|维向量,即
是一个|L|维向量,即 ,其中|L|代表依存关系标签的数量。该向量的第i维的值即为依存边类型为
,其中|L|代表依存关系标签的数量。该向量的第i维的值即为依存边类型为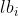 的得分。
的得分。
隐层中的非线性激活函数g可以用常规的sigmoid函数、tanh函数等。为了更好地对特征之间的交互作用进行建模,Pei等人提出tanh-cube的特殊激活函数:
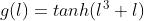
该函数可以很好地模拟传统模型中的组合特征效果,使得人们在设计特征时只专注于设计一些基本特征,而将组合特征的选择和学习交由神经网络模型自行学习决定。
Pei等没有把依存边方向作为特征进行建模,而是在隐层和输出层均采用了与方向相关的变换参数。
2)Kiperwasser等人同样采用单隐层的多层感知机模型,没有采用与方向相关的模型参数,对于左向边和右向边,模型共享同样的参数,激活函数使用tanh。把依存标签的预测与依存边的预测分开进行,首先进行无标签依存分析,然后再通过另一个多层感知机计算依存标签的得分。因为经过无标签依存分析后,无须对所有可能的依存边进行标签预测,从而可以提高运行效率。评分模型:

3)Dozat等人受到双线性注意力机制模型的启发,提出了一种基于双仿射变换的评分模型。采用了将依存边预测和依存关系标签预测分开进行的策略。评分模型:
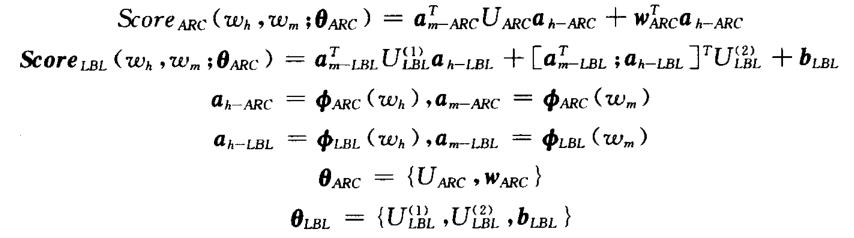
在双仿射变换模型中, 以及
以及 分别代表中心词
分别代表中心词 和依存词
和依存词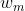 的特征向量表示。针对依存边预测和关系标签预测,Dozat等人采用了不同的特征表示。从形式上看,双仿射映射函数中的
的特征向量表示。针对依存边预测和关系标签预测,Dozat等人采用了不同的特征表示。从形式上看,双仿射映射函数中的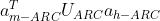 可以显示捕捉中心词和依存词特征之间的交互作用。同时,Dozat等人也认为
可以显示捕捉中心词和依存词特征之间的交互作用。同时,Dozat等人也认为 可以用来捕捉中心词所能拥有的依存词的先验分布信息,因为如果中心词的类型不同,其所能拥有的依存词的数量也会不同,例如,动词倾向于拥有更多的依存词,而虚词则倾向于没有依存词。与之类似,标签评分函数中的偏置项
可以用来捕捉中心词所能拥有的依存词的先验分布信息,因为如果中心词的类型不同,其所能拥有的依存词的数量也会不同,例如,动词倾向于拥有更多的依存词,而虚词则倾向于没有依存词。与之类似,标签评分函数中的偏置项 也可以用来捕捉类别标签的先验分布规律,因为并非所有的标签类别都按照同样的规律出现。另外,
也可以用来捕捉类别标签的先验分布规律,因为并非所有的标签类别都按照同样的规律出现。另外,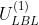 是维度为
是维度为 的张量矩阵,
的张量矩阵, 是维度为
是维度为 的矩阵,因为标签得分需要针对标签集中的每个标签进行。
的矩阵,因为标签得分需要针对标签集中的每个标签进行。
(2)深度特征提取
除了在评分模型上的改进外,深度图解码依存分析模型也展现出了优秀的特征表达和学习能力。深度图解码依存分析的特征表示不再采用高维稀疏表示,而是采用低维稠密的特征表示;而且深度模型的特征学习能力极大减轻了人工特征工程工作。
1)特征的低维嵌入表示
在传统的图解码依存分析模型中,特征表示为高维稀疏向量,特征之间相互独立。这种特征表示方法无法捕捉特征之间的共性,也存在严重的数据稀疏问题。
在深度图解码依存分析模型中,特征被映射为低维空间中的稠密向量,句法和语义性质相近的特征被嵌入到空间中邻近的位置,使其在向量表示上呈现出共性或相似性。
具体而言,令D代表所有特征组成的集合,即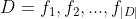 ,其中的每个特征
,其中的每个特征 均被表述为一个嵌入向量
均被表述为一个嵌入向量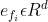 ,所有特征向量堆叠即可形成一个嵌入向量矩阵
,所有特征向量堆叠即可形成一个嵌入向量矩阵 。该矩阵的每一列对应着一个特征的嵌入向量表示。特征的嵌入向量并不需要人为设定,而是作为模型参数的一部分,同评分模型一起经由模型训练自动习得(即嵌入层)。一般而言,在训练开始时,这些特征向量可通过随机初始化的方式设定初值,并随同评分模型一起训练并最终得到特征的合理嵌入表示。但对于一些取值为词的特征,也常常采用word2vec、Glove等标准词向量学习技术基于大规模未标注语料预先学习词向量,并把得到的词向量用作特征向量的初值,一般把这种做法称作预训练(pre-training)机制。大部分研究都表明,引入预学习机制有助于改善特征向量学习的质量,从而对依存分析结果产生积极影响。
。该矩阵的每一列对应着一个特征的嵌入向量表示。特征的嵌入向量并不需要人为设定,而是作为模型参数的一部分,同评分模型一起经由模型训练自动习得(即嵌入层)。一般而言,在训练开始时,这些特征向量可通过随机初始化的方式设定初值,并随同评分模型一起训练并最终得到特征的合理嵌入表示。但对于一些取值为词的特征,也常常采用word2vec、Glove等标准词向量学习技术基于大规模未标注语料预先学习词向量,并把得到的词向量用作特征向量的初值,一般把这种做法称作预训练(pre-training)机制。大部分研究都表明,引入预学习机制有助于改善特征向量学习的质量,从而对依存分析结果产生积极影响。
2)组合特征的自动学习
传统图解码依存分析模型的子图评分模型为基于特征的线性模型,特征之间相互独立。为了捕捉特征与模型评分之间的非线性关系,需要加入组合特征,即把多个基本特征组合起来作为新的特征。组合特征的引入增加了特征工程的难度,同时也爆炸地扩大了特征空间,增大了数据稀疏的风险和特征提取的时空代价。
Pei等人在图解码模型中取消设置组合特征,只使用数量有限的基本特征(原子特征)。特征之间的交互影响通过打分模型中非线性机制加以学习体现。模型输入特征是若干原子特征,形式上是这些原子特征向量的拼接向量:

激活函数为之前提到的tanh-cube函数,这个函数不仅表现出较强的组合特征学习能力,而且能加快模型训练的收敛速度。
取消组合特征可以在使用较少的特征模板情况下达到更高的分析精度与更快的分析速度。
3)基于LSTM模型的特征学习
Wang等人、Kiperwasser等人以及Dozat等人的模型中,首先通过双向LSTM模型生成句中词的双向LSTM编码向量,并用学到的编码向量取代人工特征用作评分模型的依据。
正向LSTM模型,是从一个从左向右对序列编码,捕获了之前的语境信息;逆向LSTM模型,从右向左对序列进行编码,捕获了之后的语境信息。
若待分析的句子为 ,相应的词类序列为
,相应的词类序列为 ,
, 以及
以及 所对应的嵌入向量为
所对应的嵌入向量为 和
和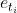 。采用双向LSTM编码机制可以表示为如下形式:
。采用双向LSTM编码机制可以表示为如下形式:

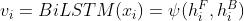
首先将句子中词及其词类的嵌入向量
。在正向LSTM编码和逆向LSTM编码向量的组合方法上(即
),可以采用传统的拼接方式或是两个向量相加的方式,也可以使用ReLU网络对其进行处理。
经由双向LSTM编码得到的编码向量与一般的孤立词向量不同,结合了词在句子中的语境信息,深度图解码依存分析模型将其视作是对词的全局特征表示,可以用来取代传统模型中由人工设计的特征。
Wang等人设计的双向LSTM编码机制:
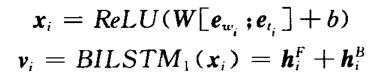
首先将句子中词及其词类的嵌入向量和拼接起来,通过一个单层ReLU网络变换为双向LSTM模型的输入向量。正向LSTM编码和逆向LSTM编码向量的组合通过将两个向量相加来实现。
Kiperwasser等人设计的双向LSTM编码机制:
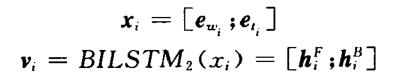
Kiperwasser等人对词和词类的嵌入向量、正向LSTM编码向量和逆向LSTM编码向量均采用传统的拼接方式。
Dozat等人让正向LSTM编码向量和逆向LSTM编码向量的拼接向量通过一个单层ReLU变换,将其转换成一个维度较低的向量。这样做可以缩减维度,也可以摈弃一些噪音信息。这种加入ReLU变换层的双仿射模型称为深度双仿射模型。在进行单层ReLU变换时,Dozat等人对依存边预测和标签预测的双向LSTM编码使用了不同的变换参数。做法为:
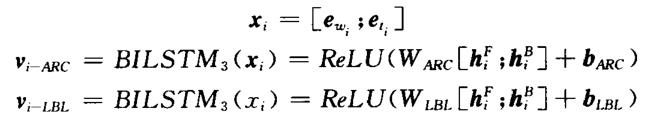
(3)模型训练
传统图解码依存分析大多采用最大化间隔原则的训练方法,深度图解码依存分析模型训练基本延续了这一训练原则。给定训练实例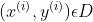 ,其中,D代表训练集,
,其中,D代表训练集, 是句子
是句子 的正确依存树,令
的正确依存树,令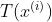 代表句子所有可能的依存分析树。最大间隔原则的目标是寻求一组最佳模型参数θ,使得对于而言,其正确依存树的得分比错误依存树得分至少大一个间隔,且该间隔的大小正比于错误依存树的结构损失
代表句子所有可能的依存分析树。最大间隔原则的目标是寻求一组最佳模型参数θ,使得对于而言,其正确依存树的得分比错误依存树得分至少大一个间隔,且该间隔的大小正比于错误依存树的结构损失 ,即:
,即:

错误依存树的结构损失通常定义为:
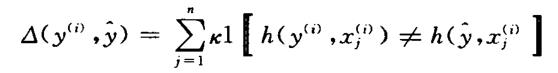
其中,n指句子的单词数量,k是比例参数。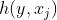 代表句子中第j个词在依存树中所对应的中心词,函数 1[r] 的值:若r为true则函数值为1,否则为0.结构损失实际上统计了依存树相对于正确依存树的错误依存边数量,让间隔正比于结构损失可以增加对错误严重的依存树的惩罚力度。
代表句子中第j个词在依存树中所对应的中心词,函数 1[r] 的值:若r为true则函数值为1,否则为0.结构损失实际上统计了依存树相对于正确依存树的错误依存边数量,让间隔正比于结构损失可以增加对错误严重的依存树的惩罚力度。
给定m 个句子组成的依存树库,基于最大间隔原则的依存分析模型训练可表述为如下的优化问题:

在具体实现时,还可以在优化函数中增加不同的正则项,以使参数具有一些人们期望的性质。
该优化问题可以选择不同的优化算法加以实现,深度学习模型中惯常使用梯度下降算法或变种(AdaGrad算法、Adam算法)。最大间隔训练方法并非图解码依存分析模型训练的唯一方法,常见的优化原则还包括交叉熵原则。
2、基于转移的依存句法分析(Transition-based)
基于转移的依存句法分析的基本模型如上述决策式句法分析模型的典型代表移进-归约状态转移模型,下面介绍基于前馈神经网络的基于转移依存句法分析:
(1)模型结构
基于转移的分析过程的格局C可以用一个三元组(S,I,A)来表示,S 是堆栈,I 是未处理的结点序列,A 是依存弧集合。用于分析动作决策的特征向量即取自这样的三元组。基于前馈神经网络的模型利用一个神经网络对分析过程中的C提取特征,并训练动作分类器。具体地,模型由输入层、嵌入层、隐含层和softmax 层组成:
1、输入层。输入层的作用是从分析状态(S;I;A) 中抽取元特征(atomic feature),这些元特征包括词特征、词性特征和依存弧特征。
2、嵌入层(embedding layer)。嵌入层由三个独立的子嵌入层组成,分别为词嵌入层、词性嵌入层和依存弧嵌入层,对应输入中的词特征、词性特征和依存弧特征。这些嵌入层的作用是将输入层抽取的离散稀疏特征转换成稠密特征。
3、隐含层。隐含层从嵌入层获得三种稠密特征输入,并对其做非线性变换。
4、softmax 层。与其他softmax 层的作用相同,该层用于预测多分类的结果。

(2)元特征
以前的基于特征工程的依存句法分析器过于依赖于专家定义的特征集合,因此研究人员为基于转移的依存句法分析方法定义了一组特征模板(见下表),这组特征显著提高了依存句法分析器的性能。这些特征被分成了三类:词特征(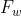 ),词性特征(
),词性特征( )和弧特征(
)和弧特征(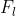 )。各个特征所代表的含义为:
)。各个特征所代表的含义为:
1、 表示栈S中的第i个词;
表示栈S中的第i个词;
2、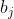 表示输入缓冲I中的第j个词;
表示输入缓冲I中的第j个词;
3、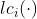 表示取词的第i个左儿子;
表示取词的第i个左儿子;
4、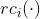 表示取词的第i个右儿子。
表示取词的第i个右儿子。
在上表中, 即为栈S中的第0个词,即栈顶的单词;
即为栈S中的第0个词,即栈顶的单词; 为输入缓冲I中第二个词;
为输入缓冲I中第二个词; 即为栈顶词的第一个左儿子;
即为栈顶词的第一个左儿子; 即为栈顶词的第二个左儿子。可以注意到:元特征模板中并不包含输入缓存中的词的儿子信息,因为输入缓存中的词尚未被分析,其没有儿子节点。
即为栈顶词的第二个左儿子。可以注意到:元特征模板中并不包含输入缓存中的词的儿子信息,因为输入缓存中的词尚未被分析,其没有儿子节点。
将以上位置信息分别与w (word embedding),p (pos) 或l (link)组合,即可得到不同位置上的词特征、词性特征或依存弧特征。例如,

 表示
表示 最右儿子的词特征;
最右儿子的词特征;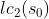 表示最左儿子的词性特征。
表示最左儿子的词性特征。
(3)执行过程
1、依存算法:
在执行过程中,模型采用标准的移进-归约算法(arc-standard方法),即:
• SHIFT:将从buffer I 中弹出,并将其压入栈S.
• LEFT-ARC(l):在栈顶第一个词与第二个词之间添加一个弧l,将从栈S中删除。将弧() 添加到A 中。
• RIGHT-ARC(l):在栈顶第二个词与第一个词之间添加一个弧l,将从栈S中删除。将弧()添加到A 中。
2、学习算法与分类模型:
作为一个依存句法分析器的重要组成部分,分类模型的作用为预测分析动作,学习算法的作用为从训练数据中学习模型的参数。
神经网络的输入层直接从分析格局C中抽取元特征。元特征的抽取如上图定义的特征。从表中可以看到,抽取的特征三个部分特征分别为18 个词特征、18 个词性特征和12 个依存弧特征。在分析过程中的每一步,输入层将从分析格局中抽取这些总共48 个特征,并对这48 个特征以词袋(bag of words)模型进行表示(即元素存在的位置为1,不存在的位置为0)。
网络嵌入层的作用为将特征的稀疏表示转换成稠密表示。嵌入层分为三个部分:词嵌入层、词性嵌入层和依存弧嵌入层;这三个嵌入层分别从对应的三种输入层中获取特征(将BOW向量中元素为1的位置,置换成为相应的元素向量:如前18个词特征位,若有元素为1,则置换为该位置上词的word embedding;同理对于中间18个词性特征位和后12个依存弧特征位),得到48个特征向量。常识上,与词典大小相比,词性与依存弧弧的取值集合相对较小,故嵌入层中词性嵌入和弧嵌入的维度小于词嵌入的维度。
模型中的隐含层将嵌入层的48 个特征向量进行首尾连接操作(也可以进行其他形式的feature fusion),将其组成一个特征向量。对特征向量进行线性与非线性变换操作,,为偏置。
最后一层,为网络的输出层,使用softmax函数对转移动作进行分析和预测:,,是指依存句法分析系统中所有动作的集合,p是针对集合中每个元素的概率向量。
基于循环神经网络的Transition-based dependency模型:
基于循环神经网络的方法,和基于前馈神经网路的方法非常相似。实际上,在使用中,基于循环神经网络的方法更受欢迎,因为转移动作序列正好符合循环神经网络的时序处理优点。
在应用循环神经网络时,每个时刻仍然是上述的输入层、嵌入层、隐含层等处理内容,只是会根据应用有所变化。转移动作序列,展开成时间序列处理。
以上是关于依存句法分析综述的主要内容,如果未能解决你的问题,请参考以下文章