perf工具_嵌入式设备_性能分析
Posted 努力努力再努力~~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了perf工具_嵌入式设备_性能分析相关的知识,希望对你有一定的参考价值。
【摘要】嵌入式产品一般都会将CPU、内存在最大压力下压榨至极限;假如现在产品遇到了一个问题,CPU idle非常低,领导交给你解决,我们应该如何分析CPU的占用是否合理,并且从什么方面开始优化呢?Linux下有一个非常好用的工具,叫做perf。
perf工具介绍的文档有很多,但是都只局限于如何使用perf,并且没有文章是针对嵌入式设备,本文主要介绍perf在嵌入设备,在真实工作产品化项目中,集成perf过程中遇到的问题和踩过的坑,指导你如何用perf来分析并解决CPU idle为0的问题。
主要包含一下几个方面
- 嵌入式设备如何集成perf
- perf常用的命令
- perf使用过程中遇到的各种异常问题【重点】
- 如何将perf生成的产物转换为直观的火焰图【重点】
- 火焰图分析【重点】
由于我们产品的开发涉及到很多部门,库、驱动非常多,集成perf可能需要涉及到的所有驱动重新编译,所以,并不是一旦遇到性能问题就集成perf工具,在集成perf之前还是应该做一些简单的分析,如果Top都能简单确认是哪个线程导致的CPU占用很高,那么就无需集成perf工具了。
简单分析方法:
- top:-h查看是哪个线程,针对线程结合代码分析
- cat /proc/cpuinfo:查看cpu MHZ,是否设备温度过高导致降频了
- 等 后续其他章节会介绍
目录
1. 开启内核配置
perf本身是集成在linux内核中的,所以在嵌入式设备使用perf工具,需要配置内核支持perf
- CROSS_COMPILE:后面跟对应的交叉编译工具链
cp arch/arm64/configs/hisi_defconfig .config make ARCH=arm64 CROSS_COMPILE=aarch64-mix410-linux- menuconfig
- 选项开启
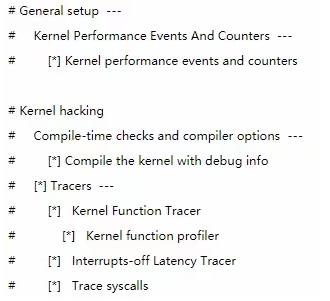
- 拷贝配置
cp .config arch/arm64/configs/hisi_defconfig- 重新编译内核
- 重新烧写内核镜像
2. 编译用户态perf工具
在kernel目录下,执行下面命令:(perf工具在内核目录下:src/tools/perf)
- WERROR=0:如果不加可能编译失败,将警告当作报错
- CROSS_COMPILE:跟指定的交叉编译工具链
cd src/tools/perf
make ARCH=arm64 CROSS_COMPILE=aarch64-mix410-linux- WERROR=0 perf编译完成后会在perf目录下生成一个名为perf的二进制文件,可以将这个文件拷贝至嵌入式设备使用
3. 重新编译业务驱动
由于内核选项更改,内核结构体等会发生变化(如:task_struct进程描述符中,有一些perf相关的成员在内核配置开启perf之后会编译进去,头文件发生变化),所有业务驱动也需要重新编译链接;(这一步着重强调,所有涉及到ko驱动都需要重新编译,否则在用户态程序执行之后执行perf,会出现莫名其妙的内核态死机;切记)
4. Perf工具的常用方法
将编译好的perf上传到嵌入式设备,即可使用perf。
如:
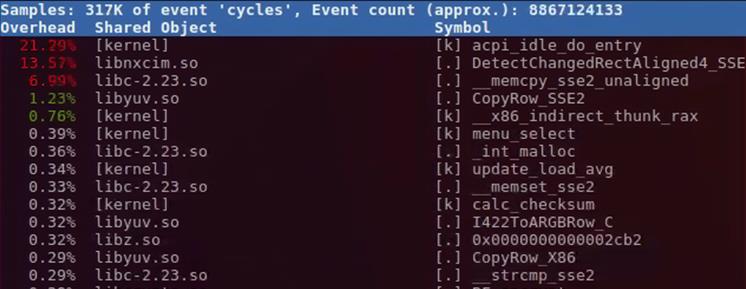
1. 实时显示系统和进程的性能统计信息:perf top (公司业务保密性,下图为网上dump)
第一列:符号引发的性能事件的比例,默认指占用的cpu周期比例。
第二列:符号所在的DSO(Dynamic Shared Object),可以是应用程序、内核、动态链接库、模块。
第三列:DSO的类型。[.]表示此符号属于用户态的ELF文件,包括可执行文件与动态链接库)。[k]表述此符号属于内核或模块。
第四列:符号名。有些符号不能解析为函数名,只能用地址表示。
2. 分析系统和进程的整体性能概况:perf stat
- task-clock:任务真正占用的处理器时间,单位为ms。CPUs utilized = task-clock / time elapsed,CPU的占用率。
- context-switches:上下文的切换次数。
- CPU-migrations:处理器迁移次数。Linux为了维持多个处理器的负载均衡,在特定条件下会将某个任务从一个CPU迁移到另一个CPU。
- page-faults:缺页异常的次数。当应用程序请求的页面尚未建立、请求的页面不在内存中,或者请求的页面虽然在内存中,但物理地址和虚拟地址的映射关系尚未建立时,都会触发一次缺页异常。另外TLB不命中,页面访问权限不匹配等情况也会触发缺页异常。
3. 记录一段时间内系统的性能信息并保存在perf.data文件中:perf record
- 如:perf record -a -F 99 -g sleep 10
- 注意:生成的perf.data是无法直接查看的,需要使用perf report解析
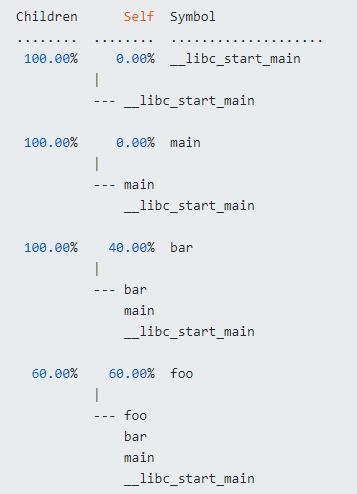
4. 读取perf.data文件并显示信息:perf report
- 如:main函数占用100%的CPU,main函数中bar函数占用40%CPU,foo函数占用60%CPU
5. 常用参数选项
-a, --all-cpus 显示所有CPU上的统计信息
-C, --cpu <cpu> 显示指定CPU的统计信息
-p, --pid <pid> stat events on existing process id
-t, --tid <tid> stat events on existing thread id6. 常用指令
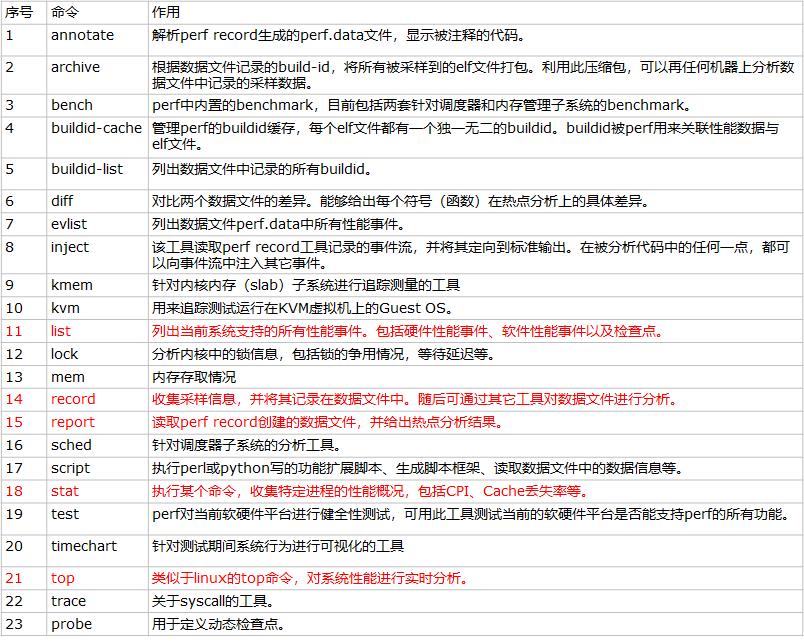
更多命令请参考perf工具相关资料:
5. 制作火焰图_flamegraph
火焰图可以更直观的看到函数的调用关系和系统性能,可以通过perf工具和flamegraph工具制作出来。
flamegraph为开源工具,可以从以下网址下载源码包:
https://github.com/brendangregg/FlameGraph https://github.com/brendangregg/FlameGraph火焰图的制作过程如下:
https://github.com/brendangregg/FlameGraph火焰图的制作过程如下:
1. perf record -a -F 99 -g sleep 10(-a参数为抓取所有cpu,-F 99设置采样频率,sleep 10抓取时间为10秒)
2. perf script > out.perf
3. 将生成的out.perf文件拷贝到flamegraph源码包目录中。
4. ./stackcollapse-perf.pl out.perf > out.folded
5. ./flamegraph.pl out.folded > out.svg
6. 使用谷歌浏览器或者Edge浏览器打开out.svg,即可看到火焰图。效果如下: (由于公司业务保密性,下图是从网上dump的)
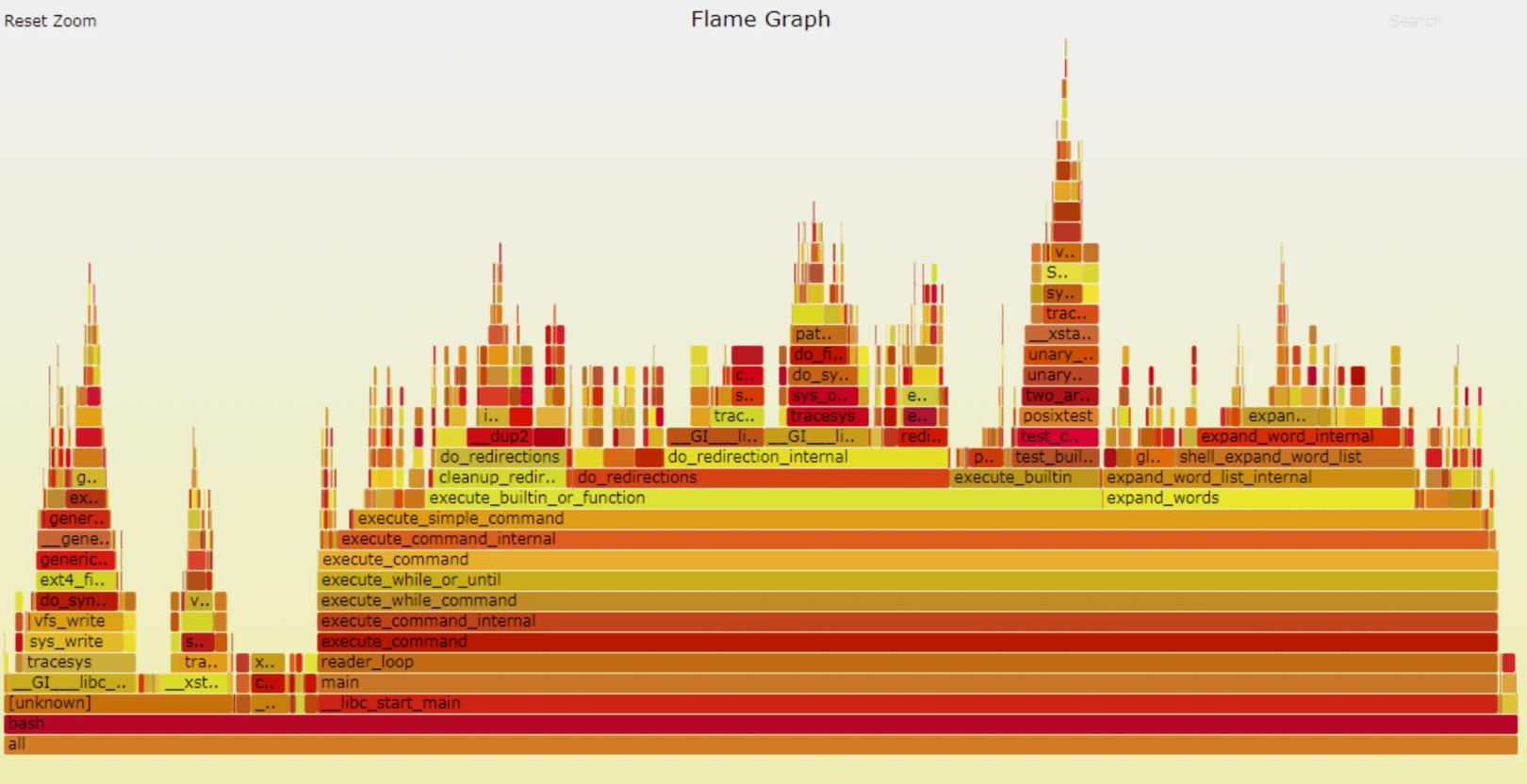
如何查看火焰图:(简单来说只需要了解下面几点)
- 颜色没有任何含义,就是方便阅读
- 从下自上是函数调用堆栈
- 宽度表示CPU占比,越宽的CPU占用越多,一般需要优化的是顶部宽的部分
- 点击可以放大某一个函数
- 左上角Reset Zoom可以还原放大
- 横轴没有时间关系
详细的介绍可以自行百度:
6. perf集成遇到的问题以及解决办法
perf集成中,遇到最麻烦的问题就是符号解析不出,解决了很多问题才最新将符号显示出来。
6.1内核态符号解析异常问题处理
1、内核没有使用-g编译
2、内核被strip过了
6.2用户态台符号解析异常问题处理
1、perf工具需要重新编译,不加下面库可以编译出工具,但是用户态符号无法解析 (这点很关键,当时我在项目上使用时排查了很久看了很多资料才发现这个问题)
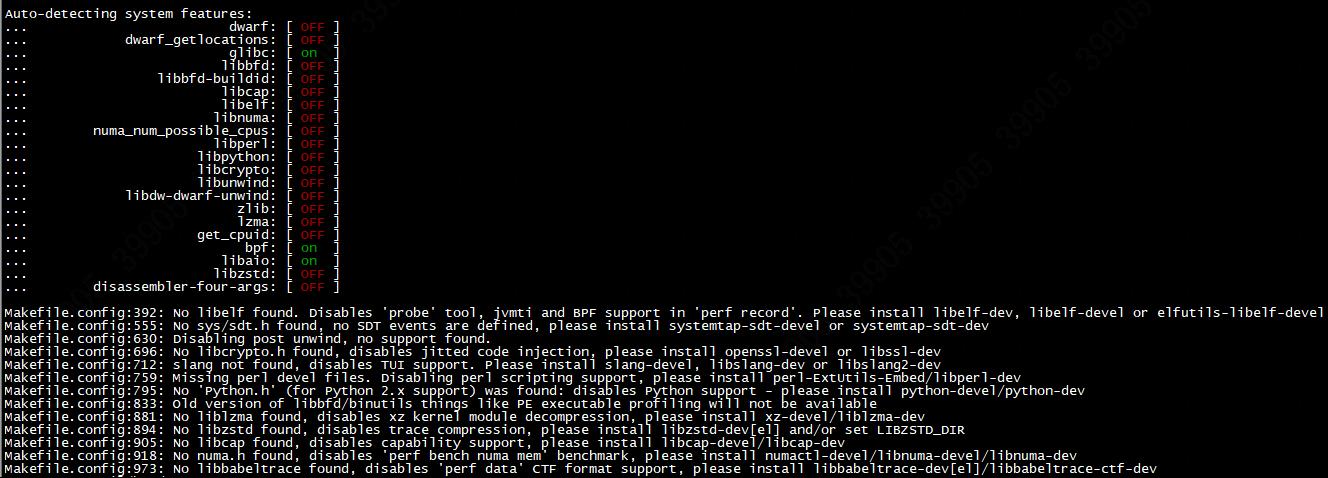
- 其实在perf编译的过程中是有打印提示的,如下图所示:
2、执行程序需要-g并且不能被strip
3、依赖的所有动态库需要是debug版本:包括libc
4、可以试试perf使用时加上选项:--call-graph dwarf
5、去除栈帧优化:编译时打开增加编译选项-fomit-frame-pointer
6.3其他
除了符号问题,当时遇到一个内核死机,也是困扰了我们较长实践,后面无意间发现,有些加载的驱动没有基于内核开启perf配置之后重新编译。
- 并且该死机很难从死机日志上看出什么,因为是头文件等不配套导致的
- 所以在前面重点强调,内核支持perf之后,所有的驱动必须重新编译
7. 实战
7.1生成火焰图
首先执行下面命令生成火焰图
嵌入式设备执行:
perf record -a -F 99 -g sleep 10
perf script > out.perf
./stackcollapse-perf.pl out.perf > out.folded
服务器执行:
./flamegraph.pl out.folded > out.svgout.svg通过谷歌或其他浏览器打开,根据章节5所述进行分析,火焰图这里就不放了,因为是公司项目,涉密
7.1CPU占比高原因
结合项目说明perf最终帮助我们定位了哪些CPU高占用问题:(但是由于是公司项目,不会深入说,简单概括)
1、Mktime接口调用
用于业务原因,我们会频繁调用该接口,该接口CPU占用很高;具体原因大家可以百度一下;我们是重新实现了一个纯用户态功能相同的接口替代该接口调用。
具体可参考一下其他文章:glibc里mktime函数的严重性能问题 – 铸剑
解决办法:mktime很慢就自己去实现一个吧 - _Leo_H - 博客园
2、memcpy、memset等接口
使用memcpy、memset操作大块内存会导致CPU占用较高
解决办法:去掉无效的memset,使用地址传递,减少memcpy的次数
3、公司公共模块封装的链表
由于链表非常大,每次查找空闲链表填充数据都非常慢
解决:记录上一次空闲位置的下一个节点,先从上一次空闲的下一个节点开始遍历,如果都不为空,或者next节点为NULL,再从头重新遍历
4、for、while循环次数过多
由于代码设计不合理,随着时间的推移,某个循环的次数会越来越多,运行时间越久,CPU占用越多
5、开源库使用debug版本
由于开源库使用的debug版本,该开源库debug版本会频繁的调用open、close、write、read等系统调用,频繁的系统调用导致CPU占比很高;
解决:将开源库编译为非debug版本
6、实时线程太多了,导致某些线程抢占不到CPU,因此跑在这些非实时线程的业务就会出现卡顿等异常
8. 其他参考
系统级性能分析工具perf的介绍与使用 - ArnoldLu - 博客园
以上是关于perf工具_嵌入式设备_性能分析的主要内容,如果未能解决你的问题,请参考以下文章