Android 音视频编解码 -- 视频编码和H264格式原理讲解
Posted 夏至的稻穗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android 音视频编解码 -- 视频编码和H264格式原理讲解相关的知识,希望对你有一定的参考价值。
Android 音视频编解码(一) – MediaCodec 初探
Android 音视频编解码(二) – MediaCodec 解码(同步和异步)
前面学习了 MediaCodec 的基本原理,以及如何解码,在学习MediaCodec 编码之前,先来学习视频是如何编码的,以及最常用的 H264。
这一章偏文字理论,但非常重要,希望沉下心来慢慢看。
说到视频,第一印象就是占内存,我们知道视频是由一连串图像组成的,假设我们现在有一个视频,1080p(1920x1080) ,帧率是25帧,时长是2个小时,如果不进行压缩的话,它的大小为 1920x1080x25x2x60x60x1.5≈260.7G 。如果我们不对视频进行压缩的话,任何存储设备都存储不了几部电影,更别说在线电影了,带宽根本撑不住。
一. 视频编码原理
前面说到,视频是一帧帧的图像,因此编码也是对图像的编码,而图像一般是 RGB,即红蓝绿三个分量来组合成所有颜色。但是 RGB 对编码不太友好,因此通常会使用 YUV 的图像格式来进行编码,Y 表示亮度,UV表示色彩空间。人眼对亮度信息敏感,对色度信息稍弱,因此我们对图像进行不同的编码。具体YUV与RGB的信息,可以查看Android OpenGL ES 学习(十一) –渲染YUV视频以及视频抖音特效
对于每一帧图像,又可以划分成一个个块来编码,不同编码类型对块的解释不通,但基本相同,如 H264 中图像块被叫做宏块,宏块的大小一般为 16x16(H264),32x32(H265,VP9)等。
二. 编码模式
图像一般具备数据冗余的,因此我们可以根据此特性去做一些操作,减少图像的数据量,比如 Bitmap 压缩,我们可以修改它的缩放因此,适配空间大小,达到压缩空间省内存的效果,视频同样如此,去除冗余的方式有:
- 空间冗余:相邻像素具备相似性
- 时间冗余:相邻帧的内容往往很相似,两张图像变化很小,相似性很高
- 视觉冗余:人眼睛对高频信息敏感度低于信息,比如眼睫毛,因此可以去除高频信息
- 信息熵冗余:我们一般会使用 Zip 等压缩工具去压缩文件,将文件大小减小,这个对于
图像来说也是可以做的。
视频编码就是通过上述4中冗余来达到视频压缩的目的。更多视频压缩信息,可以参考极客学院-视频怎么编码的
而 H264 就是针对以上冗余信息进行算法编程,达到视频压缩的。
三. H264 简介
视频编码标准其实有很多,而大名鼎鼎的就是 H264 了,可以说是最常用,最普遍的视频编码格式。其实除了H264,还有H265,H264和H265都是国际标准化组织(ISO)和国际电信联盟(ITU)开发的编码标准,而VP8、VP9 和 AV1是谷歌开发的编码标准,H264 和 H265 是需要专利费的,所以VP8、VP9 和 AV1(都是免费)也是谷歌为了对抗他们高昂专利费而开发出来的。
上面讲到了视频编码的原理,这里我们通过H264来了解视频编码中的码流结构,以及H264 是如何解决4中冗余信息的。它的主要步骤为:
- 帧内预测:解决空间冗余问题
- 帧间预测:解决时间冗余问题
- DCT变化和量化:解决视觉冗余问题
3.1 帧内预测 - 如何减少空间冗余
前面说到,帧内预测是为了解决空间冗余问题,我们知道,一幅图像中相邻像素的亮度和色度信息是比较接近的,并且亮度和色度信息也是逐渐变化的,不太会出现突变。也就是说,图像具有空间相关性,帧内预测就是按照这个特点来进行的。
比如这张蓝色,它相邻的像素的亮度和色彩就是相似。

所以帧内预测就是利用已经编码后的相邻像素的值,来预测待编码的像素值,从而达到减少空间冗余的目的。
你可能会奇怪,已经编码过的像素,不是变成码流了吗,怎么还能去预测待编码的像素的。其实这个已经编码的像素是会重建成重建像素,用做之后待编码快的参考像素的。
不同块大小的帧内预测模式
这里不打算深入讲,因为要深入讲的话,得重新开一章才行,这里我们简单了解一下即可。
前面说到,视频编码是以块为单位的。在H264的标准里面,块可以分为宏块和子块,宏块的大小是 16x16 (YUV 4:2:0 ,Y 为16x16,UV 为 8x8),在帧内预测中,图像除了相似的地方,还有更细节的部分,如蓝色天空的一朵云,因此,Y 宏块还可以分成16个 4x4 的子块

Y 与 UV 的预测是分开进行的,因此,我们可以总结三个点:
- 宏块大小为 16x16,Y 为16x16,UV 为 8x8
- Y 和 UV 块是分开独立进行预测的,即Y会参考已编码Y块的像素,UV 会参考已编码的UV块像素
- 16 x 16 的Y块可以继续划分成 16 个 4 x 4 的子块。
所以,我们在实际帧内预测的时候就会分为:4 x 4 Y块的预测、16 x 16 Y块的预
测、8 x 8 UV块的预测.
实际上,4x4的字块中,帧内预测的模式最多,共有8个,其中有8个方向模式和一种DC模式,且方向模式指的是预测是有方向角度的。这里涉及到具体的编码算法,就不展开,若感兴趣,可参考极客学院-帧内预测
3.2 帧间预测 - 如何减少时间冗余
这里也不深入,主要连接P帧,B 帧的概念即可
前面说到,时间冗余是指相邻两帧画面相似的地方比较多,前后两帧图像变化很小,比如帧率30,1秒内有30张图像,如果是连续变化,两帧的图像其实变化往往很小,这就是相关性,帧间预测,就是利用这个特点来进行算法编码的。即:
通过在已经编码的帧里面找到一个块来预测等待编码块的像素,从而达到减少时间冗余的目的。
注意这里和帧内预测的区别:
- 帧内预测是同张图像,等待编码的块去参考已编码的块像素;而帧间预测,则是等待编码的图像去参考已经编码的图像像素块。
- 帧间预测可以在多个已经编码的图像里,去寻找参考像素块,也可以是单个。
- 帧间预测,即可以参考前面的图像,也可以参考后面的图像(如果参考后面的图像,后面的图像也需要提前编码)。只参考前面的帧,我们成为前向参考帧 - P帧了;参考后面的帧或者前后两帧图像的帧,我们称之双向参考帧 - B帧。
这里以 H264 的标准来讲讲 P 帧的帧间预测过程,当然也是了解个大概,更详细的,参考极客学院 - 帧间预测
其实阵间预测也是通过块作为参考的,我们会在已经编码的帧里面找到一个块来作为预测块,这个已经编码的帧称之为参考帧。
那问题来了,前面说到帧间预测是图像与图像之间的参考,如果两张图像一模一样,还好理解一点,如果是有变化的呢?比如下面这张图:

可以看到,树木是不变的,但是汽车移动了,这里是怎么计算的?
从编码的角度来看,汽车是不变的,变的是运动轨迹,因此,为了表示这种变化,可以使用运动矢量来表示编码帧中编码块和参考帧中,预测块之间的位置的差值。
比如说上面两幅图像中,小车从前一幅图像中的(32,80)的坐标位置,变化到当前图像
(80,80)的位置,向前行驶了 48 个像素。很明显,如果我们选用(32,80)这个块作
为当前(80,80)这个编码块的预测块的话,是不是就可以得到全为 0 像素的残差块了?
这是因为小车本身是没有变化的,变化的只是小车的位置。
而这里的难点,在于如何找到这个最佳的参考帧,这里就涉及到运动算法。你可能会箱单,既然都分成块了,那逐行对比即可,即全局搜索,好处就是啥都能对比到,但是缺点就是一帧算下来,耗时过长,因此还需要更快速的算法。这里就不细讲,参考极客学院 - 帧间预测
3.2 变换量化 – 如何减少视觉冗余
通过前面的知识,已经知道 ,通过帧内编码可以去除空间冗余,通过帧间编码可以去除时间冗余,而为了分离图像块的高频和低频信息从而去除视觉冗余,我们需要做 DCT 变换和量化。
其实DCT 变换,就是离散余弦变化,它可以将你扛到的图像转到成数据,并能很好的去除相关性。
经过 DCT 变化之后,低频信息会集中出现在左上角,高频信息则分散到其他地方,而人又对高频信息不敏感,因此图像在经过 DCT 变化后,再去除一些高频信息,就可以达到压缩的目的。
而高频信息幅度值比较小,因此还可以使用量化的方式,即除法操作,将高频信息幅度变小,达到压缩的目的。

更多细节,参考极客学院-变化量化
四. H264
前面学习了视频编码的原理,现在来看H264,估计会简单很多。先来看看结构:

在上面的结构中,一个视频编码后的数据叫做帧,一帧由1个片 (slice)或多个片组成,一个片 又可以分成多个宏块 (MB),一个宏块又可以由多个子块组成。而宏块是H264的基本单位,前面也说到,编码基本是基于块去做参考的。
4.1 帧类型
可能平时你也接触过,H264的帧类型,可以分为 I帧,P帧,和B帧。前面的视频编码原理讲到,为了减少空间冗余和时间冗余,有涉及到帧内预测和帧间预测。
再回顾一下,帧内预测,是参考自身的宏块,帧间预测是不同帧之间的参考,即:
- 帧内预测不需要参考已编码帧,对已编码帧是没有依赖的,并可以自行完成编码
和解码。 - 帧间预测是需要参考已编码帧的,并对已编码帧具有依赖性。帧间预测需要参
考已经编码好了的帧内编码帧或者帧间编码帧。并且,帧间编码帧又可以分为只参考前面
帧的前向编码帧,和既可以参考前面帧又可以参考后面帧的双向编码帧。
因此,我们可以得出两者之间的关系:
| 帧类型 | 预测方式 | 参考帧 | 优点 | 缺点 | |
|---|---|---|---|---|---|
| I帧 | 帧内编码帧 | 只帧内预测 | 无 | 能独立编码 | 压缩率小 |
| P帧 | 前向编码帧 | 可以进行帧内预测和帧内预测 | 参考前面的I帧或P帧 | 压缩率比I帧高 | 必需参考正确的帧才能正确解码 |
| B帧 | 双向编码帧 | 可以进行帧内预测和帧内预测 | 参考前面或者后面已经编码的I帧或者P帧 | 压缩率最高 | 需要缓存帧,参考后面的帧,延时高 |
可以看到,如果编解码中,如果前面一个帧出现了错误,那么P帧和B帧肯定也会出现错误,虽然B帧也可以参考后面的帧,但一般很少用到B帧,比如只有P帧,错误就会一直传递,为了避免这种情况,就有一种特殊的I帧,叫 IDR 帧,也叫立即刷新帧。
4.2 IDR 帧
在H264的标砖中,IDR 后的帧不再参考前面的帧,这样如果一帧编码错误后,如果此时有IDR帧过来,后面的帧就只会参考这个IDR帧,就截断了错误,后面就可以正常编解码了。
所以,一般都会使用 IDR帧,而不是普通I帧。
4.3 GOP - 关键帧间隔
从一个 IDR 帧开始到下一个 IDR 帧的前一帧为止,这里面包含的 IDR 帧、普通 I 帧、P 帧和 B 帧,我们称为一个 GOP(图像组)。

所以,一个GOP的大小,是由IDR的间隔决定的,这个间隔,也叫做 关键帧间隔,关键帧越大,则IDR相关越远,GOP越大,反之亦然。
当然GOP不是越大越好,也不是越小越好,比如直播场景,由于网络等因素,你可能GOP小一些比较好,而局域网投屏,网络基本稳定,所以GOP可以设置大一些。
4.4 码流结构
前面也说到一帧图像可以划分成一个或多个 Slice,而一个 Slice 包含多个宏块,且一个宏块又可以划分成多个不同尺寸的子块。这里我们一层层去剥开它。
4.4.1 码流格式
H264 有两种格式,一种是Annexb,另一种是MP4,相同是他们都有起始码,而它们的不同是:
- Annexb: 起始码是三个字节,即 00 00 01
- MP4: 起始码是四个字节,即 00 00 00 01
因此,我们在解析H264文件时,要注意头部信息的起始码。
4.4.2 SPS/ PPS
在H264码流中,有两个很重要的信息,即sps和pps:
- sps:主要包含图像的宽高,YUV 格式和位深等基本信息
- pps:主要包含熵编码类型,基础QP和最大参考帧等编码信息
如果一段码流中,缺失了这两个部分,之后的I帧,P帧,B帧都无办法解码。
4.4.3 NALU
现在我们知道了,H264 的码流中, SPS、PPS、I 帧、P帧和 B 帧。由于帧又可以划分成一个或多个 Slice。因此,帧在码流中实际上是以 Slice 的形式呈现的。
所以,H264 的码流主要是由 SPS、PPS、I Slice、P Slice和B Slice 组成
的。如下图所示:

那如何在码流中区分这些数据呢?
为了解决这个问题,H264设计了NALU (网络抽象层单元),sps 是一个 NALU,pps也是一个 NALU单元,每一个片(Slice) 也是一个 NALU 。
它的结构组成是:
- NALU : 一个字节的 Nalu Header 加若干个字节的Nalu data 组成吗
– 如果这个NALU 是 Slice,它的data ,有可以拆分成 slice Header 和 Slice Data
– 而Slice data 由可以拆分成 MB Data,如下图:

这里主要看 NALU Header ,它是一个字节,结构如下:

这里关注 type类型,它占5个bit,表示 NALU 的类型,取值如下:

有了 NALU Type 表示,我们就可以知道了几个重要的类型,如sps 是7,pps 是8,而IDR 帧是5等等:

通过解析一段H264的码流,我们也可以看到这些信息:
SPS:

PPS:

IDR:
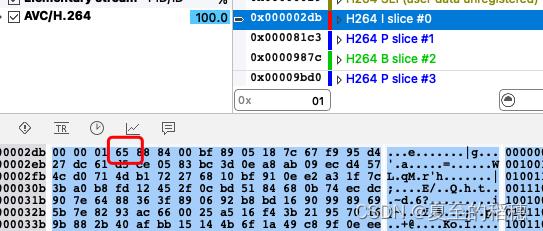
因此,我们解析H264 文件时,就可以通过起始码,00 00 01 x 或00 00 00 001 x 的方式去取出每一帧的数据,再喂给解码器,实现解码的效果。
参考:
极客学院-帧内预测
极客学院 - 帧间预测
极客学院-变化量化
以上是关于Android 音视频编解码 -- 视频编码和H264格式原理讲解的主要内容,如果未能解决你的问题,请参考以下文章