kafka的安装部署及应用
Posted -飞鹤-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka的安装部署及应用相关的知识,希望对你有一定的参考价值。
1. 介绍
1.1. 简介
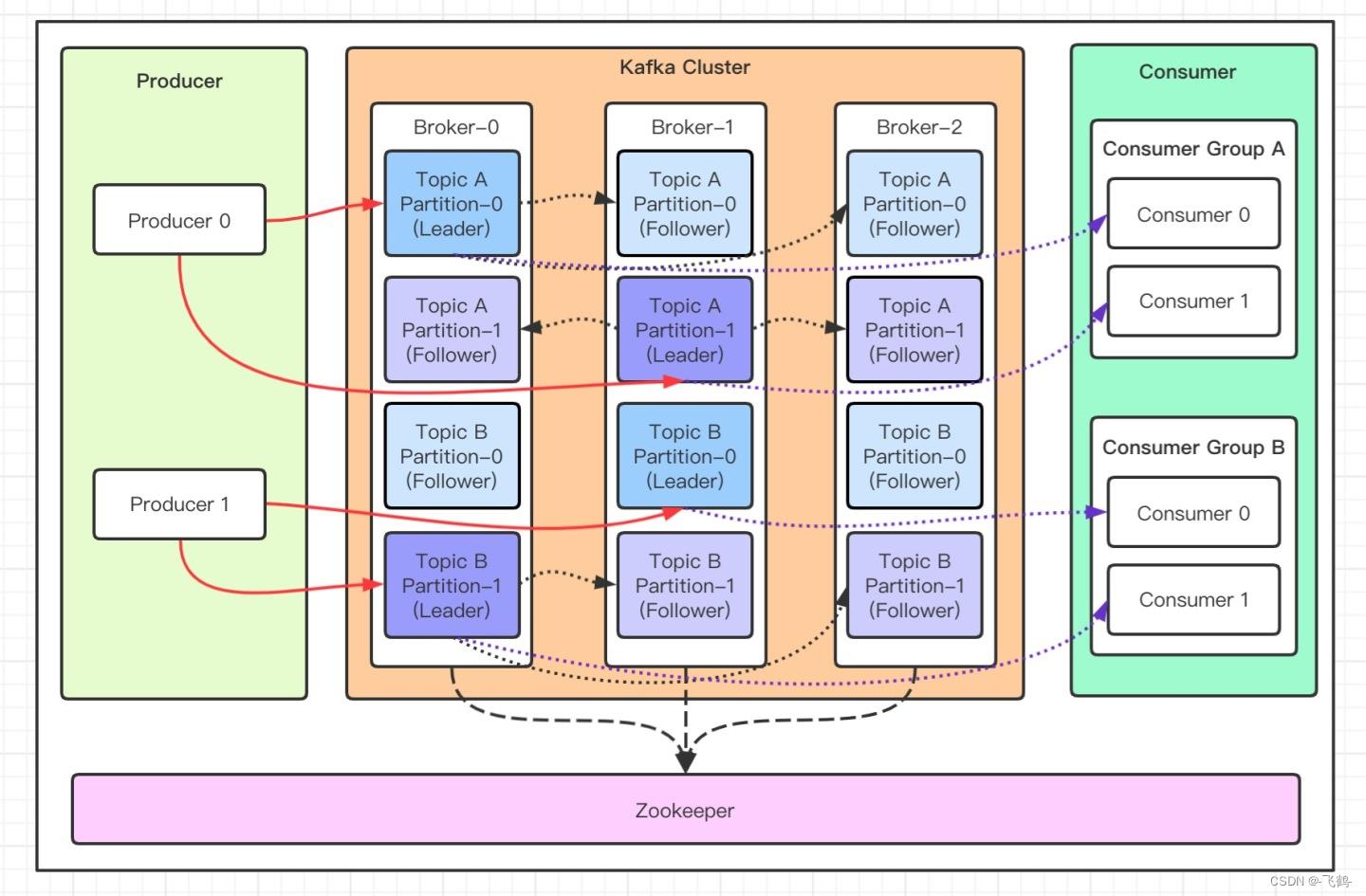
kafka是一款分布式、支持分区的、多副本,基于zookeeper协调的分布式消息中间件。其最大特性就是能够实时处理大量消息。
1.2. 基本概念
- Broker, 消息中间件的处理节点,也即服务器。一个broker一个服务器,多个broker即构成一个kafka的服务集群。
- Topic, kafka根据topic来对消息进行分类,每个发布到kafka的消息都必须指定一个topic。
- Partition,为了应对大量的topic消息,可以将topic消息分为不同的partition,并且每个partition可以分布到不同上的Broker上,达到负载均衡。Partition也可以分布在一台电脑上的不同磁盘上,可以提升磁盘的I/O响应率。
- Replication,每一个分区都可以有多个副本,用作备份,在主分区(Leader分区)数据异常时,可以将备份分区(Follower分区)设置为主分区(Leader)。
- Producer,消息生产者,也即消息发布者。
- Consumer,消息消费者,也即消费订阅者。
- Consumer group,消息订阅集群, 每个consumer都属于一个特定的consumer group,若未指定,则属于默认的group。一个group中只有一个comsumer能够消费消息。
- Zookeeper, kafka 集群依赖 zookeeper 来保存集群的的元信息,来保证系统的可用性。Zookeeper负责管理集群中的消息负载均衡,将消息分配到不同的分区,并且判断使用哪个副本作为Leader分区等。
1.3. 应用场景
- 日志收集,可以用kafka收集各种服务的日志 ,通过已统一接口的形式开放给各种消费者。
- 消息系统,解耦生产和消费,并且可以基于消息系统提供事件响应框架。
- 分布式大数据处理,基于Kafka的分布式和高性能,可以用于分布式大数据处理。
1.4. 特点
- 可靠性,kafka的传输是基于tcp的自定义协议,可以设置ack机制来保证数据数据在副本中由浅完成才返回,并且如果数据异常,默认会有3次重发机制。
- 灵活性,kafka的消费记录是以offset来控制的,即消费者可以灵活地获取想要的消息。
- 可扩展性,kafka可以非常方便地扩容服务器(Broker),而不影响原有的服务器功能。
- 高性能,Kafka采用顺序添加消息,并且采用页缓存和零拷贝技术,可以大幅提升磁盘I/O利用率。
1.5. 生产数据
kafka 每次把生产的数据发送向Leader分区,并顺序写入到磁盘,然后Leader分区会将数据同步到各个从分区Follower,即使主分区挂了,也不会影响服务的正常运行。
- 数据在写入的时候可以指定需要写入的分区,如果有指定,则写入对应的分区。
- 如果没有指定分区,但是设置了数据的key,则会根据key的值hash出一个分区。
- 如果既没指定分区,又没有设置key,则会轮询选出一个分区。
1.5.1. 三种数据发送方式
Kafka中有三种发送消息的方式:
只发不管结果(fire-and-forget):只调用接口发送消息到Kafka服务器,但不管成功写入与否。由于Kafka是高可用的,因此大部分情况下消息都会写入,但在异常情况下会丢消息。
同步发送(Synchronous send):调用send()方法返回一个Future对象,我们可以使用它的get()方法来判断消息发送成功与否。会阻塞当前线程,执行效率低,但可靠性最高。
异步发送(Asynchronous send):调用send()时提供一个回调方法,不会阻塞当前线程,当接收到broker结果后回调此方法。可靠性不如同步发送,可能因为等问题不保证100%被回调。
1.5.2. 生产者常用参数
-
acks:用来指定分区中必须要有多少个副本收到这条消息,之后生产者才会认为这条消息是成功写入的。
acks = 1, 默认值即为1.生产者发送消息之后,只要分区的leader副本成功写入消息,那么它就会收到来自服务端的成功响应。如果消息无法写入leader副本,比如在leader副本崩溃、重新选举新的leader副本的过程中,那么生产者就会收到一个错误的响应,为了避免消息丢失,生产者可以选择重发消息。如果消息写入leader副本并返回成功响应给生产者,且在被其他follower副本拉取之前leader副本崩溃,那么此时消息还是会丢失,因为新选举的leader副本中并没有这条对应的消息。acks设置为1,是消息可靠性和吞吐量之间的折中方案。
acks = 0, 生产者发送消息之后不需要等待任何服务的相应。如果在消息从发送到写入kafka的过程中出现某些异常,导致kafka并没有收到这条消息,那么生产者也无从得知,消息也就丢失了。在其他配置环境相同的情况下,acks设置为0可以达到最大的吞吐量。
acks = -1 或acks = all。 生产者在消息发送之后,需要等待ISR中的所有副本都成功写入消息之后才能够对来自服务端的成功响应。在其他配置环境相同的情况下,acks设置为-1(all)可以达到最强的可靠性。但这并不意味着消息就一定可靠,因为ISR中可能只有leader副本,这样就退化成了acks = 1 的情况。要获得更高的消息可靠性需要配合min.insync.replicas等参数的联动。 -
max.request.size: 用来限制生产者客户端能发送的消息的最大值,默认为1048576B,即1MB。
-
retries和retry.bakcoff.ms: retries参数用来配置生产者重试的次数。默认值为0,即在发生异常的时候不进行任何重试动作。retry.backoff.ms默认值为100,用来设置两次重试之间的时间间隔。避免无效的频繁重试。
-
compression.type:这个参数用来指定消息的压缩方式,默认值为“none”,默认情况下,消息不会被压缩。可配置为“gzip”、“snappy”、和“lz4”。
-
connections.max.idle.ms: 用来指定在多久之后关闭闲置的连接,默认值是540000(ms),及9分钟。
-
linger.ms: 用来指定生产者发送ProducerBatch之前等待更多消息(ProducerRecord)加入ProducerBatch的时间,默认值为0.生产者客户端会在ProducerBatch被填满或等待时间超过linger.ms值时发送出去。
-
receive.buffer.bytes: 用来设置Socket接收消息缓冲区(SO_RECBUF)的大小,默认值为131072(B),即32KB。
-
send.buffer.bytes: 用来设置Socket发送消息缓冲区(SO_SNDBUF)的大小,默认值为131072(B),即32KB。
-
request.timeout.ms: 用来配置Producer等待请求响应的最长时间,默认值为30000(ms)。请求超时之后可以选择重试。注意: 这个参数需要比broker端参数raplica.lag.time.max.ms的值要大,这样可以减少因客户端重试而引起的消息重复的概率。
1.6. 消费数据
消费者主动的去kafka集群拉取消息时,也是从Leader分区去拉取数据。
多个消费者组成一个消费者组,并且同一个消费者组内的消费者不能消费同一个分区中的消息,以免偏移混乱,可以消费不同分区中的消息。
一般建议一个消费者对应一个分区,以提升响应性能。
1.6.1. 消费者参数
-
fetch.min.bytes
一次拉取的最小字节数(1B) -
fetch.max.bytes
一次拉取的最大数据量(50M) -
fetch.max.wait.ms
拉取时的最大等待时长(500ms) -
max.partition.fetch.bytes
每个分区一次拉取的最大数据量(1MB) -
max.poll.records
一次拉取的最大条数(500) -
connections.max.idle.ms
网络连接的最大闲置时长(540000ms) -
request.timeout.ms
一次请求等待响应的最大超时时间,consumer 等待请求响应的最长时间(30000ms) -
metadata.max.age.ms
元数据在限定时间内没有进行更新,则会被强制更新(300000) -
reconnect.backoff.ms
尝试重新连接指定主机之前的退避时间(50ms) -
retry.backoff.ms
尝试重新拉取数据的重试间隔(100ms) -
isolation.level
隔离级别!决定消费者能读到什么样的数据read_uncommitted:可以消费到 LSO(LastStableOffset)位置; read_committed:可以消费到 HW(High Watermark)位置 -
max.poll.interval.ms
超过时限没有发起 poll 操作,则消费组认为该消费者已离开消费组
2. 安装
kafka是基于Java/Scala的软件,所以在安装kafka之前需要先安装java。Linux下安装更方便,且更能利用网络的性能,建议在Linux下安装。
2.1. 安装java
直接安装默认的即可。
sudo apt install default-jre
2.2. 安装kafka
新版的kafka默认已经集成了zookeeper,所以只要下载稳定版解压即可。
mkdir kafka
cd kafka
wget https://dlcdn.apache.org/kafka/3.3.1/kafka_2.13-3.3.1.tgz
sudo tar -xzf kafka_2.13-3.3.1.tgz
3. 部署
kafka的部署分为两种方式,一种方式是基于zookeeper,另一种方式是单独部署。
3.1. 基于zookeeper
3.1.1. 启动zookeeper
zookeeper的配置文件config/zookeeper.properties,一般不需要改动,如果有端口冲突,可以配置新的端口号。
sudo ./bin/zookeeper-server-start.sh config/zookeeper.properties
3.1.2. 启动kafka
kafka配置文件config/server.properties的常用配置如下:
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka/logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接Zookeeper地址
zookeeper.connect=172.18.1.22:2181
# 配置连接Zookeeper集群地址,可以将一个broker分布到多个zookeeper上
# zookeeper.connect=172.18.1.22:2181,172.18.1.23:2181,172.18.1.24:2181
- 单机单broker部署
sudo bin/kafka-server-start.sh config/server.properties
- 单机多broker部署
配置多个server1.properties,server2.properties,server3.properties中的listeners为不同的端口,然后启动多个进程
sudo bin/kafka-server-start.sh config/server1.properties
sudo bin/kafka-server-start.sh config/server2.properties
sudo bin/kafka-server-start.sh config/server3.properties
- 多机多broker部署
在多台电脑上启动zookeeper,再配置server1.properties中的zookeeper.connect分别对应不同电脑上的zookeeper。然后启动多个kafka。。
sudo bin/kafka-server-start.sh config/server1.properties
sudo bin/kafka-server-start.sh config/server2.properties
sudo bin/kafka-server-start.sh config/server3.properties
3.2. 单一模式
3.2.1. 单broker模式
单一模式,也即KRaft模式,不需要zookeeper。这是kafka新版本提供的功能,此模式避免与zookeeper通信,可以提升管理性能。
- 生成UUID
KAFKA_CLUSTER_ID=“$(bin/kafka-storage.sh random-uuid)”
- 格式化Log目录
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
- 启动服务器
sudo ./bin/kafka-server-start.sh config/kraft/server.properties
advertised.listeners=PLAINTEXT://172.18.11.46:9092,需要指定IP,否则其他电脑无法访问
3.2.2. 多broker模式
配置config/kraft/server.properties文件
# The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller
# The node id associated with this instance's roles
node.id=1
# @前面的序列号为node.id, roles=controller的都要配置在此处, 以考虑最终controller的投票
controller.quorum.voters=1@localhost:9093,2@172.18.11.12:9093,3@172.18.11.13:9093
4. 应用
4.1. 命令行应用
- 创建主题
# 默认broker,partition
bin/kafka-topics.sh --create --topic quickstart --bootstrap-server localhost:9092
# 多集群
bin/kafka-topics.sh --create --topic quickstart --bootstrap-server localhost:9092,172.18.11.12:9092,,172.18.11.13:9092
# 指定broker,partition,并且指定3个副本
kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 1 --topic quickstart-events
- 查询主题
sudo bin/kafka-topics.sh --list --bootstrap-server localhost:9092
## 多集群
sudo bin/kafka-topics.sh --list --bootstrap-server localhost:9092,172.18.11.12:9092,,172.18.11.13:9092
sudo bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092
-
生产消息
# KRaft模式 $ bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092 This is my first event This is my second event # 多zookeeper模式 $ bin/kafka-console-producer.sh --broker-list localhost:9092 localhost:9093 localhost:9094 --topic my-replicated-topic -
消费消息
# KRaft模式 $ bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092 This is my first event This is my second event -
删除主题
先要确保配置文件config/kraft/server.properties中配置了可删除。
auto.create.topics.enable = false
delete.topic.enable=true
删除指令
# KRaft模式
bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic quickstart-events
- 点对点消费
点对点消费,即发一个生产者对应一个消费者,订阅同一个主题的消费者的group id必须一样,即对一个主题而言,同时只有一个消费者在消费。 - 订阅发布
订阅发布,即一个主题有多个消费者,每个消费者的Group ID不一样,即可以使多个消费者同时消费一个主题。 - 删除消息
消除消息,只能通过配置服务的log.retention.hours=48或log.retention.bytes=1073741824来自动删除消息。
4.2. Python
kafka默认提供的是Java接口,但是C++,Python的接口也都有提供。
- 安装kafka的Python客户端接口库
pip install kafka-python
- 示例
from kafka import KafkaProducer, KafkaConsumer
from kafka.errors import kafka_errors
import traceback
import json
def producer_demo():
# 假设生产的消息为键值对(不是一定要键值对),且序列化方式为json
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
key_serializer=lambda k: json.dumps(k).encode(),
value_serializer=lambda v: json.dumps(v).encode())
# 发送三条消息
for i in range(0, 3):
future = producer.send(
'kafka_demo',
key='count_num', # 同一个key值,会被送至同一个分区
value=str(i),
partition=1) # 向分区1发送消息
print("send ".format(str(i)))
try:
# kafka默认是异步的, 消费会先发送到消息缓存中,根据配置的时间来定时将消息缓存发送到服务器
# 默认立即发往服务器
future.get(timeout=10) # 监控是否发送成功
except kafka_errors: # 发送失败抛出kafka_errors
traceback.format_exc()
def consumer_demo():
consumer = KafkaConsumer(
'kafka_demo',
bootstrap_servers=':9092',
group_id='test'
)
for message in consumer:
print("receive, key: , value: ".format(
json.loads(message.key.decode()),
json.loads(message.value.decode())
)
)
consumer_demo()
producer_demo()
4.3. C/C++
- 安装
参见:https://gitcode.net/mirrors/edenhill/librdkafka?utm_source=csdn_github_accelerator - 示例
参见:https://developer.confluent.io/get-started/c/
以上是关于kafka的安装部署及应用的主要内容,如果未能解决你的问题,请参考以下文章