你真的懂字符编码了吗?
Posted wiljm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你真的懂字符编码了吗?相关的知识,希望对你有一定的参考价值。
如果你经常遇到乱码问题,并且很难解决,或者不知道怎么就解决问题,那么你应该看看这篇文章。
概述
首先声明,本文不讲解各个字符编码格式(如需了解请自行百度)。本文只是为了给【经常遇到乱码问题】的程序员讲解一下字符和字节之间转换导致的【乱码问题】的【成因】是什么!
再讲解之前,郑重说明一点。计算机只认识二进制!计算机只认识二进制!计算机只认识二进制!电脑上呈现的一切,计算机其实都不认识;或者说我们看到的数据(屏幕显示)和计算机看到的(内部存储)是完全不一样的。
差点忘记一点重要的事,本文主要是针对于 Java 语言进行讲解。但是呢,其他语言的程序员也可以作为参考,因为大部分的内容都是纯理论的,只是借助于 Java 平台来讲解【字符】和【字节】之间的关系。
计算机认识字符吗?
大部分的人都觉得计算机能够显示文字就代表计算机认识字符;其实不然,计算机能够识别的只有二进制数。
那么为什么计算机能够显示字符呢?这就涉及到字符编码格式(再次声明,本文不讲解编码格式,如需了解请自行百度,后面不再重复此声明)了,虽然计算机只识别二进制数,但是我们又不认识二进制,人类认识的是字符信息。那么怎么把【二进制信息】转换成【字符信息】呢?正常的情况下,两个语言不通的人需要交流,都需要一个翻译官作为媒介去进行沟通。所以可以简单的把【字符编码格式】看成翻译官,它把二进制数据翻译(【解码】)成字符数据,把字符数据翻译(【编码】)成二进制数据。这不就是翻译官做的事情么?
因为计算机不认识字符,所以计算机在做处理字符的时候,在我们看起来它是在对字符进行操作;实际上是对通过字符编码格式【编码】之后的二进制数据进行操作。所以,可以总结出如下几点:
- 在保存字符数据的时候,程序需要根据字符编码格式得到字符数据对应的二进制数据才能进行保存。
- 在读取字符数据(实际上是读取二进制数据)的时候,程序需要根据字符编码格式得到二进制数据对应的字符数据才能进行显示。
在 Java 里面,字符数据就是 String 类型的对象;二进制数据就可以看成【字节数组】。
Java 中的编码
Java 语言中的字符都是 Unicode 编码,这一句话相信只要是 Java 程序员都听说过!(没有听说过,那你还是好好补下 Java 基础吧~~)
那么 Java 语言中的字符都是 Unicode 编码这句话是什么意思呢?相信大多数人就是简单的理解为【一个 char 等于两个 byte】,这样虽然正确;但是为了更好的分析乱码问题的成因,我们应该了解得更多。
那么还有什么需要了解的呢?在此之前,我们先来说一说在 Java 项目中有多少个配置编码的地方,Workspace(工作空间)、Project(项目)、File(文件本身)这三个地方都需要进行编码的配置。那么有些人又有疑问呢?什么我从来没有配置过编码啊!什么我很少配置编码啊!什么我只配置过 Project 编码啊!等等之类的。你没有配置,那是因为存在默认配置参数:
- Workspace 默认编码和计算机操作系统使用的编码保持一致。计算机操作系统使用的编码查看和修改的地方在【控制面板】=》【区域和语言】=》【管理】=》【更改系统区域设置】。
- Project 默认编码和 Worksace 的编码保持一致(也可以说Project 默认继承于 Workspace 的编码)。
- File 默认编码和 Project 的编码保持一致(也可以说 File 默认继承于 Project 的编码)。
接下来说一个特别重要的类 Charset,这个类可以查看 Java 运行环境中的默认编码。有人又会问了,Java 环境中的编码不是 Unicode 编码么?还需要查看?这个问题稍后再说。先上一段代码,用于查看 Java 运行环境中的默认编码。
System.out.println(Charset.defaultCharset().name());这里的打印结果和 File (就是你程序的执行入口,拥有 main 函数的那个文件, 注意: 如果一个项目的不同文件存在不同编码,且拥有多个 main 函数入口,那么你通过哪个 main 函数执行程序,Java 运行环境中的默认编码就是包含这个 main 函数的文件编码。ps:这里有点绕,要是不明白请自行练手!)
介绍完了基础概念,下面该进入正题了。
Java 语言中的字符都是 Unicode 编码说明了什么事情呢?说明 Java 语言在运行过程中,字符数据都是通过 Unicode 编码格式编码成的二进制数据表示的。计算机是不认识字符数据的,所以要处理字符数据必须把字符数据转换成二进制数据,这样就需要一个编码格式,Java 语言就选择了使用 Unicode 编码格式去将字符数据转换成二进制数据才进行处理的。所以说,Unicode 编码是 Java 语言内部维护字符数据的一种手段。
那么前面又说了 Java 运行环境中的默认编码,这个又是什么呢?这里的编码是和外部通信时所用到的编码格式。至于为什么不直接使用 Unicode 编码,简单的打个比方,Unicode 就相当于是 Java 王国所使用的一种语言,外部字符数据相当于是外国的语言,虽然这两种语言可能相同,比如很多国家都使用英语(英语也有差异,分为美式英语和英式英语嘛),但是还有一些国家是用的中文、日文、俄文等等。你要是使用同一种语言(编码)去和外国(外部数据)交流,那别人也不见得看得懂啊。
因此,还需要一个和外部通信时的编码格式。这个和外部进行通信的默认编码格式就是 Charset.defaultCharset().name()!
传输的是字符还是字节?
要是还是不明白这个问题,我想我要再次强调一遍。计算机只认识二进制!计算机只认识二进制!计算机只认识二进制!
字节流也好,字符流也罢,内部流动的全部是字节数据(也就是二进制数据)。这时候又有人会说了,字符流明明是传输的字符,我输入也是输入的字符,我读取也是读取的字符,你说的字节我完全没有看到啊,不要欺负我读书少好么?(ps:还就真欺负你读书少!人蠢就应该多读书不知道么?)
有上面疑问的人都忽略了一件事情,那就是在 OutputStreamWriter 里面维护了一个 StreamEncoder 对象,用于对字符流编码成字节流。如代码清单 1-1 所示。
代码清单 1-1
private final StreamEncoder se;
/**
* Creates an OutputStreamWriter that uses the named charset.
*
* @param out
* An OutputStream
*
* @param charsetName
* The name of a supported
* @link java.nio.charset.Charset </code>charset<code>
*
* @exception UnsupportedEncodingException
* If the named encoding is not supported
*/
public OutputStreamWriter(OutputStream out, String charsetName)
throws UnsupportedEncodingException
super(out);
if (charsetName == null)
throw new NullPointerException("charsetName");
se = StreamEncoder.forOutputStreamWriter(out, this, charsetName);
/**
* Creates an OutputStreamWriter that uses the default character encoding.
*
* @param out An OutputStream
*/
public OutputStreamWriter(OutputStream out)
super(out);
try
se = StreamEncoder.forOutputStreamWriter(out, this, (String)null);
catch (UnsupportedEncodingException e)
throw new Error(e);
在 InputStreamReader 里面维护了一个 StreamDecoder,用于对字节流解码变成字符流。如代码清单 1-2 所示。
代码清单 1-2
private final StreamDecoder sd;
/**
* Creates an InputStreamReader that uses the default charset.
*
* @param in An InputStream
*/
public InputStreamReader(InputStream in)
super(in);
try
sd = StreamDecoder.forInputStreamReader(in, this, (String)null); // ## check lock object
catch (UnsupportedEncodingException e)
// The default encoding should always be available
throw new Error(e);
/**
* Creates an InputStreamReader that uses the named charset.
*
* @param in
* An InputStream
*
* @param charsetName
* The name of a supported
* @link java.nio.charset.Charset </code>charset<code>
*
* @exception UnsupportedEncodingException
* If the named charset is not supported
*/
public InputStreamReader(InputStream in, String charsetName)
throws UnsupportedEncodingException
super(in);
if (charsetName == null)
throw new NullPointerException("charsetName");
sd = StreamDecoder.forInputStreamReader(in, this, charsetName);
无论是 StreamEncoder 还是 StreamDecoder 都和 Charset 相关,也就是是和编码格式相关。可以自行指定,如果不指定编码格式就使用默认的编码格式,这里的默认编码格式就是前面说到的 Java 运行环境的默认编码,可以通过 Charset.defaultCharset().name() 查看默认的编码格式是什么。
所以虽然我们在使用 字符流 API 时感觉我们在传输字符流,实际上内部传输的仍然是字节流。如果不理解,请记住一点:计算机只认识二进制数据!要是问计算机为什么只认识二进制数据,那么我只能说我也不知道了。(虽然可以说什么高低电压,然后扯上一波历史选择的结果。但是,学习应该是该深入的时候就深入,该浅尝的时候就浅尝!无谓的纠结反倒不利于学习)
究竟为何乱码?
写到这里,突然发现有一点很重要的东西忘记说了。那就是,无论是字节转字符还是字符转字节,都离不开编码格式!任何脱离了编码格式的关于字节与字符相互转换的话题都是不切合实际的!
那么究竟为什么乱码呢?相信看过前面的内容之后你应该就很清楚了吧。
什么!还是不清楚?那么我再举个例子吧。请睁大你的眼睛,仔细得看,认真的思考!
磁盘F中有个文件 test.txt(路径:F:\\test.txt),文件保存的是编码格式 为 GBK(Windows 编码为 ANSI) 的字符数据(二进制数据),文件内容如图 1-1 所示。
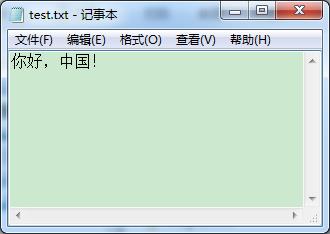
图 1-1 GBK 编码格式的文件
那么要读入到 Java 程序中,就要告诉 Java 程序这个文件的编码格式是 GBK,如果不告诉 Java 程序文件的编码格式,Java 程序就使用默认的运行环境编码格式。如代码清单 1-3 所示。
代码清单 1-3
public class FromFileReaderTest
public static void main(String[] args) throws IOException
System.out.println(Charset.defaultCharset().name());
File file = new File("F:/test.txt");
BufferedReader reader = new BufferedReader(
new InputStreamReader(new FileInputStream(file)));
String line = reader.readLine();
System.out.println(line);
运行结果如下:

可以看出,字符串已经乱码,那么是什么原因呢?是因为文件是使用的 GBK 编码,这句话的意思是说,文件保存的是通过 GBK 编码之后的二进制数据。然后 Java 程序通过 UTF-8 去解析通过 GBK 编码的二进制数据,这能不乱码么?都不是同一个码表(编码格式)了。
进行简单的修改,显式的指定 InputStreamReader 的编码格式为 GBK,如代码清单 1-4 所示。
代码清单 1-4
BufferedReader reader = new BufferedReader(
new InputStreamReader(new FileInputStream(file), "gbk"));运行结果如下:
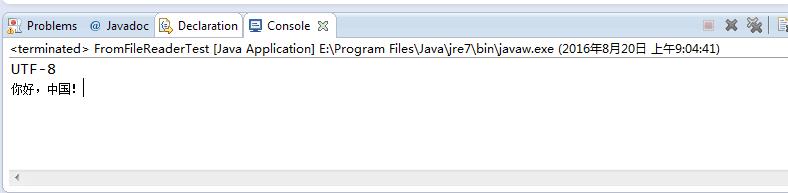
可以看出,已经没有了乱码问题!因为解码的编码格式和编码的格式都是 GBK 了,所以不会出现乱码问题。
结语
希望通过上文的讲解,能够让你彻底远离乱码问题的痛苦深渊!
要是还不明白,最后送你一个绝招!相信大多数人都听说过:用什么编码格式进行编码,就用什么编码格式进行解码。这很容易理解,在 Java 比较容易产生混淆的是,【Java 自身的编码格式】和【Java 运行环境的编码格式】、【Java 项目(文件)的编码格式】和【Java 数据的编码格式】。最后再总结一下:
- Java 自身的编码格式:Unicode 编码,是运行 Java 程序所用的编码格式。Java 程序会把所有的字符内容全部转换成 Unicode 编码格式。
- Java 运行环境的编码格式:和外部进行数据交换的时候所用的编码格式。可以通过 Charset.defaultCharset().name() 查看默认编码格式。
- Java 项目(文件、工作空间)的编码格式:默认是【文件编码格式】继承于【项目编码格式】继承于【工作空间编码格式】继承于【系统编码格式】。都可以自己设置。
- Java 数据的编码格式:默认编码格式和 Java 运行环境的编码格式一致,可以自己设置。Java 程序在和外部通信的时候会把 Unicode 编码格式的字符数据转换成 Java 数据的编码格式。
以上!
补充
上文有一些遗漏的地方,下面对其进行补充说明。
- 需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
- Unicode 的实现方式称为 Unicode 转换格式(Unicode Transformation Format,简称 UTF),因为一些历史原因,Windows记事本的“Unicode”这个名号其实相当有误导性。这个编码实际上是UTF-16 LE。
- Java 中的 Unicode 编码实际上是 UTF-16。

以上是关于你真的懂字符编码了吗?的主要内容,如果未能解决你的问题,请参考以下文章