注意力机制~ 预训练语言模型
Posted 天狼啸月1990
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了注意力机制~ 预训练语言模型相关的知识,希望对你有一定的参考价值。
背景
机器学习:偏数学(《统计学习方法》--李航)
深度学习(人工智能)项目:大数据支持(主流)
problem: 目前很多项目没有大数据支持(小数据)
1. 预训练 pre-training
1.1 pre-training classification
- Frozen冻结:浅层参数不变
- Fine-tuning微调(常用):浅层参数会跟着任务B训练而改变。
1.2 pre-training concept
预训练通过一个已经训练好的模型A,去完成一个小数据量的任务B,使用了model A的浅层参数去训练任务B,得到模型B。任务A和任务B及其相似,即便任务B也是大数据,可以训练出模型B,我们可以用模型A的浅层参数,节省训练时间,节省成本。
这不就是transfer learning吗???
预训练(Pre-training Models, PTMs)的实施过程跟迁移学习是一样的,一般是在一个基础数据集上进行任务训练,生成一个基础网络,然后将学习到的特征重新进行微调或迁移到另一个目标网络上,用来训练新的目标任务。
1.3 pre-training usage
fairseq、transformers库
2. 统计语言模型
2.1 语言模型
语言(就是文本text) + 模型(本质就是一个函数function/映射f: x -> y):
本质:语言模型(language model),就是计算一句话的概率。
具体来说,就是为一个长度为m的文本确定一个概率分布,表示这段文本存在的可能性。
语言模型两个任务:
- p("今天的蜂蜜很甜"),确定其概率。
- --> 然后可以做应用:预测下一个词是什么,"今天的蜂蜜__"
2.2 统计语言模型
用统计的方法解决上述语言模型的问题
分词:"今天","的","蜂蜜","很甜"。这句话是序列(有顺序的),即在计算条件概率时要考虑语序order。
2.2.1 解决第一个问题:计算一句话的概率p
用了一个条件概率的链式法则(概率论)

通过这个法则,我们可以求出每一个词出现的概率,然后联乘,就是这句话出现的概率。
2.2.2 解决第二个问题:预测下一个词可能是什么
"今天的蜂蜜__"
p(w_next|"今天", "的","蜂蜜")
词库(V),可以理解成新华词典
把词库V里的每一个词,进行上一步的预测计算。穷举/枚举法,贪心算法
e.g.
词库V = "好甜", "火星",...
p(好甜|"今天", "的","蜂蜜")
p(火星|"今天", "的","蜂蜜")
...
如果词很多,那计算的时间和成本太高了!!!
n元模型
2.2.3 n元模型
在实践中,如果文本的长度较长,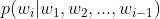 的估算会非常困难。
的估算会非常困难。
n元模型(n-gram model)。在n元模型中估算条件概率时,只需要对当前次的前n-1个词进行计算,一般也就用到三元模型。马尔科夫链

3元语言模型:
p(好甜|"今天", "的","蜂蜜")
p(火星|"今天", "的","蜂蜜")
2元语言模型:
p(好甜|"的","蜂蜜")
p(火星| "的","蜂蜜")
3元模型和2元模型计算得到的条件概率差不多
2.2.4 n-gram model 计算
语料库:
"俄罗斯的蜂蜜好甜"
"今天的蜂蜜好甜"
"云南的蜂蜜好香"
"新疆的蜂鸣透明"
p(好甜|"的","蜂蜜") = count("的", "蜂蜜","好甜")/count("的","蜂蜜") = 1/2
2.2.5 平滑 smooth strategy
预测不存在词的条件概率,会在分子或分母上出现0
平滑 smooth strategy,在分子上加1,在分母上加|V|等等。
3. 神经网络语言模型
用神经网络的方法解决语言模型的问题。
3.1 独热编码(one-hot encoding)
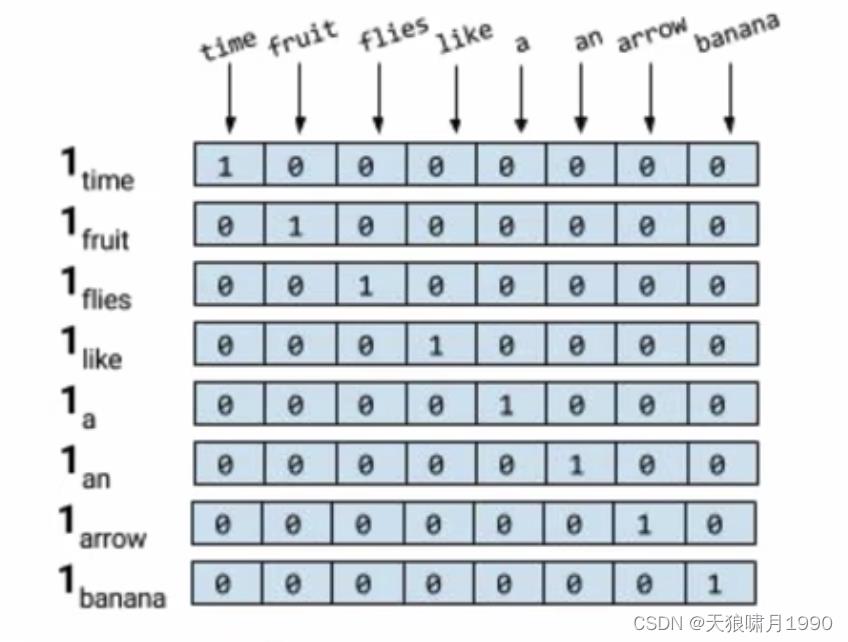
background: 让计算机认识现实生活中的文本,因为计算机只认知编码方式。
独热编码:根据词典V中单词量|V|,构建一个|v|*|v|矩阵,根据单词的顺序(索引index),分配相应的向量,one-hot vector只有index元素为1,其余元素为0。
参考
04 统计语言模型(n元语言模型)_哔哩哔哩_bilibili
自然语言处理中的语言模型预训练方法(ELMo、GPT和BERT) - robert_ai - 博客园
以上是关于注意力机制~ 预训练语言模型的主要内容,如果未能解决你的问题,请参考以下文章