学习率衰减局部最优Batch归一化Softmax回归
Posted 劳埃德·福杰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习率衰减局部最优Batch归一化Softmax回归相关的知识,希望对你有一定的参考价值。
1.学习率衰减(Learning rate decay)
在训练初期,梯度下降的步伐大一点,开始收敛的时候,小一些的学习率能让步伐小一些。
1 epoch = 遍历一遍训练集
学习率衰减公式:
例:假设衰减率decayrate = 1, =0.2
=0.2
epochNum | α |
1 | 0.1 |
2 | 0.067 |
3 | 0.05 |
4 | 0.04 |
其它学习率衰减公式:α=0. (指数衰减)。。。等等
(指数衰减)。。。等等
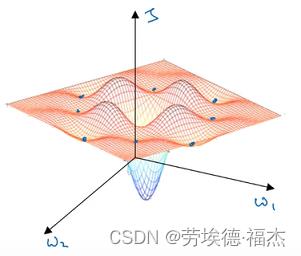
2. 局部最优(local optima)的问题
梯度下降的时候可能会困在一个局部最优中,而不会抵达全局最优。
3.Batch归一化(Batch Normalization)
我们知道,训练一个模型,比如logistic回归,归一化输入特征可加速学习过程。
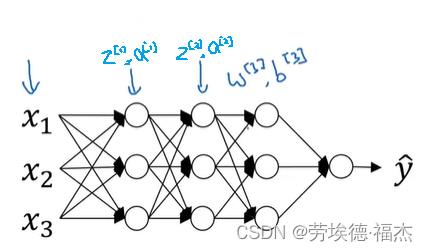
对于更深一点的模型,也可以归一化隐藏层的输出,比如归一化 (代入激活函数就是
(代入激活函数就是 ),以便更有效率地训练
),以便更有效率地训练 ,
, 。
。
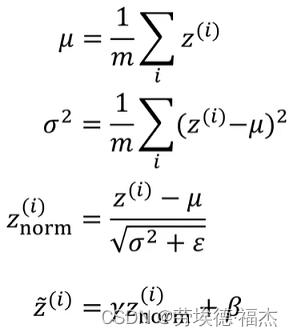
4.Softmax回归(Softmax regression)
不同于logistic回归,解决的是二分类问题,Softmax回归能解决多分类问题,即识别多种分类中的一个。
假设要区分3个类别(A,B,C),那么神经网络的输出层要有4个神经单元(分别输出"A,B,C,其它"这四类的识别概率)。
最后一层layer L的神经元执行操作如下:
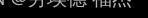 ,
, ,
, ,
, 是上一层的输出。
是上一层的输出。
举例:
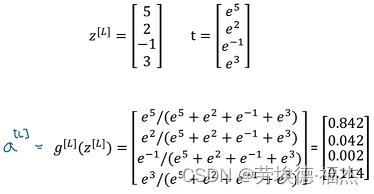
训练一个Softmax分类器:
正向传播:从输入层到输出层,依次计算并存储模型的参数。
反向传播:从输出层到输入层,依次计算参数的梯度,来更新参数。
以上是关于学习率衰减局部最优Batch归一化Softmax回归的主要内容,如果未能解决你的问题,请参考以下文章