强化学习笔记-01强化学习介绍
Posted tostq
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习笔记-01强化学习介绍相关的知识,希望对你有一定的参考价值。
本文是博主对《Reinforcement Learning- An introduction》的阅读笔记,不涉及内容的翻译,主要为个人的理解和思考。
1. 强化学习是什么?解决什么样的问题?
强化学习主要是针对于同环境进行交互下,学习如何决策使得目标奖励最大。包含了三个要素:交互Interaction、决策Policy和奖励Reward。
- 同环境的交互Interaction:主要包含了两个方面:受环境影响状态State,通过动作Action来影响环境。强化学习并不需要对环境的完全可知,环境可以作为黑盒,通过环境可以根据当前state和action获取下一状态和奖励。
- 决策Policy:构建了由状态到动作的映射关系,这个是强化算法学习的核心
- 奖励Reward:代表了环境在当前状态反馈的即期的收益,既是强化学习优化目标,也是强化学习迭代信号。
强化学习可应用的例子很多,比如:
- 游戏决策类:比如围棋游戏,目标是胜出得分最大,决策是每一步走子的位置,状态是指当前棋盘内黑白子的位置,同环境的交互是指对手根据当前走子状态形成下一步走子,而奖励是指最终的胜出得分。
- 参数优化类:比如信息流推荐,目标是用户总浏览时长,决策是每一次下翻推荐的内容,状态是当前客户已经浏览内容及一些个性化特征,同环境的交互是指用户的浏览行为
- 机器人控制:比如双足机器人行走,目标是行走的长度,决策是每个状态下关节的动作,状态是当前各部位的位置状态,同环境的交互是指机器人的状态变化。
因此我们可以粗略地说,强化学习是学习如何同环境进行交互,从而使目标奖励最大化。下一节我们将以更为抽象化的数学语言来描述强化学习的实现要点。
2. 强化学习的实现要点
结合前面的讨论,强化学习的要点主要有四个:
- policy:
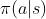 ,决策函数,其输入为状态s,输出为动作a,可以是模型或者概率图表
,决策函数,其输入为状态s,输出为动作a,可以是模型或者概率图表 - reward:奖励r,为从环境根据状态及动作即时生成
- value:
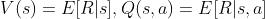 ,即状态s下未来累积奖励的预估,R表示未来累积奖励,在value-base的模型中,value函数会用于决策函数的计算,
,即状态s下未来累积奖励的预估,R表示未来累积奖励,在value-base的模型中,value函数会用于决策函数的计算, ,即表示选择使下一状态value最大的动作。
,即表示选择使下一状态value最大的动作。 - 环境建模:
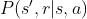 ,即确定在当前状态s及动作a的情况下,得到下一状态s'和奖励。在很多情况下并不需要对环境进行建模,通过环境建模来考虑未来暂未发生的动作状态,进行预先计划的方法称之为model-base模型。
,即确定在当前状态s及动作a的情况下,得到下一状态s'和奖励。在很多情况下并不需要对环境进行建模,通过环境建模来考虑未来暂未发生的动作状态,进行预先计划的方法称之为model-base模型。
由上可知,强化学习的核心在于policy决策函数的学习,直接学习policy函数称为policy-base的方法,但很多情况下,我们是通过状态s下价值预估函数V(s)来间接生成policy函数的,称之为value-base的方法。
另一部分是训练过程,exploration(探索) and exploitation(加强)是强化学习的另一特点,exploit是为了保持当前reward,往已经探索的方向继续开拓加强,而explore是探索未知的方向,为了不陷入局部最优而寻找更高reward。强化学习就是根据过去已经获得的经验,不断加强当前价值函数或决策函数的预估,之后再根据新一轮决策函数去exploit and explore新方向,这个不断优化的过程,称之为强化学习。
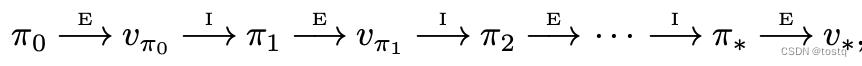
上图value-base模型的迭代说明了这个过程,图中E表示根据当前决策函数π去执行动作获得奖励,并更新价值函数v,I表示根据价值函数v来更新新一轮的决策函数π,这个不断迭代加强,最终决策函数和价值函数都收敛的过程就是强化的过程。
3. 强化学习同传统机器学习的比较
传统监督机器学习一般是从带标签的数据开始训练,这个数据标签是依据先验知识得到的(比如人为标计),其目标是要学习建立由输入X到输出Y之间映射关系的模型。而强化学习一般不需要这类先验知识,其是通过交互来不断学习和探索的,但又不同于非监督方法学习的是输入数据间的某种隐藏的结构(比如聚类),强化学习的在于学习决策函数,而使目标奖励最大化。
特别是对涉及到同环境进行交互的问题,传统机器学习方法需要包含先验的带标签的数据,而交互类问题,很难去标记覆盖所有情况下的动作状态,特别是状态动作空间大的情况,而强化学习通过exploit and explore,能自动地地去探索最优的动作状态空间。
这种探索思路也非常类似于进化类算法(比如遗传算法、模拟退火、蚂蚁算法等等),其也能解决很多强化学习所涉及的环境交互问题,在很多领域上也有胜过强化学习的能力。进化学习同强化学习最大的差异在于其并没有value函数。
进化学习的一般性思路是构造很多个决策函数(模型),然后根据决策函数最终的奖励来寻找最优的决策函数。所以一般用于决策函数空间小,或者好的决策函数很容易找到,或者有大量的时间或资源可以用来探索的情况。
因为进化学习不会用到中间状态的价值预估,只会用到最终的奖励,这可能会带来一些效率上的损失,但是如果中间价值预估非常不准,或者对于环境没有较完备的认识,我们也可以考虑用进化学习来取代强化学习。
以上是关于强化学习笔记-01强化学习介绍的主要内容,如果未能解决你的问题,请参考以下文章