HadoopMapReduce分布式计算实践(统计文本单词数量)
Posted ccql
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HadoopMapReduce分布式计算实践(统计文本单词数量)相关的知识,希望对你有一定的参考价值。
文章目录
1. 前言
在博客【Hadoop】MapReduce原理剖析(Map,Shuffle,Reduce三阶段)中已经分析了MapReduce的运行过程,以及部分原理。那么这篇博客则是进行一次实践,使用MapReduce统计文本中的单词数量。实际上我们只需要写Mapper和Reducer部分的代码,最后在Main中进行一些设置即可。
2. Mapper代码
MyMapper类继承于Mapper类,重写了map函数。map函数输入为<k1, v1>,k1为LongWritable类型,表示每一行的偏移量;v1为Text类型,表示该行内容。其实现方法为:以空格为分隔符切割单词,并将每个切除的单词写为<word, 1>的形式,表示该单词出现过一次。
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* map函数接收<k1,v1>,产生<k2,v2>
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException
//使用stdout方式输出<k1,v1>
System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//使用logger方式输出<k1,v1>
logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//k1表示每一行的偏移量,v1表示该行内容
//首先把每一行的单词切割出来
String[] words = v1.toString().split(" ");
for (String word : words)
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
context.write(k2, v2);
3. Reducer代码
MyReducer类继承于Reduce类,重写了reduce方法。对经过Combiner的<k2,v2s>数据中的v2s进行求和并组成<k3,v3>。
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>
/**
* 对v2s的数据进行累加,保存v2s的和
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
Logger logger = LoggerFactory.getLogger(MyReducer.class);
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Reducer<Text, LongWritable, Text,
LongWritable>.Context context) throws IOException, InterruptedException
//sum计算v2s的和
long sum = 0L;
for (LongWritable v2 : v2s)
System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
logger.info("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
logger.info("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
context.write(k3, v3);
4. Main代码
由于考虑到代码的复用性,并没有将地址直接写在代码中,而是在运行前以参数形式输入。在Main函数中需要指定很多配置,如下:
- 设置类地址:
job.setJarByClass(WordCountJob.class); - 指定输入/输出路径,其中输入的地址可以是一个文件,也可以是一个文件夹。若是文件则对这一个文件进行切割并执行MapReduce,若是文件夹,则对该文件夹中的所有文件进行切割并执行,也就是说要执行多文件的MapReduce并不需要修改代码,只需要在输入时将其放在同一个文件夹下即可,可以说是相当方便了。
- 指定Mapper类,以及k2和v2的类型。
- 指定Reducer类,以及k3和v3的类型。
- 提交job任务。
在某些任务中不需要使用Reduce,只需要在main中添加job.setNumReduceTasks(0);即可,且不需要书写Reduce部分的代码。
public static void main(String[] args)
try
if(args.length!=2)
System.exit(100);
//配置项
Configuration configuration = new Configuration();
//创建一个job
Job job = Job.getInstance(configuration);
//不设置的话,集群就找不到这个类
job.setJarByClass(WordCountJob.class);
//指定输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
job.setOutputValueClass(LongWritable.class);
//指定reduce相关的代码
job.setReducerClass(MyReducer.class);
//指定k3的类型
job.setOutputKeyClass(Text.class);
//指定v3的类型
job.setOutputValueClass(LongWritable.class);
//提交job
job.waitForCompletion(true);
catch (Exception e)
e.printStackTrace();
5. 项目打包
项目打包需要在Maven的pom.xml文件中进行一些配置,如下:
- 首先,添加如下打包配置,指定编码类型、jdk版本,是否打包依赖等配置。
<build>
<plugins>
<!-- compiler插件, 设定JDK版本 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<encoding>GBK</encoding>
<source>1.8</source>
<target>1.8</target>
<showWarnings>true</showWarnings>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
- 其次,在pom中的hadoop-client和log4j依赖中增加scope属性,值为provided,表示只在编译的时候使用这个依赖,在执行以及打包的时候都不使用,因为hadoop-client和log4j依赖在集群中都是有的,所以在打jar包的时候就不需要打进去了,如果我们使用到了集群中没有的第三方依赖包就不需要增加这个provided属性了,不增加provided就可以把对应的第三方依赖打进jar包里面了。如下,在依赖中添加一行
<scope>provided</scope>即可,但记得在本地运行本项目的其他程序时要注释掉!
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
<scope>provided</scope>
</dependency>
- 最后,在cmd窗口该目录下运行
mvn clean package -DskipTests即可成功打包,将jar包db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar上传到Linux系统。
打包后应该有两个jar包,分别是
db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar和db_hadoop-1.0-SNAPSHOT.jar。一般来说前者与后者相比,打包的时候有依赖,但是由于本项目在依赖中添加了<scope>provided</scope>,所以在打包时并不会将依赖也打入包中,所以这两个文件是相同的。
6. Hadoop运行
在运行前记得先给hdfs上传一个要操作的对象文件,我这里创建的是hello.txt,文件内容是:
[root@bigData01 hadoop-3.2.0]# hdfs dfs -cat /test/hello.txt
hello you
hello me
hello world
使用命令hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar MR.WordCountJob /test/hello.txt /out即可运行程序,其中各部分的含义为:
- hadoop:表示使用hadoop脚本提交任务;
- jar:表示执行jar包;
- db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar:指定具体的jar包路径信息;
- MR.WordCountJob:指定要执行的mapreduce代码的全路径;
- /test/hello.txt:指定mapreduce接收到的第一个参数,代表的是输入路径,这里的输入路径可以直接指定hello.txt的路径,也可以直接指定它的父目录,因为它的父目录里面也没有其它无关的文件;如果指定目录的话就意味着hdfs会读取这个目录下所有的文件,所以后期如果我们需要处理一批文件,那就可以把他们放到同一个目录里面,直接指定目录即可。
- /out:指定mapreduce接收到的第二个参数,代表的是输出目录,这里的输出目录必须不存在;
执行结果如下:
[root@bigData01 hadoop-3.2.0]# hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar MR.WordCountJob /test/hello.txt /out
2023-01-25 22:38:29,431 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
2023-01-25 22:38:30,124 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2023-01-25 22:38:30,154 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1674656126666_0003
2023-01-25 22:38:30,332 INFO input.FileInputFormat: Total input files to process : 1
2023-01-25 22:38:31,268 INFO mapreduce.JobSubmitter: number of splits:1
2023-01-25 22:38:31,293 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
2023-01-25 22:38:31,873 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1674656126666_0003
2023-01-25 22:38:31,874 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-01-25 22:38:32,092 INFO conf.Configuration: resource-types.xml not found
2023-01-25 22:38:32,092 INFO resource.ResourceUtils: Unable to find ‘resource-types.xml’.
2023-01-25 22:38:32,175 INFO impl.YarnClientImpl: Submitted application application_1674656126666_0003
2023-01-25 22:38:32,210 INFO mapreduce.Job: The url to track the job: http://bigData01:8088/proxy/application_1674656126666_0003/
2023-01-25 22:38:32,210 INFO mapreduce.Job: Running job: job_1674656126666_0003
2023-01-25 22:38:39,491 INFO mapreduce.Job: Job job_1674656126666_0003 running in uber mode : false
2023-01-25 22:38:39,491 INFO mapreduce.Job: map 0% reduce 0%
2023-01-25 22:38:45,565 INFO mapreduce.Job: map 100% reduce 0%
2023-01-25 22:38:51,623 INFO mapreduce.Job: map 100% reduce 100%
2023-01-25 22:38:52,635 INFO mapreduce.Job: Job job_1674656126666_0003 completed successfully
2023-01-25 22:38:52,719 INFO mapreduce.Job: Counters: 54
…
7. 运行结果查看
7.1 输出文件查看
执行后查看/out文件夹中的文件/out/part-r-00000,这个文件即是输出的结果文件:
[root@bigData01 hadoop-3.2.0]# hdfs dfs -cat /out/part-r-00000
hello 3
me 1
world 1
you 1
7.2 日志查看
要查看日志的话需要先配置yarn-site.xml文件,重启集群,并开启日志聚合功能:
- 配置yarn-site.xml文件:
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata01:19888/jobhistory/logs/</value>
</property>
- 重启并开启日志聚合功能:
[root@bigdata01 hadoop-3.2.0]# sbin/stop-all.sh
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
[root@bigData01 hadoop-3.2.0]# bin/mapred --daemon start historyserver
[root@bigData01 hadoop-3.2.0]# jps
8114 NodeManager
7429 DataNode
7669 SecondaryNameNode
7239 NameNode
9159 JobHistoryServer
7945 ResourceManager
9198 Jps
经过上述步骤后打开http://bigdata01:8088,其中bigdata01替换为你的虚拟机ip地址(我之所以写了虚拟机的名称而不是ip地址,是因为我在windows系统的hosts文件中进行过配置,若没有配置过就直接写ip),点击MapReduce任务(重启集群后会删除,因此需要再执行一次该任务)如下:
- 点击MapReduce任务

- 点击history

- 选择自己要查看Map/Reduce任务:
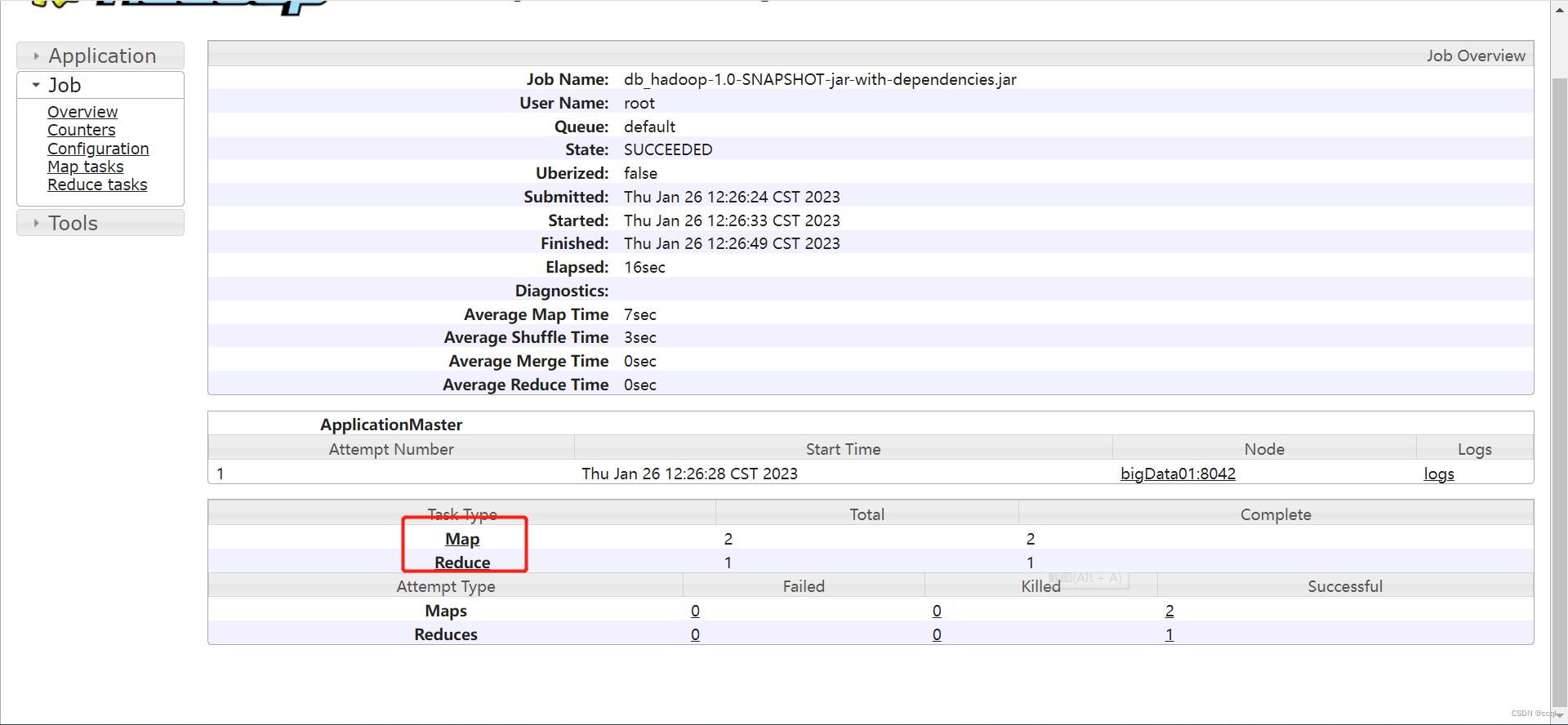
- 选择Map Task/Reduce Task(通常Maptask不止一个,每个InputSplit对应一个Map task,InputSplit的计算方法以及原理在博客【Hadoop】MapReduce原理剖析(Map,Shuffle,Reduce三阶段)中已经介绍的很清楚了,感兴趣的读者可以阅览):

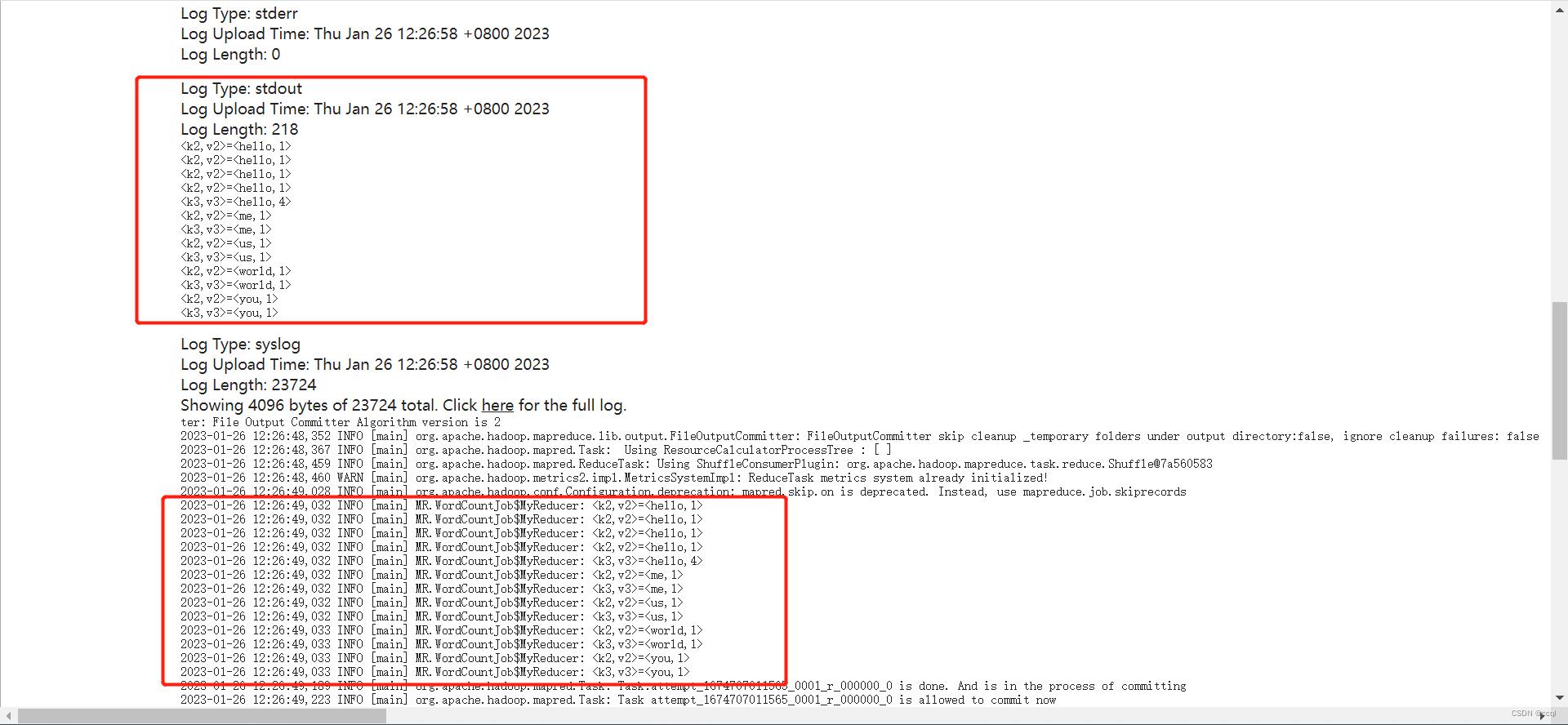
- 点击logs查看:

- 查看日志,可以看到在stdout和syslog中都可以看到中间结果的输出,这是因为在写代码的时候添加了输出日志的代码,如:
System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");和logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");。
至此,MapReduce分布式计算实践(统计文本单词数量)博客撰写结束,我知道这个实践很基础,也有很多博主写过这个实践过程,这篇博客就当作是我自己的学习记录,虽然很简单很基础但毕竟万丈高楼平地起嘛,让我们一起加油吧!
以上是关于HadoopMapReduce分布式计算实践(统计文本单词数量)的主要内容,如果未能解决你的问题,请参考以下文章
大数据系列之分布式计算批处理引擎MapReduce实践-排序