搭建Hadoop3.x分布式集群
Posted 小甜菜Pro
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搭建Hadoop3.x分布式集群相关的知识,希望对你有一定的参考价值。

如今Hadoop已经升级为第3个大版本,相比Hadoop2.x,Hadoop3.x没有在架构上进行大的改动,而是提高了系统的可扩展性和资源利用率上,因此,Hadoop3.x有更高的性能、更强的容错能力和更高效的数据处理能力。
到现在为止Hadoop最新的版本为3.3.4,可以在官网https://hadoop.apache.org/进行下载,下面演示使用三台主机搭建集群模式,三台主机的主机名依次为master、slave1和slave2,并且全部使用root用户。
一、安装JDK8
1、下载JDK8。浏览器输入https://www.oracle.com/java/technologies/downloads/网站进行下载(若链接失效可以搜索oracle官网并找到JDK8进行下载)。
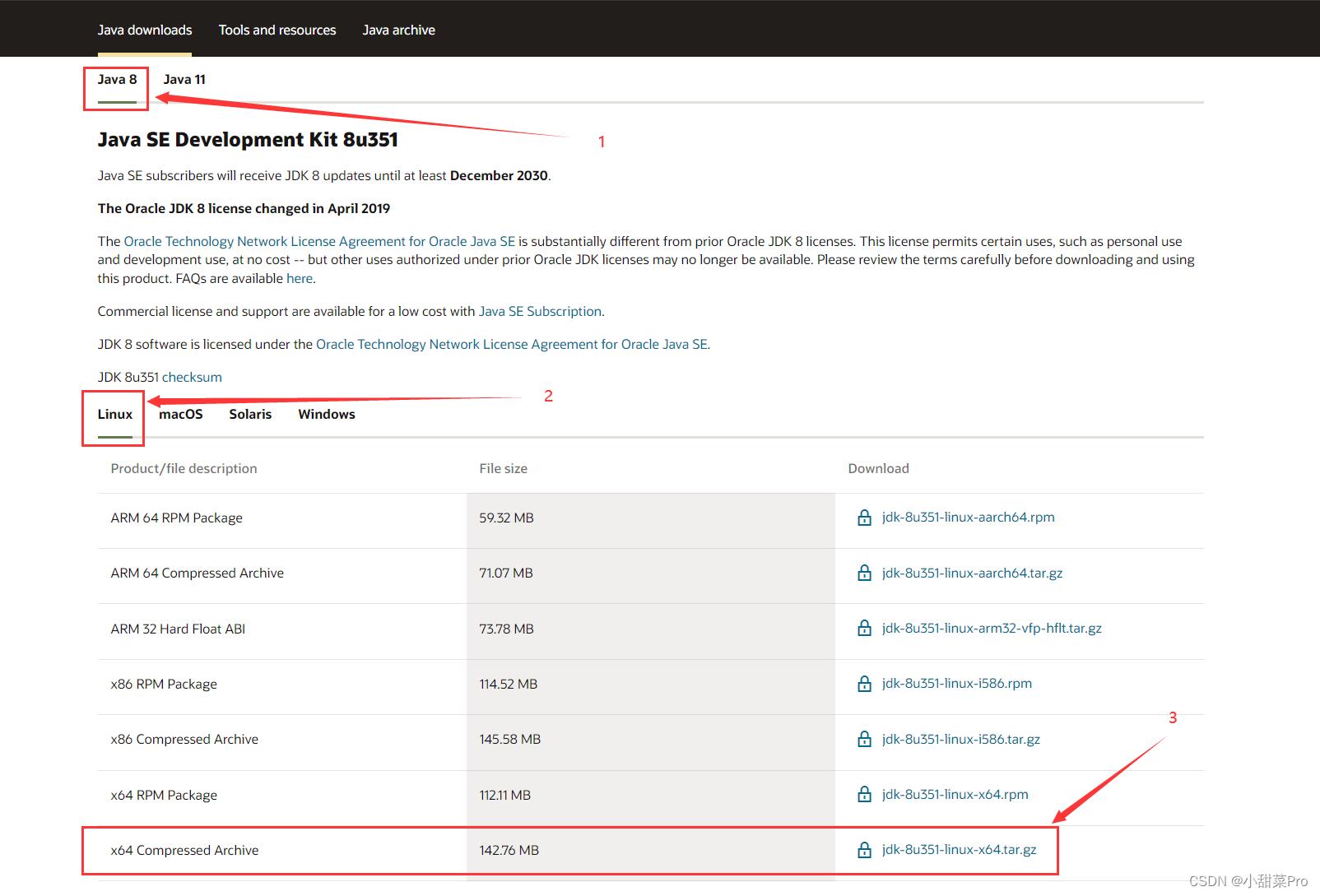
2、将下载好的安装包上传至master主机中/root/download路径下。
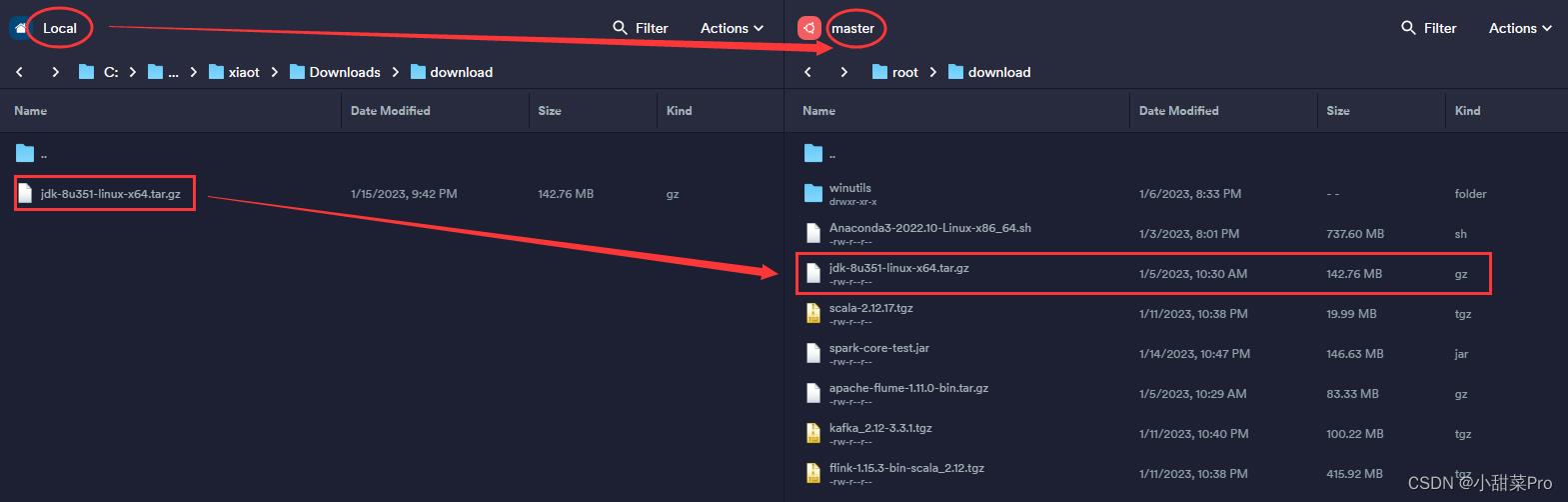
3、# tar -zxvf /root/download/jdk-8u351-linux-x64.tar.gz -C /usr/local命令解压。
4、# mv /usr/local/jdk1.8.0_351/ /usr/local/jdk命令将默认文件夹重命名。
5、# vim /root/.bashrc修改系统环境变量,在文件最后添加以下代码。
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/1ib/tools.jar
使用:wq保存并退出。
6、将文件分发到另外两台主机。
scp -r /usr/local/jdk slave1:/usr/local # 将JDK分发到slave1主机
scp -r /usr/local/jdk slave2:/usr/local # 将JDK分发到slave2主机
scp /root/.bashrc slave1:/root # 将环境变量分发到slave1主机
scp /root/.bashrc slave2:/root # 将环境变量分发到slave2主机
7、在三台主机上运行# source /root/.bashrc命令让环境变量立即生效。
8、使用# java -version命令查看JDK是否安装成功(此命令是用来查看JDK版本号),出现下图则代表安装成功。

二、安装Hadoop3.3.4
1、下载Hadoop。打开官网https://hadoop.apache.org并按照以下图示进行下载。
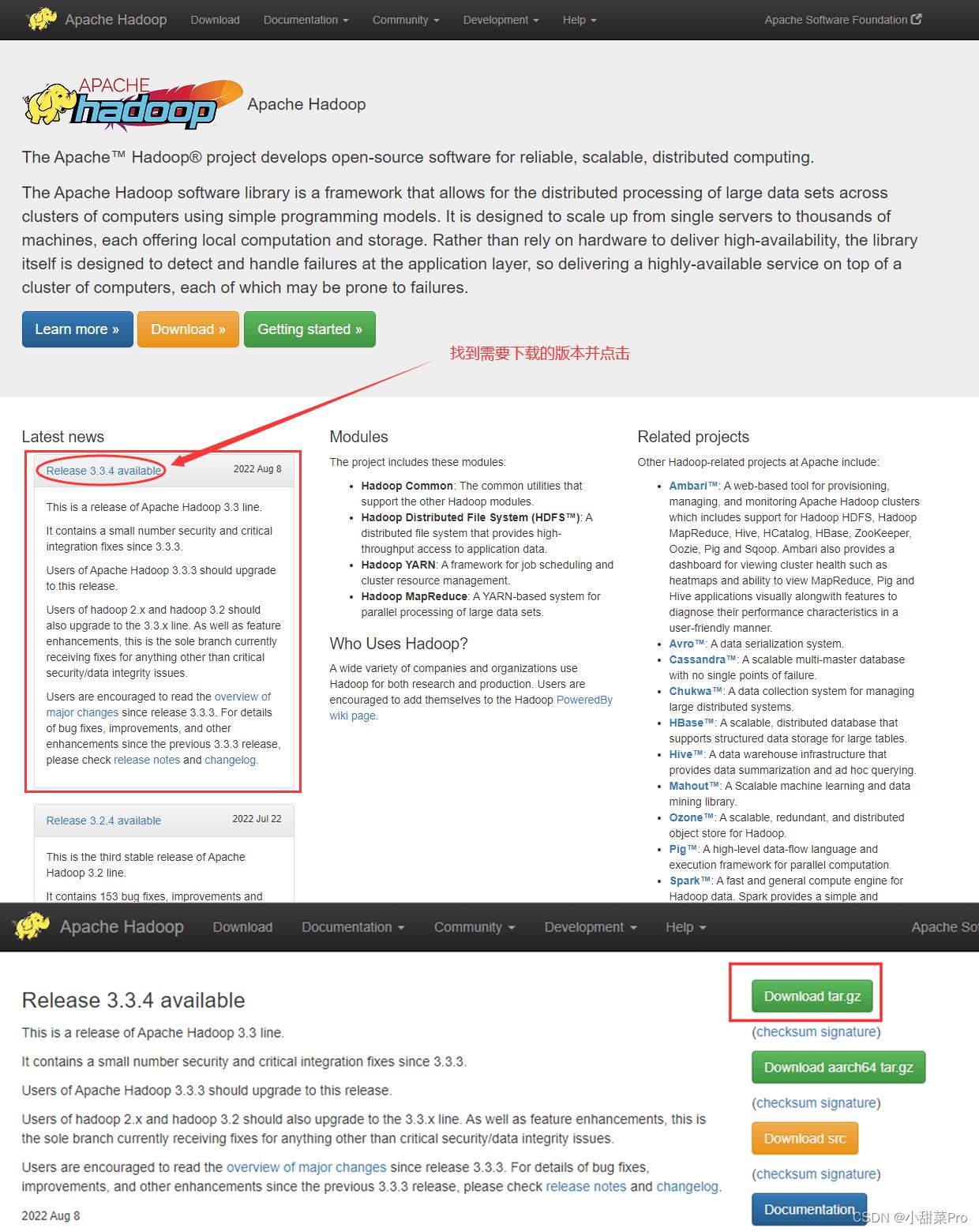
2、将下载好的安装包上传至master主机中/root/download路径下。
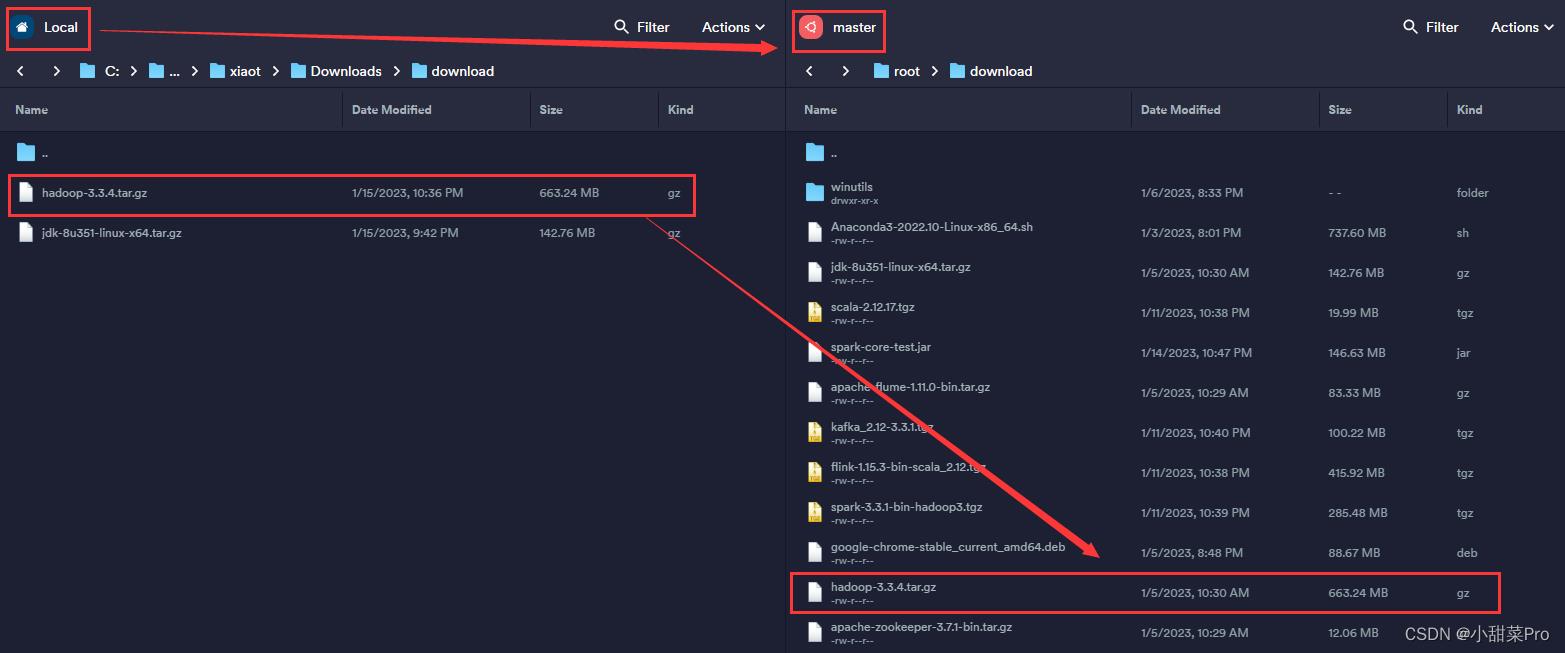
3、# tar -zxvf /root/download/hadoop-3.3.4.tar.gz -C /usr/local命令解压。
4、# mv /usr/local/hadoop-3.3.4/ /usr/local/hadoop命令将默认文件夹重命名。
5、# vim /root/.bashrc修改系统环境变量,在文件最后添加以下代码。
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使用:wq保存并退出,同时使用# source /root/.bashrc命令让环境变量立即生效。
6、# cd /usr/local/hadoop/etc/hadoop命令进入Hadoop配置文件路径。
7、修改hadoop-env.sh配置文件,使用# vim ./hadoop-env.sh命令。
# 修改JDK默认路径
export JAVA_HOME=/usr/local/jdk
# 以下配置需要在文件最后添加
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
8、修改core-site.xml配置文件,使用# vim ./core-site.xml命令。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
9、修改hdfs-site.xml配置文件,使用# vim ./hdfs-site.xml命令。
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:9868</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
10、修改yarn-site.xml配置文件,使用# vim ./yarn-site.xml命令。参数yarn.scheduler.minimum-allocation-mb和参数yarn.scheduler.maximum-allocation-mb分别表示ResourceManager每个容器可以申请的最少和最多物理内存量,参数yarn.nodemanager.resource.cpu-vcores表示该节点上NodeManager总的可用虚拟CPU核数,参数yarn.nodemanager.resource.memory-mb表示该节点上NodeManager可使用的物理内存总量,以上参数需要根据实际主机硬件配置进行相应调整。
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>12288</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
11、修改mapred-site.xml配置文件,使用# vim ./mapred-site.xml命令。参数yarn.application.classpath需要使用命令# $HADOOP_HOME/bin/hadoop classpath获得value值。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/share/hadoop/yarn:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*</value>
</property>
</configuration>
12、修改workers配置文件,使用# vim ./workers命令。
master
slave1
slave2
13、创建路径。
mkdir -p /usr/local/hadoop/tmp
mkdir -p /usr/local/hadoop/dfs/name
mkdir -p /usr/local/hadoop/dfs/data
14、将文件分发到另外两台主机。
scp -r /usr/local/hadoop slave1:/usr/local # 将Hadoop分发到slave1主机
scp -r /usr/local/hadoop slave2:/usr/local # 将Hadoop分发到slave2主机
scp -r /root/.bashrc slave1:/root # 将环境变量分发到slave1主机
scp -r /root/.bashrc slave2:/root # 将环境变量分发到slave2主机
15、在三台主机上运行# source /root/.bashrc命令让环境变量立即生效。
安装完成后在首次启动Hadoop集群前需要使用# $HADOOP_HOME/bin/hdfs namenode -format命令初始化HDFS,对主节点进行格式化处理。
启动Hadoop集群使用命令$HADOOP_HOME/sbin/start-dfs.sh && $HADOOP_HOME/sbin/start-yarn.sh,当以上的系统环境变量配置成功后可以直接使用start-dfs.sh && start-yarn.sh命令进行启动。
启动成功后可以使用jps命令查询系统当前所有java进程pid,出现下图则表示启动成功。

使用浏览器分别访问http://master:9870和http://master:8088可以查看HDFS和YARN集群状态。
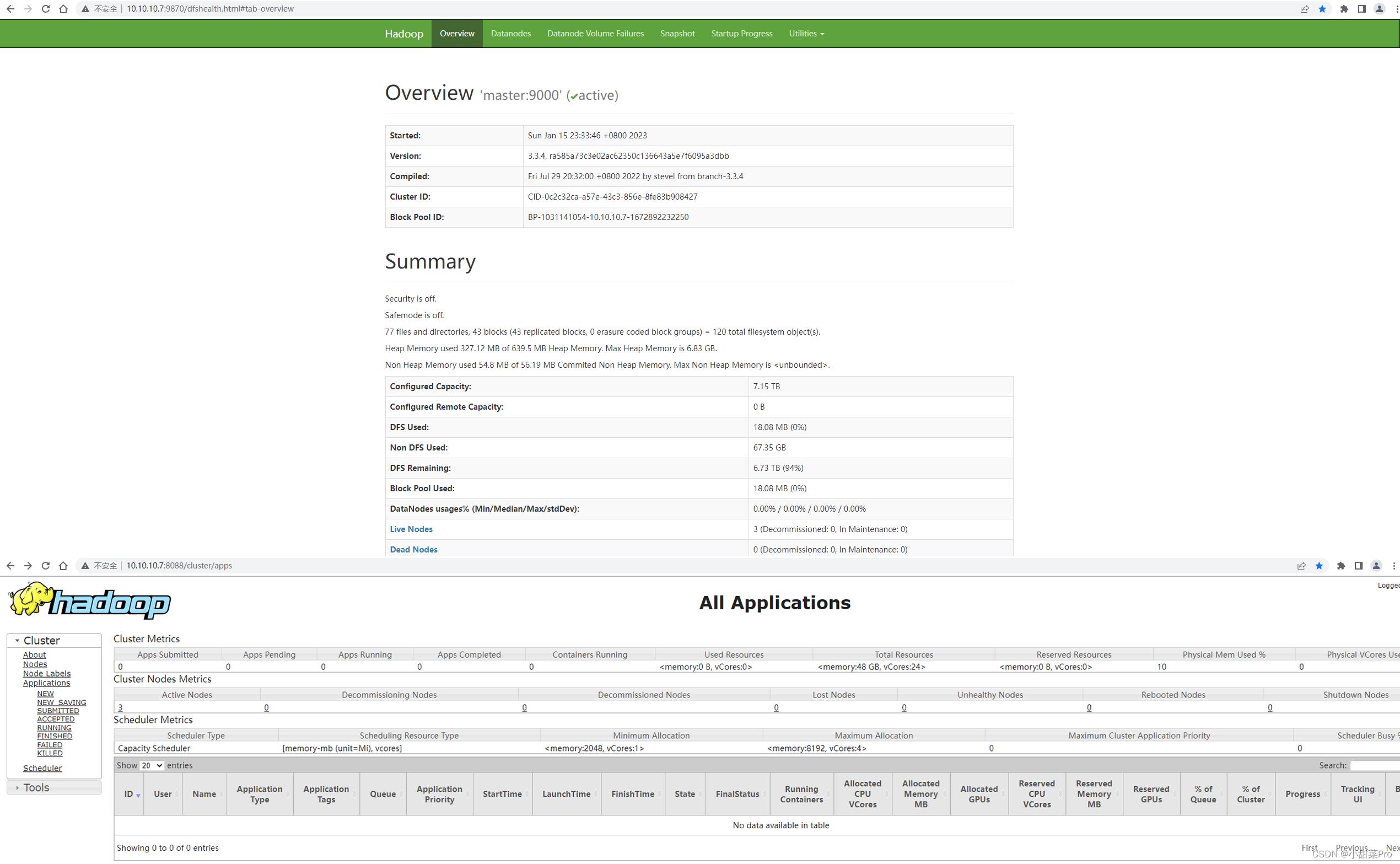
若要关闭集群可以使用$HADOOP_HOME/sbin/stop-yarn.sh && $HADOOP_HOME/sbin/stop-dfs.sh命令。
以上就是本期分享的全部内容,感谢观看!
本文中部分图片来自公开网络,仅供学习交流使用,不会用于任何商业用途,如果侵犯到原著作者权益,请向邮箱xiaotiancaipro@163.com联系删除,谢谢。
以上是关于搭建Hadoop3.x分布式集群的主要内容,如果未能解决你的问题,请参考以下文章