Java中的hashCode,真的很容易弄懂
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java中的hashCode,真的很容易弄懂相关的知识,希望对你有一定的参考价值。
写这篇文章是因为在看hashMap源码时遇到有什么hashcode值,然后就去查,脑袋里面是有印象的,不就是在Object中有equals和hashcode方法嘛,这在学java基础的时候就遇到过,不过那时候无所谓,囫囵吞枣,原理永远不去深挖,就一笔带过去了。今天仔细看了几篇文章,发现hashCode机制很容易弄懂,学习不能有畏难情绪,不然很难进步。
[1] hash、hash表是什么?
hash是一个概念、是一个函数,该函数中的实现就是一种算法,就是通过一系列的算法来得到一个hash值(即hashCode),这个时候,我们就需要知道另一个东西,hash表。
通过hash算法得到的hash值就存在这张hash表中,也就是说,hash表就是所有的hash值组成的,有很多种hash函数,也就代表着有很多种算法得到hash值。
hash值主要是用来在散列存储结构中确定对象的存储地址的,提高对象的查询效率,如HashMap、HashTable等。
[2] hashCode有什么用?
hashCode()的作用是获取哈希码(int整数),也称为散列码。这个哈希码的作用是确定该对象在哈希表中的索引位置。
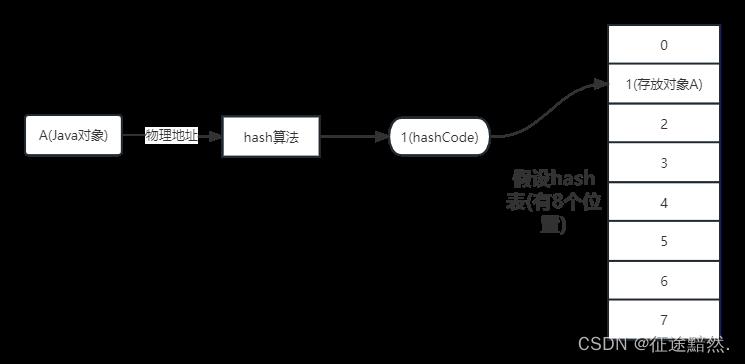
如上图,假设哈希表有8个位置,索引为0-7。此时有一个对象A,它的物理地址会经过hash算法生成一个hashCode,这个哈希值也是在0-7之间的,然后我们把对象A存储在哈希表中索引值为1的位置。
hashCode()定义在JDK的Object类中,这就意味着Java中的任何类都包含有hashCode()函数。另外需要注意的是:Object的hashCode()方法是本地方法,也就是用C语⾔或C++实现的,该方法通常用来将对象的内存地址转换为整数之后返回。
public native int hashCode();
众所周知,native方法更高效。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么hashcode不直接写物理地址?还要另外用一张hash表来代表对象的地址?为什么使用了hashCode就更高效了?
假设我们有一个能存放1000个数这样大的内存中,在其中要存放1000个不一样的数字,用最笨的方法,就是存一个数字,就遍历一遍,看有没有相同得数,当存了900个数字,开始存901个数字的时候,就需要跟900个数字进行对比,这样就很麻烦,很是消耗时间,用hashcode来记录对象的位置,来看一下。hash表中有1、2、3、4、5、6、7、8个位置,存第一个数,hashcode为1,该数就放在hash表中1的位置,存到100个数字,hash表中8个位置会有很多数字了,1中可能有20个数字,存101个数字时,他先查hashcode值对应的位置,假设为1,那么就有20个数字和他的hashcode相同,他只需要跟这20个数字相比较(equals),如果每一个相同,那么就放在1这个位置,这样比较的次数就少了很多,实际上hash表中有很多位置,这里只是举例只有8个,所以比较的次数会让你觉得也挺多的,实际上,如果hash表很大,那么比较的次数就很少很少了。
[3] 为什么总是把hashCode与equals放在一起讨论?它们有什么区别和联系?
由于hashCode在一定程度上可以判断两个对象是否相等,equals也可以判断两个对象是否相等,但是equals有时会被重写,它就不再判断对象的物理地址是否相等了,所以此时我们在设计对象时,得考虑到hashCode与equals的最终结果要符合逻辑。
hashCode与equals的最终结果要符合的逻辑介绍如下:
两个对象有相同的hashCode值,它们不⼀定是相等的。
因为hashCode()所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关(所谓哈希碰撞也就是指的是不同的对象得到相同的hashCode)。
什么情况下,两个对象⼀定是相等的?(这段特别特别重要)
当两个对象的物理地址是一样的,那它们肯定是相等的,是同一个对象。这里就涉及到判等的两个操作:操作符"=="与equals方法:
操作符
"=="与equals方法的区别,可以参考我的历史文章:Java基本类型和包装类什么情况下判断相等(“==“或“equals“)?
当对对象使用操作符"=="时,判断的就是两者的物理地址是否,没问题;
当对对象使用equals方法时,如果equals方法没有被重写,它相当于使用操作符"=="判断两者的物理地址,也没问题;可是如果equals方法被重写了,它判断的不一定是对象的物理地址是否相等,此时就有问题了。
例如String类重写了equals方法判断字符是否相等,当两个字符串相等时equals方法返回false,可是若此时这两个字符串发生hash碰撞了,比较hash值为true,就不一致了。
为什么equals方法重写的话,建议也一起重写hashcode方法?(这段特别特别重要)
首先,说的是“建议”,其实是可以不重写的。重写hashcode是为了满足Java中Hash家族的一些约定俗成的要求。
先以HashSet 如何检查重复来举例Java执行过程:
当你把对象加入HashSet时,HashSet会先计算对象的 hashCode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashCode 值作比较,如果没有相符的hashCode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashCode 值的对象,这时会调用 equals() 方法来检查 hashCode 相等的对象是否真的相同。如果两者相同,HashSet就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
基于上述的流程,Java为了提高Hash家族的效率,它默认两个对象的hash值不同那么它们就不相等。但是只用hash值来判断的话,发生哈希碰撞就无法分辨对象是否相等了。
所以,hash检测相当于第一重保险,第一重保险可以筛选99%,剩下1%才会去equals那里,这样效率嘎嘎高。
总结下来就是:
1、如果两个对象的hashCode值相等,那这两个对象不一定相等(哈希碰撞)。
2、如果两个对象的 hashCode 值相等并且 equals()方法也返回 true,我们才认为这两个对象相等。
3、如果两个对象的 hashCode值不相等,我们就可以直接认为这两个对象不相等。
所以,基于上述3点,equals方法重写的话,建议也一起重写hashcode方法。
以上是关于Java中的hashCode,真的很容易弄懂的主要内容,如果未能解决你的问题,请参考以下文章