Kafka用Zookeeper所做的那些事
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka用Zookeeper所做的那些事相关的知识,希望对你有一定的参考价值。
参考技术A Kafka是高可用的分布式消息系统,首先要解决的就是资源协调分配和多副本状态维护的问题。解决这些问题通常就是两种思路,一是依靠Zookeeper来协调,二是设定一个中心节点,让这个中心节点来协调。如果依靠Zookeeper来协调,会存在大量的竞争条件,对Zookeeper的访问压力增大,而且如果Zookeeper出现了问题(比如网络抖动),系统很容易出现紊乱。Kafka采用的是第二种思路,即选举一个中心节点来进行资源协调与多副本状态维护,这个中心节点被称作Controller(一个特殊的Broker),这个选举过程依靠Zookeeper来完成。
Broker启动时,会竞争创建临时"/controller"。如果创建成功,则成为Controller,并把Broker的id等信息写入这个节点。同时会全程监控"/controller"的数据变化,如果旧的Controller挂掉,则开启新一轮的竞争过程。
Kafka要进行资源协调,第一件需要知道的事情就是各个Broker的存活状态,这个问题利用Zookeeper可以很容易做到。
假设某个Broker,id为0,它启动时,会创建"/brokers/ids/0"临时节点,并把端口等信息写进去。Controller会监控"/brokers/ids"的节点变化,以实时感知各broker的状态,进行资源协调。
在Kafka这个多副本分区的消息系统里,创建一个topic,至少需要以下3个步骤:
Controller的存在,可以很容易完成上面的b和c步骤,但a步骤不行,如果Controller挂掉,则这些信息会不可用。Kafka把这些信息保存在Zookeeper中,依靠其高可用特性来保证这些信息的高可用。假设某个topic名字为mytopic,创建时,其分区信息保存在"/brokers/topics/mytopic"中。Controller全程监控"/brokers/topics"的孩子节点变动,实时感知这些信息,以完成后续步骤。
创建完成之后,后续往往会有分区调整和topic删除等需求。普通青年可能会觉得这两个问题很简单,给Controller发个相关请求就可以了。事实远非如此!
拿分区调整来说,假设某分区有三个副本,分别位于Broker-1、Broker-2和Broker-3,leader为1,现在扩容增加了Broker-4、Broker-5、Broker-6,为了平衡机器间压力,需要将副本1 2 3移到4 5 6,至少经历以下步骤:
以上每个步骤都有可能失败,如何才能保证这次调整顺利进行呢?
首先,我们不能直接修改该分区的副本信息为 4 5 6,原因很简单,需要等待4 5 6的追赶过程以便产生新leader。其次,操作未完全成功的命令需要保存下来,如果操作过程中,Controller挂掉,则新的Controller可以从头开始直至成功。
Kafka怎么做的呢?
当然,这里一次只能有一个调整命令,但一个调整命令可以同时调整多个topic的多个分区。
在这个过程中,Zookeeper的作用是: 持久化操作命令并实时通知操作者 ,是不是只有Zookeeper可以做这个事情呢,不是,但Zookeeper可以做得很好,保证命令高可用。
类似的操作还有topic删除,副本的leader变更等,都是沿用上面的套路。
Broker的集群中有全局配置信息,但如果想针对某个topic或者某个client进行配置呢,Kafka把这些信息保存在Zookeeper中,各个Broker实时监控以更新。
脑裂问题是指,在一个设有中心节点的系统中,出现了两个中心节点。两个中心同时传达命令,自然会造成系统的紊乱。
Kafka利用Zookeeper所做的第一件也是至关重要的一件事情是选举Controller,那么自然就有疑问,有没有可能产生两个Controller呢?
首先,Zookeeper也是有leader的,它有没有可能产生两个leader呢?答案是不会。
quorum机制可以保证,不可能同时存在两个leader获得大多数支持。假设某个leader假死,其余的followers选举出了一个新的leader。这时,旧的leader复活并且仍然认为自己是leader,这个时候它向其他followers发出写请求也是会被拒绝的。因为每当新leader产生时,会生成一个epoch,这个epoch是递增的,followers如果确认了新的leader存在,知道其epoch,就会拒绝epoch小于现任leader epoch的所有请求。那有没有follower不知道新的leader存在呢,有可能,但肯定不是大多数,否则新leader无法产生。Zookeeper的写也遵循quorum机制,因此,得不到大多数支持的写是无效的,旧leader即使各种认为自己是leader,依然没有什么作用。
Kafka的Controller也采用了epoch,具体机制如下:
理论上来说,如果Controller的SessionExpired处理成功,则可以避免双leader,但假设SessionExpire处理意外失效的情况:旧Controller假死,新的Controller创建。旧Controller复活,SessionExpired处理 意外失效 ,仍然认为自己是leader。
这时虽然有两个leader,但没有关系,leader只会发信息给存活的broker(仍然与Zookeeper在Session内的),而这些存活的broker则肯定能感知到新leader的存在,旧leader的请求会被拒绝。
每个Broker有一个metaDataCache,缓存有topic和partition的基本信息,可以正常的生产和消费信息,但不能进行topic的创建、调整和删除等操作。
此外,Broker会不断重试连接。
待续
假设Broker数目为B,topic数目为T,所有topic总partition数目为P,Client数目为C,以下数值均为峰值:
谈谈zookeeper的那些事



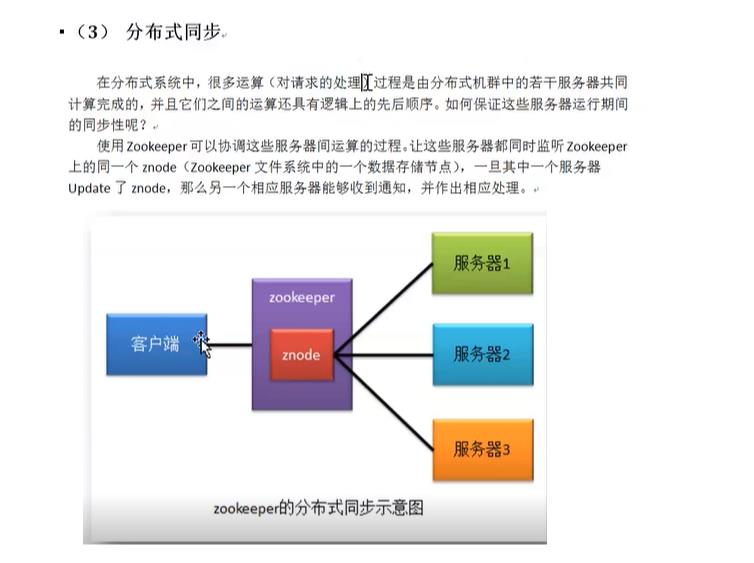


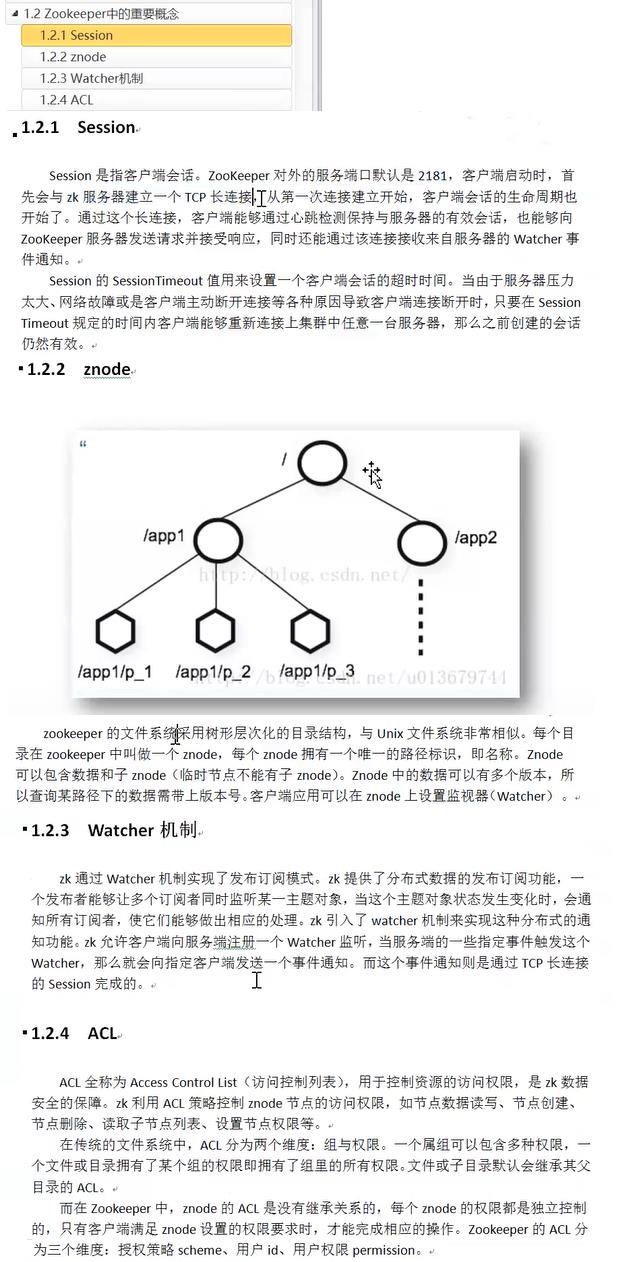




以上是关于Kafka用Zookeeper所做的那些事的主要内容,如果未能解决你的问题,请参考以下文章
Zookeeper 集群+kafka集群+kafka manager搭建
filebeat-2-通过kafka队列链接logstash