Python爬虫之Scrapy框架系列——项目实战某瓣Top250电影所有信息的txt文本存储
Posted 孤寒者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫之Scrapy框架系列——项目实战某瓣Top250电影所有信息的txt文本存储相关的知识,希望对你有一定的参考价值。
上篇文章已经成功解析提取到豆瓣Top250电影想要的所有数据。下一步就是将其交给管道进行存储。
目录:
- 1. 编写items.py文件(定义结构化数据字段)
- 2. 爬虫文件里将数据一一对应字段名:
- 3. 将数据返回给管道:
- 4. 编写pipelines.py文件进行数据存储:
- 5. 某瓣Top250首页25个电影更多信息已经抓取完毕,效果如下:
- 拓展:上面实现了某瓣首页25个电影信息的爬取,那么如何爬取更多页呢?
1. 编写items.py文件(定义结构化数据字段)
- 首先,引擎交给spider(爬虫文件)的信息已经被爬虫解析并提取正确的信息,下一步是spider(爬虫文件)将数据再次交给引擎,而能否成功交给引擎,这就取决于items.py文件(定义结构化数据字段)是否有对应的字段名等待插入数据:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#需要定义字段名 就像数据库那样,有字段名,才能插入数据(即存储数据)
# films_name=scrapy.Field() #定义字段名
film_name=scrapy.Field()
star_name=scrapy.Field()
score=scrapy.Field()
items.py文件中已经创建好字段名等待插入数据了,下一步就是:
2. 爬虫文件里将数据一一对应字段名:
在刚刚的爬虫文件的循环下写入即可:
# 使用字段名 收集数据
item=item=DoubanItem()
item["film_name"]=film_name
item["star_name"]=star_name
item["score"]=score
注意:在settings.py文件中开启管道并关闭robots协议!
3. 将数据返回给管道:
- 引擎将数据交给管道的中间的item这一步已经成功走过去了,下一步就是如何将数据返回给管道:在这里要注意一个问题:惯性思维会让我们在这个函数里定性的使用return返回item,但是,切记return返回的是parse这个方法(会造成只会传给管道第一个电影信息的bug)。而我们所需要的是返回每次解析后的数据,so我们想到了生成器,使用yield返回,这样每搞一次数据出来,生成器就给一次数据,循环如此,非常nice!!!
我们只需在爬虫文件的循环最底下加入即可:
# 形式:"film_name":"肖申克的救赎","star_name":"蒂姆","score":"9.7"
yield item
4. 编写pipelines.py文件进行数据存储:
- 引擎已经将数据交给管道(即pipelines.py管道文件),但是,我们这是25个请求,就会进行25次处理,也就意味着,引擎会交给管道25次数据,那么我们在管道里进行储存数据的时候,按往常来说就要来来回回打开关闭文件,进行数据的写入。这样显然不好。所以:在此引入管道文件里的两种牛批的方法:
#爬虫文件开启,此方法就开启
def open_spider(self,spider):
pass
#爬虫文件关闭,此方法就开启
def close_spider(self,spider):
pass
-
这就非常合我们的需求,结合这两个方法,我们只需要在open_spider()方法里加入打开文件操作;在close_spider()方法里加入关闭文件操作即可,这样就避免了文件的来来回回的开启关闭,好处不言而喻。
-
来看看升级版的pipelines.py文件(管道文件):
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
class DoubanPipeline(object):
def open_spider(self,spider): #爬虫文件开启,此方法就开启
self.f=open("films.txt","w",encoding="utf-8") #打开文件
def process_item(self, item, spider): #会来25次,就会调用25次这个方法 如果按常规来写,文件就会被操作25次打开关闭
#为了能写进text json.dumps将dic数据转换为str
json_str=json.dumps(dict(item),ensure_ascii=False)+"\\n"
self.f.write(json_str) #爬虫文件开启时,文件就已经打开,在此直接写入数据即可!
return item
def close_spider(self,spider): #爬虫文件关闭,此方法就开启
self.f.close() #爬虫文件关闭时,引擎已经将全部数据交给管道,关闭文件
5. 某瓣Top250首页25个电影更多信息已经抓取完毕,效果如下:
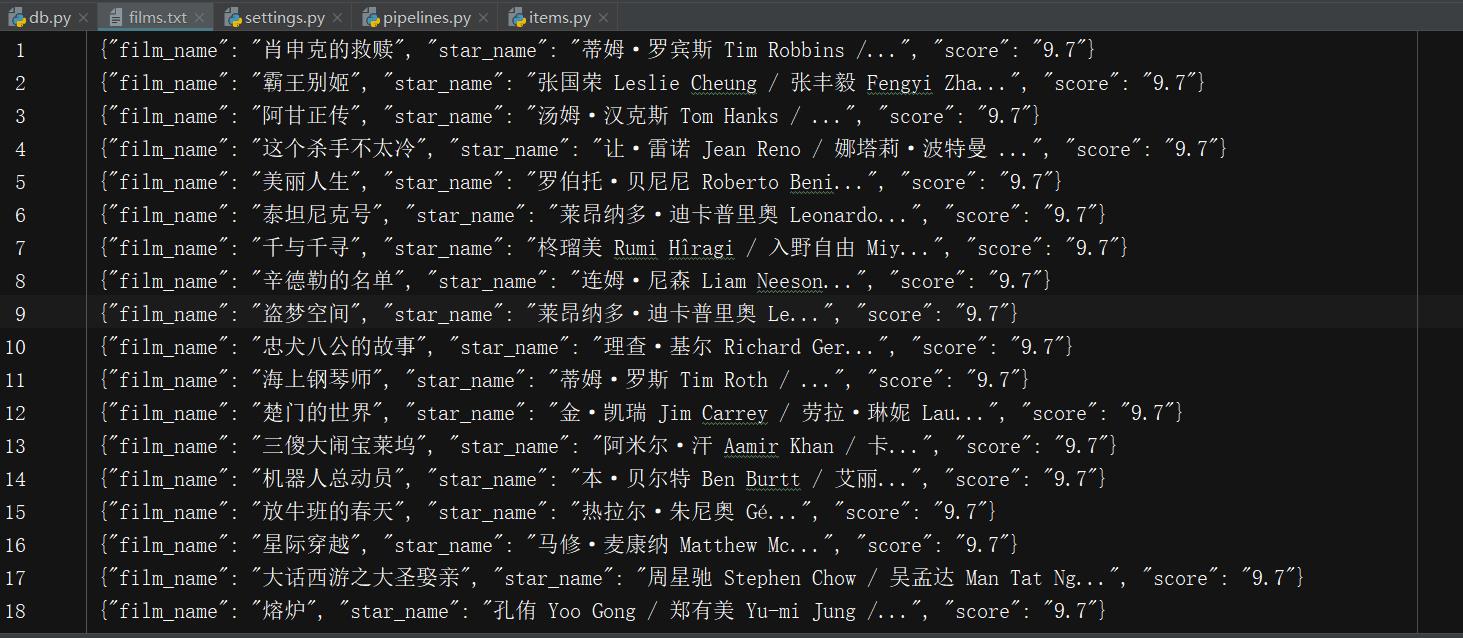
拓展:上面实现了某瓣首页25个电影信息的爬取,那么如何爬取更多页呢?
1. 首先,分析如何爬取两页:
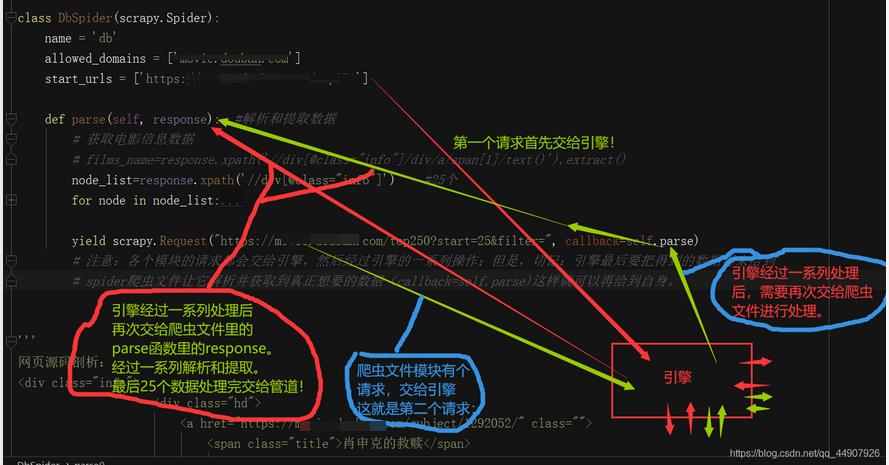
- 注意:Scrapy框架运行的流程,任何模块发出的请求都是给到引擎的,所以,我们只需要在爬虫文件中的第一次请求的数据提交给管道之后,使用yield发起一个请求(某瓣电影Top250第二页的url),那么,这个请求就会自动的交给了引擎,就开启了新一轮的自动化走流程,但是,在最后引擎需要将数据再送给spider爬虫文件让其解析并获取真正想要存储到管道的数据,所以就需要callback回调自身这个parse函数。
逻辑如下图:
2. 获取两页的信息都可以实现了,那么获取更多(比如:10页),只要找到每页url的规律,给个循环就OK啦!
2.1 剖析每页url可知:每加一页,对应的start参数的值就会加25。
'''
各页url规律剖析:
https://xxx.com/top250
https://xxx.com/top250?start=0&filter=
https://xxx.com/top250?start=25&filter=
https://xxx.com/top250?start=50&filter=
'''
2.2 在爬虫文件每个请求执行完成功之后,利用格式化输出.format()方法向引擎发送每页的请求即可!
- (每完成一个请求的全部流程,page_num就会加一,25倍的page_num就对应了每页url的start参数的值;注意:我们会发现总共就10页有信息,多了就没得信息了,所以设置了if判断,如果url获取的信息为空,就返回空,引擎接到空的请求,就会自动关闭)
# -*- coding: utf-8 -*-
import scrapy
import re
from ..items import DoubanItem # 因为我们要使用包含定义字段名的类,所以需要导入
class DbSpider(scrapy.Spider):
name = 'db'
allowed_domains = ['xxx.com']
start_urls = ['xxx/top250']
page_num = 0 # 类变量
def parse(self, response): # 解析和提取数据
# 获取电影信息数据
# films_name=response.xpath('//div[@class="info"]/div/a/span[1]/text()').extract()
node_list = response.xpath('//div[@class="info"]') # 25个
if node_list: # 此判断的作用:在爬取到10页之后,就获取不到了!判断每次是否获取到数据,如果没有则返回空(即停止了)
for node in node_list:
# 电影名字
film_name = node.xpath('./div/a/span[1]/text()').extract()[0]
# 主演 拿标签内容,再正则表达式匹配
con_star_name = node.xpath('./div/p[1]/text()').extract()[0]
if "主" in con_star_name:
star_name = re.findall("主演?:? ?(.*)", con_star_name)[0]
else:
star_name = "空"
# 评分
score = node_list.xpath('./div/div/span[@property="v:average"]/text()').extract()[0]
# 使用字段名 收集数据
item = DoubanItem()
item["film_name"] = film_name
item["star_name"] = star_name
item["score"] = score
# 形式:"film_name":"肖申克的救赎","star_name":"蒂姆","score":"9.7"
yield item # 不使用return的原因是,return返回的是parse这个方法(会造成只会传给管道第一个电影信息的bug)。而我们所需要的是返回每次解析后的数据
self.page_num += 1
print("page_num:", self.page_num)
page_url = "xxx/top250?start=&filter=".format(self.page_num * 25)
yield scrapy.Request(page_url, callback=self.parse)
# 注意:各个模块的请求都会交给引擎,然后经过引擎的一系列操作;但是,切记:引擎最后要把得到的数据再来给到
# spider爬虫文件让它解析并获取到真正想要的数据(callback=self.parse)这样就可以再给到自身。
else:
return
'''
各页url规律剖析:
https://xxx.com/top250
https://xxx.com/top250?start=0&filter=
https://xxx.com/top250?start=25&filter=
https://xxx.com/top250?start=50&filter=
'''
'''
网页源码剖析:
<div class="info">
<div class="hd">
<a href="https://xxx.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span property="v:best" content="10.0"></span>
<span>1983356人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
'''
切记:
要在settings.py文件中开启延时。
不然:网站很容易检测出来,后果严重!!!

2.3 运行会发现很棒哦!

以上是关于Python爬虫之Scrapy框架系列——项目实战某瓣Top250电影所有信息的txt文本存储的主要内容,如果未能解决你的问题,请参考以下文章