Redis集群cluster实操
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis集群cluster实操相关的知识,希望对你有一定的参考价值。
参考技术A 先如今我们想要自己搭建一套多redis节点/实例的集群,实现一套无主模型的集群Redis 集群的数据分片
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
我们先去到存放redi源码目录下,打开utils目录,会发现里面有个create-cluster文件夹,进入这个文件夹,会发现有如下两个文件:
我们先打开README文件看看里面是写了什么?
我们再来看看creat-cluster这个脚本文件里面装着什么药?
我们分析一下最前面的内容:
我们先把redis运行起来,执行以下指令后,会发现有启动了6个端口,代表着启动了6台redis
我们再这6台redis,进行搭建集群,“分赃”(是指分给每个master给一些槽位),执行以下指令后,会发现其中的30005跟随30001,其中的30006跟随30002,其中的30004跟随30003
我们看到,这个redis cluster为其中的3个master准备了一些槽位:
这个时候我们尝试连接其中一个master,随便哪个,我这里连接的是30001端口,然后做了一些操作,你会发现下面的图片中,有两句指令是报错的,只有第一句指令是返回OK的,是什么原因呢?
redis-cli -p 30001
使用以下指令就可以重定向到对应映射值的端口上
我们尝试一下能不能使用事务,如下图,我们开启事务后,中间是有几次经过hash算法之后重定向到其他端口上面的,到最后我们执行exec之后报错。是因为我们在30001上开启的事务,由于hash值映射我们重定向到其他端口上了,其他端口并没有开启事务,所以报错!
我们可以将某些类似于相同hash值的key放在一块执行,这样就可以避免重定向,从而实现事务操作
接下来我们换一种方式来进行实现redis cluster,用原始的命令来实现。我们先把启动的redis关掉,并把持久化文件删除,然后再启动
使用redis原生命令来启动,我们先查询help
输入指令原生指令,启动redis cluster,启动成功,和刚才的一模一样
我们再尝试连接客户端,进行一些操作,和我们用脚本启动一模一样
解下来我们再了解一些reshard这个指令,给数据从新分片
输入指令后,redis会提示我们要移出多少个槽位,我们随便填个3000,然后回车
接下来,将接收方的节点id输入进去,目的是要把这3000个槽位移动给接收方
注意我们这里提示错误,原因是我们移动给了一个不是master的节点
我们给一个master的节点id重来一遍,接着要我们提供槽位来源,可以选一个或者多个槽位来源,比如我们要把3000个槽位移动给30002端口,我们可以从30001上移动也可以从30003上移动,我们直接在30001上移过来
输入yes回车
等待一会,我们看到3000个节点,从30001移动到30002端口上面了
我们可以查看槽位分布情况
原先是分布比较平均,都是5461个槽位,而我们从30001移动3000个到30002,发现原来的30001的只剩下2461个槽位的确少了3000个,并且30002的现在由8462个槽位多了3000个槽位!
种种现象我们看到,这完全就符合我们开头说的,用数据哈希槽的方式去分片数据,也就redis内部实现的预分区
Redis集群Cluster集群
在哨兵模式中,仍然只有一个Master节点,当并发写请求较大时,无法缓解写的压力,在3.0版本Redis-Cluster出现解决了这个问题
Redis-Cluster集群特点:
1)由多个Redis服务器组成的分布式网络服务集群
2)集群之中由多个Master主节点,每一个主节点都可读可写
3)节点之间相互通信,两两相连
4)Redis集群无中心节点
在Redis-Cluster集群中,可以为每一个主节点添加从结点,主节点和从结点遵循主从模型的特性(添加从节点可以扩展系统的读性能)
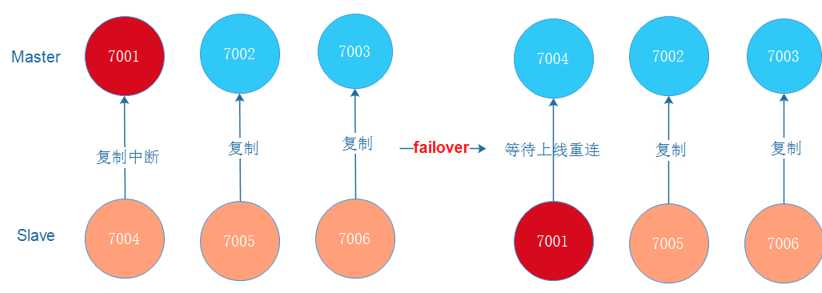
Redis-Cluster集群的故障转移机制:
Redis-Cluster集群的故障转移机制和Redis Sentinel基本一样,区别在于Redis-Cluster集群的故障转移是由集群中其他在线的主节点负责进行的,所以集群不必另外使用Redis Sentinel
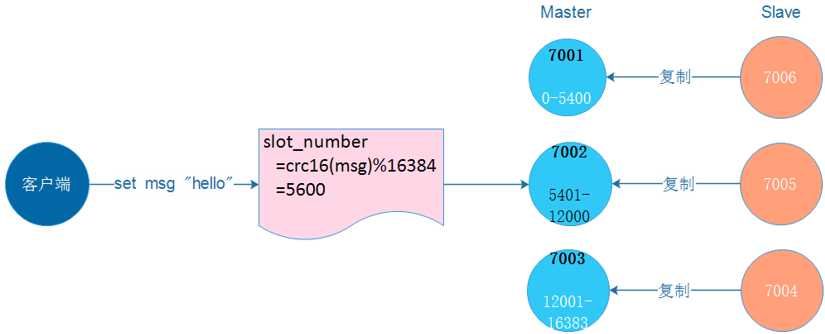
Redis-Cluster集群分片策略:
分片策略主要是解决key存储位置的
集群将整个数据库分为16384个槽位(solt),所有的key-value数据都存储在这些solt的某一个中,而一个槽位可以存放多个数据,key的槽位计算公式为:slot_number=crc16(key)%16384,其中crc16为16位循环冗余校验和函数。
集群中的每个主节点都可以处理0个至16383个槽,当16384个槽都有某个节点在负责处理时,集群进入上线状态(反之则处于瘫痪状态),并开始处理客户端发送的数据命令请求。
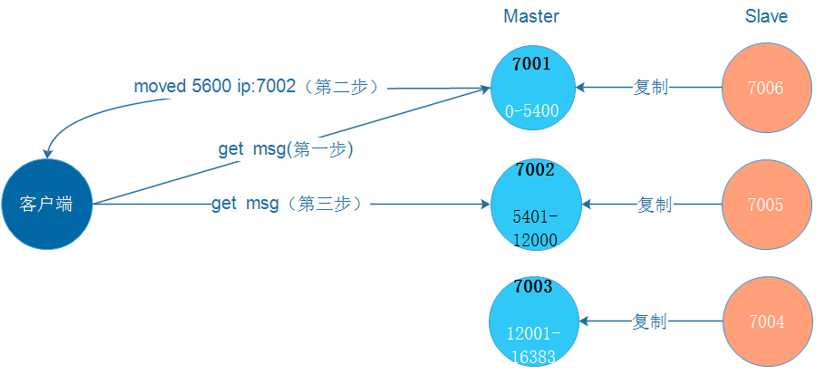
Redis-Cluster集群redirect
由于Redis集群无中心节点,请求会随机发给任意主节点:
主节点只会处理自己负责槽位的命令请求,其它槽位的命令请求,该主节点会返回客户端一个转向错误;
客户端根据错误中包含的地址和端口重新向正确的负责的主节点发起命令请求。
配置流程:
1.环境搭建
1.1安装ruby环境


1.2安装ruby和redis的接口程序,利用xftp将redis-3.0.0.gem拷贝至/usr/local下安装

2.集群的规划
由于物理机数量有限,本文将采用同一台主机构建一个伪分布式集群,以不同端口表示不同的redis节点:
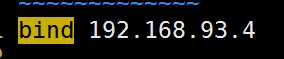
主节点:192.168.93.4:7001 192.168.93.4:7002 192.168.93.5:7003
从结点:192.168.93.4:7004 192.168.93.4:7005 192.168.93.5:7006
在/usr/local/下创建redis-cluster目录,7001~7006
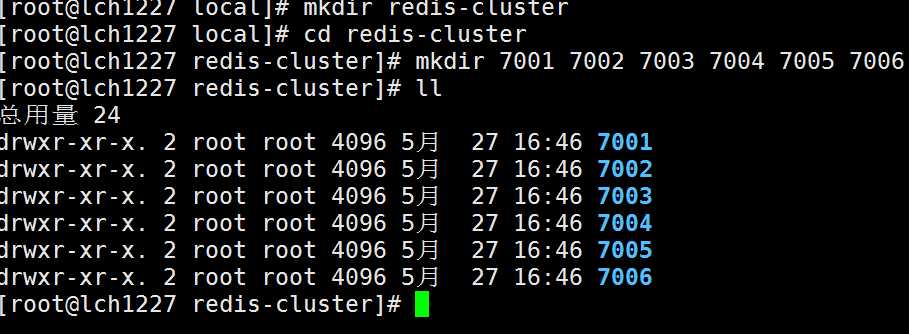
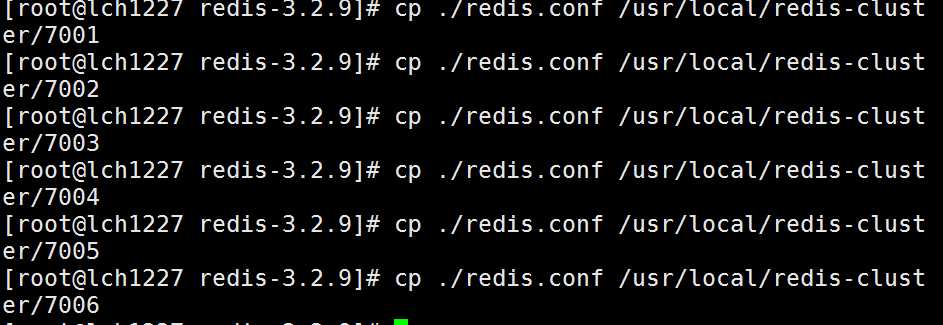
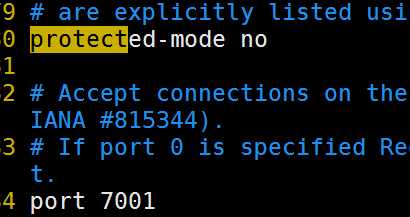
3.将redis解压路径下的配置文件redis.conf,依次拷贝到7001~7006目录中,并修改(port、bind、protected-mode、cluster)
建议配置(daemonized yes 后台启动,logfile /usr/local/redis/redis-cluster/700X/node.log日志输出位置)
7001的配置


其他节点配置同7001
4.指定各个节点的配置文件启动客户端


5.执行创建集群的命令(进入redis安装源码src下)

创建成功
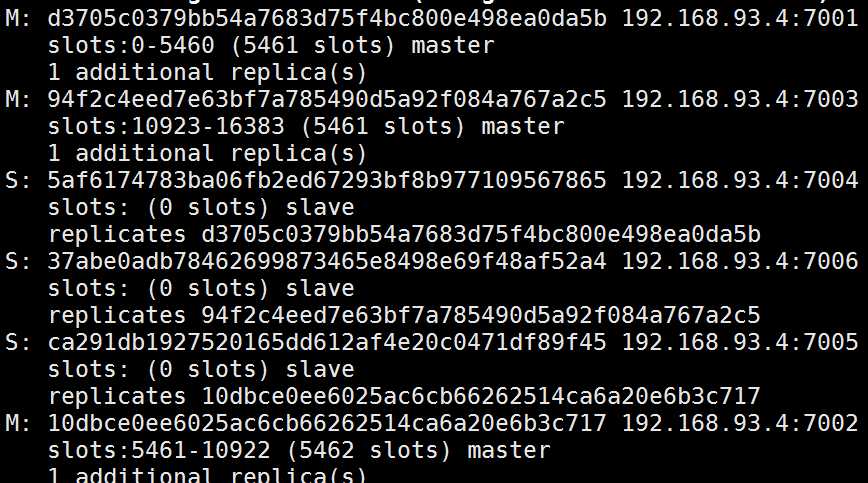
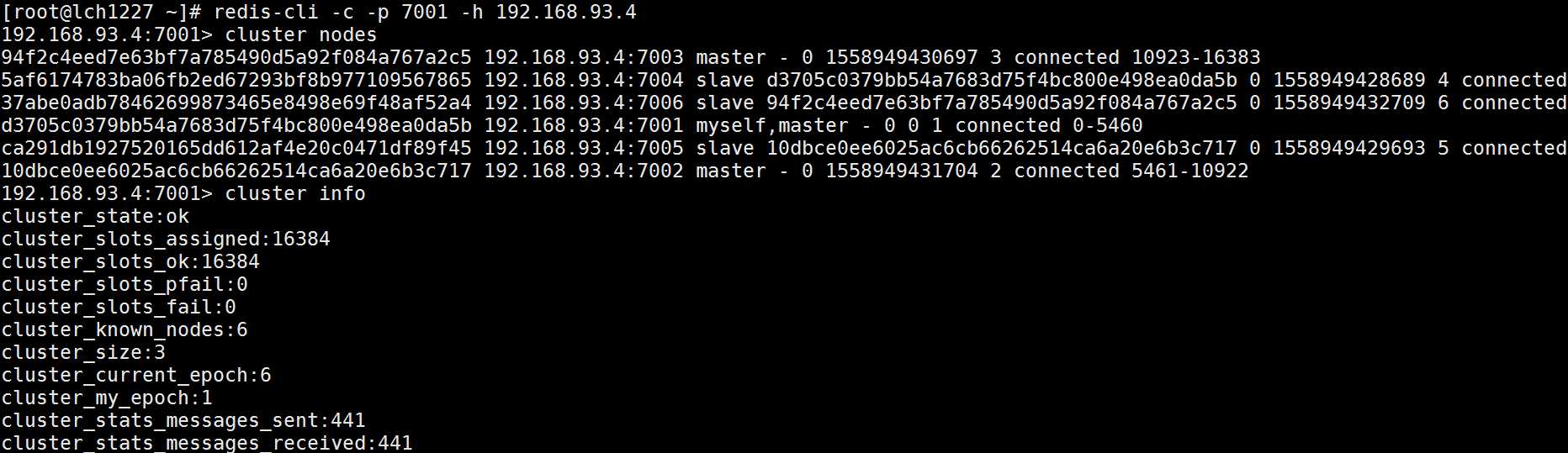
利用客户端查看集群信息
-c表示以集群方式连接redis,
-h指定ip地址,
-p指定端口号
cluster nodes 查询集群结点信息;
cluster info 查询集群状态信。
添加主节点:
下面是添加一个master主节点添加7007节点,添加一个“7007”目录作为新节点,配置信息同前面7001~7006配置
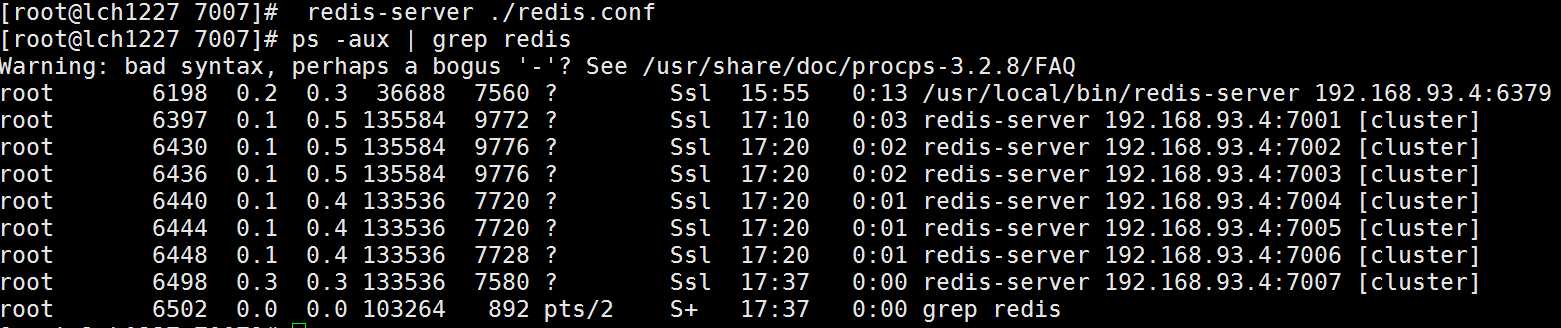

通过客户端7007发现已加入到集群中
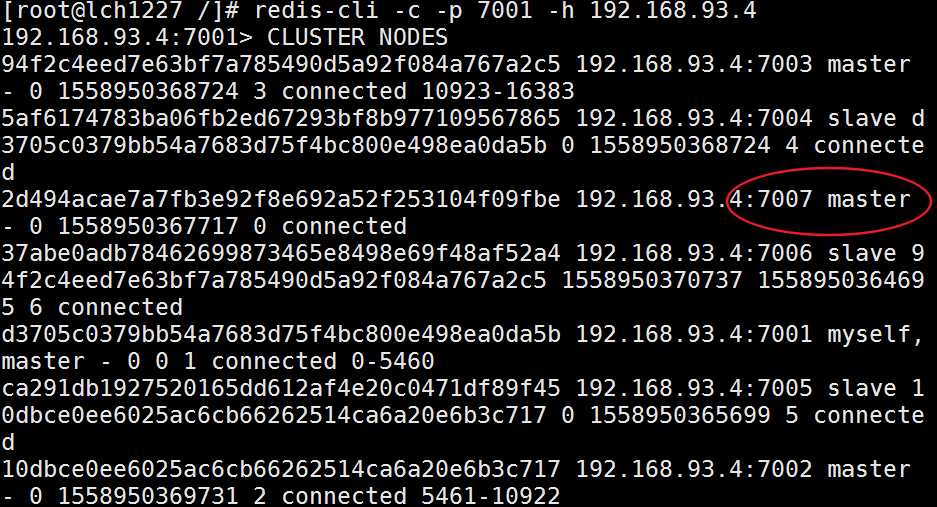
为7007节点分配hash槽,才能存储数据
1)先连上集群
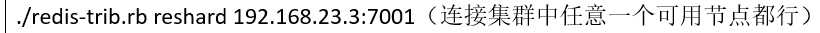
2)输入hash槽的数量
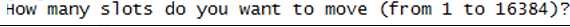
3)输入7007节点的id值
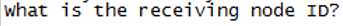
 4)输入分配槽点的源节点id
4)输入分配槽点的源节点id

输入all则为从每一主节点中分配
5)同意分配计划,或取消重新分配
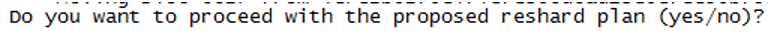
通过客户端查看集群状态

添加从节点(先配置7008的基础信息,同上7001~7007)
到src目录下添加从节点

添加成功

通过客户端查看集群状态

以上是关于Redis集群cluster实操的主要内容,如果未能解决你的问题,请参考以下文章