iText7高级教程之html2pdf——5.自定义标签和CSS应用
Posted CuteXiaoKe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了iText7高级教程之html2pdf——5.自定义标签和CSS应用相关的知识,希望对你有一定的参考价值。
作者:CuteXiaoKe
微信公众号:CuteXiaoKe
{kind=link}
在本章中,我们将更改pdfhtml插件的两个最重要的内部机制。
- 我们将覆盖将HTML标签与iText对象匹配的默认功能,更具体地说是
DefaultTagWorkerFactory机制,以及 - 我们将覆盖将CSS样式与iText样式相匹配的默认功能,更具体地说是
DefaultCssApplierFactory机制。
其中一些示例将是很人为化的,但通过这些案例,我们可以更好地了解pdfHTML的内部工作原理。
1. 更改标签的行为
到目前为止,我们始终隐式使用DefaultTagWorkerFactory类。这是一个实现ITagWorkerFactory接口的类。此工厂接口中只有一个方法:getTagWorker(IElementNode tag,ProcessorContext context)/getTagWorker(IElementNode tag,ProcessorContext context)。方法参数:
IElementNode对象可以为你提供有关正在处理的标签的信息(例如标签的名称);ProcessorContext可以让你访问PdfDocument和其他几个转换器属性。
getTagWorker()/GetTagWorker()方法返回一个ITagWorker实例。
DefaultTagWorkerFactory实现getTagWorker()/GetTagWorker()方法,并使用DefaultTagWorkerMapping对象将标签的名称映射到ITagWorker实例。此映射存储在TagProcessorMapping实例中。
以下是标签worker默认映射的一些示例:
<p>-标签映射到PTagWorker类,<span>-标签映射到SpanTagWorker类,<a>-标签映射到ATagWorker类,这个类继承SpanTagWorker类,<b>-标签和<i>-标签也映射到SpanTagWorker类。这些标签被认为是特殊类型的<span>-标签。- …等等
PTagWorker、SpanTagWorker、ATagWorker等都实现了ITagWorker接口,更具体地说,它们实现了以下四种方法:
processContent()/ProcessContent()——处理元素的打开和关闭标签中存在的任何文本内容,processTagChild()/ProcessTagChild()——处理嵌套在元素的打开和关闭标签中的其他标签,processEnd()/ProcessEnd()——包含在处理完所有其他内容后执行的代码,以及getElementResult()/GetElementResult()——可用于取回最终结果,即IPropertyContainer实例。
这些标签worker类负责创建和填充iText对象。例如:PTagWorker类有一个Paragraph对象作为成员变量。当遇到<p>标签时,将执行以下步骤:
Paragraph成员变量的实例在PTagWorker对象的构造函数中创建,- 内容在
processContent()/ProcessContent()和processTagChild()/ProcessTagChild()方法中收集, Paragraph在processEnd()/ProcessEnd()方法中最终确定下来,并且getElementResult()/GetElementResult()方法返回最终确定的Paragraph。
在第一个例子中,我们将从第2章(2_inline_css.html文件)中选取一个示例,但我们将以这样的方式更改标签worker工厂,即将<a>-标签视为<span>标签。图5.1显示了生成的PDF。
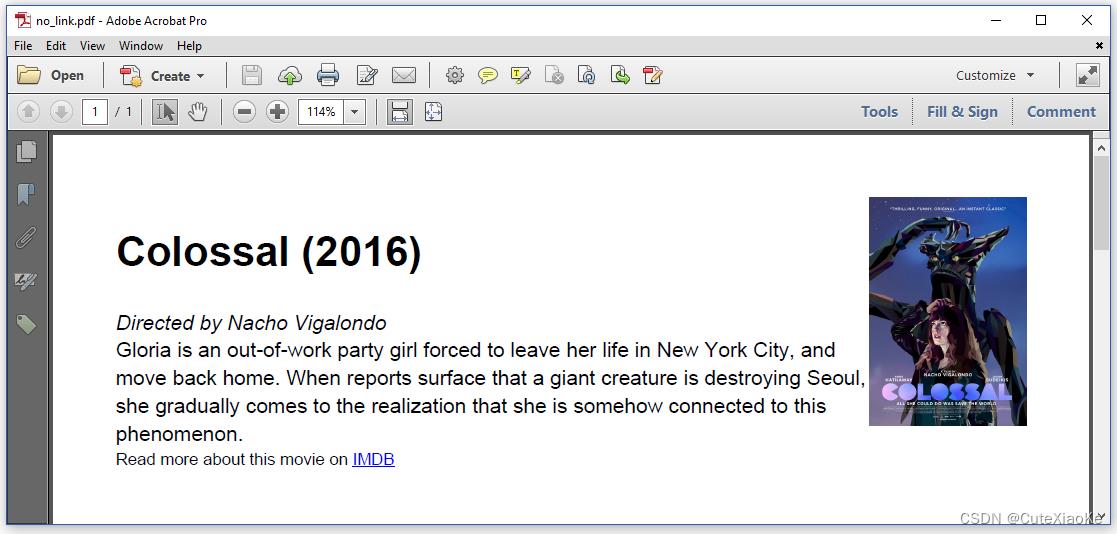
这个文档看起来与我们在第2章中得到的结果完全相同,但当我们尝试在实际的PDF中单击IMDB链接时,什么都没有发生。HTML中的链接不再是PDF中的链接,因为我们使用ConverterProperties的方法更改了setTagWorkerFactory()/SetTagWorkerFactory()默认的标签worker工厂。代码如下:
public void createPdf(String src, String dest) throws IOException
ConverterProperties converterProperties = new ConverterProperties();
converterProperties.setTagWorkerFactory(
new DefaultTagWorkerFactory()
@Override
public ITagWorker getCustomTagWorker(
IElementNode tag, ProcessorContext context)
if ("a".equalsIgnoreCase(tag.name()) )
return new SpanTagWorker(tag, context);
return null;
);
HtmlConverter.convertToPdf(new File(src), new File(dest), converterProperties);
当然,我们可以创建ITagWorkerFactory接口的全新实现,但这将是一项巨大的工作。我们希望尽可能多地利用现有的pdfHTML功能,以便能够正确地呈现<div>、<h1>等标签。
我们可以通过重用DefaultTagWorkerFactory中已经存在的功能来做到这一点。DefaultTagWorkerFactory有一个名为getCustomTagWorker()/GetCustomTagWorkers()的方法,该方法始终返回空值null。此方法始终是DefaultTagWorkerFactory的getTagWorker()/GetTagWorker()的实现方法中调用的第一个方法。
- 如果
getCustomTagWorker()/GetCustomTagWorkers()方法返回null(除非重写该方法,否则始终是这种情况),则使用默认的标签工作者映射。例如:如果遇到<a>-标签,则返回ATagWorker实例。 - 如果
getCustomTagWorker()/GetCustomTagWorkers()方法未返回null(在我们上面的“重写”版本中可能是这种情况),则默认映射将被忽略。例如:如果在我们的示例中遇到<a>-标签,则返回SpanTagWorker实例,而不是期望的ATagWorker。
我们还没有覆盖任何CSS appliers,这解释了为什么IMDB这个词被加下划线并呈现为蓝色,但由于我们从功能和结构的角度将<a>-标签视为<span>-标签,因此没有添加任何链接。编写此示例是为了解释pdfHTML的内部工作原理。我们在第一个例子中所做的很容易被认为是引入了一个bug。
但这并不意味着没有任何有用的用例。例如,我们可以扩展DefaultTagWorkerFactory以支持自定义标签。
2. 引入自定义标签
假设我们想向不同的人发送邀请函。我们用HTML创建了这封邀请函(请见invitation.html),但我们引入了两个非真实的自定义标签,非现有的HTML语法:<name>和<date>,html文件内容如下:
<html>
<head>
<title>Invitation to SXSW 2018</title>
</head>
<body>
<u><b>Re: Invitation</b></u>
<br>
<p>Dear <name>SXSW visitor</name>,
we hope you had a great SXSW film festival experience last year.
And we would like to invite you to the next edition of SXSW Film
that takes place from March 9 until March 17, 2018.</p>
<p>Sincerely,<br>
The SXSW crew<br>
<date>August 4, 2017</date></p>
</body>
</html>
我们使用createPdf()/CreatePdf()方法把这个html文件转换成PDF:
public void createPdf(String src, String dest) throws IOException
HtmlConverter.convertToPdf(new File(src), new File(dest));
如果我们查看图5.2,我们会看到“SXSW visitor”和“August 4, 2017”作为常规文本。与其他内容没有明显区别。未知标签被视为普通的<span>标签。
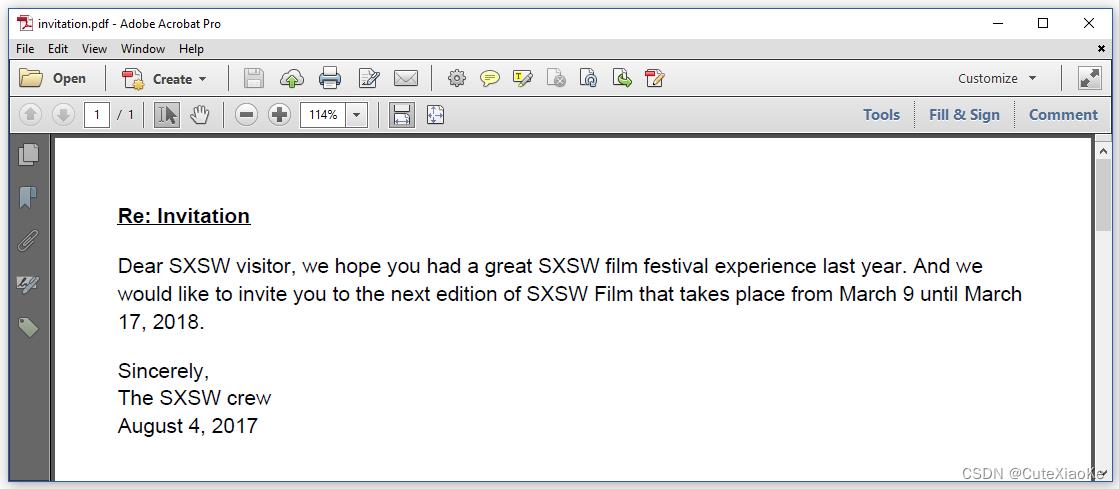
让我们来看接下来的例子,在main()方法找那个,我们使用同一个HTML,但是生产不同三个PDF文件,代码如下:
String[] names = "Bruno Lowagie", "Ingeborg Willaert", "John Doe";
int counter = 1;
for (String name : names)
app.createPdf(name, SRC, String.format(DEST, counter++));
在这个示例的createPdf()/CreatePdf()方法中,我们根据DefaultTagWorkerFactory上创建一个变体,该变体为标签<name>和<date>返回SpanTagWorker。并且我们重写这些SpanTagWorker实例的processContent()/ProcessContent()方法,从而忽略实际内容(content变量)。相反,name或今天的日期作为内容传递。代码如下:
public void createPdf(String name, String src, String dest) throws IOException
SimpleDateFormat sdf = new SimpleDateFormat("MMMM d, yyyy", Locale.ENGLISH);
ConverterProperties converterProperties = new ConverterProperties();
converterProperties.setTagWorkerFactory(
new DefaultTagWorkerFactory()
@Override
public ITagWorker getCustomTagWorker(
IElementNode tag, ProcessorContext context)
if ("name".equalsIgnoreCase(tag.name()) )
return new SpanTagWorker(tag, context)
@Override
public boolean processContent(
String content, ProcessorContext context)
return super.processContent(name, context);
;
else if ("date".equalsIgnoreCase(tag.name()) )
return new SpanTagWorker(tag, context)
@Override
public boolean processContent(
String content, ProcessorContext context)
return super.processContent(
sdf.format(new Date()), context);
;
return null;
);
HtmlConverter.convertToPdf(new File(src), new File(dest), converterProperties);
此代码将导致默认内容(“SXSW visitor”和“August 4, 2017”)替换为特定名称和今天的日期。生成的PDF如图5.3所示。
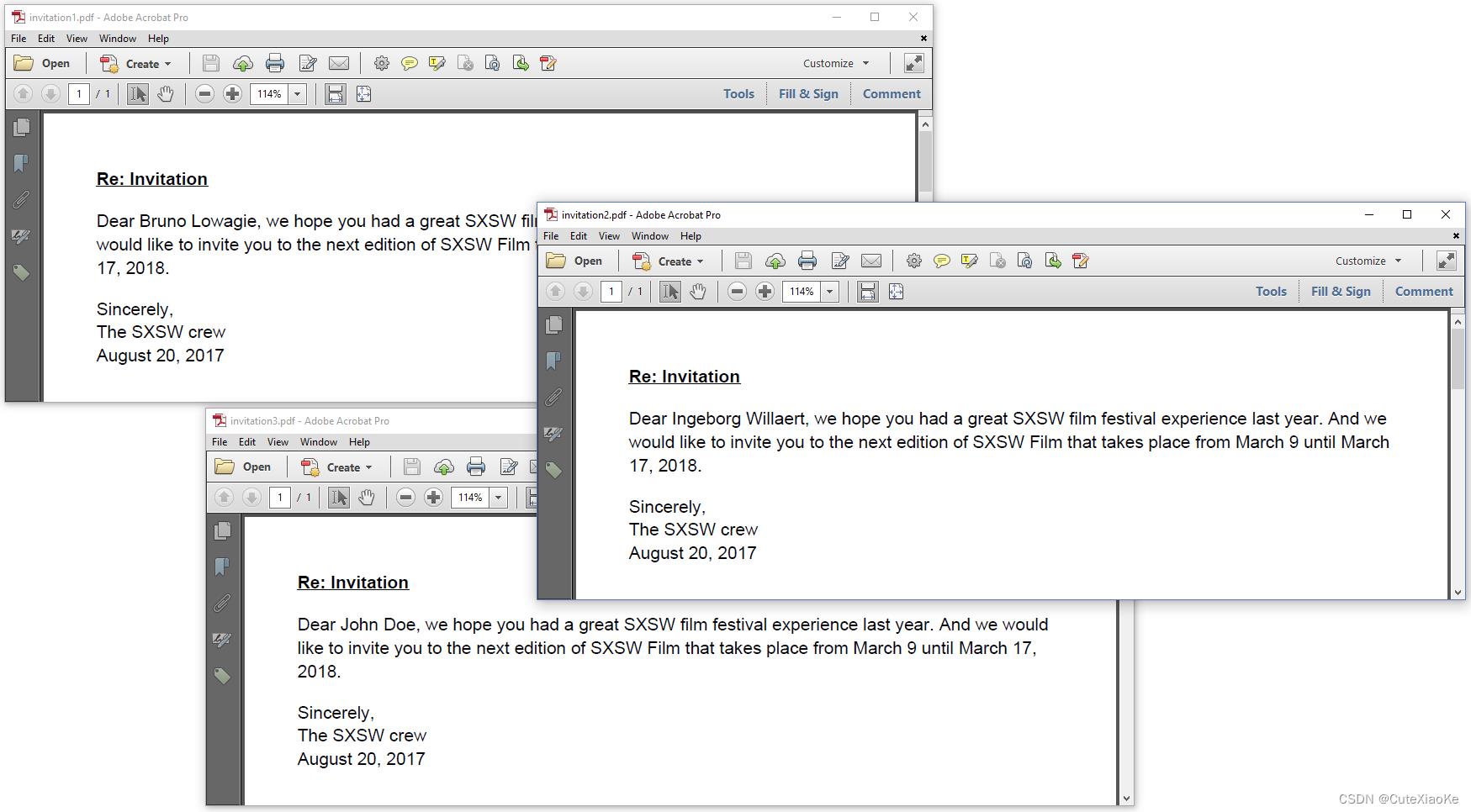
在某些情况下,不可能重用现有的ITagWorker的任意实现。我们必须创建自己的标签worker程序。
3. 创建你自己的ITagWorker实现
假设我们想要创建一个显示QR二维码的PDF文档,例如基于qrcode.html文件:
<html>
<head>
<meta charset="UTF-8">
<title>QRCode Example</title>
<link rel="stylesheet" type="text/css" href="css/qrcode.css"/>
</head>
<body>
<h1>SXXpress codes</h1>
<p>Bruno Lowagie has a South by Express pass for the following movies:
<p>Colossal</p>
<qr charset="Cp437" errorcorrection="Q">
Film: Colossal; Date: Friday, March 10; Time: 6:15 PM; Place: Alamo Lamar D
</qr>
<p>Mr. Roosevelt</p>
<qr charset="Cp437" errorcorrection="L">
Film: Mr. Roosevelt; Date: Sunday, March 12; Time: 2:15 PM; Place: Paramount Theatre
</qr>
</body>
</html>
HTML中没有<qr>-标签,因此当我们在浏览器中打开此HTML文件时,我们只能看到文本。然而,我们可以使用此HTML文件创建带有QR码而不是文本的PDF文档。如图5.4。
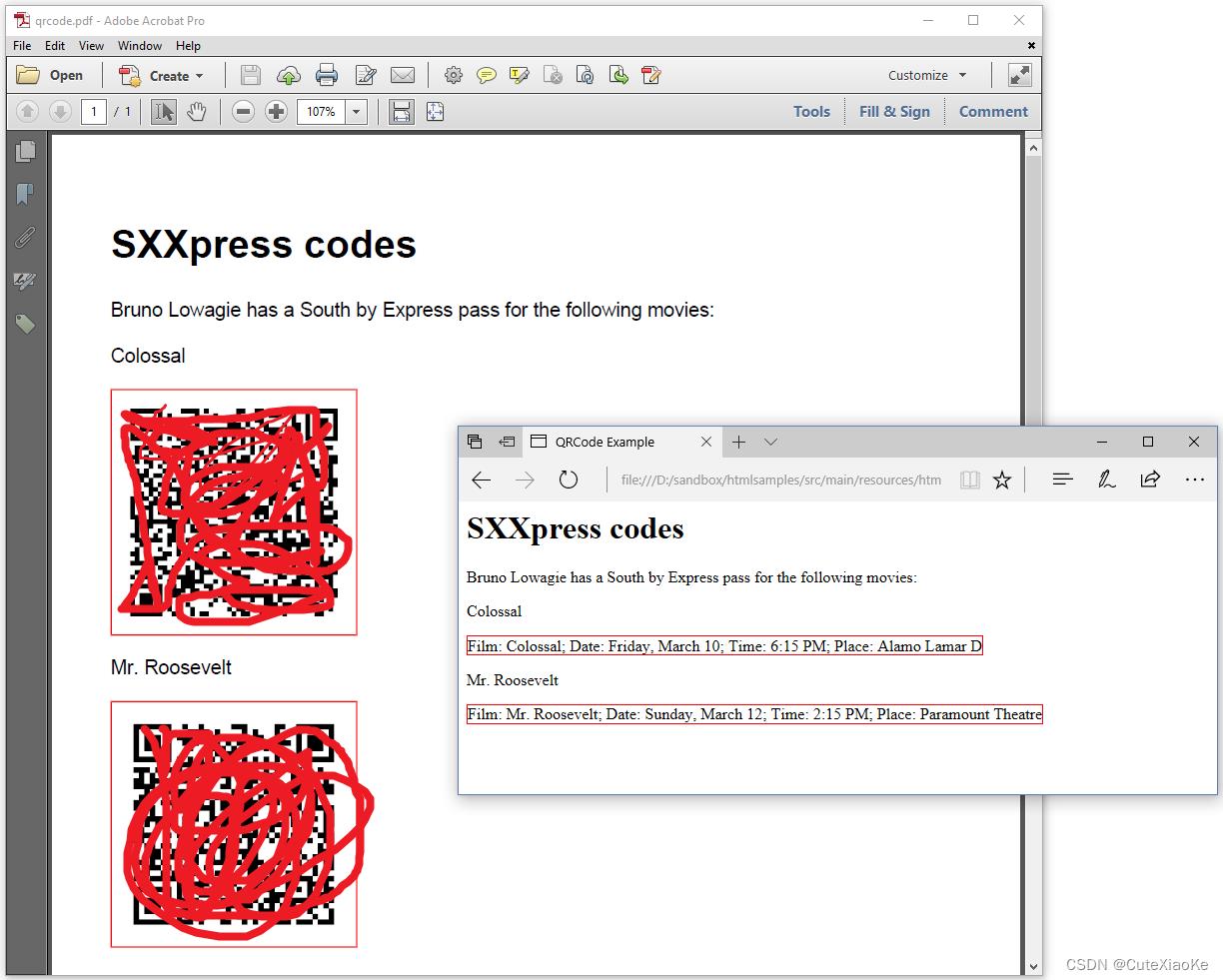
HTML文件中的文本有一个红色边框,因为这就是我们如何在qrcode.css文件中定义<qr>-标签的样式:
qr
border:solid 1px red;
height:200px;
width:200px;
这次,我们创建了一个继承扩展DefaultTagWorkerFactory类的QRCodeTagWorkerFactory:
class QRCodeTagWorkerFactory extends DefaultTagWorkerFactory
@Override
public ITagWorker getCustomTagWorker(IElementNode tag, ProcessorContext context)
if(tag.name().equals("qr"))
return new QRCodeTagWorker(tag, context);
return null;
如果遇到<qr>-标签,我们将其映射到QRCodeTagWorker。此QRCodeTagWorker需要实现ITagWorker接口:
static class QRCodeTagWorker implements ITagWorker
private static String[] allowedErrorCorrection =
"L","M","Q","H";
private static String[] allowedCharset =
"Cp437","Shift_JIS","ISO-8859-1","ISO-8859-16";
private BarcodeQRCode qrCode;
private Image qrCodeAsImage;
public QRCodeTagWorker(IElementNode element, ProcessorContext context)
Map<EncodeHintType, Object> hints = new HashMap<>();
String charset = element.getAttribute("charset");
if(checkCharacterSet(charset))
hints.put(EncodeHintType.CHARACTER_SET, charset);
String errorCorrection = element.getAttribute("errorcorrection");
if(checkErrorCorrectionAllowed(errorCorrection))
ErrorCorrectionLevel errorCorrectionLevel =
getErrorCorrectionLevel(errorCorrection);
hints.put(EncodeHintType.ERROR_CORRECTION, errorCorrectionLevel);
qrCode = new BarcodeQRCode("placeholder",hints);
@Override
public boolean processContent(String content, ProcessorContext context)
qrCode.setCode(content);
return true;
@Override
public boolean processTagChild(
ITagWorker childTagWorker, ProcessorContext context)
return false;
@Override
public void processEnd(IElementNode element, ProcessorContext context)
qrCodeAsImage = new Image(qrCode.createFormXObject(context.getPdfDocument()));
@Override
public IPropertyContainer getElementResult()
return qrCodeAsImage;
private static boolean checkErrorCorrectionAllowed(String toCheck)
for(int i = 0; i<allowedErrorCorrection.length;i++)
if(toCheck.toUpperCase().equals(allowedErrorCorrection[i]))
return true;
return false;
private static boolean checkCharacterSet(String toCheck)
for(int i = 0; i<allowedCharset.length;i++)
if(toCheck.equals(allowedCharset[i]))
return true;
return false;
private static ErrorCorrectionLevel getErrorCorrectionLevel(String level)
switch(level)
case "L":
return ErrorCorrectionLevel.L;
case "M":
return ErrorCorrectionLevel.M;
case "Q":
return ErrorCorrectionLevel.Q;
case "H":
return ErrorCorrectionLevel.H;
return null;
静态字符串数组是可以传递给BarcodeQRCode类构造函数的提示的可能值。如果你看一下qrcode.htm文件,可以看到我们使用属性charset和errorcorrection传递这些值。
我们看到两个成员变量,一个是BarcodeQRCode实例;另一个是Image实例。BarcodeQRCode对象是一个低级对象,它知道如何绘制QR码,但最终,我们需要一个结果,它是IPropertyContainer接口的实例。为了得到这样的结果,我们将二维码包装在Image对象中。请放心:此操作不会将QR码更改为光栅/点位图像;它不会降低QR码的分辨率和易读性。Image类完全能够存储矢量图像,例如使用iText的二维码功能创建的二维码。
在这之后,我们有了自定义QR码标签worker的构造函数。在这个构造函数中,我们首先创建一个变量名为hints的Map/Dictionary。我们从<qr>-标签的属性中获取这些提示的值。也就是charset和errorcorrection 。当然我们只接受允许的值,我们使用checkCharacterSet()/CheckCharacterSet()和checkErrorCorrectionAllowed()/CheckErrorCorrectionallowed()方法检查这些值。然后使用getErrorCorrectionlevel()方法将errorcorrection登记属性转换为ErrorCorrectionLevel 。处理完属性后,我们将创建一个BarcodeQRCode实例。因为我们还不知道二维码的内容,所以我们使用“placeholder”作为代码的值。
我们用processContent()/ProcessContent()方法中的实际内容替换这个“placeholder”。同时我们不希望<qr>-标签有任何嵌套的标签,因此processTagChild()/ProcessTagChild()方法可以简单地返回false。在过程结束时,在processEnd()方法中,我们将qrCode对象包装在Image对象中。与BarcodeQRCode对象不同,Image类实现IPropertyContainer接口。我们在getElementResult()/GetElementResult()方法中返回这个IPropertyContainer对象。
我们已经成功地实现了ITagWorker接口的四种方法,现在我们可以在自定义QRCodeTagWorkerFactory中使用这个QRCodeTagWorker。
将此自定义QRCodeTagWorkerFactory用作createPdf()/CreatePdf()方法中的ConverterProperties 之一:
public void createPdf(String src, String dest) throws IOException
ConverterProperties properties = new ConverterProperties();
properties
.setCssApplierFactory(new QRCodeTagCssApplierFactory())
.setTagWorkerFactory(new QRCodeTagWorkerFactory());
HtmlConverter.convertToPdf(new File(src), new File(dest), properties);
从这段代码中可以看出,我们使用setTagWorkerFactory()/SetTagWorkerFactory()方法来扩展标签处理机制,但我们也使用setCsApplierFactory()/SetCsApplierFactory()来扩展CSS功能的处理。
这在本例中是必要的,因为我们使用CSS为<qr>-标签定义了边框颜色、宽度和高度。然而,由于<qr>是一个自定义标签,iText不知道遇到此类标签时要使用ICssApplier的哪个实现。我们可以通过重写DefaultCsApplierFactory类的getCustomCsApprier()/GetCustomCsApp()方法轻松解决此问题:
class QRCodeTagCssApplierFactory extends DefaultCssApplierFactory
@Override
public ICssApplier getCustomCssApplier(IElementNode tag)
if (tag.name().equals("qr"))
return new BlockCssApplier();
return null;
在这段代码中,我们告诉iText,每当遇到<qr>-标签时,我们都需要将该标签视为块元素。我们只需重用用于块元素(如<div>、<p>、<blockquote>等)的BlockCsApplier。你可以查看DefaultTagCsApplierMapping的源代码,以获得默认ICssApplier映射的完整概述。
在接下来的几个示例中,我们将创建自定义CSS appliers。
4. 创建自定义css applier
在上一个示例中,我们扩展了DefaultCssApplierFactory,为<qr>-标签添加了BlockCssApplier。在下一个示例中,我们将创建自己的ICssApplier实现。
在这个相当人为的示例中,我们将使用第3章中的sxsw.html文件,并将覆盖所有<div>-元素的CSS applier。我们将忽略这些元素的所有样式,除了background。如果为<div>-元素定义了背景色,我们将用灰色值(#dddddd)替换实际值。见图5.5。
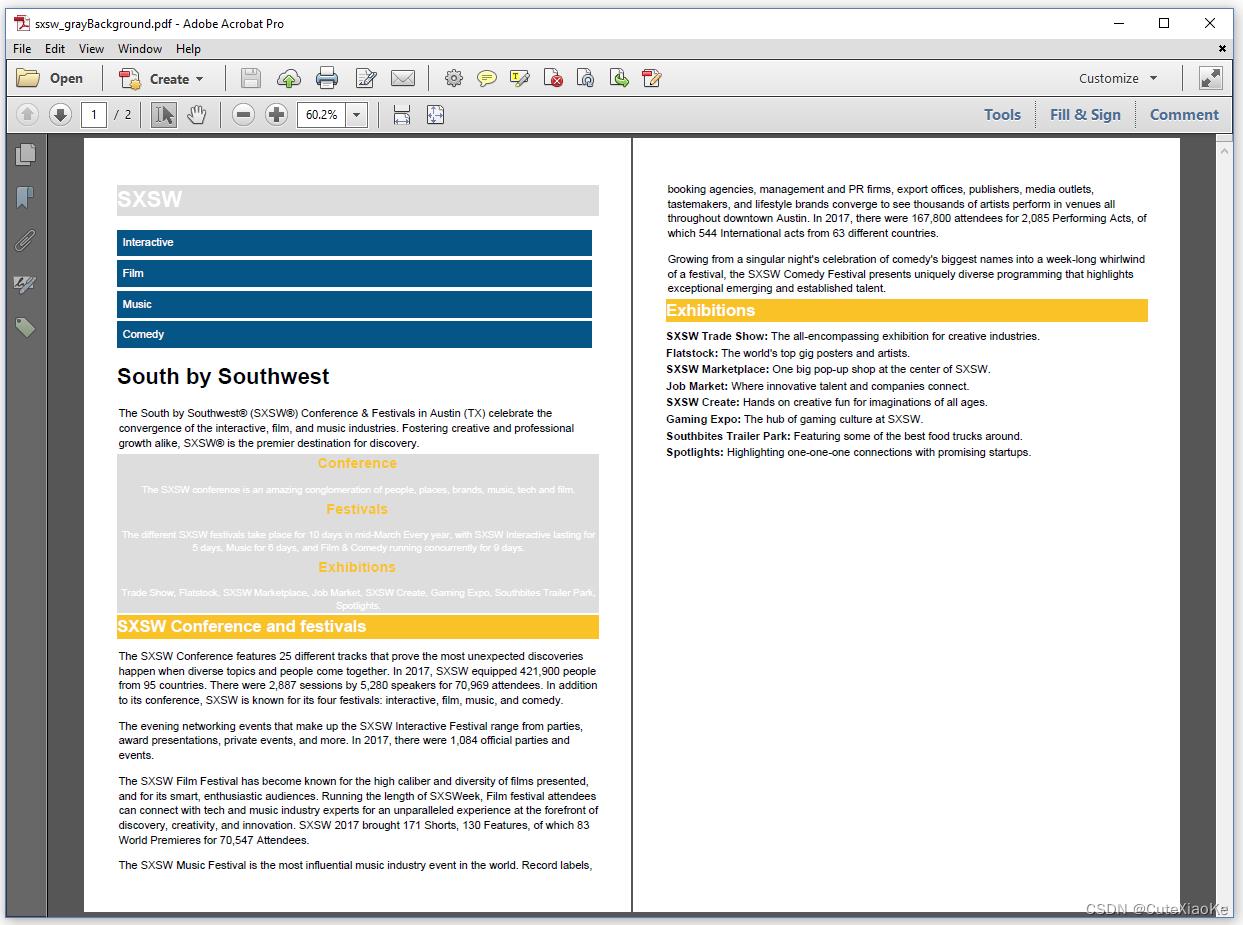
ICssApplier接口有一个名为apply()/apply()的方法。在这个示例中,我们实现了如下方法:
class GrayBackgroundBlockCssApplier implements ICssApplier
public void apply(ProcessorContext context,
IStylesContainer stylesContainer, ITagWorker tagWorker)
Map<String, String> cssProps = stylesContainer.getStyles();
IPropertyContainer container = tagWorker.getElementResult();
if (container != null && cssProps.containsKey(CssConstants.BACKGROUND_COLOR))
cssProps.put(CssConstants.BACKGROUND_COLOR, "#dddddd");
BackgroundApplierUtil.applyBackground(cssProps, context, container);
如果有背景色,我们用#dddddd替换该颜色,然后使用BackgroundApplierUtil类将背景应用于container你仍然可以在生成的PDF中看到带有彩色背景的元素。这是因为这些背景是在<h2>或<li>元素的上下文中定义的,而我们的自定义ICssApplier仅用于<div>元素。
在实现这种功能时要非常小心。在这种情况下,我们完全忽略了任何其他可能适用的CSS属性。扩展现有的ICssApplier实现要好得多。
在下一个示例中,我们将使用一些“Dutch CSS”来定义颜色。由于没有“Dutch CSS”,我们将扩展DefaultCssApplierFactory以支持这种虚构的CSS功能。
5. 实现自己的自定义CSS
dutch_css.html文件是我们在第2章中使用的文件的变体,但它有一些特
以上是关于iText7高级教程之html2pdf——5.自定义标签和CSS应用的主要内容,如果未能解决你的问题,请参考以下文章