Windows7 caffe训练cifar10,出现 Cannot write to snapshot prefix 'examples/cifar10/cifar10_qui
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Windows7 caffe训练cifar10,出现 Cannot write to snapshot prefix 'examples/cifar10/cifar10_qui相关的知识,希望对你有一定的参考价值。
Could not create logging file: File existsCOULD NOT CREATE A LOGGINGFILE 20161028-170345.3228!Could not create logging file: File existsCOULD NOT CREATE A LOGGINGFILE 20161028-170345.3228!Could not create logging file: File existsCOULD NOT CREATE A LOGGINGFILE 20161028-170345.3228!F1028 17:03:45.443140 7876solver.cpp:438] Cannot write to snapshot prefix 'examples/cifar10/cifar10_quick'. Make sure that the directory exists and is writeable.*** Check failure stack trace: ***
这张图片,上一张传错了,不会删。
把路径改好就可以了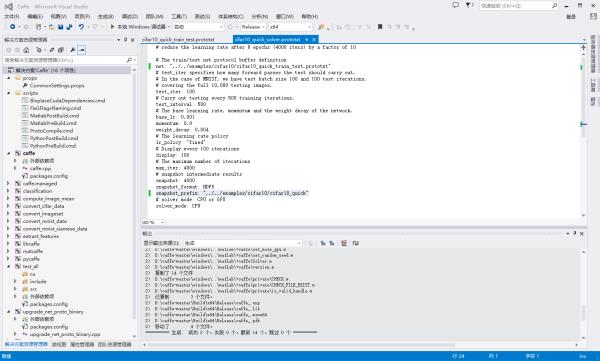
使用caffe的cifar10网络模型训练自己的图片数据
由于我涉及一个车牌识别系统的项目,计划使用深度学习库caffe对车牌字符进行识别。刚开始接触caffe,打算先将示例中的每个网络模型都拿出来用用,当然这样暴力的使用是不会有好结果的- -||| ,所以这里只是记录一下示例的网络模型使用的步骤,最终测试的准确率就暂且不论了!
一、图片数据库
来源
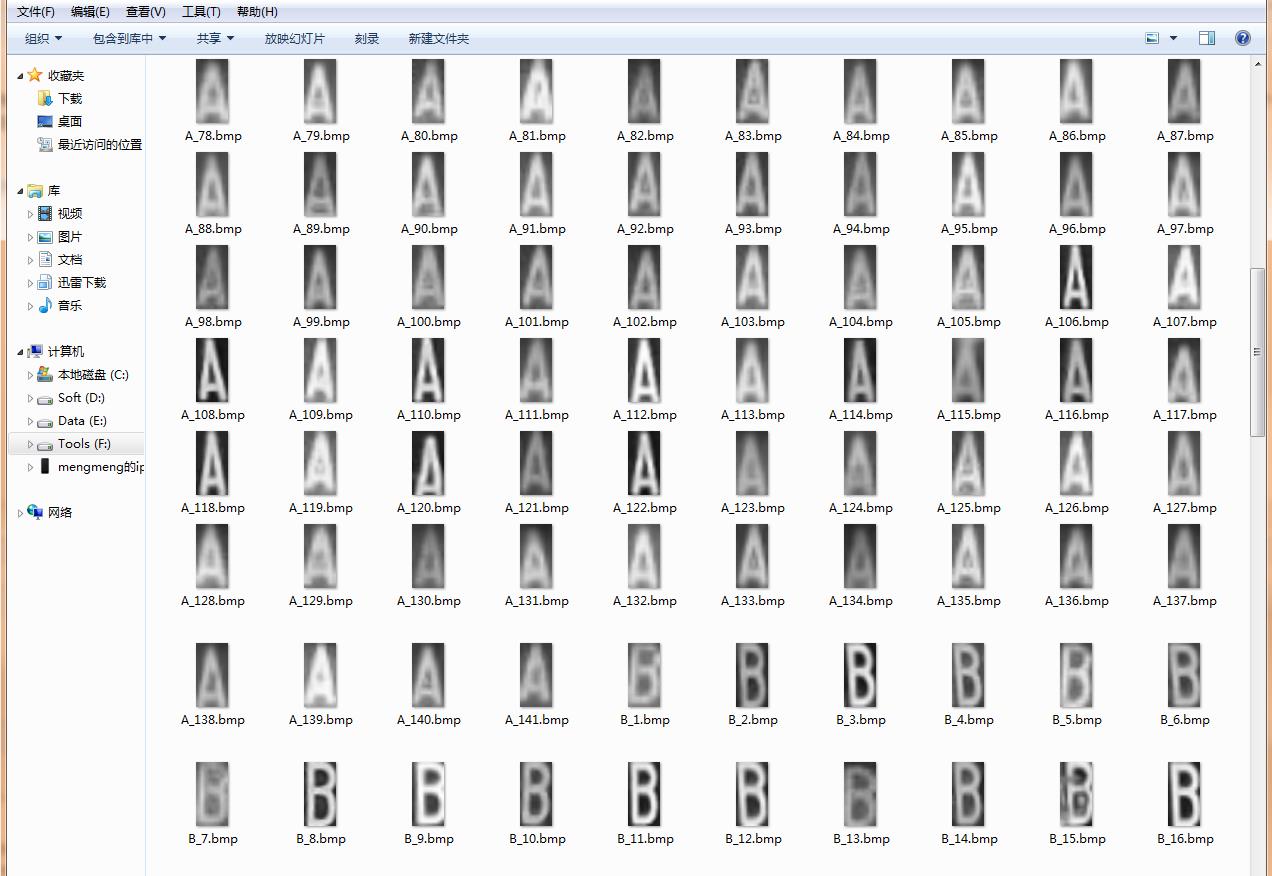
我使用的图像是在项目的字符分割模块中分割出来的字符图像,灰度化并归一化至32*64,字符图片样本示例如下:
建立自己的数据文件夹
在./caffe/data/目录下建立自己的数据文件夹mine,并且在mine文件夹下建立train文件夹和test文件夹(由于只是为了熟悉cifar10网络模型,为减少训练时长,所以只选取了A,B,C三个字符样本进行训练和测试)。train文件夹用于存放训练样本,test文件夹用于存放测试样本。
然后,将你处理好的训练样本图片放在./caffe/data/mine/train/这个文件夹下面,测试样本放在./caffe/data/mine/test/这个文件夹下面。
train:
test:
编写train.txt和test.txt文本
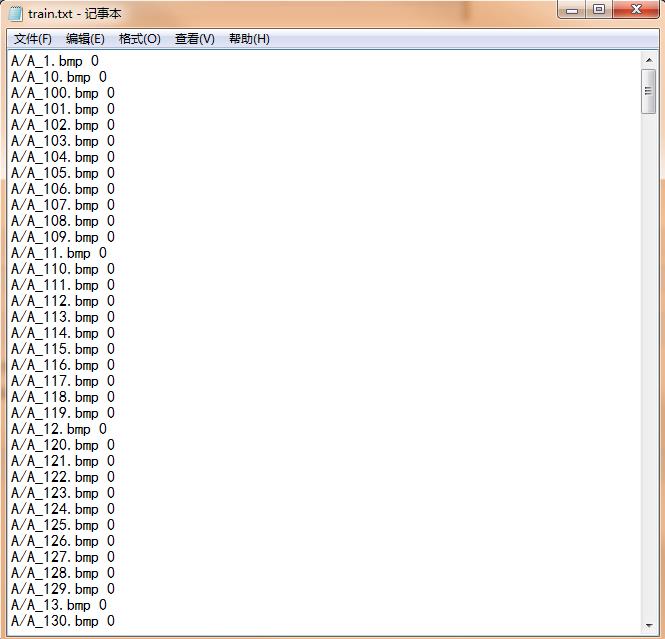
(1)--train.txt :存放训练图片的路径名(相对于./caffe/data/mine/train/)和类别标签,一行一张图片,如下所示:
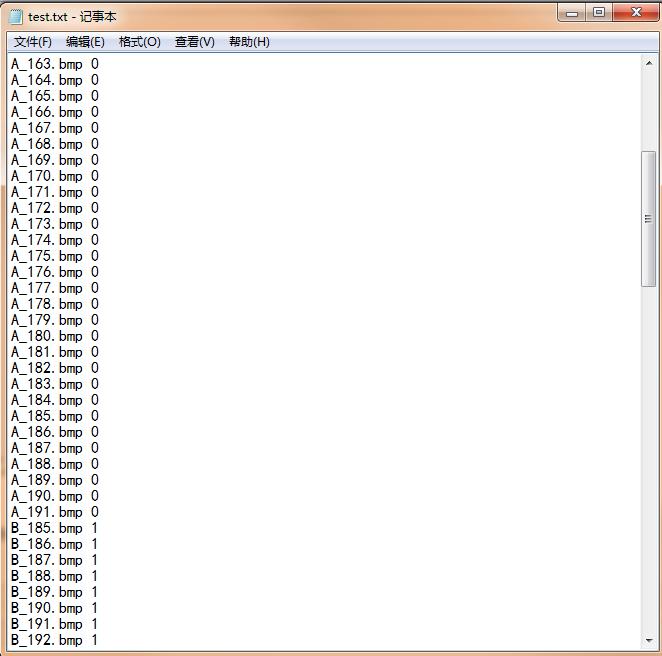
(2)--test.txt :存放测试样本的路径名(相对于./caffe/data/mine/test/)和类别标签,一行代表一张图片,如下图所示:
二、将图片数据转换为LEVELDB格式的数据
在原caffe工程中将caffe.cpp从工程中移除,将tools文件夹中的convert_imageset.cpp添加到工程中,编译后在./caffe/bin/下生成.exe,将其改名为convert_imageset.exe。
然后,在根目录下(我的是F:\\caffe\\)写一个批处理bat文件,命名为converttrain2ldb.bat,旨在将训练集中的数据格式转换为leveldb格式:
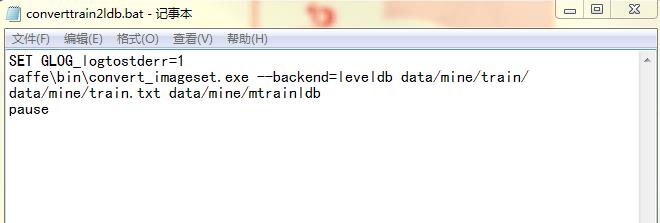
运行后,在data/mine/下生成mtrainldb文件夹,文件夹的内容如下所示:
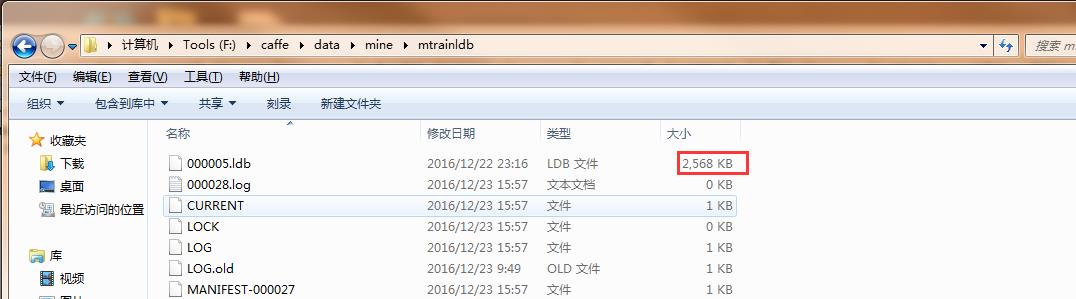
当你生成的.ldb文件的大小为0KB或很小很小,那应该就是你的bat文件出错了。
同理将测试集转换为leveldb文件:
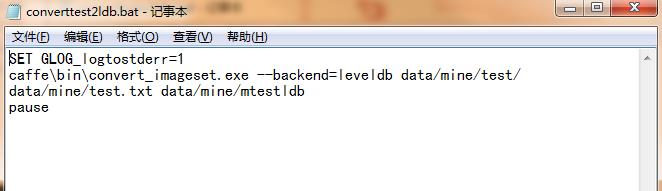
三、计算图像的均值
在原caffe工程中将caffe.cpp从工程中移除,将tools文件夹中的compute_image_mean.cpp添加到工程中,编译后在./caffe/bin/下生成.exe,将其改名为compute_image_mean.cpp.exe。
在根目录下写一个批处理bat文件,命名为computeMean.bat,旨在计算图像的均值,生成均值文件:
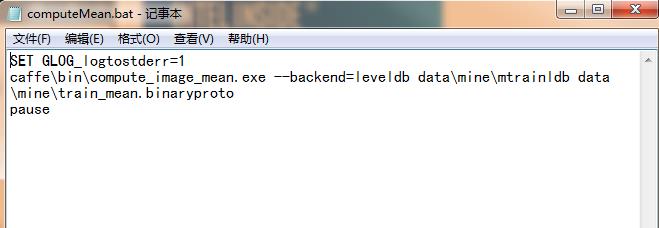
运行后,在data/mine/下生成均值文件。如下所示:

四、创建网络模型,编写配置文件,编写训练脚本,验证测试集
创建网络模型
在./data/mine下建立文件夹train-val,将./examples/cifar10/文件夹下的cifar10_quick_train_test.prototxt网络模型配置文件copy至该文件夹下面,如下所示:

并且进行如下的修改:
name: "CIFAR10_quick" layer { name: "cifar" type: "Data" top: "data" top: "label" include { phase: TRAIN } transform_param { //【第1块修改的地方】下面是均值文件所在的路径,改为你自己的均值文件所在的路径 mean_file: "data/mine/train_mean.binaryproto" } data_param { //【第2块修改的地方】下面改为训练样本生成的数据库所在的目录[注意:是训练样本数据库] source: "data/mine/mtrainldb" batch_size: 50 //【第3块修改的地方】由于我们的训练样本不多,所以我们一次读入50张图片就好 backend: LEVELDB } } layer { name: "cifar" type: "Data" top: "data" top: "label" include { phase: TEST } transform_param { //【第4块修改的地方】下面是均值文件所在的路径,改为你自己的均值文件所在的路径 mean_file: "data/mine/train_mean.binaryproto" } data_param { //【第5块修改的地方】下面改为测试样本生成的数据库所在的目录[注意:是测试样本数据库] source: "data/mine/mtestldb" batch_size: 50//【第6块修改的地方】由于我们的测试样本只有150张,所以我们一次读入50张图片就好 backend: LEVELDB } } layer { name: "conv1" type: "Convolution" bottom: "data" top: "conv1" param { lr_mult: 1 } param { lr_mult: 2 } 中间的省略...... layer { name: "ip2" type: "InnerProduct" bottom: "ip1" top: "ip2" param { lr_mult: 1 } param { lr_mult: 2 } inner_product_param { num_output: 3 //【第7块修改的地方】我们现在是3分类问题,所以将第二个全连接层改为3 weight_filler { type: "gaussian" std: 0.1 } bias_filler { type: "constant" } } } layer { name: "accuracy" type: "Accuracy" bottom: "ip2" bottom: "label" top: "accuracy" include { phase: TEST } } layer { name: "loss" type: "SoftmaxWithLoss" bottom: "ip2" bottom: "label" top: "loss" }
编写超参数配置文件
同样的,将cifar10_quick_solver.prototxt超参数配置文件copy至./data/mine/train-val下,进行下面的修改:
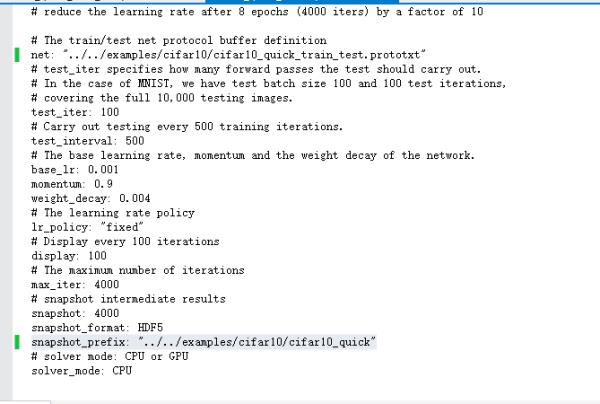
//【1】改为你自己的网络模型配置文件的目录 net: "data/mine/train-val/cifar10_quick_train_test.prototxt" //【2】预测阶段迭代次数,设为3,因为batch_size设为50,这样就可以覆盖150张测试集图片 test_iter: 3 //【3】每迭代50次, 进行一次测试 test_interval: 50 //【4】权值学习率,其实就是在反向传播阶段,权值每次的调整量的程度 base_lr: 0.001 momentum: 0.9 weight_decay: 0.004 //【5】在整个过程中,我们使用固定的学习率,也可尝试使用可变学习率 lr_policy: "fixed" //【6】因为想观察每一次训练的变化,所以设置迭代一次显示一次内容 display: 1 //【7】将最大迭代次数设为4000 max_iter: 4000 //【8】每迭代1000次输出一次结果 snapshot: 1000 //【9】输出格式 snapshot_format: HDF5 //【10】输出文件的前缀 snapshot_prefix: "data/mine/cifar10_quick" //【11】用的是CPU solver_mode: CPU
编写训练脚本
在根目录下新建批处理bat文件,命名为trainMine_useCifar10.bat,内容如下所示:
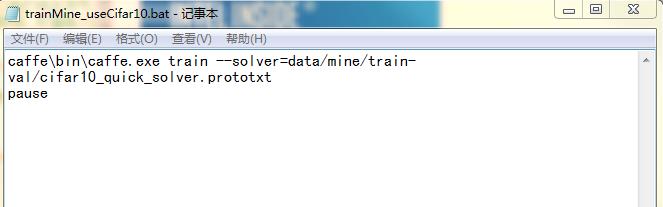
运行后,即调用train-val文件夹下的cifar10_quick_solver.prototxt开始训练,训练过程如下图所示:
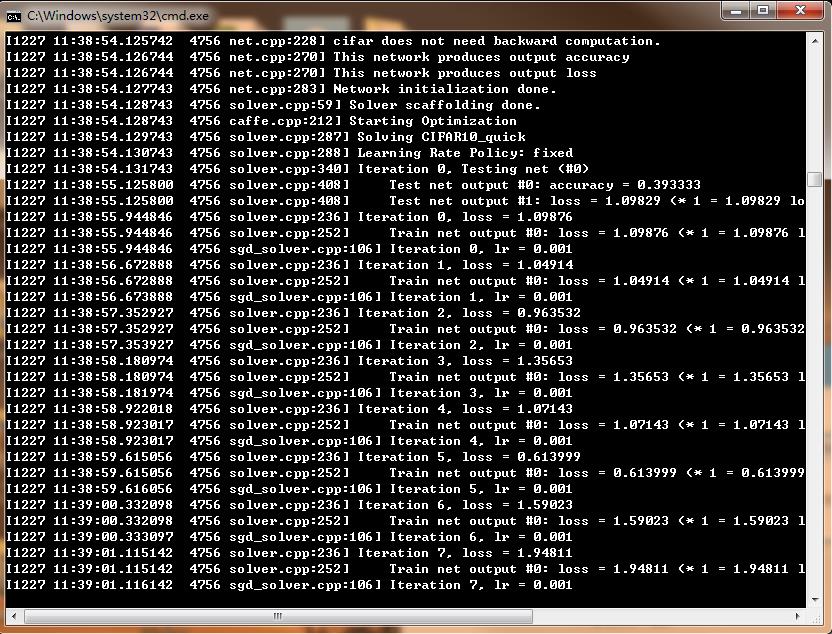
...
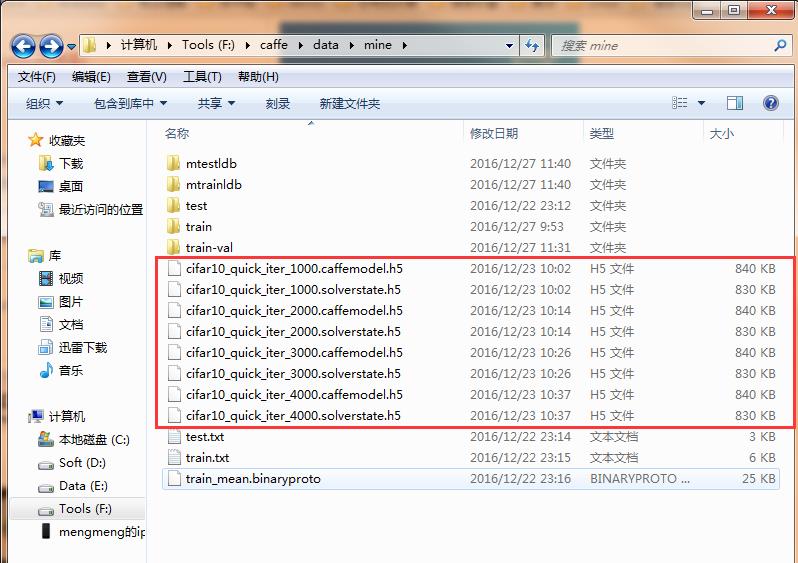
训练完成后,在指定目录下生成了HDF5格式的训练模型:
验证测试集
在根目录下编写批处理bat文件,命名为testMine_useCifar10.bat:
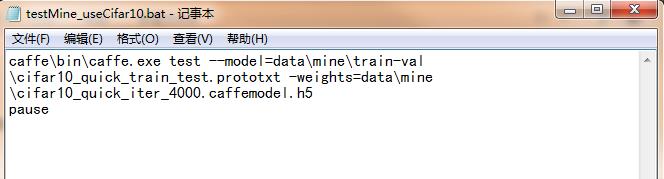
双击运行后,开始对测试集中的数据进行测试,输出结果如下所示:
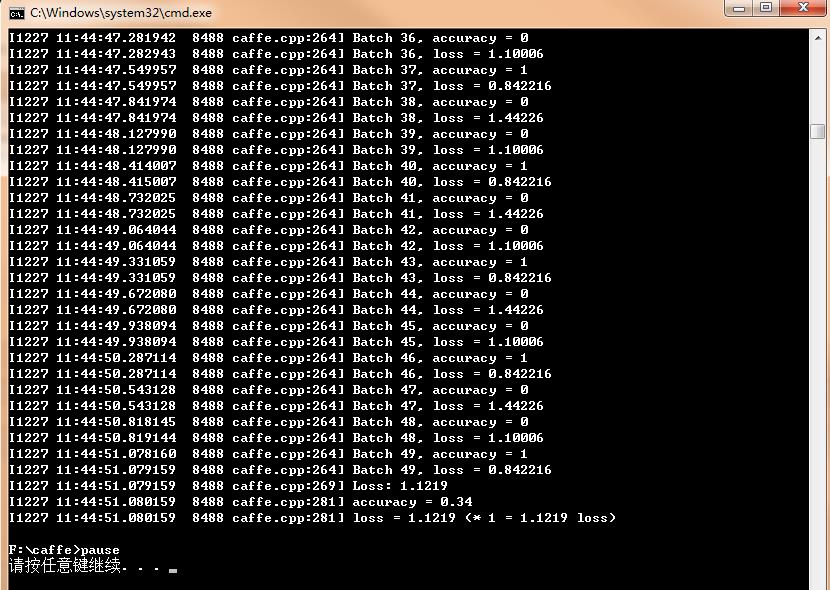
可以看到,有些测试batch的准确率为1,有些batch的准确率为0,accuracy部分除了这两个数字,未出现其它数字,所以我估摸着必有蹊跷,但还不知道问题出在哪,待日后再弄明白!
以上。
以上是关于Windows7 caffe训练cifar10,出现 Cannot write to snapshot prefix 'examples/cifar10/cifar10_qui的主要内容,如果未能解决你的问题,请参考以下文章
Windows caffe cifar10 demo 训练与测试