jvm学习笔记(自用)
Posted 是Cc哈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了jvm学习笔记(自用)相关的知识,希望对你有一定的参考价值。
1.jvm内存模型
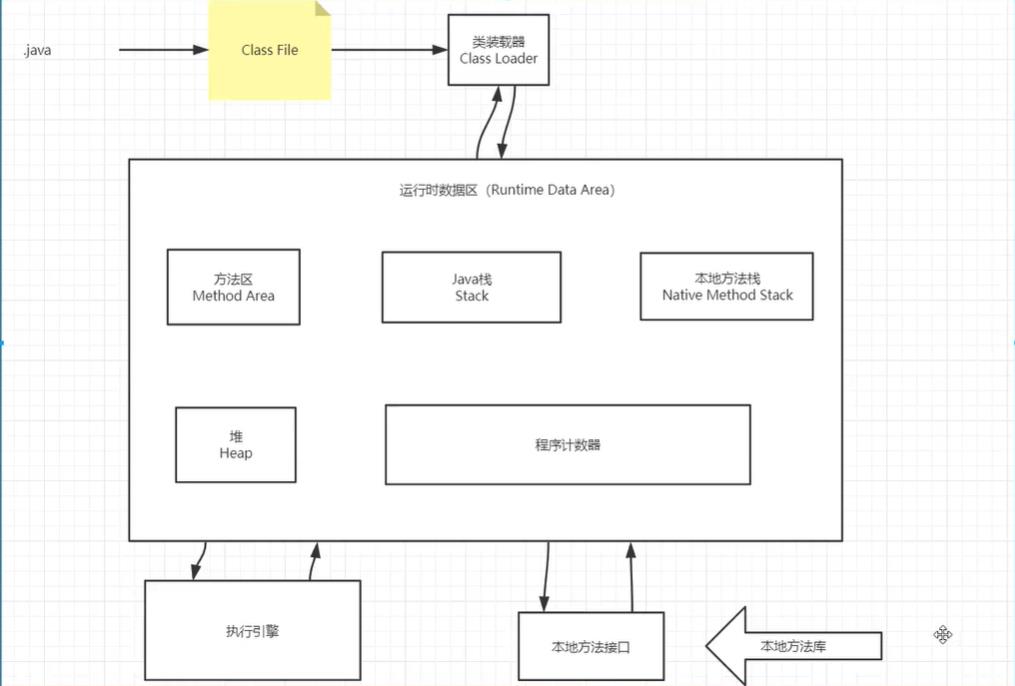
2.类加载器
作用:加载Class文件
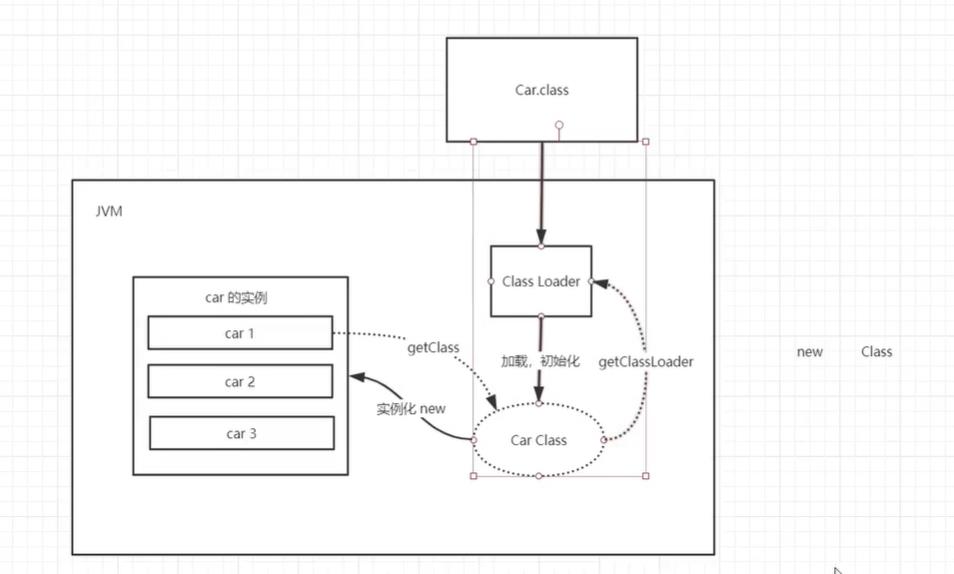
类加载器分类:
1.虚拟机自带的加载器
2.启动类(根)加载器
3.扩展类加载器
4.应用程序(系统)加载器
加载步骤:
1.类加载器收到类加载的请求
2.将这个请求向上委托给父加载器去完成,一直向上委托,直到启动类加载器
3.启动加载器检查是否能够加载当前这个类,能加载到就结束,使用当前的加载器,否则,抛出异常,通知子加载器进行加载
4.重复步骤3,若执行到应用程序加载器依然无法加载,则会报Class Not Found Error
3.双亲委派机制:
源码:
public Class<?> loadClass(String name) throws ClassNotFoundException
return loadClass(name, false);
// -----??-----
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
// 首先,检查是否已经被类加载器加载过
Class<?> c = findLoadedClass(name);
if (c == null)
try
// 存在父加载器,递归的交由父加载器
if (parent != null)
c = parent.loadClass(name, false);
else
// 直到最上面的Bootstrap类加载器
c = findBootstrapClassOrNull(name);
catch (ClassNotFoundException e)
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
if (c == null)
// If still not found, then invoke findClass in order
// to find the class.
c = findClass(name);
return c;
其实这段代码已经很好的解释了双亲委派机制,为了大家更容易理解,我做了一张图来描述一下上面这段代码的流程:
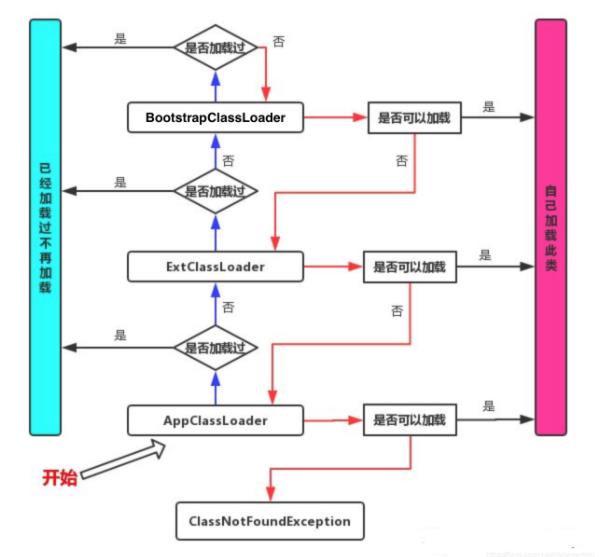
从上图中我们就更容易理解了,当一个Hello.class这样的文件要被加载时。不考虑我们自定义类加载器,首先会在AppClassLoader中检查是否加载过,如果有那就无需再加载了。如果没有,那么会拿到父加载器,然后调用父加载器的loadClass方法。父类中同理也会先检查自己是否已经加载过,如果没有再往上。注意这个类似递归的过程,直到到达Bootstrap classLoader之前,都是在检查是否加载过,并不会选择自己去加载。直到BootstrapClassLoader,已经没有父加载器了,这时候开始考虑自己是否能加载了,如果自己无法加载,会下沉到子加载器去加载,一直到最底层,如果没有任何加载器能加载,就会抛出ClassNotFoundException。
4.native 关键字:
凡是带了native关键字的,说明java的作用范围打不到了,回去调用底层C语言的库
会进入本地方法栈
调用本地方法本地接口 JNI
JNI作用:扩展Java的使用,融合不同的编程语言为Java所用,它再内存区域中专门开辟了一块标记区域:Native Method stack,登记native方法,在最终执行的时候,加载本地方法库中的方法通过JNI
5.PC寄存器:
程序计数器:Program Counter Rigister
每个线程都有一个程序计数器,是线程私有的,就是一个指针,指向方法区中的方法字节码(用来存储指向像一条指令的地址,也即将要执行的指令代码),在执行引擎读取下一条指令,是一个非常小的内存空间,几乎可以忽略不计。
6.方法区:
Mehtod Area 方法区
方法区是被所有线程共享,所有字段和方法字节码,以及一些特殊方法,如构造函数,接口代码也在此定义,简单说所有定义的方法的信息都保存在该区域,此区域属于共享区间
静态变量、常量、类信息(构造方法,接口定义)、运行时的常量池存在方法区中,但是试里变量存在堆内存中,和方法区无关。
7.栈:
栈模型:
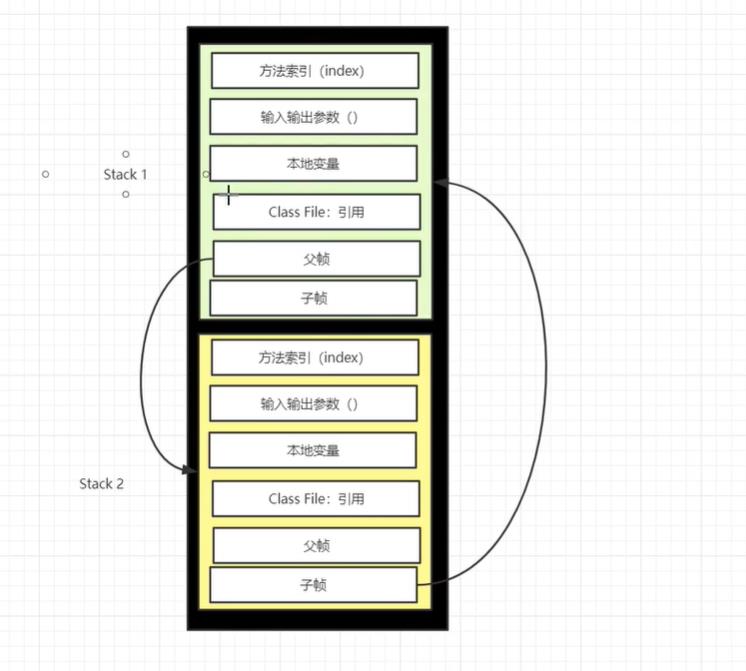
栈+堆+方法区交互关系:
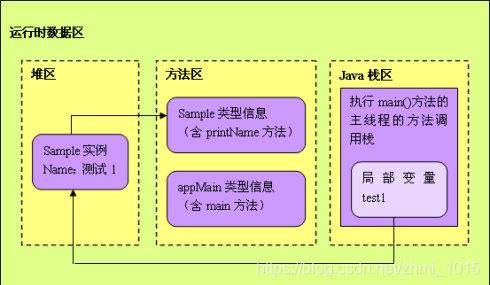
public class AppMain //运行时,JVM把AppMain的信息都放入方法区
public static void main(String[] args) //main成员方法本身放入方法区。
Sample test1 = new Sample( " 测试1 " ); //test1是引用,所以放到栈区里,Sample是自定义对象应该放到堆里面
Sample test2 = new Sample( " 测试2 " );
test1.printName();
test2.printName();
// Sample.java
public class Sample //运行时,JVM把appmain的信息都放入方法区。
private name; //new Sample实例后,name引用放入栈区里,name对象放入堆里。
public Sample(String name)
this .name = name;
public void printName() // printName()成员方法本身放入方法区里。
System.out.println(name);
JVM执行具体流程
系统收到了我们发出的指令,启动了一个Java虚拟机进程,这个进程首先从classpath中找到AppMain.class文件,读取这个文件中的二进制数据,然后把Appmain类的类信息存放到运行时数据区的方法区中。这一过程称为AppMain类的加载过程。
接着,JVM定位到方法区中AppMain类的Main()方法的字节码,开始执行它的指令。这个main()方法的第一条语句就是:
Sample test1 = new Sample(“测试1”);
语句很简单啦,就是让JVM创建一个Sample实例,并且呢,使引用变量test1引用这个实例。貌似小case一桩哦,就让我们来跟踪一下JVM,看看它究竟是怎么来执行这个任务的:
1)、Java虚拟机一看,不就是建立一个Sample类的实例吗,简单,于是就直奔方法区(方法区存放已经加载的类的相关信息,如类、静态变量和常量)而去,先找到Sample类的类型信息再说。结果呢,嘿嘿,没找到@@,这会儿的方法区里还没有Sample类呢(即Sample类的类信息还没有进入方法区中)。可JVM也不是一根筋的笨蛋,于是,它发扬“自己动手,丰衣足食”的作风,立马加载了Sample类, 把Sample类的相关信息存放在了方法区中。
2)、Sample类的相关信息加载完成后。Java虚拟机做的第一件事情就是在堆中为一个新的Sample类的实例分配内存,这个Sample类的实例持有着指向方法区的Sample类的类型信息的引用(Java中引用就是内存地址)。这里所说的引用,实际上指的是Sample类的类型信息在方法区中的内存地址,其实,就是有点类似于C语言里的指针啦~~,而这个地址呢,就存放了在Sample类的实例的数据区中。
3)、在JVM中的一个进程中,每个线程都会拥有一个方法调用栈,用来跟踪线程运行中一系列的方法调用过程,栈中的每一个元素被称为栈帧,每当线程调用一个方法的时候就会向方法栈中压入一个新栈帧。这里的帧用来存储方法的参数、局部变量和运算过程中的临时数据。OK,原理讲完了,就让我们来继续我们的跟踪行动!位于“=”前的test1是一个在main()方法中定义的变量,可见,它是一个局部变量,因此,test1这个局部变量会被JVM添加到执行main()方法的主线程的Java方法调用栈中。而“=”将把这个test1变量指向堆区中的Sample实例,也就是说,test1这个局部变量持有指向Sample类的实例的引用(即内存地址)。
4)、JVM将继续执行后续指令,在堆区里继续创建另一个Sample类的实例,然后依次执行它们的printName()方法。当JVM执行test1.printName()方法时,JVM根据局部变量test1持有的引用,定位到堆中的Sample类的实例,再根据Sample类的实例持有的引用,定位到方法区中Sample类的类型信息(包括①类,②静态变量,③静态方法,④常量和⑤成员方法),从而获取printName()成员方法的字节码,接着执行printName()成员方法包含的指令。
三种JVM:
1.sun公司:Hotspot
2.BEA: JRockit
3.IBM: J9 vm
堆:
Heap,一个JVM只有一个堆内存,堆内存的大小是可以调节的
-Xms 设置初始化内存大小,默认为计算机内存的1/64
-Xmx 设置最大分配内存,默认1/4
-XX:+PrintGCDetails 打印GC垃圾回收信息
-XX:+HeapDumpOnOutOfmemoryError oom错误的Dump文件
堆内存中还要细分成三个区域:
1.新生区(伊甸园区)
2.养老与
3.永久区
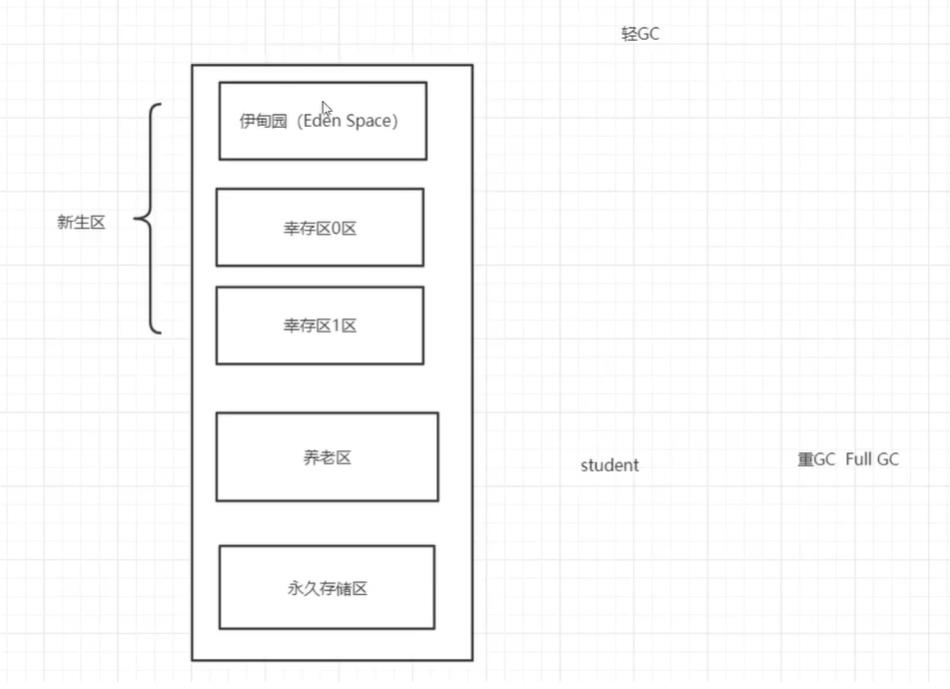
GC垃圾回收,主要在Eden区和养老区
在JDK8以后,永久存储区改名叫元空间
新生区:
类:诞生和成长的地方
伊甸园区,所有的对象都是在伊甸园区new出来的
幸存者区(0,1)
永久区:
这个区域常驻内存中。用来存放JDK自身携带的Class对象。Interface元数据,存储的是Java运行时的一些环境或类信息,这个区域不存在垃圾回收!关闭VM虚拟机就会释放这个区域的内存
jdk1.6之前:永久代,常量池是在方法区
jdk1.7:永久代,但是慢慢的退化了,去永久代,常量池在堆中
jdk1.8:无永久代,常量池在元空间

解决OOM错误方法
快速看到代码第几行出错可以用内存快照分析工具,MAT,Jprofiler
MAT,Jprofiler作用:
分析Dump内存文件,快速定位内存泄露;
获得堆中的数据
获得大的对象
GC垃圾回收:
JVM在进行GC是,并不是对这三个区域统一回收。大部分时候,回收都是新生代
1.新生代
2.幸存区(form,to)
3.老年区
GC两种类:轻GC(普通Gc),重GC(全局GC)
GC回收4大算法
1.引用计数
2.复制算法
以上是关于jvm学习笔记(自用)的主要内容,如果未能解决你的问题,请参考以下文章