sql语句查询过滤重复数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql语句查询过滤重复数据相关的知识,希望对你有一定的参考价值。
已有的数据库 建立索引语句为 CREATE
INDEX [aaa] ON biao([bb], [ee])
WITH
DROP_EXISTING
ON [PRIMARY]
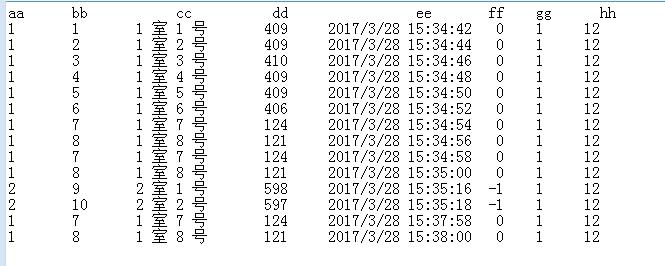
aa bb cc dd ee ff gg hh
1 1 1 室 1 号 409 2017/3/28 15:34:42 0 1 12
1 2 1 室 2 号 409 2017/3/28 15:34:44 0 1 12
1 3 1 室 3 号 410 2017/3/28 15:34:46 0 1 12
1 4 1 室 4 号 409 2017/3/28 15:34:48 0 1 12
1 5 1 室 5 号 409 2017/3/28 15:34:50 0 1 12
1 6 1 室 6 号 406 2017/3/28 15:34:52 0 1 12
1 7 1 室 7 号 124 2017/3/28 15:34:54 0 1 12
1 8 1 室 8 号 121 2017/3/28 15:34:56 0 1 12
1 7 1 室 7 号 124 2017/3/28 15:34:58 0 1 12
1 8 1 室 8 号 121 2017/3/28 15:35:00 0 1 12
2 9 2 室 1 号 598 2017/3/28 15:35:16 -1 1 12
2 10 2 室 2 号 597 2017/3/28 15:35:18 -1 1 12
1 7 1 室 7 号 124 2017/3/28 15:37:58 0 1 12
1 8 1 室 8 号 121 2017/3/28 15:38:00 0 1 12
这是一个大容量数据库,数据容量有几百万条,aa字段可以忽略,bb为每个室号的id标识,cc为名字可以忽略,dd为一个数字,ee时间,ff忽略,gg和hh为固定的数字分别为1和12.
求一个能查询的语句,根据时间倒序之后,过滤掉bb相同的数据(留时间最近的),然后已bb字段排序,排序不好实现可以不排序,查询速度越快越好 查询结果如下图
1 1 1 室 1 号 409 2017/3/28 15:34:42 0 1 12
1 2 1 室 2 号 409 2017/3/28 15:34:44 0 1 12
1 3 1 室 3 号 410 2017/3/28 15:34:46 0 1 12
1 4 1 室 4 号 409 2017/3/28 15:34:48 0 1 12
1 5 1 室 5 号 409 2017/3/28 15:34:50 0 1 12
1 6 1 室 6 号 406 2017/3/28 15:34:52 0 1 12
1 7 1 室 7 号 124 2017/3/28 15:37:58 0 1 12
1 8 1 室 8 号 121 2017/3/28 15:38:00 0 1 12
2 9 2 室 1 号 598 2017/3/28 15:35:16 -1 1 12
2 10 2 室 2 号 597 2017/3/28 15:35:18 -1 1 12
确定可以使用,重谢。
复制代码代码如下:
select * from people
where peopleId in (select peopleId from people group by peopleId having count
(peopleId) > 1)
2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录
复制代码代码如下:
delete from people
where peopleId in (select peopleId from people group by peopleId having count
(peopleId) > 1)
and rowid not in (select min(rowid) from people group by peopleId having count(peopleId
)>1)
SQL重复数据只显示一条,查询语句怎么写
SQL重复数据只显示一条,查询语句编码的写法是:
如果是所有字段都重复,使用 distinct。
如果部分字段重复,只能使用group by 或是其他的方法。
结构化查询语言(Structured Query Language)简称SQL(发音:/ˈes kjuː ˈel/ "S-Q-L"),是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。
结构化查询语言是高级的非过程化编程语言,允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统, 可以使用相同的结构化查询语言作为数据输入与管理的接口。结构化查询语言语句可以嵌套,这使它具有极大的灵活性和强大的功能。
参考技术A SELECT name, MAX(ID) FROM XXX GROUP BY name; 参考技术B 如果只是按你的结果得到数据,则语句是:select 名字,max(金额) 金额
from 表
group by 名字
但感觉金额应该是统计的,比如张三显示230,则应该是
select 名字,sum(金额) 金额\
from 表
group by 名字 参考技术C 1、显示最大的
select 名字,max(金额) 金额
from 表
group by 名字
2、显示合计的
select 名字,sum(金额) 金额
from 表
group by 名字 参考技术D select 名字 ,max(金额)
from table
group by 名字
以上是关于sql语句查询过滤重复数据的主要内容,如果未能解决你的问题,请参考以下文章