Hadoop-yarn组件的三种调度器
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop-yarn组件的三种调度器相关的知识,希望对你有一定的参考价值。
参考技术A FIFO是简单容易理解的调度器,它是一个先进先出的队列,也就是按照job提交顺序来排队,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。支持多队列多用户,每个队列中的资源量可以配置,同一个队列中的作业公平共享队列中所有资源。比如有三个队列: queueA、queueB 和queueC,每个队列中的job按照优先级分配资源,优先级越高分配的资源越多,但是每个job都会分配到资源以确保公平。在资源有限的情况下,每个job理想情况下获得的计算资源与实际获得的计算资源存在一种差距,这个差距就叫做缺额。在同一个队列中,job的资源缺额越大,越先获得资源优先执行。作业.是按照缺额的高低来先后执行的,而且可以看到上图有多个作业同时运行。
大数据HADOOP-YARN容量调度器多队列配置详解实战
YARN容量调度器多队列配置详解
简介
Capacity调度器具有以下的几个特性:
- 层次化的队列设计,这种层次化的队列设计保证了子队列可以使用父队列设置的全部资源。这样通过层次化的管理,更容易合理分配和限制资源的使用。
- 容量保证,队列上都会设置一个资源的占比,这样可以保证每个队列都不会占用整个集群的资源。
安全,每个队列有严格的访问控制。用户只能向自己的队列里面提交任务,而且不能修改或者访问其他队列的任务。 - 弹性分配,空闲的资源可以被分配给任何队列。当多个队列出现争用的时候,则会按照比例进行平衡。
多租户租用,通过队列的容量限制,多个用户就可以共享同一个集群,同时保证每个队列分配到自己的容量,提高利用率。 - 操作性,yarn支持动态修改调整容量、权限等的分配,可以在运行时直接修改。还提供给管理员界面,来显示当前的队列状况。管理员可以在运行时,添加一个队列;但是不能删除一个队列。管理员还可以在运行时暂停某个队列,这样可以保证当前的队列在执行过程中,集群不会接收其他的任务。如果一个队列被设置成了stopped,那么就不能向他或者子队列上提交任务了。
- 基于资源的调度,协调不同资源需求的应用程序,比如内存、CPU、磁盘等等。
需求
default 队列占总内存的40%,最大资源容量占总资源的60%
ops 队列占总内存的60%,最大资源容量占总资源的80%
配置队列优先级策略
配置多队列的容量调度器
- 在yarn-site.xml里面配置使用容量调度器
<!-- 使用容量调度器 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
- 在capacity-scheduler.xml中配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 表示集群最大app数 -->
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
</property>
<!-- 表示集群上某队列可使用的资源比例 目的是为了限制过多的am数,即app数 -->
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.1</value>
</property>
<!-- 配置指定调度器使用的资源计算器 -->
<!-- DefaultResourseCalculator 默认值,只使用内存进行比较 -->
<!-- DominantResourceCalculator 多维度资源计算,内存、cpu -->
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
</property>
<!-- root队列中有哪些子队列-->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,ops</value>
</property>
<!-- *******************default队列*********************** -->
<!-- default 队列占用的资源容量百分比 40% -->
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>40</value>
</property>
<!-- default 队列占用的最大资源容量百分比 60%-->
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>60</value>
</property>
<!-- 允许单个用户最多可获取的队列资源的倍数,默认值1,
确保单个用户无论集群有多空闲,永远不会占用超过队列配置的资源
当值大于1时,用户可使用的资源将超过队列配置的资源,
但应该不能超过队列配置的最大资源
-->
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
</property>
<!-- 队列状态 -->
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
</property>
<!-- 限定哪些admin用户可向root队列中提交应用程序 -->
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
</property>
<!-- 为root队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等 -->
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
</property>
<!-- 配置哪些用户有权配置提交任务优先级 -->
<property>
<name>yarn.scheduler.capacity.root.default.acl_application_max_priority</name>
<value>*</value>
</property>
<!-- 任务的超时时间设置:yarn application -appId $appId -updateLifeTime Timeout -->
<!-- 如果application指定了超时时间,则提交到该队列的application能够制定的最大超时时间不能超过该值。-->
<property>
<name>yarn.scheduler.capacity.root.default.maximum-application-lifetime</name>
<value>-1</value>
</property>
<!-- 如果application没有指定超时时间,则用default-application-lifetime 作为默认值 -->
<property>
<name>yarn.scheduler.capacity.root.default.default-application-lifetime</name>
<value>-1</value>
</property>
<!-- *******************hive队列*********************** -->
<!-- hive 队列占用的资源容量百分比 60% -->
<property>
<name>yarn.scheduler.capacity.root.ops.capacity</name>
<value>60</value>
</property>
<!-- default 队列占用的最大资源容量百分比 80%-->
<property>
<name>yarn.scheduler.capacity.root.ops.maximum-capacity</name>
<value>80</value>
</property>
<!-- 允许单个用户最多可获取的队列资源的倍数,默认值1,
确保单个用户无论集群有多空闲,永远不会占用超过队列配置的资源
当值大于1时,用户可使用的资源将超过队列配置的资源,
但应该不能超过队列配置的最大资源
-->
<property>
<name>yarn.scheduler.capacity.root.ops.user-limit-factor</name>
<value>1</value>
</property>
<!-- 队列状态 -->
<property>
<name>yarn.scheduler.capacity.root.ops.state</name>
<value>RUNNING</value>
</property>
<!-- 限定哪些admin用户可向root队列中提交应用程序 -->
<property>
<name>yarn.scheduler.capacity.root.ops.acl_submit_applications</name>
<value>*</value>
</property>
<!-- 为root队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等 -->
<property>
<name>yarn.scheduler.capacity.root.ops.acl_administer_queue</name>
<value>*</value>
</property>
<!-- 配置哪些用户有权配置提交任务优先级 -->
<property>
<name>yarn.scheduler.capacity.root.ops.acl_application_max_priority</name>
<value>*</value>
</property>
<!-- 任务的超时时间设置:yarn application -appId $appId -updateLifeTime Timeout -->
<!-- 如果application指定了超时时间,则提交到该队列的application能够制定的最大超时时间不能超过该值。-->
<property>
<name>yarn.scheduler.capacity.root.ops.maximum-application-lifetime</name>
<value>-1</value>
</property>
<!-- 如果application没有指定超时时间,则用default-application-lifetime 作为默认值 -->
<property>
<name>yarn.scheduler.capacity.root.opsdefault-application-lifetime</name>
<value>-1</value>
</property>
<!--
CapacityScheduler尝试调度机本地容器之后错过的调度机会数。
通常,应该将其设置为集群中的节点数。
默认情况下在一个架构中设置大约40个节点。应为正整数值。
-->
<property>
<name>yarn.scheduler.capacity.node-locality-delay</name>
<value>40</value>
</property>
<!--
在节点本地延迟时间之外的另外的错过的调度机会的次数,在此之后,
CapacityScheduler尝试调度非切换容器而不是机架本地容器.例如:在node-locality-delay = 40和rack-locality-delay = 20的情况下,
调度器将在40次错过机会之后尝试机架本地分配,在40 + 20 = 60之后错过机会.使用-1作为默认值,禁用此功能.
在这种情况下,根据资源请求中指定的容器和唯一位置的数量以及集群的大小,计算分配关闭交换容器的错失机会的数量
-->
<property>
<name>yarn.scheduler.capacity.rack-locality-additional-delay</name>
<value>-1</value>
</property>
<!-- 此配置指定用户或组到特定队列的映射 -->
<property>
<name>yarn.scheduler.capacity.queue-mappings</name>
<value>u:root:default,g:root:default,u:%user:%user</value>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings-override.enable</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.capacity.per-node-heartbeat.maximum-offswitch-assignments</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.capacity.application.fail-fast</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.capacity.workflow-priority-mappings</name>
<value></value>
</property>
<property>
<name>yarn.scheduler.capacity.workflow-priority-mappings-override.enable</name>
<value>false</value>
</property>
</configuration>
- 同步到其他节点后,刷新配置
bin/yarn rmadmin -refreshQueues
- 查看界面展示
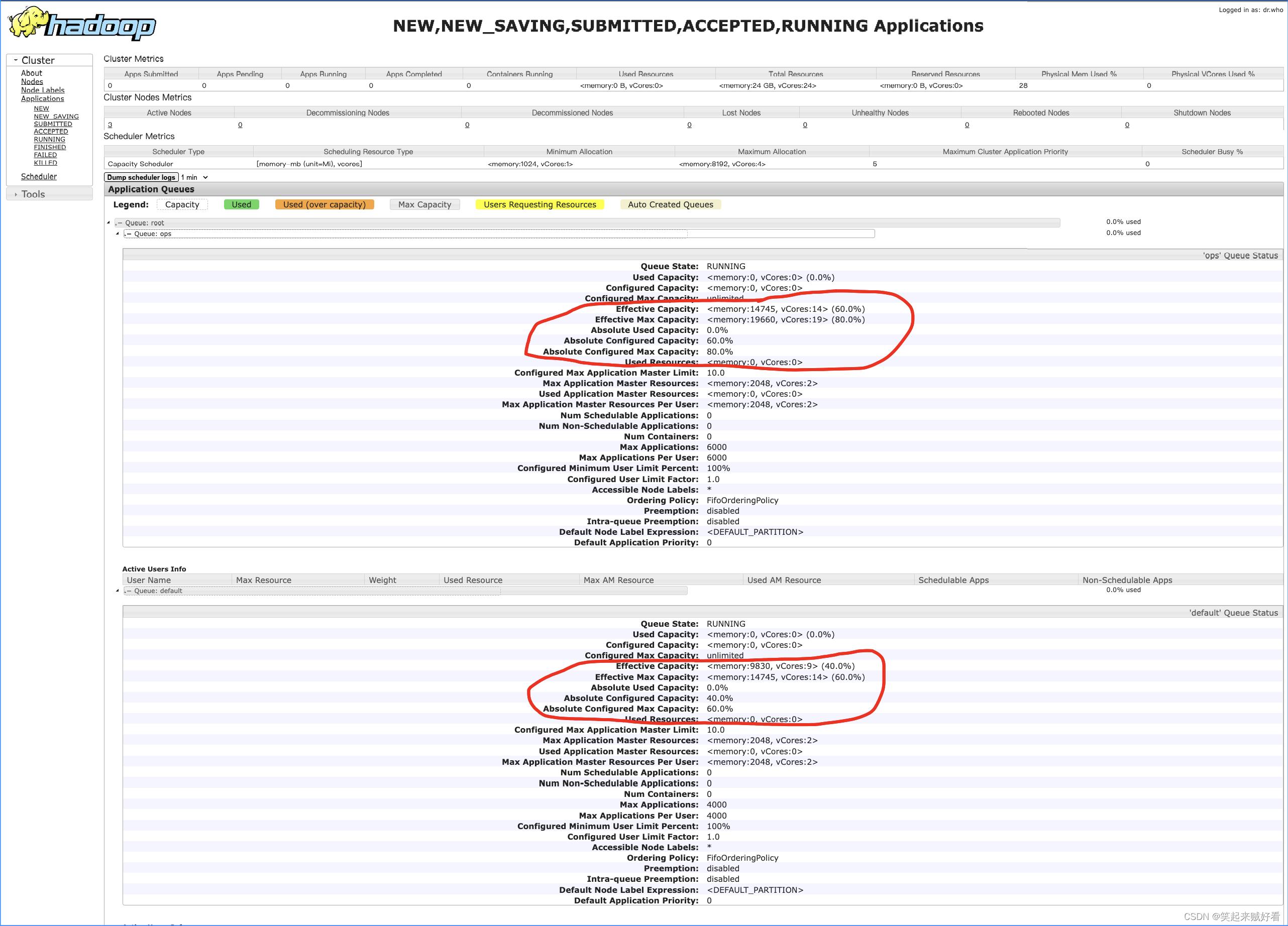
验证队列资源
- 提交任务,查看队列资源占比情况
提交任务
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 2g --executor-memory 2g --executor-cores 1 --num-executors 1 --queue default examples/jars/spark-examples_2.12-3.2.1.jar 100
–driver-memory 2g --executor-memory 2g --executor-cores 1 --num-executors 1
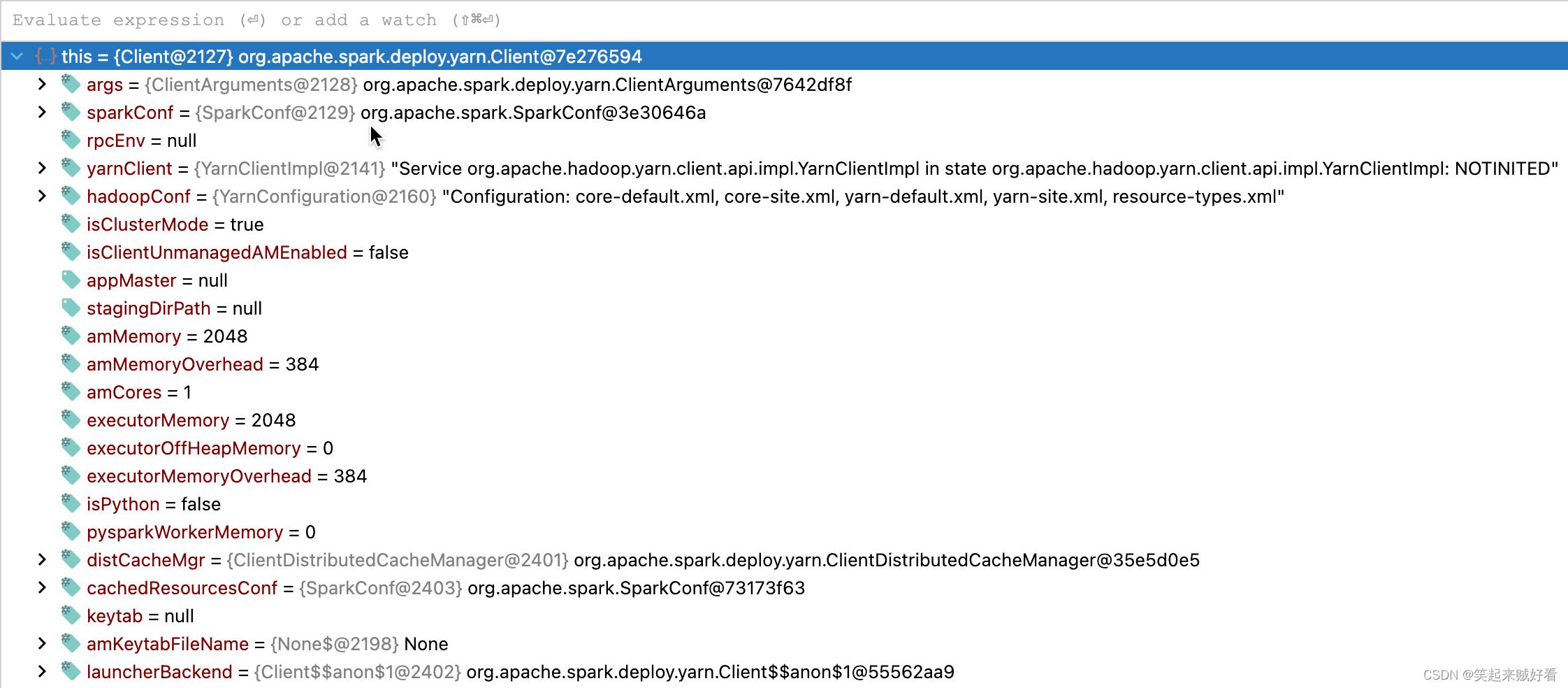

可以看到 向YARN的资源需求是:
amMemory = 2048
amMemoryOverhead = 384
executorMemory = 2048
executorOffHeapMemory. = 0
executorMemoryOverhead = 384
amCores = 1
最终向YARN上申请AM的资源大小为:
am = amMemory + amMemoryOverhead = 2432
executor = executorMemory + executorMemoryOverhead = 2432
capability = <memory:2432,vCores:1>
由于配置的集群资源分配最小单位为1024MB, 因此需要向上取整, 即 3072 MB
这也是为甚么我明明申请的 资源 比较小,但是在yarn上显示的资源总不对,比实际申请的资源要高一些。资源比预期的要高。
这主要是yarn的资源计算是用DominantResourceCalculator来计算管理 cpu、内存的。
spark和yarn上申请的资源没有对的上。
所以最终的资源:
Driver 申请的资源 --driver-memory 2g 实际在yarn中AM申请的资源为 3g1c
Executor 申请的资源 --executor-memory 2g --executor-cores 1 --num-executors 1 实际在yarn中executor申请的资源为 3g1c
最终总的资源为 6g2c

同理再提交一下 1g1c的
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 1g --executor-memory 1g --executor-cores 1 --num-executors 2 --queue default examples/jars/spark-examples_2.12-3.2.1.jar 100
–driver-memory 1g --executor-memory 1g --executor-cores 1 --num-executors 2
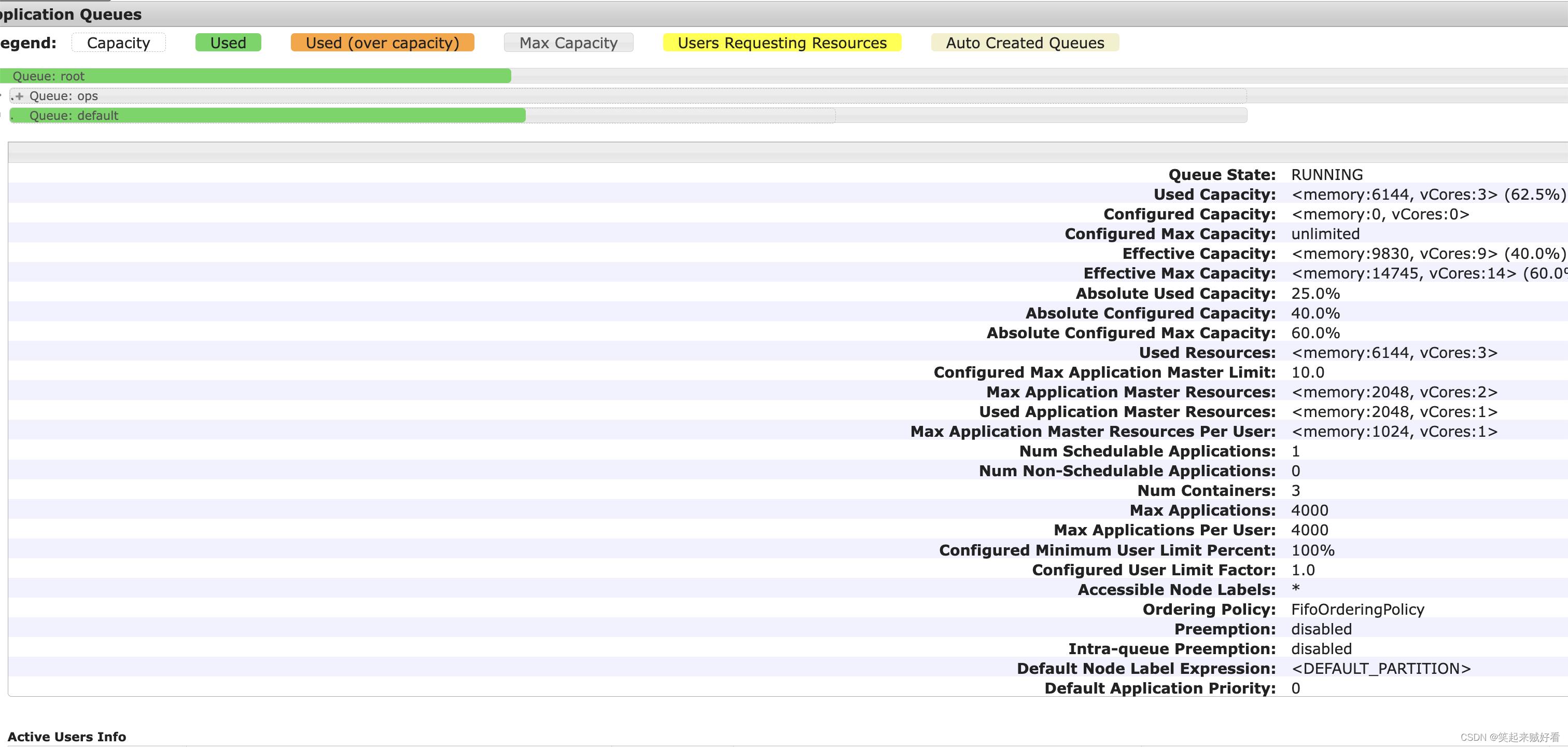
所以最终的资源:
Driver 申请的资源 --driver-memory 1g 实际在yarn中AM申请的资源为 1g1c
Executor 申请的资源 --executor-memory 1g --executor-cores 1 --num-executors 2 实际在yarn中executor申请的资源为 4g2c
最终总的资源为 6g3c
- 验证队列的最大资源限制
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 2g --executor-memory 2g --executor-cores 2 --num-executors 5 --queue default examples/jars/spark-examples_2.12-3.2.1.jar 100

当内存需求超过队列最大资源时
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 2g --executor-memory 2g --executor-cores 2 --num-executors 6 --queue default examples/jars/spark-examples_2.12-3.2.1.jar 100


最终看到申请的资源可以超过队列配置的资源,但是不会超过最大的资源
spark申请的容器为 6 个,但是最终只启动了4个。
希望对正在查看文章的您有所帮助,记得关注、评论、收藏,谢谢您
以上是关于Hadoop-yarn组件的三种调度器的主要内容,如果未能解决你的问题,请参考以下文章