MS:Metric
Posted zzzyzh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MS:Metric相关的知识,希望对你有一定的参考价值。
文章目录
前言
本文主要介绍几种在医学图像分割领域常用的评价标准:Dice Loss, Sensitivity & Specificity, Hausdorff distance, Average surface distance 等
1. Dice Loss
1.1. Dice coefficient
Dice 系数,是一种集合相似度度量函数,通常用于计算两个样本点的相似度(值范围为
[
0
,
1
]
[0, 1]
[0,1] ),其值越大意味着这两个样本越相似
- 用于分割问题,分割最好时为1,最差为0
- 用于解决样本不均衡的问题,但不稳定,容易出现梯度爆炸
计算公式:
D
i
c
e
=
2
∣
X
∩
Y
∣
∣
X
∣
+
∣
Y
∣
Dice = \\frac2|X \\cap Y||X| + |Y|
Dice=∣X∣+∣Y∣2∣X∩Y∣
参数含义:
- ∣ X ∩ Y ∣ |X\\cap Y| ∣X∩Y∣ 表示 X X X 和 Y Y Y 之间交集元素的个数
- ∣ X ∣ |X| ∣X∣ 和 ∣ Y ∣ |Y| ∣Y∣ 分别表示 X X X、 Y Y Y 中元素的个数
- 其中,分子中的系数 2,是因为分母存在重复计算 X X X 和 Y Y Y 之间的共同元素的原因
- 有时候会在分子分母中全部添加一个可选参数:Laplace smoothing
- 避免当 ∣ X ∣ |X| ∣X∣ 和 ∣ Y ∣ |Y| ∣Y∣ 都为 0 时,分子被 0 除的问题
- 减少过拟合
1.2. F1 score - Dice
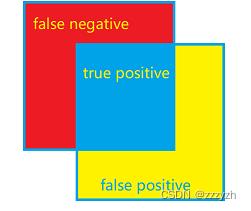
| Truth\\Classified | Positive | Negative |
|---|---|---|
| Positive | True Positive | False Negative |
| Negative | False Positive | True Negative |
- Precision
- 表示在预测为1的样本中实际为1的概率
P = T P T P + F P P = \\fracTPTP + FP P=TP+FPTP
- 表示在预测为1的样本中实际为1的概率
- Recall
- 表示在实际为1的样本中预测为1的概率
R = T P T P + F N R = \\fracTPTP + FN R=TP+FNTP
- 表示在实际为1的样本中预测为1的概率
- Precision 和 Recall 往往是相互制约的
- 如果提高模型的 Precision,就会降低模型的 Recall;
- 提高模型的 Recall 就会降低模型的 Precision
在二分类问题中,Dice coefficient 也可以写成:
D
i
c
e
=
2
T
P
F
P
+
2
T
P
+
F
N
=
F
1
s
c
o
r
e
Dice = \\frac2TPFP + 2TP +FN = F1score
Dice=FP+2TP+FN2TP=F1score
1.3. Dice Loss
Dice Loss 数学表达式如下:
D
i
c
e
L
o
s
s
=
1
−
D
i
c
e
=
1
−
2
∣
X
∩
Y
∣
∣
X
∣
+
∣
Y
∣
DiceLoss = 1 - Dice = 1 - \\frac2|X \\cap Y||X| + |Y|
DiceLoss=1−Dice=1−∣X∣+∣Y∣2∣X∩Y∣
当 Dice Loss 用于医学图像分割问题中,参数含义:
- X X X 表示真实分割图像的像素标签
- Y Y Y 表示模型预测分割图像的像素类别
- ∣ X ∩ Y ∣ |X \\cap Y| ∣X∩Y∣ 近似为预测图像的像素与真实标签图像的像素之间的点乘,并将点乘结果相加
- ∣ X ∣ |X| ∣X∣ 和 ∣ Y ∣ |Y| ∣Y∣ 分别近似为它们各自对应图像中的像素相加
对于二分类问题,真实分割标签图像的像素只有
0
0
0,
1
1
1 两个值,因此
∣
X
∩
Y
∣
|X \\cap Y|
∣X∩Y∣ 可以有效地将在预测分割图像中未在真实分割标签图像中激活的所有像素值清零,对于激活的像素,主要是惩罚低置信度的预测,置信度高的预测会得到较高的 Dice 系数,从而得到较低的 Dice Loss,即:
D
i
c
e
L
o
s
s
=
1
−
2
∑
i
=
1
N
y
i
y
i
^
∑
i
=
1
N
y
i
+
∑
i
=
1
N
y
i
^
DiceLoss = 1 - \\frac2\\sum_i=1^N y_i \\haty_i\\sum_i=1^N y_i + \\sum_i=1^N \\haty_i
DiceLoss=1−∑i=1Nyi+∑i=1Nyi^2∑i=1Nyiyi^
参数含义:
- y i y_i yi 表示像素 i i i 的标签值
- y i ^ \\haty_i yi^ 表示像素 i i i 的预测值
- N N N 为像素点总个数,等于单张图像的像素个数乘以 batchsize
Dice Loss 可以缓解样本中前景背景(面积)不平衡带来的消极影响,前景背景不平衡也就是说图像中大部分区域是不包含目标的,只有一小部分区域包含目标。Dice Loss 训练更关注对前景区域的挖掘,即保证有较低的 FN,但会存在损失饱和问题。因此单独使用 Dice Loss 往往并不能取得较好的结果,需要进行组合使用,比如 Dice Loss+CE Loss 或者 Dice Loss+Focal Loss 等
2. Sensitivity & Specificity
| Truth\\Classified | Positive | Negative |
|---|---|---|
| Positive | True Positive | False Negative |
| Negative | False Positive | True Negative |
- TP:P 表示你预测的 Positive,T (True) 表示你预测正确,TP 表示你把正样本预测为正样本
- FP:P 表示你预测的 Positive,F (False) 表示你预测错误,FP 表示你把负样本预测为正样本
- TN:N 表示你预测的 Negative,T (True) 表示你预测正确,TN 表示你把负样本预测为负样本
- FN:N 表示你预测的 Negative,F (False) 表示你预测错误,FP 表示你把正样本预测为负样本
- FP + TP = 所有分类为阳性的样本
- TP + FN = 真阳 + 假阴 = 所有真的是阳性的样本
2.1. Sensitivity
TPR:True positive rate,描述识别出的所有正例占所有正例的比例
计算公式:
T
P
R
=
T
P
T
P
+
F
N
TPR = \\fracTPTP+ FN
TPR=TP+FNTP
可以理解为患者实际有病且被正确诊断出来的概率,即敏感性高 = 漏诊率低(但假性多)
2.2. Specificity
FPR:False positive rate,描述将负例识别为正例的情况占所有负例的比例
F P R = F P F P + T N FPR = \\fracFPFP + TN FPR=FP+TNFP
可以理解为患者时间没病而且被正确确诊的概率,即特异性低 = 误诊率高(即假阴性多)
3. Hausdorff distance
3.1. 概念
Hausdorff distance 是度量空间中两个子集之间的距离,它将度量空间的非空子集本身转化为度量空间。
非正式地说,如果一个集合的每个点都接近另一个集合的某个点,那么两个集合在 Hausdorff distance 上是接近的。Hausdorff distance 是指对手在两组中的一组中选择一个点,然后必须从那里到达另一组的最长距离。换句话说,它是从一个集合中的一个点到另一个集合中最近的点的所有距离中最大的一个。
假设有两组集合:
A
=
a
1
,
a
2
,
⋯
,
a
p
,
B
=
b
1
,
b
2
,
⋯
,
b
p
A = \\ a^1, a^2, \\cdots, a^p \\, \\quad B = \\ b^1, b^2, \\cdots, b^p \\
A=a1,a2,⋯,ap,B=b1,b2,⋯,bp
3.2. 单向 Hausdorff distance
计算公式:
h
(
A
,
B
)
=
max
a
∈
A
min
b
∈
B
∣
∣
a
−
b
∣
∣
h
(
B
,
A
)
=
max
b
∈
A
min
a
∈
B
∣
∣
b
−
a
∣
∣
h(A, B) = \\displaystyle\\max_a \\in A\\displaystyle\\min_b \\in B || a - b || \\\\ h(B, A) = \\displaystyle\\max_b \\in A\\displaystyle\\min_a \\in B || b - a ||
h(A,B)=a∈Amaxb∈Bmin∣∣a−b∣∣h(B,A)=b∈Amaxa∈Bmin以上是关于MS:Metric的主要内容,如果未能解决你的问题,请参考以下文章