数据挖掘离群点检测方法详解及Sklearn中异常检测方法实战(附源码 超详细)
Posted showswoller
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘离群点检测方法详解及Sklearn中异常检测方法实战(附源码 超详细)相关的知识,希望对你有一定的参考价值。
需要源码请点赞关注收藏后评论区留言私信~~~
离群点的检测
离群点的检测方法很多,每种方法在检测时都会对正常数据对象或离群点作出假设,从所做假设的角度,离群点检测方法可以分为基于统计学的离群点检测、基于近邻的离群点检测、基于聚类以及基于分类的离群点检测
基于统计学的离群点检测
在基于统计学的离群点检测方法中,假设数据集中的正常数据对象由一个统计模型产生,如果某数据不符合该统计模型,则该数据对象是离群点。在基于统计的离群点检测过程中,一般先设定数据集的分布模型,如正态分布、泊松分布和二项式分布等,然后根据模型进行不和谐检验以发现离群点。不和谐检验中需要样本空间数据集的参数知识、分布的参数知识以及期望的离群点数目
离群点的统计检测方法中的不和谐检验需要两个假设,即工作假设和备择假设,工作假设指如果某样本点的某个统计量相对于数据分布其显著性概率充分小,则认为该样本点是不和谐的,工作假设被拒,备择假设被采用,即该样本点来自另一个分布模型,如果某样本点不符合工作假设,则认为它是离群点,如果符合备择假设,则认为它是符合某一备择假设的离群点
【例10-1】假设某类数据总体服从正态分布,现有部分数据6,7,6,8,9,10,8,11,7,9,12,7,11,8,13,7,8,14,9,12,基于统计方法检测离群点

基于邻近性的离群点检测
给定特征空间中的数据对象集,可以使用距离度量对象之间的相似性。直观地,远离其他大多数对象的数据对象被视为离群点。基于邻近性的方法假定离群点对象与它最近邻的邻近性显著偏离数据集中其他对象与其近邻之间的邻近性
基于邻近型的离群点检测方法有基于距离的和基于密度的方法
(1) 基于距离的离群点检测方法
在基于距离的离群点检测方法中,离群点就是远离大部分对象的点,即与数据集中的大多数对象的距离都大于某个给定阈值的点。基于距离的检测方法考虑的是对象给定半径的邻域。如果在某个对象的邻域内没有足够的其他的点,则称此对象为离群点。基于距离的离群点方法有嵌套-循环算法、基于索引的算法和基于单元的算法
基于距离的离群点方法有嵌套-循环算法、基于索引的算法和基于单元的算法。下面简要介绍嵌套-循环算法

(2) 基于密度的离群点检测方法
基于密度的离群点检测方法考虑的是对象与它近邻的密度。如果一个对象的密度相对于它的近邻低得多,则被视为离群点。最有代表性的基于密度的离群点检测方法是基于局部离群点离群因子的离群点检测方法
局部离群因子(Local Outlier Factor, LOF)会给数据集中的每个点计算一个离群因子LOF,通过判断LOF是否接近于1来判定是否是离群因子,若LOF大于1 则认为是离群点,若接近于1 则是正常点,对于任何给定的数据点,局部离群因子算法计算的离群度等于数据点P的K近邻集合的平均局部数据密度与数据点自身局部数据密度的比值
LOF是一个大于1的数值,并且没有固定的范围,而且当数据集通常数量较大,内部结构复杂时,有可能取到近邻点属于不同数据密度的聚类簇,使计算数据点的近邻平均数据密度产生偏差,导致得出与实际差别较大甚至相反的结果
基于聚类的离群点检测
离群点与簇的概念高度相关,因此,可以通过考察对象与簇之间的关系检测离群点。直观地,离群点是一个属于小的偏远簇或者不属于任何簇的数据对象。基于聚类的离群点检测方法分为两个阶段,首先对数据进行聚类,然后计算对象或簇的离群因子,将离群因子大的对象或稀疏簇中的对象判定为离群点。对于基于原型的聚类,可以用对象到其簇中心的距离度量对象属于簇的程度
基于分类的离群点检测
如果训练数据中有类标号,则可以将其视为分类问题。该问题的解决思路是训练一个可以区分正常数据和离群点的分类模型。构造分类器时,训练数据的分布可能极不均衡,相对正常数据,离群点的数目极少,这样会造成在构建分类器时精度收到很大影响。为了解决两类数据的不均衡问题,可以使用一类模型(One-class Model)进行检测,简单来说,就是构建一个仅描述正常类的分类器,不属于任何正常类的任何样本都属于离群点,仅使用正常类的模型可以检测所有离群点,只要数据对象在决策边界外,就认为是离群点,数据和正常数据的距离变得不再重要,避免了提取离群点数据的繁重工作,但这种方式受训练数据的影响非常大
sklearn中的异常值检测方法
sklearn中关于异常检测的方法主要有两种
(1)novelty detection:当训练数据中没有离群点,我们的目标是用训练好的模型去检测另外新发现的样本
(2)outlier detection:当训练数据中包含离群点,模型训练时要匹配训练数据的中心样本,忽视训练样本中的其他异常点
sklearn提供了一些机器学习方法,可用于奇异(Novelty)点或异常(Outlier)点检测,包括OneClassSVM、Isolation Forest、Local Outlier Factor (LOF) 等。其中OneClassSVM可用于Novelty Detection,而后两者可用于Outlier Detection
下面用OneClassSVM检测奇异点
输出结果如下图所示
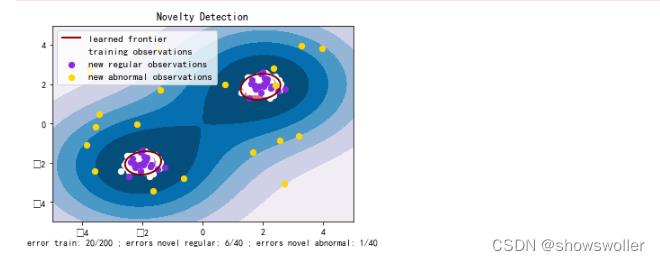
部分代码如下
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager
from sklearn import svm
xx, yy = np.meshgrid(np.linspace(-5, 5, 500), np.linspace(-5, 5, 500))
# Generate train data
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_teliers = y_pred_outliers[y_pred_outliers == 1].size
# plot the line, the points, and the nearest vectors to the plane
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.title("Novelty Detection")
plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 7), cmap=plt.cm.PuBu)
a = plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='darkred')
plt.contourf(xx, yy, Z, levels=[0, Z.max()], colors='palevioletred')
s = 40
plt.xlim((-5, 5))
plt.ylim((-5, 5))
plt.legend([a.collections[0], b1, b2, c],
["learned frontier", "training observations",
"new regular observations", "new abnormal observations"],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11))
plt.xlabel(
"error train: %d/200 ; errors novel regular: %d/40 ; "
"errors novel abnormal: %d/40"
% (n_error_train, n_error_test, n_error_outliers))
plt.show()利用EllipticEnvelope实现对离群点的检测,它是sklearn协方差估计中对高斯分布数据集的离群点检测方法,该方法在高维度下的表现效果欠佳

代码如下
import numpy as np
from sklearn.covariance import EllipticEnvelope
xx, yy = np.meshgrid(np.linspace(-5, 5, 500), np.linspace(-5, 5, 500))
# 生成训练数据
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X+2, X-2]
# 生成新用于测试的数据
X = 0.3 * np.random.randn(10, 2)
X_test = np.r_[X + 2, X - 2]
# 模型拟合
clf = EllipticEnvelope()
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
print ("novelty detection result:\\n",y_pred_test)总结
离群点(Outlier)是指显著偏离一般水平的观测对象
离群点不同于噪声数据
离群点一般分为全局离群点、条件离群点和集体离群点
离群点检测方法可以分为基于统计学的离群点检测、基于近邻的离群点检测、基于聚类以及基于分类的离群点检测
在基于统计学的离群点检测方法中,假设数据集中的正常数据对象由一个统计模型产生,如果某数据不符合该统计模型,则该数据对象是离群点
基于邻近性的方法假定离群点对象与它最近邻的邻近性显著偏离数据集中其他对象与其近邻之间的邻近性。基于邻近型的离群点检测方法有基于距离的和基于密度的方法
创作不易 觉得有帮助请点赞关注收藏~~~
以上是关于数据挖掘离群点检测方法详解及Sklearn中异常检测方法实战(附源码 超详细)的主要内容,如果未能解决你的问题,请参考以下文章