Hadoop3 - HDFS DataNode 动态扩容和缩容
Posted 小毕超
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop3 - HDFS DataNode 动态扩容和缩容相关的知识,希望对你有一定的参考价值。
一、HDFS 动态扩容和缩容
上篇文章对 HDFS 的文件存储策略进行了讲解,本篇文章继续学习 HDFS 的动态扩容和缩容,下面是上篇文章地址:
动态扩容:已有HDFS集群容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的DataNode节点。
动态缩容:旧的服务器需要进行退役更换,暂停服务,需要在当下的集群中停止某些机器上HDFS的服务。
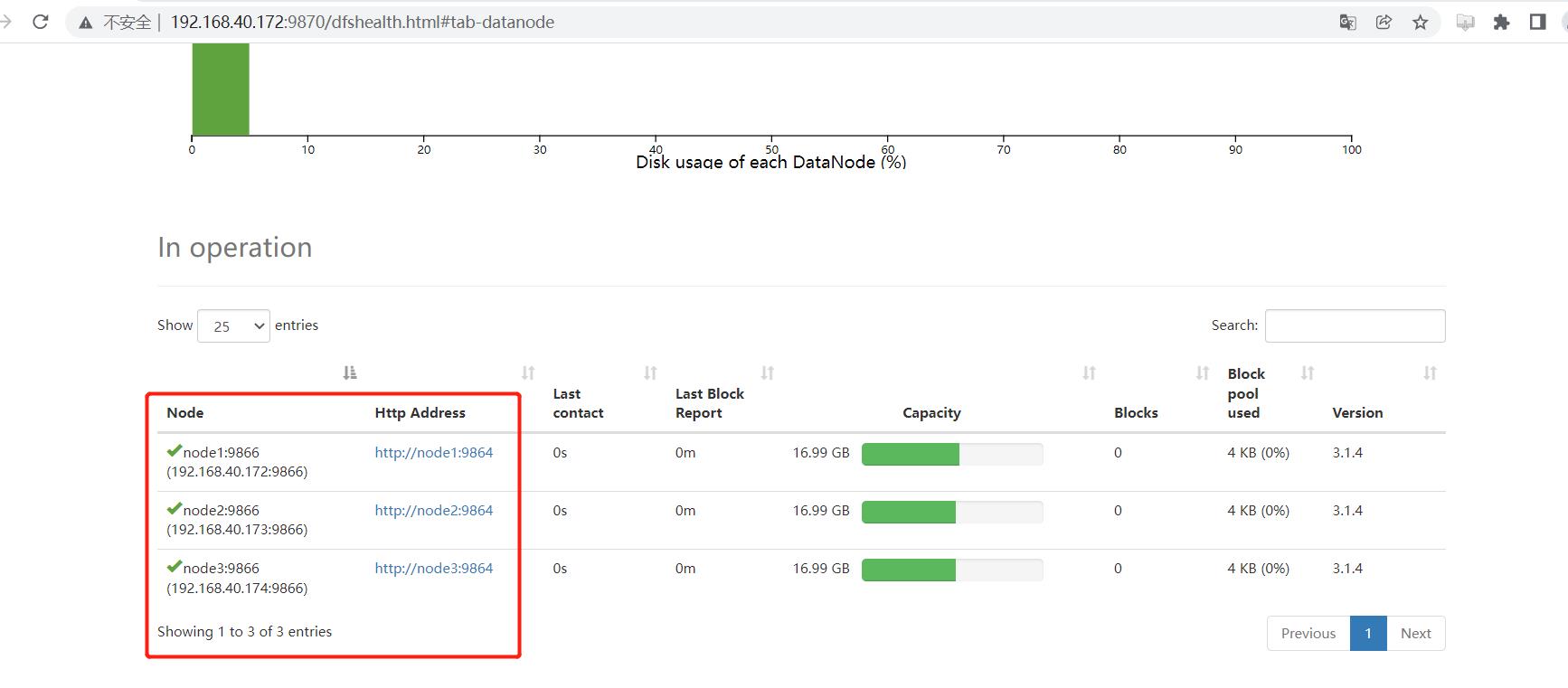
在进行扩容和缩容前,先看下当前的 HDFS 集群结构:
| 主机 | 规划设置主机名 | 角色 |
|---|---|---|
| 192.168.40.172 | node1 | NameNode、DataNode、ResourceManager、NodeManager |
| 192.168.40.173 | node2 | SecondaryNameNode、DataNode、NodeManager |
| 192.168.40.174 | node3 | DataNode、NodeManager |
下面将在该集群架构的基础上进行操作,如果还没有搭建集群,可以参考下面这篇我的文章:
二、DataNode 扩容
下面我们增加一台主机,该主机已安装好 JAVA 环境,下面对 DataNode 进行扩容,总体结构如下:
| 主机 | 规划设置主机名 | 角色 |
|---|---|---|
| 192.168.40.172 | node1 | NameNode、DataNode、ResourceManager、NodeManager |
| 192.168.40.173 | node2 | SecondaryNameNode、DataNode、NodeManager |
| 192.168.40.174 | node3 | DataNode、NodeManager |
| 192.168.40.175 | node4 | DataNode |
- 增加
node1到node4的免密登录,方便后面使用一键操作脚本
ssh-copy-id 192.168.40.175
- 修改
node1节点 /etc/hosts 增加node4的映射
vi /etc/hosts
192.168.40.172 node1
192.168.40.173 node2
192.168.40.174 node3
192.168.40.175 node4
将修改后的 hosts 同步至其余主机:
scp /etc/hosts root@node2:/etc/hosts
scp /etc/hosts root@node3:/etc/hosts
scp /etc/hosts root@node4:/etc/hosts
- 修改
node1节点hadoop安装包下etc/hadoop/workers文件,增加node4节点:
vi workers
node1
node2
node3
node4
node4节点时间同步,并创建同意的工作目录
yum -y install ntpdate
ntpdate ntp4.aliyun.com
mkdir -p /export/server/,/export/data/,/export/software/
- 将
node1节点修改后的hadoop包,同步至node4节点的相同目录下:
cd /export/server/
scp -r hadoop-3.1.4 root@node4:/export/server/
- 将
node1节点的环境变量,同步至node4节点:
scp /etc/profile root@node4:/etc/
- 进入
node4节点重新加载环境变量
source /etc/profile
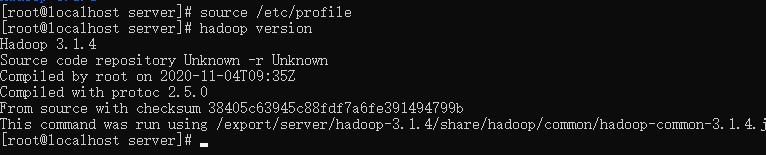
node4节点验证环境是否生效:
hadoop version
node4节点设置hostname标识自己为node4
hostname node4
node4节点启动DataNode服务
hdfs --daemon start datanode
- 到 HDFS 的web管理页查看是否增加成功:
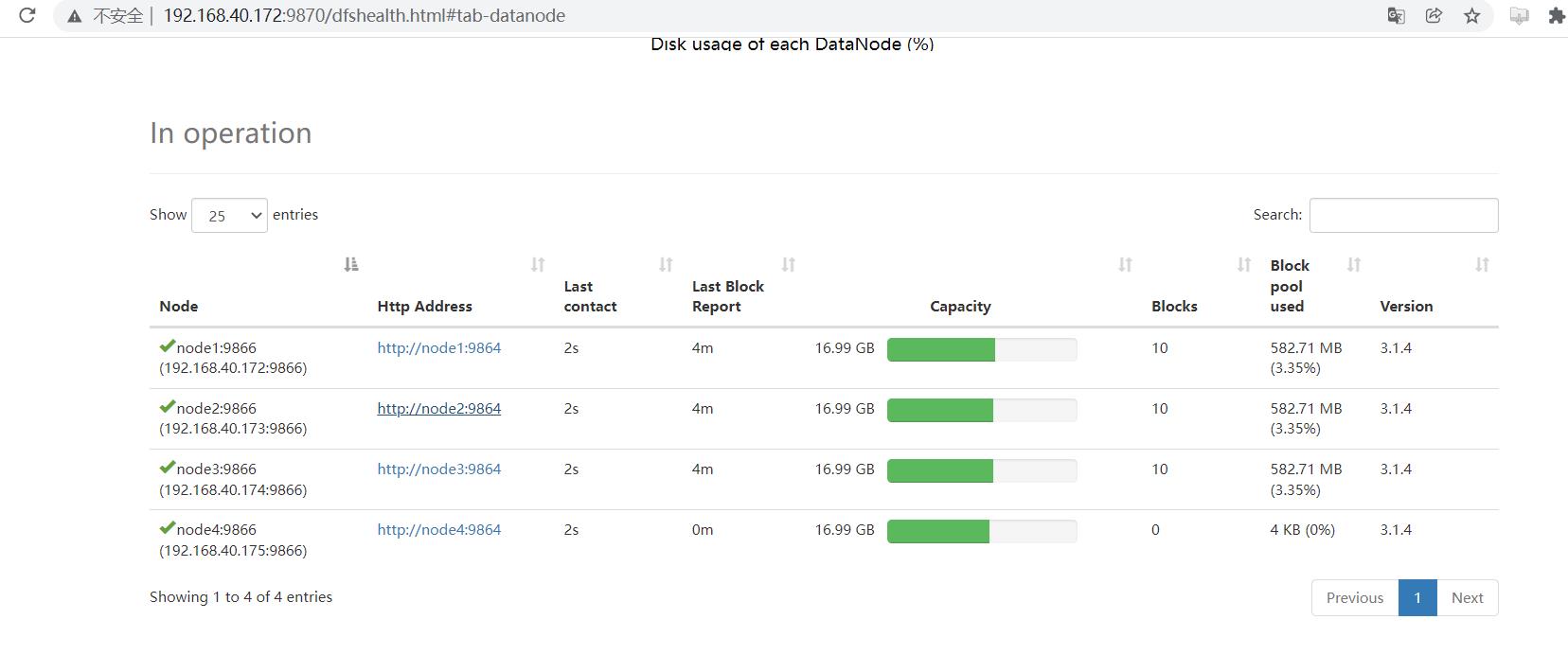
可以看到 node4 节点已经上线,但没有数据块的存储,使得集群整体来看负载不均衡。因此最后还需要对hdfs负载设置均衡。
DataNode负载均衡服务,在node1节点操作
首先设置数据传输带宽为 100M 过大的话,有可能影响业务服务的操作。
hdfs dfsadmin -setBalancerBandwidth 104857600
启动Balancer,其中 threshold 参数如果为 5 的话,则表示以阈值5%运行(默认值10%),这意味着程序将确保每个DataNode上的磁盘使用量与群集中的总体使用量相差不超过5%。例如,如果集群中所有DataNode的总体使用率是集群磁盘总存储容量的40%,则程序将确保每个DataNode的磁盘使用率在该DataNode磁盘存储容量的35%至45%之间。
由于我原有集群数据不多,这里我把阈值设为 1 ,方便看到效果:
hdfs balancer -threshold 1
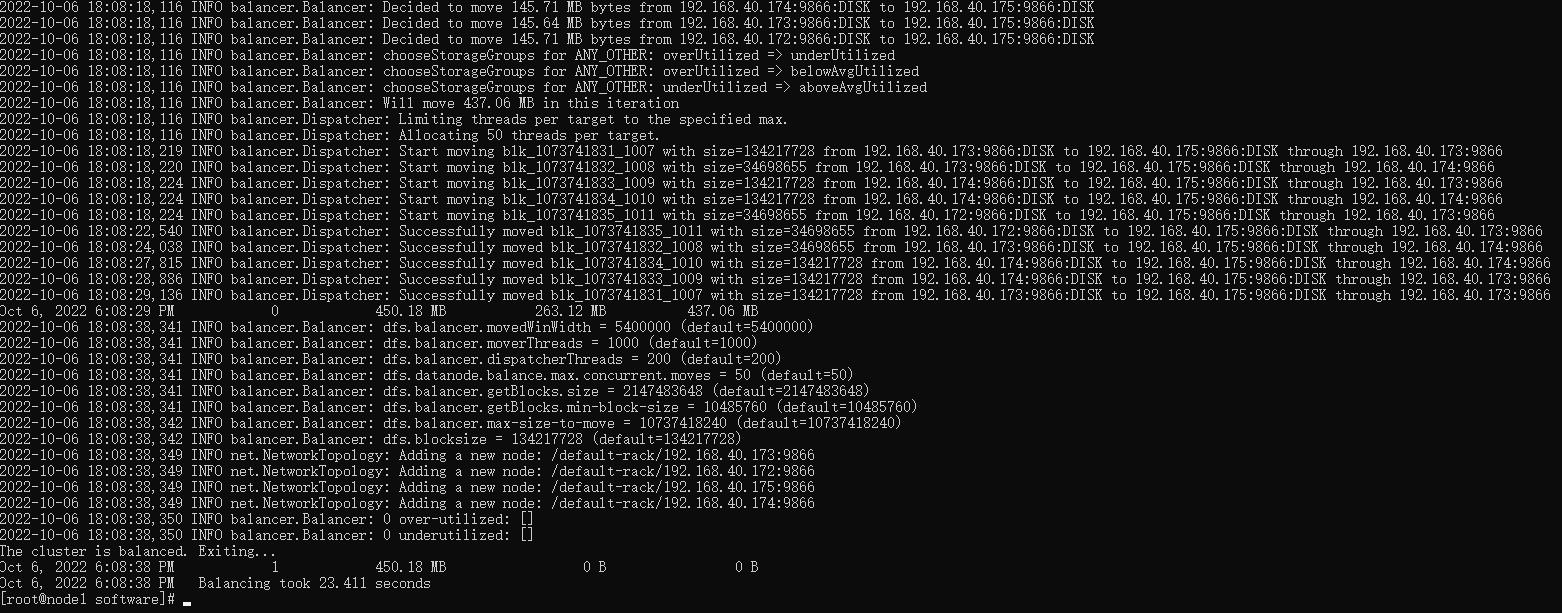
在到 web 管理页面查看:
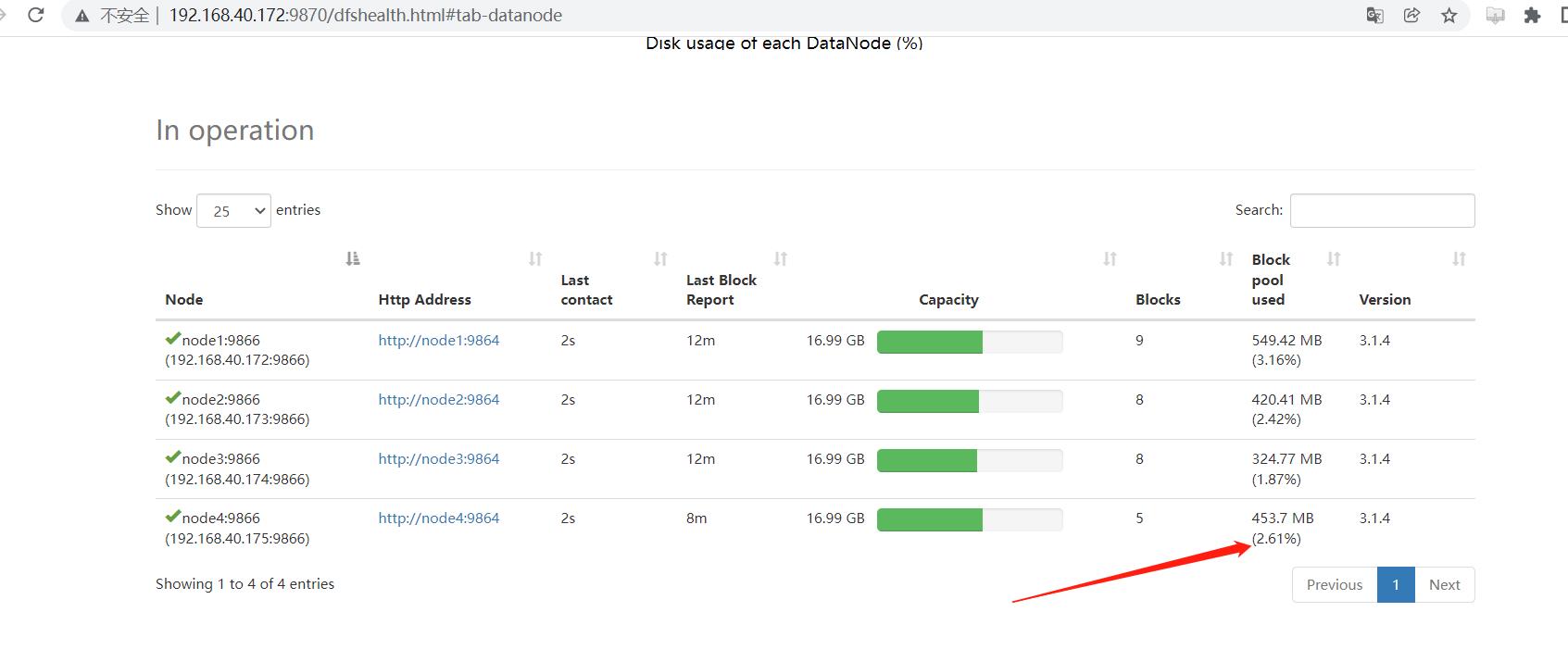
数据已经均衡了。
三、DataNode 缩容
DataNode 缩容,不像扩容那样启动一个节点即可, 缩容还需要把当前节点数据移出去才可以,hadoop 已经提供了下线功能,前提是在namenode机器的hdfs-site.xml配置文件中需要提前配置dfs.hosts.exclude属性,该属性指向的文件就是所谓的黑名单列表,会被namenode排除在集群之外。如果文件内容为空,则意味着不禁止任何机器。所以在安装 hadoop 的时候就需要指定好改配置,如果最开始没有配置该参数,则需要添加后重启 namenode 。
修改 hdfs-site.xml 文件:
vi hdfs-site.xml
<property>
<name>dfs.hosts.exclude</name>
<value>/export/server/hadoop-3.1.4/etc/hadoop/excludes</value>
</property>

重启 namenode 使其生效。
编辑 /export/server/hadoop-3.1.4/etc/hadoop/excludes 文件,添加需要下线的主机名称。
注意:如果副本数是3,在线的节点小于等于3,是不能下线成功的,需要修改副本数后才能下线。

下面在 namenode 所在的机器刷新节点:
hdfs dfsadmin -refreshNodes

下面到 web 管理页查看:

node4 节点正在下线中,稍等一会在刷新下:

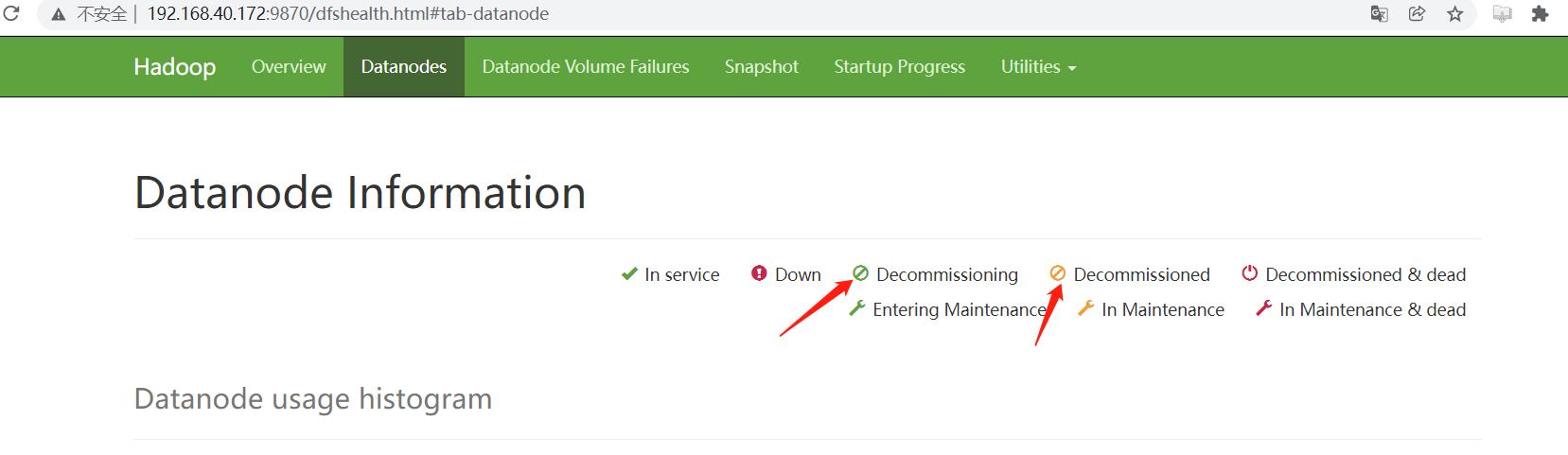
已经下线成功,在该页面的最上方可以看到该图标的解释:
最后就可以放心的将 node4 节点的 DataNode 服务停掉了:
hdfs --daemon stop datanode
如果剩下的HDFS集群,出现分布不均衡,则进行负载均衡服务:
hdfs balancer -threshold 5
以上是关于Hadoop3 - HDFS DataNode 动态扩容和缩容的主要内容,如果未能解决你的问题,请参考以下文章