Spark - COVID-19 案例实践使用 ScalaJavaPython 三种语言演示
Posted 小毕超
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark - COVID-19 案例实践使用 ScalaJavaPython 三种语言演示相关的知识,希望对你有一定的参考价值。
一、COVID-19 案例
在前面的文章中,有使用 MapReduce 实践 COVID-19 新冠肺炎案例,本篇基于 Spark 对该数据集进行分析,下面是 MapReduce 案例的文章地址:
数据格式如下所示:
date(日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例)
2021-01-28,Pike,Alabama,01109,2704,35
2021-01-28,Randolph,Alabama,01111,1505,37
2021-01-28,Russell,Alabama,01113,3675,16
2021-01-28,Shelby,Alabama,01117,19878,141
2021-01-28,St. Clair,Alabama,01115,8047,147
2021-01-28,Sumter,Alabama,01119,925,28
2021-01-28,Talladega,Alabama,01121,6711,114
2021-01-28,Tallapoosa,Alabama,01123,3258,112
2021-01-28,Tuscaloosa,Alabama,01125,22083,283
2021-01-28,Walker,Alabama,01127,6105,185
2021-01-28,Washington,Alabama,01129,1454,27
数据集下载:
二、计算各个州的累积cases、deaths
思路:
- 读取数据集
- 转换键值对,
key:州,value:各个县的cases、deaths值 - 根据
key聚合,相加cases、deaths值 - 根据州排序输出
- Scala:
object CovidSum
case class CovidVO(cases: Long, deaths: Long) extends java.io.Serializable
def main(args: Array[String]): Unit =
val conf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val t1 = sc.textFile("D:/test/input/")
t1.filter(StringUtils.isNotBlank)
.map(s =>
val line = s.split(",")
if (line.size >= 6)
val state = line(2)
val cases = line(4).toLong
val deaths = line(5).toLong
(state, CovidVO(cases, deaths))
else
null
).filter(Objects.nonNull)
.reduceByKey((v1, v2) => CovidVO(v1.cases + v2.cases, v1.deaths + v2.deaths))
.sortByKey(ascending = true, 1)
.foreach(t =>
println(t._1 + " " + t._2.cases + " " + t._2.deaths)
)
- Java:
public class CvoidSum
@Data
@AllArgsConstructor
@NoArgsConstructor
static class CovidVO implements Serializable
private Long cases;
private Long deaths;
public static void main(String[] args)
SparkConf conf = new SparkConf().setAppName("spark").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("WARN");
JavaRDD<String> t1 = sc.textFile("D:/test/input/");
t1.filter(StringUtils::isNotBlank)
.mapToPair(s ->
List<String> line = Arrays.asList(s.split(","));
if (line.size() >= 6)
String state = line.get(2);
Long cases = Long.parseLong(line.get(4));
Long deaths = Long.parseLong(line.get(5));
return new Tuple2<>(state, new CovidVO(cases, deaths));
return null;
).filter(Objects::nonNull)
.reduceByKey((v1, v2) -> new CovidVO(v1.getCases() + v2.getCases(), v1.getDeaths() + v2.getDeaths()))
.sortByKey(true, 1)
.foreach(t ->
System.out.println(t._1 + " " + t._2.getCases() + " " + t._2.getDeaths());
);
- Python:
from pyspark import SparkConf, SparkContext
import findspark
if __name__ == '__main__':
findspark.init()
conf = SparkConf().setAppName('spark').setMaster('local[*]')
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
t1 = sc.textFile("D:/test/input/")
def mapT(s):
line = s.split(",")
if (len(line) >= 6):
state = line[2]
casesStr = line[4]
deathsStr = line[5]
cases = int(casesStr if (casesStr and casesStr != '') else '0')
deaths = int(deathsStr if (deathsStr and deathsStr != '') else '0')
return (state, (cases, deaths))
else:
return None
t1.filter(lambda s: s and s != '') \\
.map(mapT) \\
.filter(lambda s: s != None) \\
.reduceByKey(lambda v1, v2: (v1[0] + v2[0], v1[1] + v2[1])) \\
.sortByKey(ascending=True, numPartitions=1) \\
.foreach(lambda t: print(t[0] + " " + str(t[1][0]) + " " + str(t[1][1])))
统计结果:
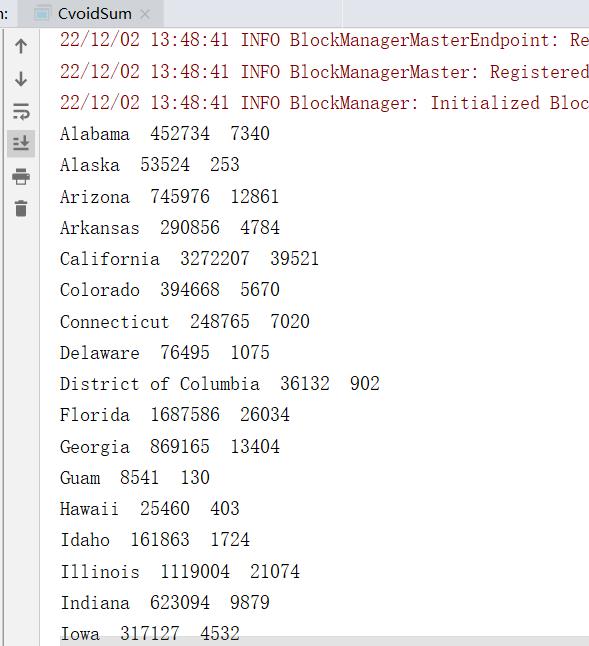
三、计算各个州的累积cases、deaths,并根据 deaths 降序排列
思路:
- 读取数据集
- 转换键值对,
key:州,value:各个县的cases、deaths值 - 根据
key聚合,相加cases、deaths值 - 根据
value中的deaths降序排列输出
- Scala:
object CovidSumSortDeaths
def main(args: Array[String]): Unit =
val conf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val t1 = sc.textFile("D:/test/input/")
t1.filter(StringUtils.isNotBlank)
.map(s =>
val line = s.split(",")
if (line.size >= 6)
val state = line(2)
val cases = line(4).toLong
val deaths = line(5).toLong
(state, CovidVO(cases, deaths))
else
null
).filter(Objects.nonNull)
.reduceByKey((v1, v2) => CovidVO(v1.cases + v2.cases, v1.deaths + v2.deaths))
.sortBy(_._2.deaths, ascending = false, 1)
.foreach(t =>
println(t._1 + " " + t._2.cases + " " + t._2.deaths)
)
- Java:
public class CvoidSumSortDeaths
@Data
@AllArgsConstructor
@NoArgsConstructor
static class CovidVO implements Serializable
private Long cases;
private Long deaths;
public static void main(String[] args)
SparkConf conf = new SparkConf().setAppName("spark").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("WARN");
JavaRDD<String> t1 = sc.textFile("D:/test/input/");
t1.filter(StringUtils::isNotBlank)
.mapToPair(s ->
List<String> line = Arrays.asList(s.split(","));
if (line.size() >= 6)
String state = line.get(2);
Long cases = Long.parseLong(line.get(4));
Long deaths = Long.parseLong(line.get(5));
return new Tuple2<>(state, new CovidVO(cases, deaths));
return null;
).filter(Objects::nonNull)
.reduceByKey((v1, v2) -> new CovidVO(v1.getCases() + v2.getCases(), v1.getDeaths() + v2.getDeaths()))
.map(t -> new Tuple2<String, CovidVO>(t._1, t._2))
.sortBy(t -> t._2.getDeaths(), false, 1)
.foreach(t ->
System.out.println(t._1 + " " + t._2.getCases() + " " + t._2.getDeaths());
);
- Python:
from pyspark import SparkConf, SparkContext
import findspark
if __name__ == '__main__':
findspark.init()
conf = SparkConf().setAppName('spark').setMaster('local[*]')
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
t1 = sc.textFile("D:/test/input/")
def mapT(s):
line = s.split(",")
if (len(line) >= 6):
state = line[2]
casesStr = line[4]
deathsStr = line[5]
cases = int(casesStr if (casesStr and casesStr != '') else '0')
deaths = int(deathsStr if (deathsStr and deathsStr != '') else '0')
return (state, (cases, deaths))
else:
return None
t1.filter(lambda s: s and s != '') \\
.map(mapT) \\
.filter(lambda s: s != None) \\
.reduceByKey(lambda v1, v2: (v1[0] + v2[0], v1[1] + v2[1])) \\
.sortBy(lambda t: t[1][1], ascending=False, numPartitions=1) \\
.foreach(lambda t: print(t[0] + " " + str(t[1][0]) + " " + str(t[1][1])))
统计结果:
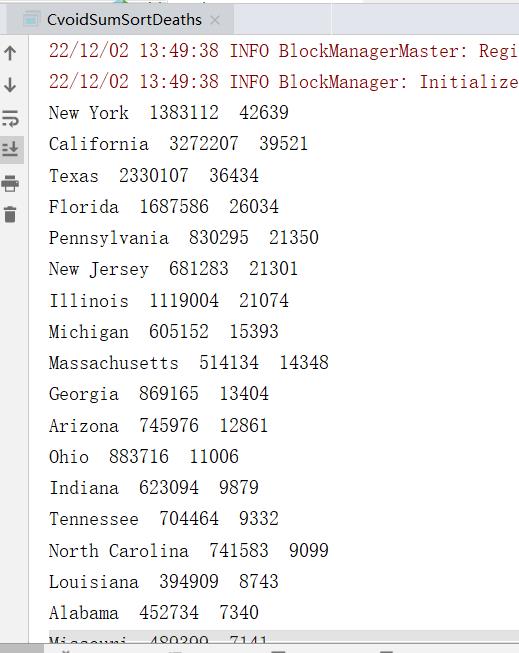
四、计算各个州根据 deaths 排列Top3的县
思路:
- 读取数据集
- 转换键值对,
key:州,value:各个 县 以及cases、deaths值 - 根据
key聚合,相加cases、deaths值 - 声明一个长度为
3的数组,来实时计算存储top3的值,从而减少全量排序的Shuffle占用内存过大问题 - 先计算出每个分区
top3的值 - 对各个分区
top3的值进行比较求取最终top3的值 - 根据州排序输出
- Scala:
object CovidTopDeaths
case class CovidVO(county: String, cases: Long, deaths: Long) extends java.io.Serializable
def main(args: Array[String]): Unit =
val conf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val t1 = sc.textFile("D:/test/input/")
t1.filter(StringUtils.isNotBlank)
.map(s =>
val line = s.split(",")
if (line.size >= 6)
val state = line(2)
val county = line(1)
val cases = line(4).toLong
val deaths = line(5).toLong
(state, CovidVO(county, cases, deaths))
else
null
).filter(Objects.nonNull)
.aggregateByKey(new Array[CovidVO](3))(
(zeroValue: Array[CovidVO], currentValue: CovidVO) =>
comparison(zeroValue, currentValue)
,
(topP1: Array[CovidVO], topP2: Array[CovidVO]) =>
var top = topP2
for (topP1Value <- topP1)
top = comparison(top, topP1Value)
top
).sortByKey(ascending = true, 1)
.foreach(t =>
for (topValue <- t._2)
if (Objects.nonNull(topValue)) println(t._1 + " " + topValue)
)
<以上是关于Spark - COVID-19 案例实践使用 ScalaJavaPython 三种语言演示的主要内容,如果未能解决你的问题,请参考以下文章