《Getting Started with NLP》chap11:Named-entity recognition
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Getting Started with NLP》chap11:Named-entity recognition相关的知识,希望对你有一定的参考价值。
《Getting Started with NLP》chap11:Named-entity recognition
最近需要做一些NER相关的任务,来学习一下这本书的第十一章
文章目录
- 《Getting Started with NLP》chap11:Named-entity recognition
- 11.1 Named entity recognition: Definitions and challenges
- 11.2 Named-entity recognition as a sequence labeling task
- 11.3 Practical applications of NER
- Summary
- 参考资料
-
This chapter covers
-
Introducing named-entity recognition (NER)
-
Overviewing sequence labeling approaches in NLP
-
Integrating NER into downstream tasks
什么是downstream task:
Downstream tasks refer to tasks that depend on the output of a previous task. For example, if task A is to extract data from a website, and task B is to analyze the data that was extracted, then task B is a downstream task of task A. Downstream tasks are often used in natural language processing (NLP) to refer to tasks that use the output of a natural language model as input. For example, once a natural language model has generated a set of language inputs, downstream tasks might include tasks like text classification, question answering, or machine translation. -
Introducing further data preprocessing tools and techniques
-
-
In this chapter, you will be working with the task of named-entity recognition (NER), concerned with detection and type identification of named entities (NEs). Named entities are real-world objects (people, locations, organizations) that can be referred to with a proper name. The most widely used entity types include person, location (abbreviated as LOC), organization (abbreviated as ORG), and geopolitical entity (abbreviated as GPE).
In practice, the set of name extended with further expressions such as dates, time references, numerical expressions (e.g., referring to money and currency(货币) indicators), and so on. Moreover, the types listed so far are quite general, but NER can also be adapted to other domains and application areas. For example, in biomedical(生物医学) applications, “entities” can denote different types of proteins and genes, in the financial domain they can cover specific types of products, and so on.
-
Named entities play an important role in natural language understanding (you have already seen examples from question answering and information extraction) and can be combined with the tasks that you addressed earlier in this book. Such tasks, which rely on the output of NLP tools (e.g., NER models) are technically called downstream tasks, since they aim to solve a problem different from, say, NER itself, but at the same time they benefit from knowing about named entities in text. For instance, identifying entities related to people, locations, organizations, and products in reviews can help better understand users’ or customers’ sentiments toward particular aspects of the product or service.
-
examples: the use of NER for two downstream tasks.
-
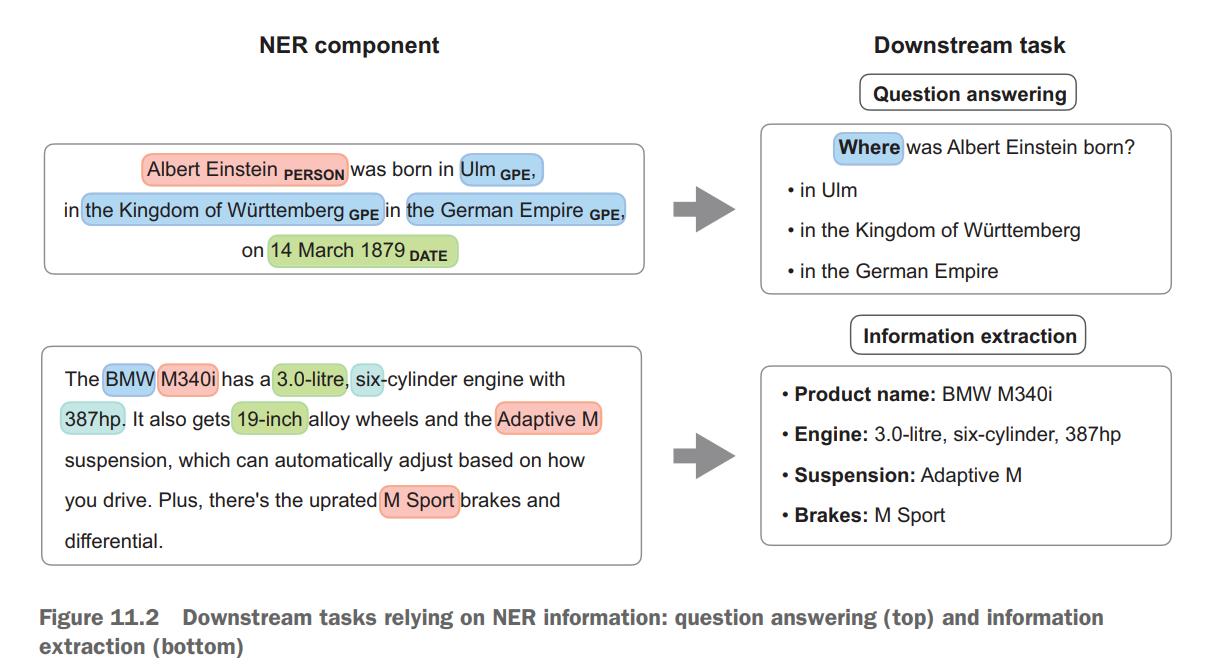
In the context of question answering, NER helps to identify the chunks of text that can answer a specific type of a question.
- For example, named entities denoting locations (LOC), or geopolitical entities (GPE) are appropriate as answers for a Where?question.
-
In the context of information extraction, NER can help identify useful characteristics of a product that may be informative on their own or as features in a sentiment analysis or another related task.
-
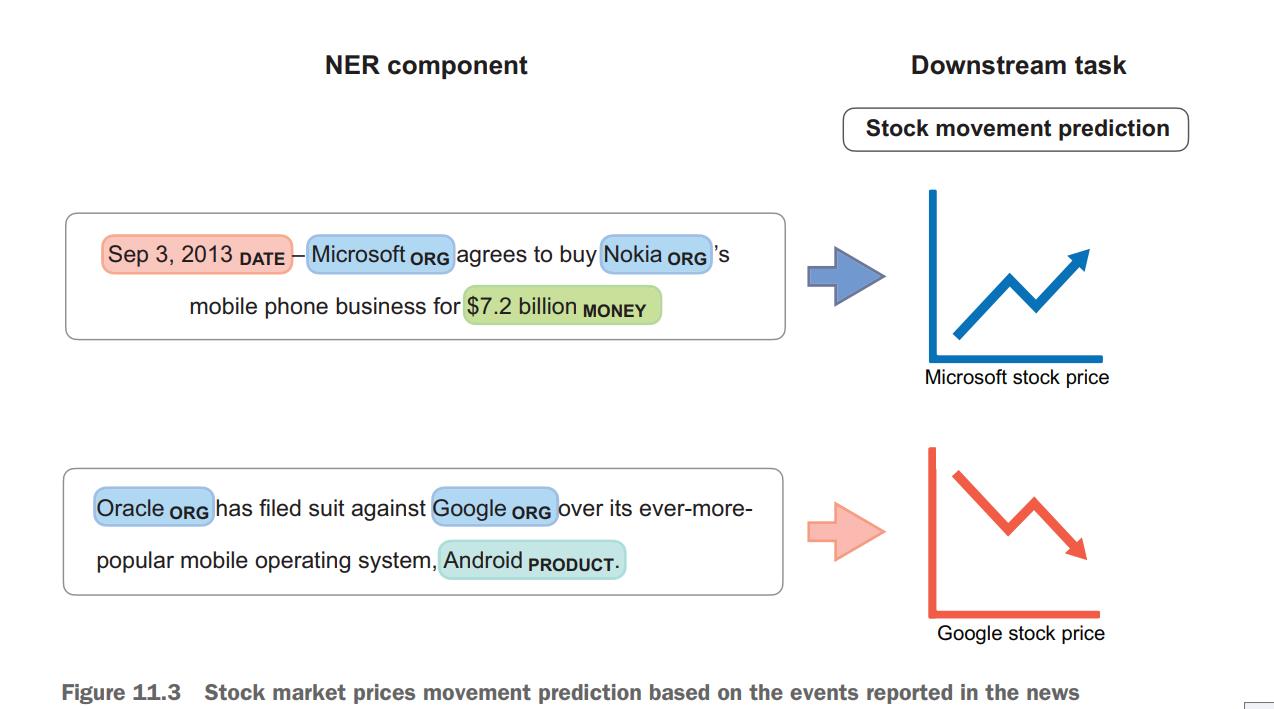
Another example of a downstream task in which NER plays a central role is stock market movement prediction. It is widely known that certain types of events influence the trends in stock price movements (for more examples and justification, see Ding et al. [2014], Using Structured Events to Predict Stock Price Movement: An Empirical Investigation, which you can access at https://aclanthology.org/D14-1148.pdf). For instance, the news about Steve Jobs’s death negatively impacted Apple’s stock price immediately after the event, while the news about Microsoft buying a new mobile phone business positively impacted its stock price. Suppose your goal is to build an application that can extract relevant facts from the news (e.g., “Apple’s CEO died”; “Microsoft buys mobile phone business”; “Oracle sues Google”) and then use these facts to predict stock prices for these companies. Figure 11.3 visualizes this idea
-
-
11.1 Named entity recognition: Definitions and challenges
11.1.1 Named entity types
- We start by defining the major named entity types and their usefulness for downstream tasks. Figure 11.4 shows entities of five different types (GPE for geopolitical entity, ORG for organization, CARDINAL for cardinal numbers, DATE, and PERSON) highlighted in a typical sentence that you could see on the news

cardinal (also cardinal number)
a number that represents amount, such as 1, 2, 3, rather than order, such as 1st, 2nd, 3rd
基数
In natural language processing, “cardinal” is a type of entity that refers to a numerical value. In named entity recognition (NER), cardinal entities are numbers that represent a specific quantity, such as “five” or “twenty-three.” Cardinal entities are often distinguished from other types of numerical entities, such as ordinal entities (which indicate a position in a sequence, such as “first” or “third”) and percentage entities (which represent a ratio or proportion, such as “50%”). NER systems may use machine learning algorithms to identify and classify cardinal entities in text data.
-
The notation(符号) used in this sentence is standard for the task of named entity recognition: some labels like DATE and PERSON are self-explanatory(无需解释的); others are abbreviations(缩写)or short forms of the full labels (e.g., ORG for organization). The set of labels comes from the widely adopted annotation(注释) scheme(方案)in OntoNotes (see full documentation at http://mng.bz/Qv5R). What is important from a practitioner’s(从业者) point of view is that this is the scheme that is used in NLP tools, including spaCy.
-
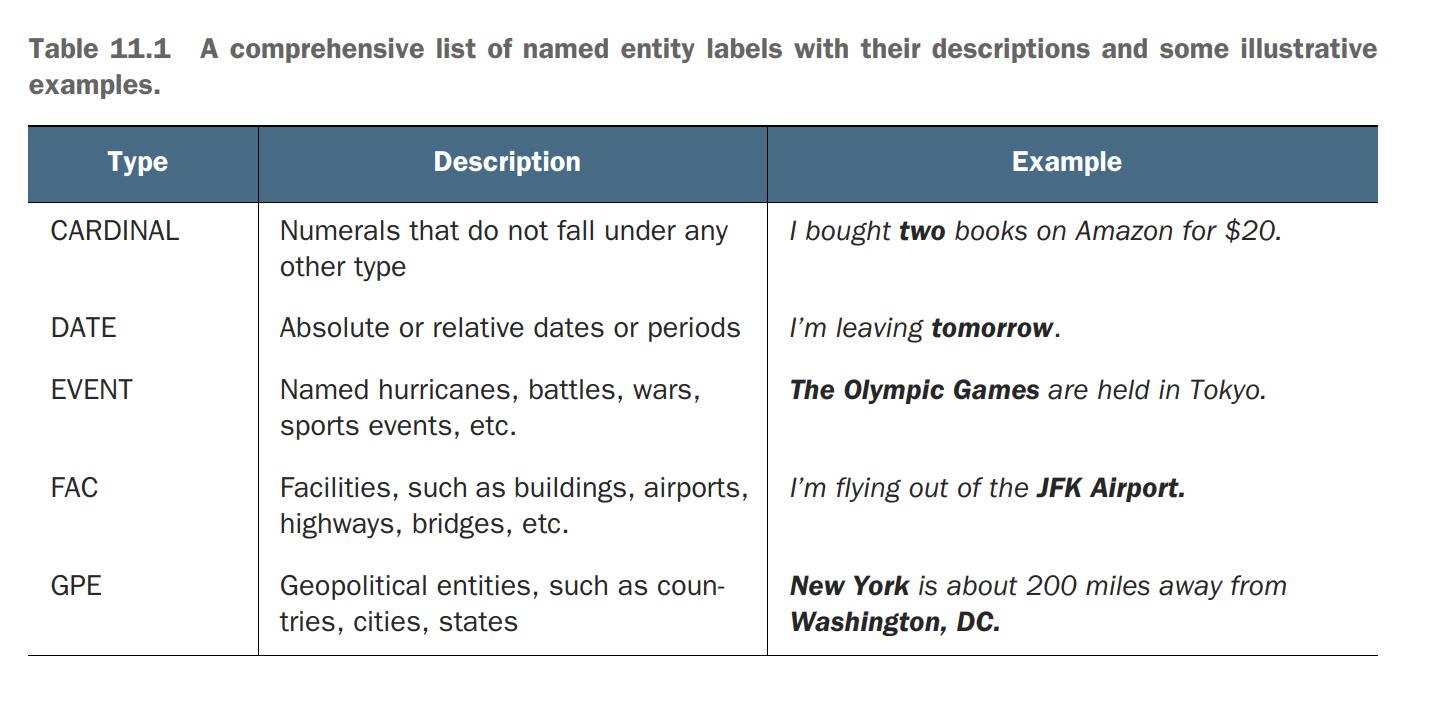
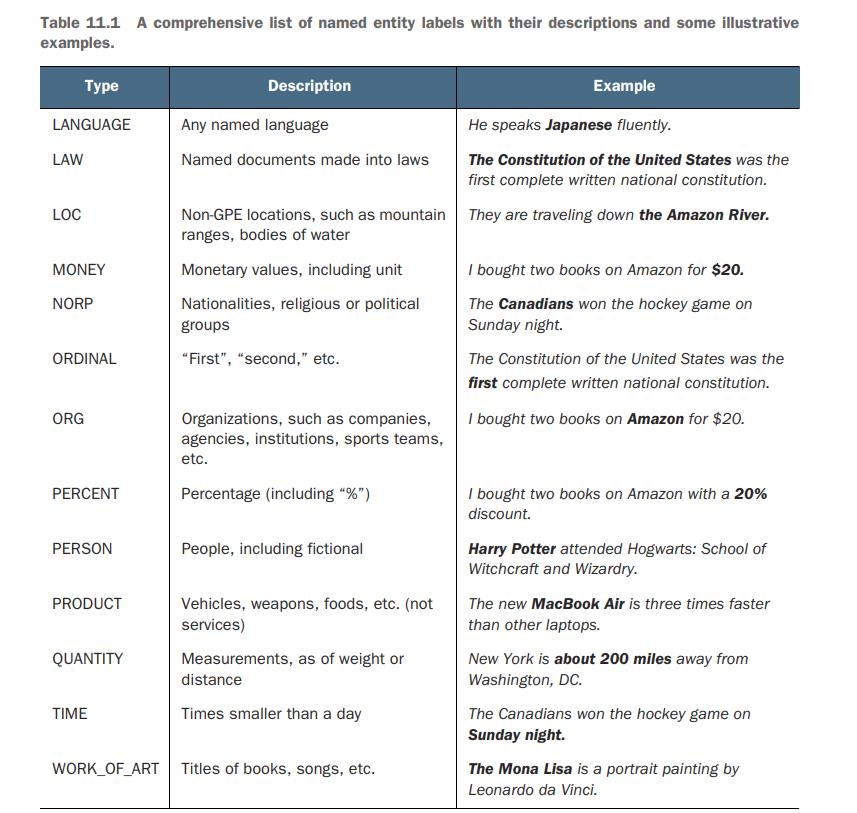
Table 11.1 lists all named entity types typically used in practice and identified in text by spaCy’s NER component and provides a description and some illustrative examples for each of them.
-
A couple of observations are due at this point. (需要注意的是)
- First, note that named entities of any type can consist of a single word (e.g., “two” or “tomorrow”) and longer expressions (e.g., “MacBook Air” or “about 200 miles”).
- Second, the same word or expression may represent an entity of a different type, depending on the context. For example, “Amazon” may refer to a river (LOC) or to a company (ORG).
Exercise 11.1
The NE labeling presented in table 11.1 is used in spaCy. Familiarize yourself with the types and annotation by running spaCy’s NER on a selected set of examples. You can use the sentences from table 11.1 or experiment with your own set of sentences. Do you disagree with any of the results?
-
code
import spacy nlp = spacy.load("en_core_web_sm") doc = nlp("I bought two books on Amazon") for ent in doc.ents: print(ent.text, ent.label_)输出结果为
two CARDINAL Amazon ORG- 前置除了需要install spacy ,还需要
python -m spacy download en_core_web_sm
- 前置除了需要install spacy ,还需要
NOTE Check out the different language models available for use with spaCy: https://spacy.io/models/en.
- Small model (en_core_web_sm) is suitable for most purposes and is more efficient to upload and use.
- However, larger models like en_core_web_md (medium) and en_core_web_lg (large) are more powerful, and some NLP tasks will require the use of such larger models. The models should be installed prior to running the code examples with spaCy. You can also install the models from within the Jupyter Notebook using the command
!python -m spacy download en_core_web_md.spaCy的官方文档感觉很不错
11.1.2 Challenges in named entity recognition
NER is a task concerned with identification of a word or phrase that constitutes an entity and with detection of the type of the identified entity. As examples from the previous section suggest, each of these steps has its own challenges.
引入思考:Exercise 11.2
- What challenges can you identify in NER, based on the examples from table 11.1?(前面那张表格)
Let’s look into these challenges together
full entity span identification
-
The first task that an NER algorithm solves is full entity span identification(span,跨度). As you can see in the examples from figure 11.2 and table 11.1, some entities consist of a single word, while others may span whole expressions, and it is not always trivial(容易解决的) to identify where an expression starts and where it finishes. For instance, does the full entity consist of Amazon or Amazon River? It would seem reasonable to select the longest sequence of words that are likely to constitute a single named entity. However, compare the following two sentences:
- Check out our [Amazon River]LOC maps selection.
- On [Amazon]ORG [River maps]PRODUCT from ABC Publishers are sold for
$5(If this sentence baffles(迷惑) you, try adding a comma(逗号), as in “On Amazon, River maps from ABC Publishers are sold for $5.”)
The first sentence contains a named entity of the type location (Amazon River). Even though the second sentence contains the same sequence of words, each of these two words actually belongs to a different named entity—Amazon is an organization, while River is part of a product name River maps.
ambiguity
-
The following examples illustrate one of the core reasons why natural language processing is challenging—ambiguity. You have seen some examples of sentences with ambiguous analysis before (e.g., when we discussed parsing and part-of-speech tagging in chapter 4).
-
For NER, ambiguity poses a number of challenges: one is related to span identification, as just demonstrated. Another one is related to the fact that the same words and phrases may or may not be named entities.
-
For some examples, consider the following pairs, where the first sentence in each pair contains a word used as a common, general noun, and the second sentence contains the same word being used as (part of) a named entity:
- “An apple a day keeps a doctor away” versus “Apple announces a new iPad Pro.”
- “Turkey is the main dish served at Thanksgiving” versus “Turkey is a country with amazing landscapes.”
- “The tiger is the largest living cat species” versus “Tiger Woods is an American professional golfer.”
Can you spot any characteristics distinguishing the two types of word usage (as a common noun versus as a named entity) that may help the algorithm distinguish between the two? Think about this question, and we will discuss the answer to it in the next section. (后面回头来看这个问题)
-
Ambiguity in NER poses a challenge, and not only when the algorithm needs to define whether a word or a phrase is a named entity or not. Even if a word or a phrase is identified to be a named entity, the same entity may belong to different NE types.
- For example, Amazon may refer to a location or a company, April may be a name of a person or a month, JFK may refer to a person or a facility, and so on.
So,an algorithm has to identify the span of a potential named entity and make sure the identified expression or word is indeed a named entity, since the same phrase or word may or may not be an NE, depending on the context of use. But even when it is established that an expression or a word is a named entity, this named entity may still belong to different types. How does the algorithm deal with these various levels of complexity?
-
First of all, a typical NER algorithm combines the span identification and the named entity type identification steps into a single, joint task.
-
Second, it approaches this task as a sequence labeling problem: specifically, it goes through the running text word by word and tries to decide whether a word is part of a specific type of a named entity. Figure 11.5 provides the mental model for this process.
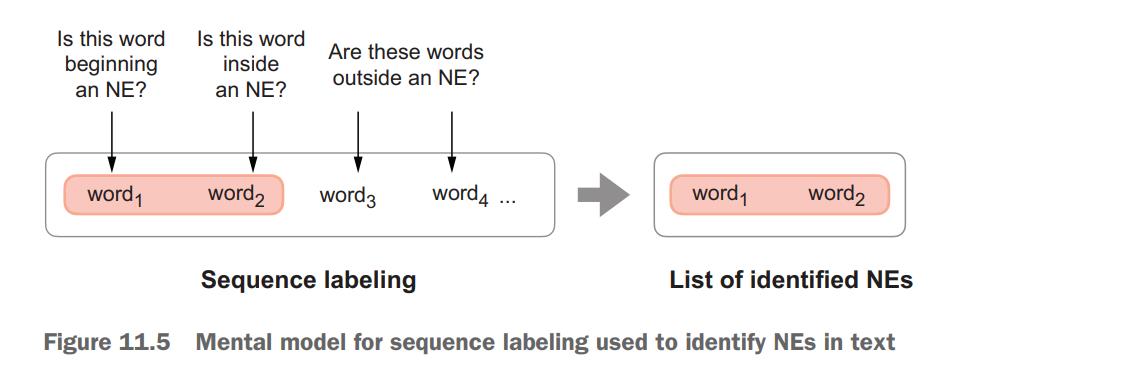
这里的mental model我感觉翻译为概念模型比较好? (或者思维导图也可以算是mental model)
A mental model is a simplified representation of a complex system or concept that we use to understand and reason about that system or concept. Mental models help us process and make sense of new information by allowing us to relate it to concepts and information that we already know. They also help us anticipate(预料) how a system or concept is likely to behave in the future based on our understanding of it.↳Mental models are often used in problem-solving and decision-making, as they allow us to evaluate different options and predict the likely outcomes of different courses of action. They are also an important component of learning and knowledge acquisition, as they help us organize and integrate new information into our existing understanding of the world.
- In fact, many tasks in NLP are framed as sequence labeling tasks, since language has a clear sequential nature. We have not looked into sequential tasks and sequence labeling in this book before, so let’s discuss this topic now.👇
11.2 Named-entity recognition as a sequence labeling task
Not surprisingly, named-entity recognition is addressed using machine-learning algorithms, which are capable of learning useful characteristics of the context. NER is typically addressed with supervised machine-learning algorithms, which means that such algorithms are trained on annotated data. To that end, let’s start with the questions of how the data should be labeled for sequential tasks, such as NER, in a way that the algorithm can benefit from the most.
11.2.1 The basics: BIO scheme
引例
看这个例子
“Inc.” is an abbreviation for “Incorporated.” It is a legal designation that is used by businesses to indicate that they are a corporation.

We said before that the way the NER algorithm identifies named entities and their types is by considering every word in sequence and deciding whether this word belongs to a named entity of a particular type.
For instance, in Apple Inc., the word Apple is at the beginning of a named entity of type ORG and Inc. is at its end. Explicitly annotating the beginning and the end of a named-entity expression and training the algorithm on such annotation helps it capture the information that if a word Apple is classified as beginning a named entity ORG, it is very likely that it will be followed by a word that finishes this named-entity expression.
The labeling scheme that is widely used for NER and similar sequence labeling tasks is called BIO scheme, since it comprises three types of tags: beginning, inside, and outside. We said that the goal of an NER algorithm is to jointly assign to every word its position in a named entity and its type, so in fact this scheme is expanded to accommodate for the type tags too.
For instance, there are tags B-PER and I-PER for the words beginning and inside of a named entity of the PER type; similarly, there are B-ORG, I-ORG, B-LOC, I-LOC tags, and so on.
O-tag is reserved for all words that are outside of any named entity, and for that reason, it does not have a type extension. Figure 11.6 shows the application of this scheme to the short example “tech giant Apple Inc.”
In total, there are 2n+1 tags for n named entity types plus a single O-tag: for the 18 NE types from the OntoNotes presented in table 11.1, this amounts to 37 tags in total.
further extensions:IO scheme 、 BIOES scheme
BIO scheme has two further extensions that you might encounter in practice: a less fine-grained IO scheme, which distinguishes between the inside and outside tags only, and a more fine-grained BIOES scheme, which also adds an end-of-entity tag for each type and a single-word entity for each type that consists of a single word. Table 11.2 illustrates the application of these annotation schemes to the beginning of our example.
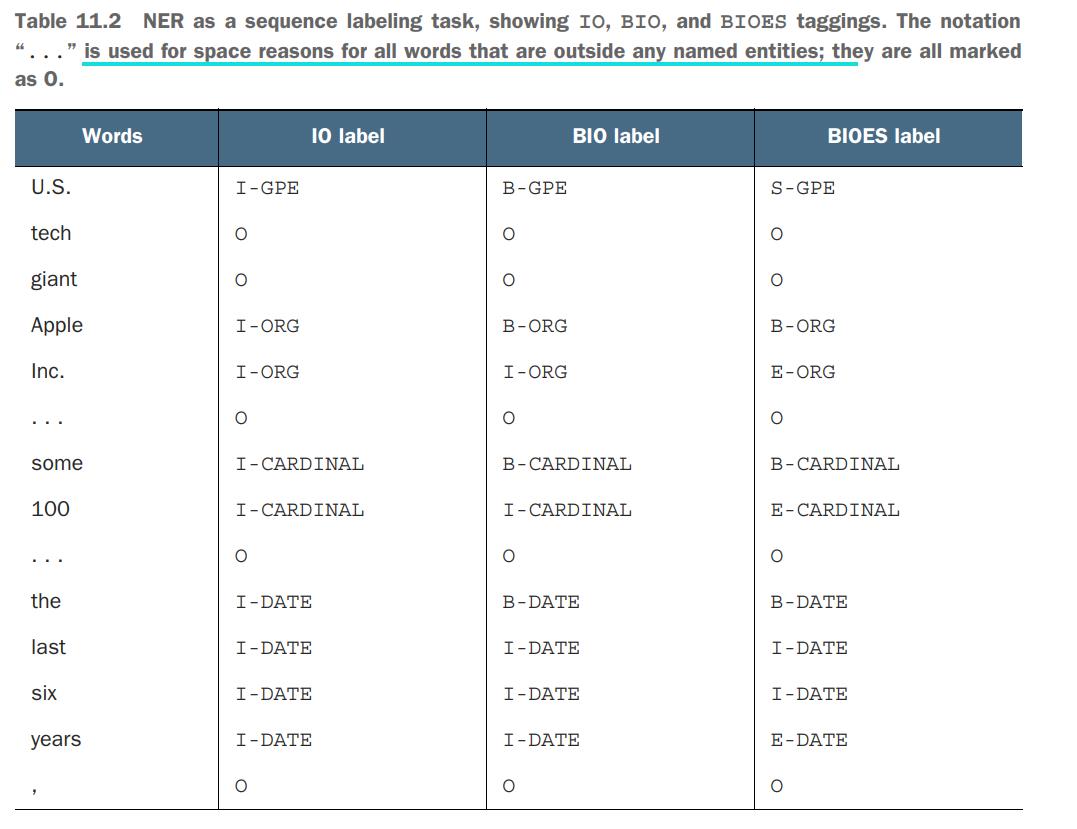
Exercise 11.3
- Table 11.2 doesn’t contain the annotation for the rest of the sentence. Provide the annotation for “the company’s CEO Tim Cook said” using the IO, BIO, and BIOES schemes.
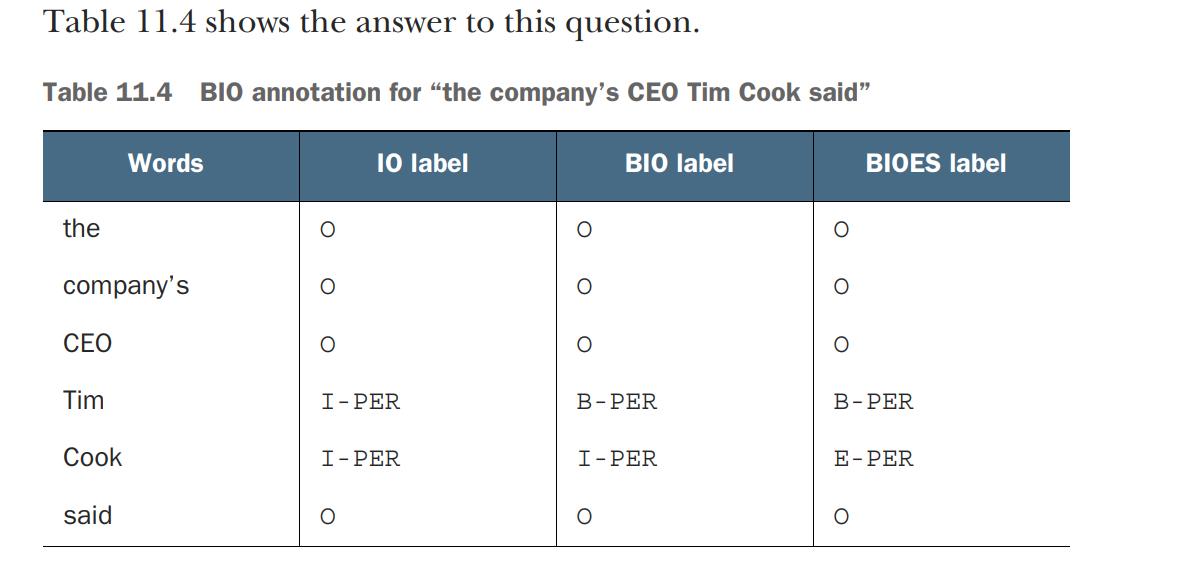
The IO, BIO, and BIOES schemes are all annotation schemes that are used to label the words in a text as part of natural language processing tasks, such as named entity recognition (NER). These schemes are used to create training data for machine learning models that are used to identify named entities in text.
The IO (Inside, Outside) scheme is a simple labeling scheme that consists of only two tags: I (Inside) and O (Outside). It is used to indicate whether a word is part of a named entity or not.
The BIO (Beginning, Inside, Outside) scheme is similar to the IO scheme, but it includes an additional tag for the beginning of a named entity. This scheme is often used to identify the boundaries of named entities in text.
The BIOES (Beginning, Inside, Outside, End, Single) scheme is an extension of the BIO scheme that includes additional tags for the end of a named entity and for named entities that consist of a single word. This scheme is used to more accurately identify the boundaries and types of named entities in text.
Exercise 11.4
- The complexity of a supervised machine-learning task depends on the number of classes to distinguish between. The BIO scheme consists of 37 tags for 18 entity types. How many tags are there in the IO and BIOES schemes?
- The IO scheme has one I-tag for each entity type plus a single O-tag for words outside any entity type. This results in n+1, or 19 tags for 18 entity types.
- The BIOES scheme has 4 tags for each entity type (B, I, E, S) plus one O-tag for words outside any entity type. This results in 4n+1, or 73 tags.
- The more detailed schemes provide for finer(更精细的) granularity(粒度) but also come at an expense of having more classes for the algorithm to distinguish between.
- While the BIO scheme allows the algorithm to train on 37 classes, the BIOES scheme has almost twice as many classes, which means the algorithm has to deal with higher complexity and may make more mistakes.
11.2.2 What does it mean for a task to be sequential?
-
Many real-word tasks show sequential nature.
-
作者举了俩例子
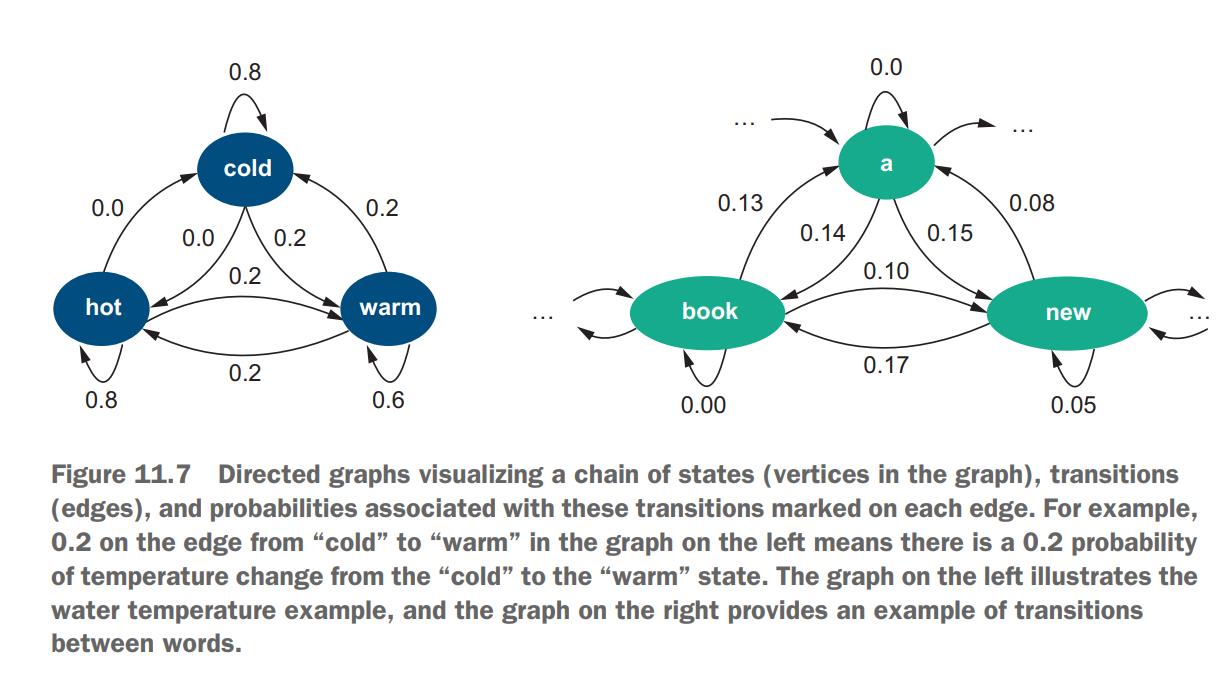
-
水的温度变化
-
As an illustrative example, let’s consider how the temperature of water changes with respect to various possible actions applied to it. Suppose water can stay in one of three states—cold, warm, or hot, as figure 11.7 (left) illustrates. You can apply different actions to it. For example, heat it up or let it cool down. Let’s call a change from one state to another a state transition. Suppose you start heating cold water up and measure water temperature at regular intervals, say, every minute. Most likely you would observe the following sequence of states: cold → . . . → cold → warm → . . . → warm → hot. In other words, to get to the “hot” state, you would first stay in the “cold” state for some time; then you would need to transition through the “warm” state, and finally you would reach the “hot” state. At the same time, it is physically impossible to transition from the “cold” to the “hot” state immediately, bypassing the “warm” state. The reverse is true as well: if you let water cool down, the most likely sequence will be hot → . . . → hot → warm → . . . → warm → cold, but not hot → cold
In fact, these types of observations can be formalized and expressed as probabilities. For example, to estimate how probable it is to transition from the “cold” state to the “warm” state, you use your timed measurements and calculate the proportion of times that the temperature transitioned cold → warm among all the observations made for the “cold” state:
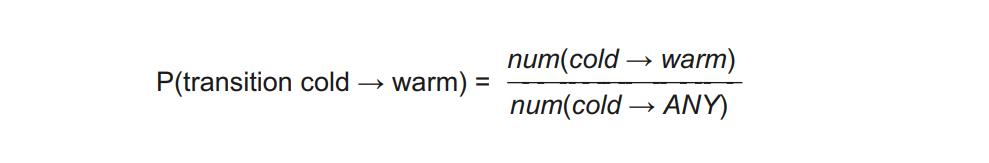
Such probabilities estimated from the data and observations simply reflect how often certain events occur compared to other events and all possible outcomes. Figure 11.7(left) shows the probabilities on the directed edges. The edges between hot → cold and cold → hot are marked with 0.0, reflecting that it is impossible for the temperature to change between “hot” and “cold” directly bypassing(绕过) the “warm” state. At the same time, you can see that the edges from the state back to itself are assigned with quite high probabilities: P(hot → hot) = 0.8 means that 80% of the time if water temperature is hot at this particular point in time it will still be hot at the next time step (e.g., in a minute). Similarly, 60% of the time water will be warm at the next time step if it is currently warm, and in 80% of the cases water will still be cold in a minute from now if it is currently cold.
Also note that this scheme describes the set of possibilities fully: suppose water is currently hot. What temperature will it be in a minute? Follow the arrows in figure 11.7 (left) and you will see that with a probability of 0.8 (or in 80% of the cases), it will still be hot and with a probability of 0.2 (i.e., in the other 20%), it will be warm.
What if it is currently warm? Then, with a probability of 0.6, it will still be warm in a minute, but there is a 20% chance that it will change to hot and a 20% chance that it will change to cold.
-
-
语句
-
Where do language tasks fit into this? As a matter of fact, language is a highly structured, sequential system. For instance, you can say “Albert Einstein was born in Ulm” or “In Ulm, Albert Einstein was born,” but “Was Ulm Einstein born Albert in” is definitely weird(怪异的) if not nonsensical(荒谬的,无稽之谈的) and can be understood only because we know what each word means and, thus, can still try to make sense of such word salad(词语混杂). At the same time, if you shuffle the words in other expressions like “Ann gave Bob a book,” you might end up not understanding what exactly is being said. In “A Bob book Ann gave,” who did what to whom? This shows that language has a specific structure to it and if this structure is violated, it is hard to make sense of the result. Figure 11.7 (right) shows a transition system for language, which follows a very similar strategy to the water temperature example from figure 11.7 (left).
It shows that if you see a word “a,” the next word may be “book” (“a book”) with a probability of 0.14, “new” (“a new house”) with a 15% chance, or some other word. If you see a word “new,” with a probability of 0.05, it may be followed by another “new” (“a new, new house”), with an 8% chance it may be followed by “a” (“no matter how new a car is, . . .”), in 17% of the cases it will be followed by “book” (“a new book”), and so on. Finally, if the word that you currently see is “book,” it will be followed by “a” (“book a flight”) 13% of the time, by “new” (“book new flights”) 10% of the time, or by some other word (note that in the language example, not all possible transitions are visualized in figure 11.7). Such predictions on the likely sequences of words are behind many NLP applications. For instance, word prediction is used in predictive keyboards, query completion, and so on. Note that in the examples presented in figure 11.7, the sequential models take into account a single previous state to predict the current state.
Technically, such models are called first-order Markov models or Markov chains .
马尔科夫模型或马尔科夫链
In a Markov chain, the probabilistic transitions between states are described by a transition matrix, which specifies the probability of transitioning from one state to another. The state of the system at any given time is called a Markov state, and the set of all possible states is called the state space. The behavior of the system over time is described by a sequence of random variables, called a Markov process.
It is also possible to take into account longer history of events.
For example, second-order Markov models look into two previous states to predict the current state and so on.
NLP models that do not observe word order and shuffle words freely (as in “A Bob book Ann gave”) are called bag-of-words models. The analogy(类比) is that when you put words in a “bag,” their relative order is lost, and they get mixed among themselves like individual items in a bag. A number of NLP tasks use bag-of-words models. The tasks that you worked on before made little if any use of the sequential nature of language. Sometimes the presence of individual words is informative enough for the algorithm to identify a class (e.g., lottery strongly suggests spam, amazing is a strong signal of a positive sentiment, and rugby has a strong association with the sports topic). Yet, as we have noted earlier in this chapter, for NER it might not be enough to just observe a word (is “Apple” a fruit or a company?) or even a combination of words (as in “Amazon River Maps”). More information needs to be extracted from the context and the way the previous words are labeled with NER tags. In the next section, you will look closely into how NER uses sequential information and how sequential information is encoded as features for the algorithm to make its decisions.
-
11.2.3 Sequential solution for NER
Just like water temperature cannot change from “cold” immediately to “hot” or vice versa without going through the state of being “warm,” and just like there are certain sequential rules to how words are put together in a sentence (with “a new book” being much more likely in English than “a book new”), there are certain sequential rules to be observed in NER.
For instance, if a certain word is labeled as beginning a particular type of an entity (e.g., B-GPE for “New” in “New York”), it cannot be directly followed by an NE tag denoting inside of an entity of another type (e.g., I-EVENT cannot be assigned to “York” in “New York” when “New” is already labeled as B-GPE, as I-GPE is the correct tag).
In contrast, I-EVENT is applicable to “Year” in “New Year” after “New” being tagged as B-EVENT. To make such decisions, an NER algorithm takes into account the context, the labels assigned to the previous words, and the current word and its properties.
Let’s consider two examples with somewhat similar contexts:
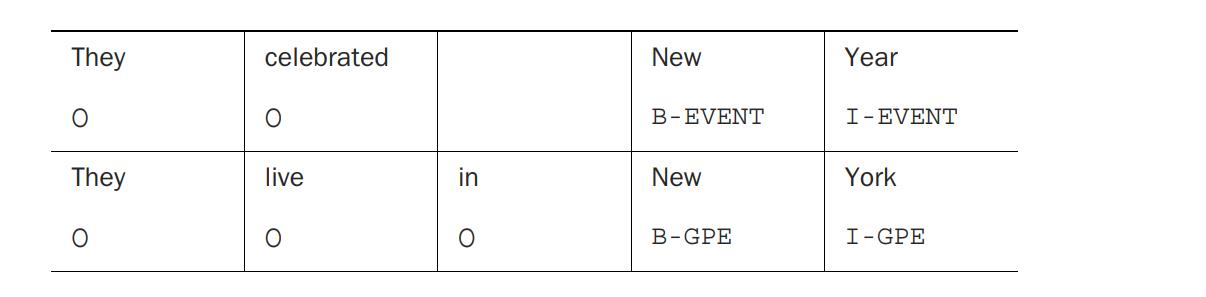
Your goal in the NER task is to assign the most likely sequence of tags to each sentence. Ideally, you would like to end up with the following labeling for the sentences: O – O – B-EVENT – I-EVENT for “They celebrated New Year” and O – O – O – B-GPE – I-GPE for “They live in New York.”
Figure 11.8 visualizes such “ideal” labeling for “They celebrated New Year” (using an abbreviation EVT for EVENT for space reasons
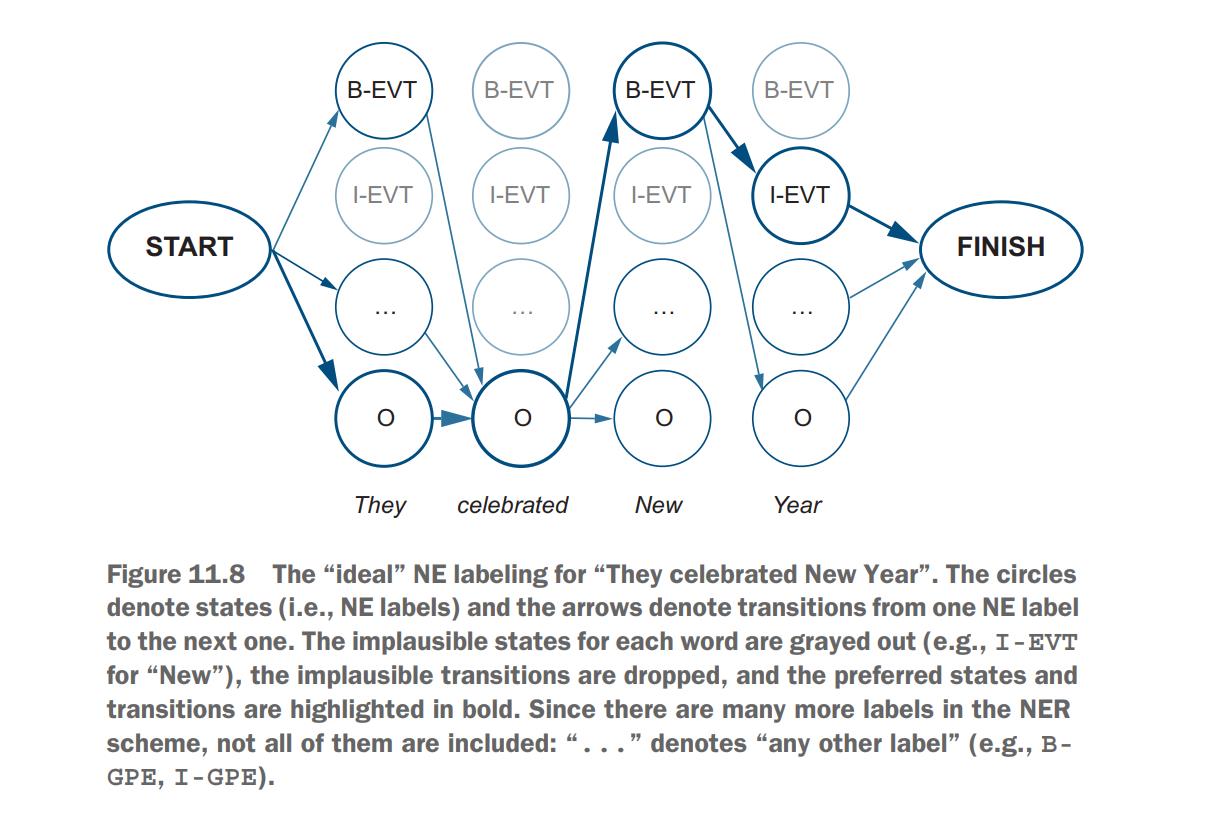
As figure 11.8 shows, it is possible to start a sentence with a word labeled as a beginning of some named entity, such as B-EVENT or B-EVT (as in “Christmas B-EVT is celebrated on December 25”).
However, it is not possible to start a sentence with I-EVT (the tag for inside the EVENT entity), which is why it is grayed out in figure 11.8 and there is no arrow connecting the beginning of the sentence (the START state) to I-EVT. Since the second word, “celebrated,” is a verb, it is unlikely that it belongs to any named entity type; therefore, the most likely tag for it is O.
“New” can be at the beginning of event (B-EVT as in “New Year”) or another entity type (e.g., B-GPE as in “New York”), or it can be a word used outside any entity (O).
Finally, the only two possible transitions after tag B-EVT are O (if an event is named with a single word, like “Christmas”) or I-EVT. All possible transitions are marked with arrows in figure 11.8; all impossible states are grayed out with the impossible transitions dropped (i.e., no connecting arrows); and the states and transitions highlighted in bold are the preferred ones.
As you can see, there are multiple sources of information that are taken into account here: word position in the sentence matters (tags of the types O and BENTITY—outside an entity and beginning an entity, respectively—can apply to the first word in a sentence, but I-ENTITY cannot); word characteristics matter (a verb like “celebrate” is unlikely to be part of any entity); the previous word and tag matter (if the previous tag is B-EVENT, the current tag is either I-EVENT or O); the word shape matters (capital N in “New” makes it a better candidate for being part of an entity, while the most likely tag for “new” is O); and so on.
This is, essentially(本质上), how the algorithm tries to assign the correct tag to each word in the sequence.
For instance, suppose you have assigned tags O – O – B-EVENT to the sequence “They celebrated New” and your current goal is to assign an NE tag to the word “Year”. The algorithm may consider a whole set of characteristic rules—let’s call them features by analogy(类比) with the features used by supervised machine-learning algorithms in other tasks. The features in NER can use any information related to the current NE tag and previous NE tags, current word and the preceding context, and the position of the word in the sentence.
Let’s define some feature templates for the features helping the algorithm predict that word 4 \\textword_4 word4 in “They celebrated New Year” (i.e., word 4 \\textword_4 word4=“Year”) should be assigned with the tag I-EVENT after the previous word “New” is assigned with B-EVENT. It is common to use the notation y i y_i yi for the current tag, y i − 1 y_i-1 yi−1 for the previous one, X X X for the input, and i i i for the position, so let’s use this notation in the feature templates

A gazetteer(地名录) (e.g., www.geonames.org) is a list of place names with millions of entries for locations, including detailed geographical and political
information. It is a very useful resource for identification of LOC, GPE, and
some other types of named entities.Word shape is determined as follows: capital letters are replaced with X, lowercase letters are replaced with x, numbers are replaced with d, and punctuation marks are preserved; for example, “U.S.A.” can be represented as “X.X.X.” and “11–12p.m.” as “d–dx.x.” This helps capture useful generalizable information.
Feature indexes used in this list are made up, and as you can see, the list of features grows quickly with the examples from the data. When applied to our example, the features will yield the following values:

It should be noted that no single feature is capable of correctly identifying an NE tag in all cases; moreover, some features may be more informative than others. What the algorithm does in practice is it weighs the contribution from each feature according to its informativeness and then it combines the values from all features, ranging from feature k = 1 k = 1 k=1 to feature k = K k = K k=K (where k k k is just an index), by summing the individual contributions as follows

The appropriate weights in this equation are learned from labeled data as is normally done for supervised machine-learning algorithms. As was pointed out earlier, the ultimate goal of the algorithm is to assign the correct tags to all words in the sequence, so the expression is actually applied to each word in sequence, from i = 1 i = 1 i=1 (i.e., the first word in the sentence) to i = n i = n i=n (the last word); that is
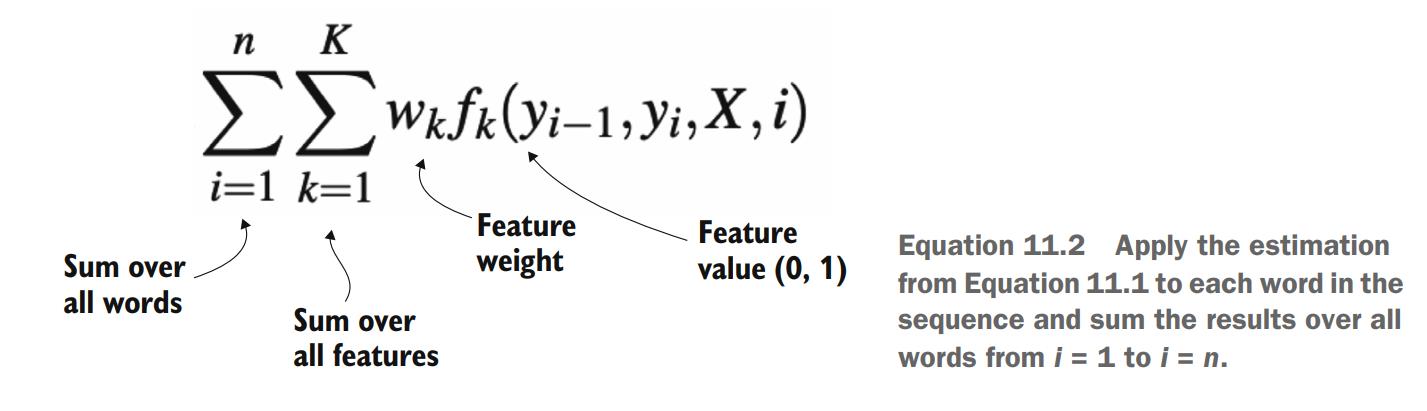
Specifically, this means that the algorithm is not only concerned with the correct assignment of the tag I-EVENT to “Year” in “They celebrated New Year”, but also with the correct assignment of the whole sequence of tags O – O – B-EVENT – I-EVENT to “They celebrated New Year”.
However, originally, the algorithm knows nothing about the correct tag for “They” and the correct tag for “celebrated” following “They”, and so on. Since originally the algorithm doesn’t know about the correct tags for the previous words, it actually considers all possible tags for the first word, then all possible tags for the second word, and so on. In other words, for the first word, it considers whether “They” can be tagged as B-EVENT, I-EVENT, B-GPE, I-GPE, . . . , O, as figure 11.8 demonstrated earlier; then for each tag applied to “They”, the algorithm moves on and considers whether “celebrated” can be tagged as B-EVENT, I-EVENT, B-GPE, I-GPE, . . . , O; and so on.
In the end, the result you are interested in is the sequence of all NE tags for all words that is most probable; that is
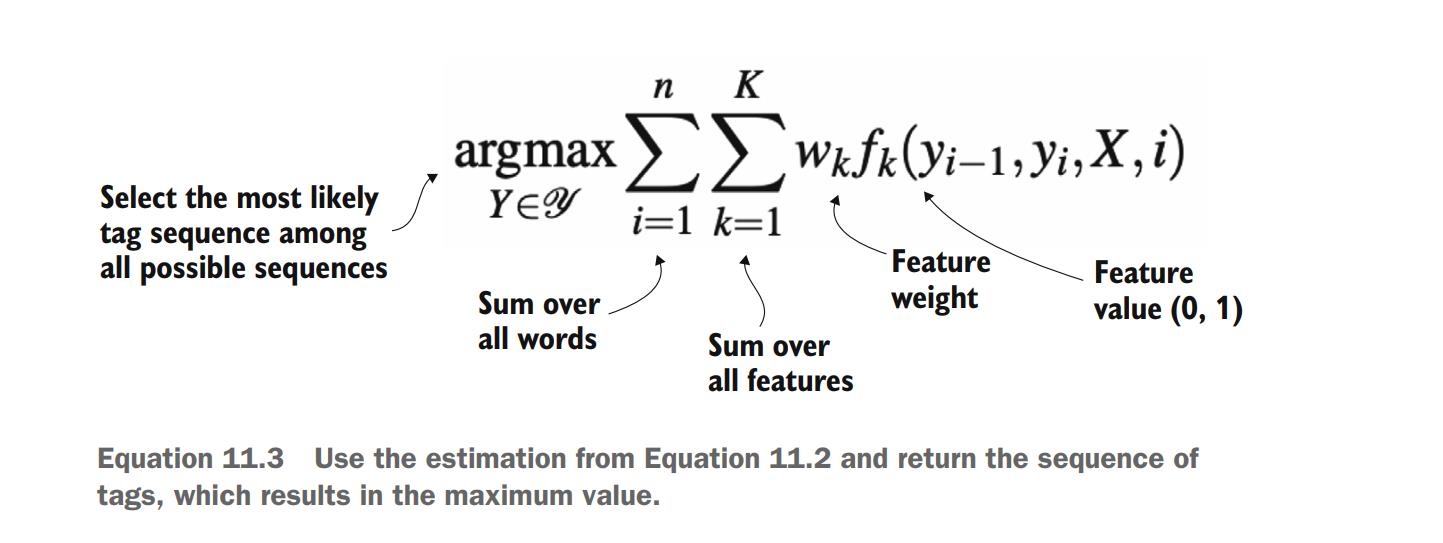
The formula in Equation 11.3 is exactly the same as the one in Equation 11.2, with just one modification: argmax means that you are looking for the sequence that results in the highest probability estimated by the rest of the formula; Y Y Y stands for the whole sequence of tags for all words in the input sentence; and the fancy font(花体字) Y Y Y denotes the full set of possible combinations of tags.
Recall the three BIO-style schemes introduced earlier in this chapter: the most coarse-grained(粗粒度) IO scheme has 19 tags, which means that the total number of possible tag combinations for the sentence “They celebrated New Year”, consisting of 4 words, is 1 9 4 = 130 , 321 19^4 =130,321 194=130,321; the middle-range BIO scheme contains 37 distinct tags and results in 3 7 4 = 1 , 874 , 161 37^4 =1,874,161 374=1,874,161 possible combinations; and finally, the most fine-grained BIOES scheme results in 7 3 4 = 28 , 398 , 241 73^4 =28,398,241 734=28,398,241 possible tag combinations for a sentence consisting of 4 words.
Note that a sentence consisting of 4 words is a relatively short sentence, yet the brute-force(蛮力法) algorithm (i.e., the one that simply iterates through each possible combination at each step) rapidly becomes highly inefficient. After all, some tag combinations (like O → I-EVENT) are impossible, so there is no point in wasting effort on even considering them. In practice, instead of a brute-force algorithm, more efficient algorithms based on dynamic programming(动态规划) are used (the algorithm that is widely used for language-related sequence labeling tasks is the Viterbi algorithm;
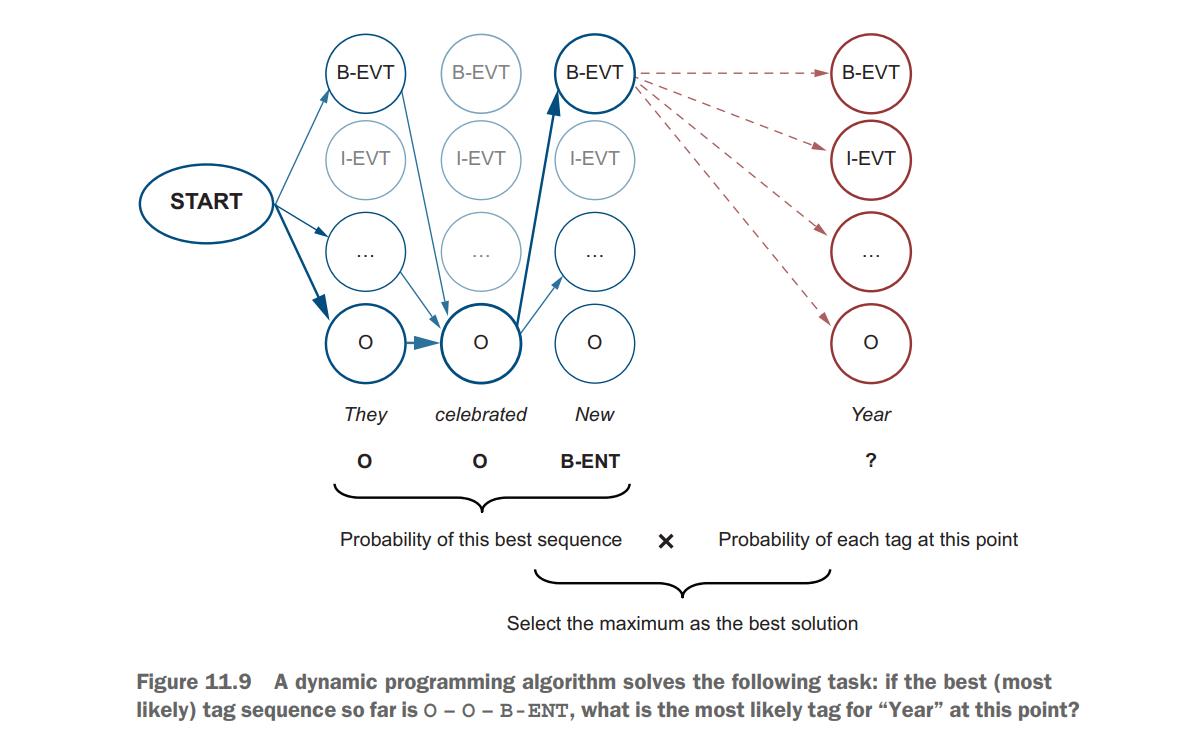
Instead of exhaustively(彻底地) considering all possible combinations, at each step a dynamic programming algorithm calculates the probability of all possible solutions given only the best, most optimal (最优的)solution for the previous step. The algorithm then calculates the best move at the current point and stores it as the current best solution. When it moves to the next step, it again considers only this best solution rather than all possible solutions, thus considerably(大幅度地) reducing the number of overall possibilities to only the most promising ones. Figure 11.9 demonstrates the intuition behind dynamic estimation of the best NE tag that should be selected for “Year” given that the optimal solution O – O – B-EVENT is found for “They celebrated New”.
This, in a nutshell, is how a sequence labeling algorithm solves the task of tag assignment. As was highlighted before, NER is not the only task that demonstrates sequential effects, and a number of other tasks in NLP are solved this way.
The approach to sequence labeling outlined in this section is used by machine-learning algorithms, most notably, conditional random fields, although you don’t need to implement your own NER to be able to benefit from the results of this step in the NLP pipeline. For instance, spaCy has an NER implementation that you are going to rely on to solve the task set out in the scenario for this chapter. The next section delves(探索;深入寻找,搜寻) into implementation (实现)details.
Conditional random fields (CRFs) are a type of probabilistic graphical model used for modeling and predicting structured data, such as sequences or sets of interconnected items. Like other graphical models, CRFs use a graph structure to represent the relationships between different variables and their dependencies. However, unlike many other graphical models, CRFs are specifically designed to handle structured data and make use of the relationships between variables to improve prediction accuracy.
条件随机场 (CRF) 是一种概率图模型,用于建模和预测结构化数据,例如序列或相互关联的项目集。 与其他图形模型一样,CRF 使用图形结构来表示不同变量之间的关系及其依赖关系。 然而,与许多其他图形模型不同,CRF 专门设计用于处理结构化数据并利用变量之间的关系来提高预测准确性。
CRFs are often used in natural language processing tasks, such as part-of-speech tagging and named entity recognition, where the input data consists of a sequence of words or other tokens and the output is a sequence of tags or labels. CRFs can also be applied to other types of structured data, such as biological sequences, and have been used in a variety of other applications, including image segmentation and handwritten character recognition.
CRFs are related to other probabilistic models, such as hidden Markov models and Markov random fields, and can be trained using a variety of algorithms, including gradient descent and the Expectation-Maximization (EM) algorithm.
11.3 Practical applications of NER
作者还是带我们回到了开头说的那个股票的例子
Let’s remind ourselves of the scenario for this chapter. It is widely known that certain events influence the trends of stock price movements. Specifically, you can extract relevant facts from the news and then use these facts to predict company stock prices.
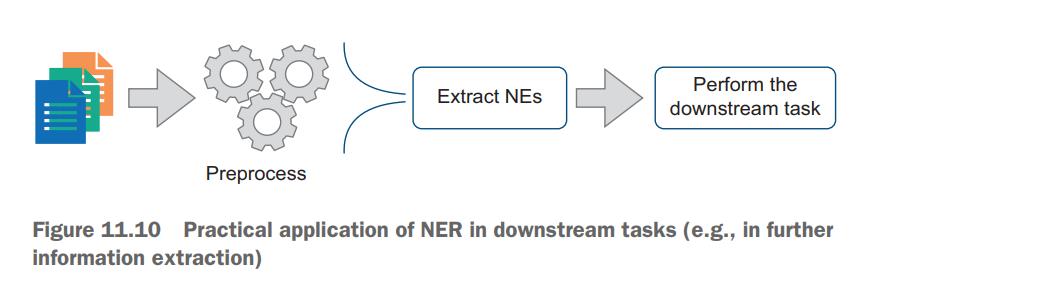
Suppose you have access to a large collection of news; now your task is to extract the relevant events and facts that can be linked to the stock market in the downstream (stock market price prediction) application. How will you do that? This means that you have access to a collection of news texts, and among other preprocessing steps, you apply NER. Then you can focus only on the texts and sentences that are relevant for your task.
For instance, if you are interested in the recent events, in which a particular company (e.g., “Apple”) participated, you can easily identify such texts, sentences, and contexts. Figure 11.10 shows a flow diagram for this process.
11.3.1 Data loading and exploration
-
数据集是用的Kaggle的这个数据集:All the news | Kaggle
-
The dataset consists of 143,000 articles scraped from 15 news websites, including the New York Times, CNN, Business Insider, Washington Post, and so on.
-
The dataset is quite big and is split into three comma-separated values (CSV) files. In the examples in this chapter, you are going to be working with the file called articles1.csv, but you are free to use other files in your own experiments.
csv
Comma-separated values (CSV) is a simple file format used to store tabular(表格式的) data, such as a spreadsheet or database. A CSV file stores data in plain text, with each line representing a row of the table and each field (column) within that row separated by a comma.
Many datasets available via Kaggle and similar platforms are stored in the .csv format. This basically means that the data is stored as a big spreadsheet(电子表格) file, where information is split between different rows and columns. For instance, in articles1.csv,
each row represents a single news article, described with a set of columns containing
information on its title, author, the source website, the date of publication, its full content, and so on. The separator(分隔符) used to define the boundary between the information
belonging to different data fields in .csv files is a comma. It’s time now to familiarize
yourselves with pandas, a useful data-preprocessing toolkit that helps you work with
files in such formats as .csv and easily extract information from them.
-
extract the data from the input file using pandas
import pandas as pd
path = <以上是关于《Getting Started with NLP》chap11:Named-entity recognition的主要内容,如果未能解决你的问题,请参考以下文章