Hadoop3 - HDFS 介绍及 Shell Cli 操作
Posted 小毕超
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop3 - HDFS 介绍及 Shell Cli 操作相关的知识,希望对你有一定的参考价值。
一、HDFS
上篇文章搭建了 Hadoop 集群,包含 HDFS 集群和 YARN 集群,本篇文章针对 HDFS 进行详细讲解与使用,下面是上篇文章的地址:
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目,它的设计初衷是为了能够支持高吞吐和超大文件读写操作,能够在普通硬件上运行的分布式文件系统,高度容错,适应于具有大数据集的应用程序,非常适于存储大型数据 (比如 TB 和 PB),HDFS使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统。
HDFS 适合的应用场景:
- 存储大文件,这里非常大指的是几百M、G、或者TB级别,需要高吞吐量,对延时没有要求。
- 基于流的数据访问方式一次写入、多次读取,数据集经常从数据源生成或者拷贝一次,然后在其上做很多分析工作 ,且不支持文件的随机修改。
- 适合用来做大数据分析的底层存储服务,并不适合用来做网盘等应用,因为,修改不方便,延迟大,网络开销大,成本太高。
- 不需要特别贵的机器,可运行于普通廉价机器,节约成本
- 需要高容错性
- 为数据存储提供所需的扩展能力
不适合的应用场景:
- 低延时的数据访问 对延时要求在毫秒级别的应用,不适合采用HDFS。HDFS是为高吞吐数据传输设计的,因此可能牺牲延时
- 大量小文件的元数据保存在NameNode的内存中, 整个文件系统的文件数量会受限于NameNode的内存大小。 经验而言,一个文件/目录/文件块一般占有150字节的元数据内存空间。如果有100万个文件,每个文件占用1个文件块,则需要大约300M的内存。因此十亿级别的文件数量在现有商用机器上难以支持
- 多方读写,需要任意的文件修改 HDFS采用追加(append-only)的方式写入数据。不支持文件任意offset的修改,HDFS适合用来做大数据分析的底层存储服务,并不适合用来做.网盘等应用,因为,修改不方便,延迟大,网络开销大,成本太高。
HDFS的架构:
HDFS 采用 master/slave架构。一般一个HDFS集群是有一个Namenode和一定数目的Datanode组成。Namenode是HDFS主节点,Datanode是HDFS从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。
其中 Datanode 主要负责实际的存储,而 Namenode 则负责存储一些元数据,如:
文件自身属性信息(文件名称、权限,修改时间,文件大小,复制因子,数据块大小)、文件块位置映射信息(记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上)
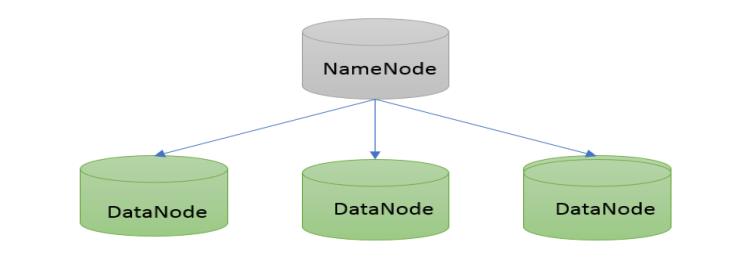
HDFS 中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定,参数位于hdfs-default.xml中:dfs.blocksize。默认大小是128M(134217728)。假如上传了一个 200M 的文件,则会分成 128M、72M 两个文件,存储在不同的 DataNode 节点上。
为了容错,文件的所有block都会有副本。每个文件的block大小(dfs.blocksize)和副本系数(dfs.replication)都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。默认dfs.replication的值是3,也就是会额外再复制2份,连同本身总共3份副本。
Namespace :
HDFS支持传统的层次型文件组织结构。用户可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
Namenode负责维护文件系统的namespace名称空间,任何对文件系统名称空间或属性的修改都将被Namenode记录下来。
HDFS会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/test1/text.txt。
下面通过 HDFS Shell 客户端对 HDFS 进行操作,请确保已经安装好 Hadoop 环境。
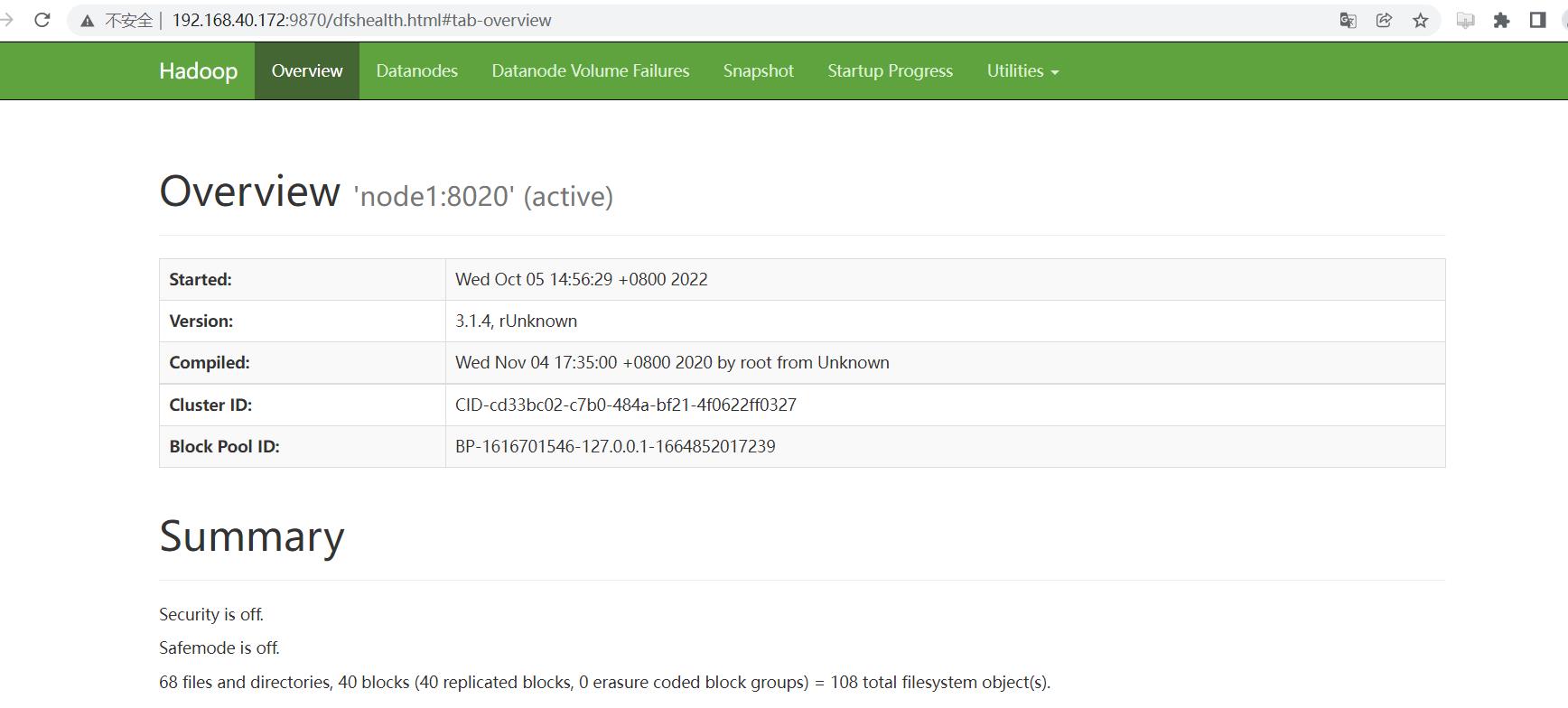
二、Shell Cli 操作
Hadoop提供了文件系统的shell命令行客户端,使用方法如下:
hdfs [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS] SUBCOMMAND:Admin Commands、Client Commands、Daemon Commands。
HDFS Shell CLI支持操作多种文件系统,包括本地文件系统(file:///)、分布式文件系统(hdfs://nn:8020)等,操作的是什么文件系统取决于URL中的前缀协议。如果没有指定前缀,则将会读取环境变量中的fs.defaultFS属性,以该属性值作为默认文件系统。
hadoop dfs、hdfs dfs、 hadoop fs 三者区别:
hadoop dfs只能操作HDFS文件系统(包括与Local FS间的操作),不过已经Deprecatedhdfs dfs只能操作HDFS文件系统相关(包括与Local FS间的操作),常用hadoop fs可操作任意文件系统,不仅仅是hdfs文件系统,使用范围更广
官方文档地址:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/FileSystemShell.html
下面我们使用 hadoop fs 进行演示:
hadoop fs -ls [-h] [-R] [<path> ...]
path 指定目录路径
-h 人性化显示文件size
-R 递归查看指定目录及其子目录
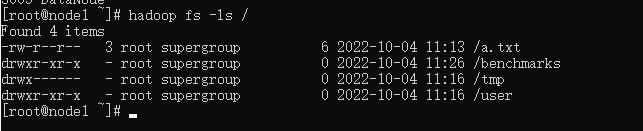
hadoop fs -ls /
hadoop fs -mkdir [-p] <path> ...
path 为待创建的目录
-p选项的行为与Unix mkdir -p非常相似,它会沿着路径创建父目录。
hadoop fs -mkdir -p /had/test/

hadoop fs -put [-f] [-p] <localsrc> ... <dst>
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限。
localsrc 本地文件系统(客户端所在机器)
dst 目标文件系统(HDFS)
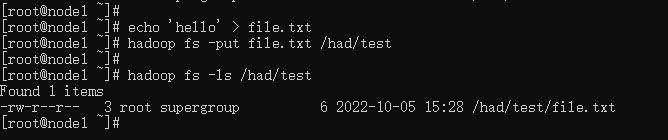
echo 'hello' > file.txt
hadoop fs -put file.txt /had/test
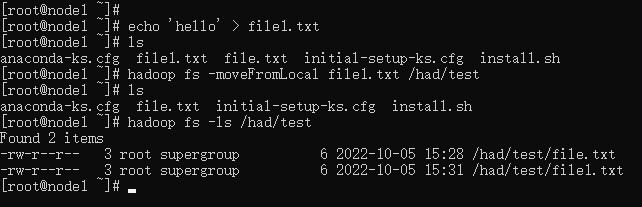
hadoop fs -moveFromLocal <localsrc> ... <dst>
echo 'hello' > file1.txt
hadoop fs -moveFromLocal file1.txt /had/test
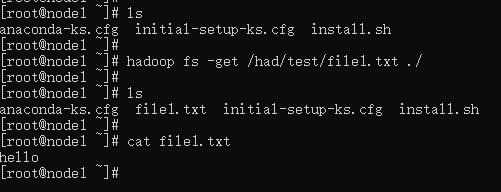
hadoop fs -get [-f] [-p] <src> ... <localdst>
下载文件到本地文件系统指定目录,localdst必须是目录
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限
hadoop fs -get /had/test/file1.txt ./
hadoop fs -cat <src> ...
读取指定文件全部内容,显示在标准输出控制台。
注意:对于大文件内容读取,慎重。
hadoop fs -cat /had/test/file.txt

hadoop fs -head <file>
hadoop fs -head /had/test/file.txt

hadoop fs -tail [-f] <file>
-f 同 linux 一至可以动态显示文件中追加的内容。
hadoop fs -tail /had/test/file.txt

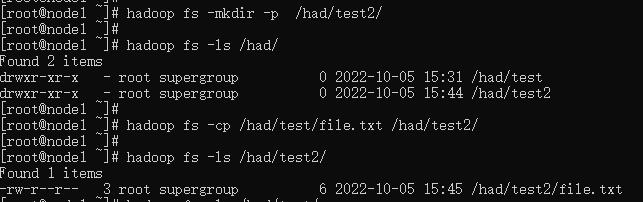
hadoop fs -cp [-f] <src> ... <dst>
-f 覆盖目标文件(已存在下)
hadoop fs -mkdir -p /had/test2/
hadoop fs -cp /had/test/file.txt /had/test2/
hadoop fs -appendToFile <localsrc> ... <dst>
将所有给定本地文件的内容追加到给定dst文件。
dst如果文件不存在,将创建该文件。
如果<localSrc>为-,则输入为从标准输入中读取。
echo 'abcd' > appent.txt
hadoop fs -appendToFile appent.txt /had/test/file.txt
hadoop fs -df [-h] [<path> ...]
显示文件系统的容量,可用空间和已用空间
hadoop fs -df -h /

hadoop fs -du [-s] [-h] <path> ...
-s:表示显示指定路径文件长度的汇总摘要,而不是单个文件的摘要。
-h:选项将以“人类可读”的方式格式化文件大小
hadoop fs -du -s -h /had/

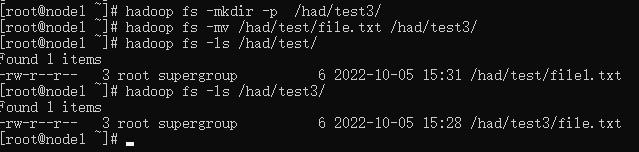
hadoop fs -mv <src> ... <dst>
移动文件到指定文件夹下
可以使用该命令移动数据,重命名文件的名称
hadoop fs -mkdir -p /had/test3/
hadoop fs -mv /had/test/file.txt /had/test3/
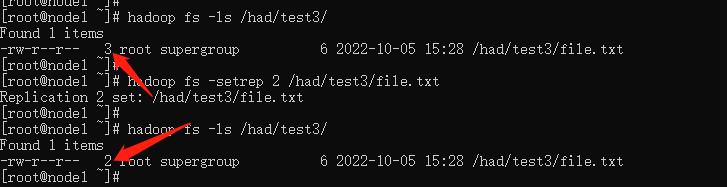
hadoop fs -setrep [-R] [-w] <rep> <path> ...
修改指定文件的副本个数。
-R表示递归 修改文件夹下及其所有
-w 客户端是否等待副本修改完毕。
hadoop fs -setrep 2 /had/test3/file.txt
以上是关于Hadoop3 - HDFS 介绍及 Shell Cli 操作的主要内容,如果未能解决你的问题,请参考以下文章