Git 以及 Vim 常见命令整理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Git 以及 Vim 常见命令整理相关的知识,希望对你有一定的参考价值。
参考技术A 除了以上列出的常用的命令外,下面着重结合场景来说明一下 git rebase 命令同个功能因一些原因打断开发,且并没有开发完成,此时可能会先提交一个备份的 commit ,为了提交简洁,需要将备份的提交合并到一起。此时就会用到 git rebase -i 命令
然后我们执行
有时我们同一个版本会有多个分支同时开发,如果采用pull + merge的方式会产生多余的提交记录影响。此时我们依然可以采用git rebase。
Linux开发工具vim以及git的使用详解
Linux开发工具
文章目录
vim是一款编辑器,平时大家是怎么编写代码的呢?怎么编译代码呢?debug代码呢?vim可以满足多种应用场景,它类似于windows下的集成开发工具vs2019
Linux当中是用vim编辑器来编写代码的,gcc/g++编译器用来编译代码,gdb调试器用来调试代码,这些都是独立的工具,而windows下的vs2019是集成开发工具
vim的基本概念与操作
vim是什么呢?文件编辑器,可以用来编写代码
那么怎么使用vim呢?
vim test.c
即便test.c不存在,他也会打开,这里就可以写代码了
一般建议先创建文件然后再vim打开文件,因为一般再写项目时,我们需要先有一个整体的框架,然后才写代码的
- vim是一个多模式的编辑器
默认打开文件是处在命令模式,在默认打开一个文件时,我们是不能进行写的,因为此时你输入的都是命令
- vim的模式
命令模式(vim默认打开是命令模式)
插入(编辑)模式
底行模式
- 命令模式进入到插入模式
i(光标不变),a(光标移到同行下一个位置),o(光标到新起一行)
- 插入模式回到命令模式
按esc键就直接回到命令模式了
- 进入底行模式
需要从命令模式进入,输入shift加:,然后输入w是保存,输入q是退出,输入wq是保存并退出
w!强制保存;!q强制退出;!wq强制保存退出
那么插入模式怎么进入底行呢?底行如何进入命令呢?底行如何进入插入呢?
任何模式回到命令模式,都可以按esc,插入模式进入底行模式,首先需要回到命令模式(esc),然后shift+:就可以了;底行模式进入命令模式:按esc就直接回到命令模式;底行模式进入插入模式:按esc进入命令模式,然后aio进入插入模式
命令模式常见命令
复制与粘贴
yy与p以及np
yy:复制当前行
p:粘贴,光标在哪里就粘贴到下一行
np:n代表想要粘贴n次
将光标放在所要复制的该行,然后输入yy,此时已经复制了,光标放在想要粘贴到的行数的前一行,然后再输入p就粘贴了;光标在哪里,就粘贴在光标所在行的下一行
上面是复制行,那么有没有多行复制的命令呢?有的:
nyy:n代表从光标开始想要复制几行
那么我们误复制粘贴了怎么办?
u:撤销上次动作
ctrl+r
撤销刚刚的撤销,相当于是反撤销
dd:删除光标所在行,其实功能更像剪切
ndd:删除光标所在行开始的n行内容
文本修改替换删除
r,nr:一次批量化的从光标开始连续修改内容
shift+r:进入替换模式,整体文本替换
esc回到命令模式
shift + ~:批量化进行大小写转化
x,nx:删除光标所在文本的内容,从左到右
shift+x:删除光标所在文本的内容,从右到左
切换到插入模式三种方式:
a:光标向后移动
i:不动
o:新起一行
cw:更改光标所在处的字到字尾处
c#w:例如,c3w表示更改3个字跳至指定的行ctrl+g列出光标所在行的行号。
#G:例如,15G,表示移动光标至文章的第15行行首。
光标定位
h,j,k,l:左,下,上,右
为什么我们的键盘有上下左右键还用hjkl这样的按键呢?因为早期的键盘是没有上下左右键的,
历史用hjkl,我们现在需要兼容历史,说不定一些研究所啥的还是需要用到这些历史的东西,所以仍然需要用hjkl
记忆:h(最左边),j(jump跳楼),k(king高高在上),l(最右边)
w:以单词为单位进行后移
b:以单词为单位进行前移
nb,nw:按照n个单词进行前移或者后移
shift+4($):将光标定位到当前行的最结尾
shift+6(^):将光标定位到当前行的最开始
gg:直接将光标定位到文件的最开始
shift+g:直接将光标定位到文件的最后
n+shift+g:将光标定位到任意第n行
底行模式常见命令
批量化替换

:w
保存
:q
退出
:wq
保存并退出
以上命令全部加!:
强制保存,强制退出,强制保存并退出
!+命令
底行进行命令操作,可以在vim里面写命令
/文本
搜索/后面的文本,搜索到后按n就是不断选择下一个

?文本
搜索?后面的文本,搜索到后按n就是不断选择下一个

set nu/nonu
调出行号或者取消行号
vs 文件名
分屏操作文件,光标在哪里,我们呢就编辑那个文件

多文件光标切换
ctrl+w,再按h或者l
ctrl+快速两次w
补充内容:
vim 文件名 +n

进入文件光标定位在第n行,如果你在编译你的代码时,出错了,然后告诉你出错在第几行,此时你就可以直接今天文件将光标定位在出错附vim近

!vim
执行vim上次的命令
我们现在知道一种保存退出vim编辑器的方法::wq,还有另外一种方法:
shift+zz
保存退出
vim配置
vim配置文件位置
我们配置vim需要在一个.vimrc的文件里配置,而在每个用户的主目录下,都可以自己建立私有的配置文件,命名为:“.vimrc”。例如,/root目录下,通常已经存在一个.vimrc文件,如果不存在,则创建之。
vim的环境设置参数
| 环境设置参数 | 功能 |
|---|---|
| :set nonu | 取消行号 |
| :set nu | 设置行号 |
| :set hlsearch | hlsearch就是high light search(高亮度查找),设置将查找的字符串反白的设置值 |
| :set nohlsearch | 不设置hlsearch |
| :set autoindent | 设置自动缩进 |
| :set noautoindent | 不设置自动缩进 |
| :set backup | 自动保存备份文件 |
| :set showmode | 这个是是否要显示–INSERT–之类的字眼在左下角的状态栏 |
| :set all | 显示目前所有的环境参数设置值 |
| :set bg=dark | 可用以显示不同的颜色色调,默认是light,dark是黑色环境 |
关于环境设置参数还有很多,这里就不一一说明了。
Linux编译器-gcc/g++使用

- 预处理:1、头文件展开 2、宏替换 3、条件编译 4、去注释
- 编译:将C语言转换为汇编语言
- 汇编:汇编语言转换为目标文件(.o,二进制)
- 链接:形成可执行程序
预处理
gcc -E test.c -o test.i
预处理阶段完成头文件的展开、宏的替换、条件编译以及去除注释,选项-E是指预处理完成后停止(生成.i文件),不进行编译,-o选项是将生成的文件输出到test.i文件中
编译
gcc -S test.c -o test.s
在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言。而-S选项的意思就是编译完成后停止(生成.s文件),不进行汇编
汇编
gcc -c test.c -o test.o
汇编阶段是把编译阶段生成的“.s”文件转成目标文件,-c选项就可以看到生成的目标文件
链接
gcc test.o -o myexe
在编译阶段过后,就来到了链接阶段,gcc不带选项就是前面的这些工作依次完成,然后再进行链接生成可执行程序
gcc常见选项:
| 选项 | 功能 |
|---|---|
| -E | 预处理完成后停止(生成.i文件),不进行编译 |
| -S | 编译完成后停止(生成.s文件),不进行汇编 |
| -c | 汇编完成后停止(生成目标文件.o文件),不进行链接 |
| -o | 用于指定目标文件名称 |
| -g | 生成debug程序,向程序中添加调试符号信息 |
| -w | 不生成任何警告信息 |
| -Wall | 生成所有警告信息 |
| -static | 此选项对生成的文件采用静态链接-g 生成调试信息。GNU 调试器可利用该信息。 |
| -shared | 此选项将尽量使用动态库,所以生成文件比较小,但是需要系统有动态库 |
| -I | 用来指定头文件所在的路径 |
动态链接和静态链接
链接分为动态链接和静态链接
动态链接:
#include<stdio.h>
#define M 100
int main()
int i = 0;
int sum = 0;
for(;i<10;i++)
sum+=i;
printf("sum=%d\\n",sum);
while(i>0)
i--;
return 0;
比如我们写了这么一段代码,求完一到十的累加后,去库里面去找printf函数使用printf函数,使用完之后继续进行我们下面写的代码,我们生成的可执行程序只包含我们自己写的代码以及我们要使用的外部函数的链接,这就是动态链接。
静态链接:
对于上面的代码,我们使用printf函数需要去外部的库里面去找,而静态链接相当于就是将printf函数的代码拷贝到我们的代码里面使用,就不用去外部库里面找了
静态链接本质就算将相关库中的代码拷贝到自己的可执行程序里面
查看可执行程序的信息:
ldd 可执行程序名称
用于打印程序或者库文件所依赖的共享库列表。
file 可执行程序名称
file命令用于辨识文件类型。通过file指令,我们得以辨识该文件的类型。
.so:动态库


.a:静态库
g++ -static test.cpp -o test_static
-static表面它是静态链接

可以看到他变成了静态链接
静态链接缺点是生成的代码体积大,但是稳定;动态链接优点是生成的代码体积小,但是它依赖第三方库,如果第三方库找不到了,它就会发生错误,我们查看可执行程序文件的属性:

可以看到使用动态链接的可执行程序大小比使用静态链接的可执行程序大小要小、
有一个问题:
在编译阶段为什么不直接把C语言代码直接变成二进制代码呢?而是先将C语言代码变成汇编语言,然后将汇编语言变成二进制代码呢?
最早期人们编程是电路开关,01指代,再往后就有了汇编语言,从开始有了汇编以后,计算机就有了编译器这个概念,没有C语言时,只有汇编语言和汇编语言编译器时,那时是汇编语言可以直接会翻译成二进制代码,在有了C语言时,把C语言变成二进制代码要比汇编语言变成二进制成本要高的多,为什么呢?因为C语言是接近于人的自然语言,如果直接把这个语言翻译成二进制,翻译成本是非常高的,所以我们只需要将C语言翻译成汇编语言,而汇编语言翻译成二进制代码这部分工作前人已经帮我们做过了,我们不需要做这部分工作,所以我们只需要管将C语言转换为汇编语言即可,成本大大降低,所以就遵守了这个规则,就有了去注释、编译、汇编、链接
Linux几乎可以直接在命令行中执行大部分后端语言:python,java等等,都可以在Linux当中写代码
gdb的使用
gdb是什么?相当于linux中的调试器
背景
程序的发布方式有两种,debug模式和release模式,Linux gcc/g++出来的二进制程序,默认是release模式,不能调试。
在Linux中,程序默认编译的时候采用动态链接,使用动态库,默认生成的可执行程序是:release版本的!是不可被调试的,需要调试:选项-g 表示发布程序以debug方式才可以被gdb调试:
gcc test.c -o test_debug -g
debug和realease
-
一个可以调试,一个不可以
-
debug在生成程序的时候,会加入调试信息,而release不会

readelf用来显示一个或者多个elf格式的目标文件的信息,这里我们用readelf来显示一下debug版本的可执行程序和release版本的可执行程序,我们发现debug版本中有调试信息,而release版本中没有调试信息
在软件开发中,真正的用户是不需要进行调试的,它们只需要使用软件,所以用户用的版本就不应该将调试信息带进去,而程序员就需要进行调试,所以在程序员端有两种模式:debug版本和release版本
编译器编译程序的时候为什么会有debug和release?
我们简谈一下做项目的过程来解释:
首先是公司的管理者进行立项、然后进行组团队(通常团队里需要有程序员、产品经理、测试人员)、产品经理进行调研需求,沟通需求,设计产品的原型,然后工程师团队进行实现(开发过程),然后进行debug自测过程,发现没问题了,然后进行提测(将realease版本交给测试团队),测试团队进行测试,找出问题就会和研发人员进行问题沟通,然后工程师团队再进行问题的自测解决,然后继续提测,直到没问题就交付软件(批量化的交付,一批一批的交付,此时交付的就是release版本了),批量化的交付是什么意思呢?比如华为鸿蒙系统的更新,它是间隔性的进行发布,比如首先给华为p40用户先进行更新,过段时间这些用户如果使用没问题再进行对下一批用户发布。
产品迭代更新,bug修复,需要重新进行测试,效率太低,自动化测试开发需求(测开人员进行)
要使用gdb调试,必须在源代码生成二进制程序的时候, 加上 -g 选项
开始使用
首先我们先生成debug版本的可执行程序:
gcc test.c -o test_debug -g

进入gdb
gdb test_debug
此时就是进入了
退出gdb
ctrl + d 或 quit

可以看到已经退出了
调试命令
list/l 行号 //显示binFile源代码,接着上次的位置往下列,每次列10行。
list/l 函数名 //列出某个函数的源代码。
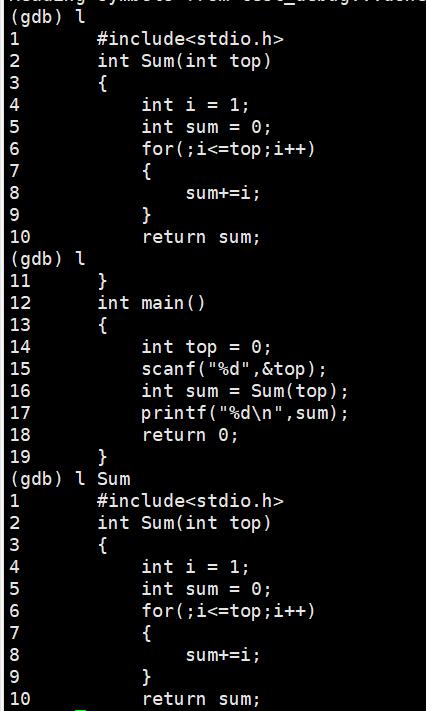
r或run:运行程序。
n 或 next:单条执行。等价于F10(逐过程)
s或step:进入函数调用。等价于F11(逐语句)bt:调用堆栈
break(b) 行号:在某一行设置断点。F9
break 函数名:在某个函数开头设置断点
info break(b) :查看断点信息。
finish:进入函数之后,执行到当前函数返回,然后挺下来等待命令,main函数不行
print§:打印表达式的值,通过表达式可以修改变量的值或者调用函数
p 变量:打印变量值。
set var:修改变量的值
continue(或c):从当前位置开始连续而非单步执行程序
run(或r):从开始连续而非单步执行程序。r加c等价于F5
delete breakpoints:删除所有断点
delete breakpoints n(d n):删除序号为n的断点调试程序完毕,或者中间过程,要有调试痕迹
disable breakpoints(disable n):禁用断点
enable breakpoints:启用断点
info(或i) breakpoints:参看当前设置了哪些断点
display 变量名:跟踪查看一个变量,每次停下来都显示它的值
undisplay:取消对先前设置的那些变量的跟踪
until X行号:跳至X行
breaktrace(或bt):查看各级函数调用及参数
info(i) locals:查看当前栈帧局部变量的值
quit:退出gdb
continue©:跳到下一个断点
自动化构建工具-make/Makefile
背景
- 会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力
- 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作
- makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
- make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
- make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
什么是make和makefile?
make是一条命令,makefile是一个文件,文件内包含目标文件和原始文件的依赖关系
gcc mytest.c -o mytest
mytest.c生成mytest,所以说mytest依赖于mytest.c
生活费用完了,需要找爸爸妈妈要,你给爸爸打电话说:爸我是你儿子(儿子依赖父亲),然后就把电话挂掉了,那么这样并没有达到你的目的,你的目的是要到生活费,所以光有依赖关系是不够的,当你说爸我是你儿子,给我打1000块钱(这就叫依赖方法)
Makefile的编写
首先我们创建Makefile文件:
touch Makefile
使用vim进行该文件的编写
mytest:test.c//依赖关系
gcc test.c -o mytest//必须以tab开头,依赖方法
mytest:test.c的意思就是mytest依赖于test.c,这里需要注意的是在写依赖方法的时候,必须要以tab开头

我们使用make命令,就可以帮我们完成自动编译,那么我们想要删除生成的可执行程序呢?
.PHONY:clean
clean:
rm -f mytest
.PHONY是什么?
定义伪目标:意思是clean总是可以执行的,.PHONY:mytest意思就是mytest总是可以执行的

我们首先不给mytest定义伪目标,他只能执行一次:
我们给mytest也定义为伪目标,就可以总是可以执行的:

make默认是执行第一个可执行程序的,所以前面输入make命令执行的是第一个可执行程序,想要执行clean需要:
make clean
在写依赖方法时,我们也可以这样写:
gcc $^ -o $@
代 表 的 是 所 有 的 依 赖 文 件 , ^代表的是所有的依赖文件, 代表的是所有的依赖文件,@是所有的目标文件
我们在Makefile中这样写:
mytest:test.o
gcc $^ -o $@
test.o:test.s
gcc -c test.s -o test.o
test.s:test.i
gcc -S test.i -o test.s
test.i:test.c
gcc -E test.c -o test.i
使用make命令,可以看到编译时是倒过来编译的,像一个递归似的编译:
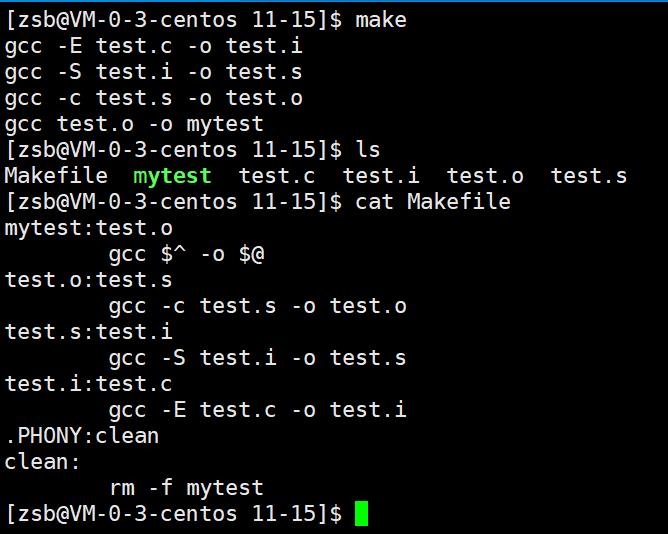
同时编译多个可执行文件
Add.c包含加法函数,各自对应的头文件是Add.h,test.c调用求加法函数来打印和
mytest:test.c Add.o
gcc test.c Add.o -o mytest
Add.o:Add.c
gcc -c Add.c
Linux下的第一个程序—进度条
行缓冲区
首先我们来看下面这段代码:
#include"mytest.h"
#include<unistd.h>
int main()
printf("hello world\\n");
sleep(5);
return 0;
这样我们运行可执行程序时是立即打印出来hello world,然后睡眠5秒

但是把\\n去掉,会是什么样子呢?

我们看到先sleep5秒才打印出来,那么是sleep先执行的吗?答案是并不是的,在执行sleep时,printf已经执行完了,printf执行完但是并不代表字符串就得显示出来,那么在sleep期间,字符串在哪里?答案是在缓冲区,缓冲区本质就是一段内存空间,暂时存储实时数据,再合适的时候刷新出去
缓冲区的刷新策略:
1、直接刷新,不缓冲
2、缓冲区写满,再刷新,称为全缓冲
3、碰到\\n就刷新,称为行刷新,通常往显示器中刷新
4、强制刷新
fflush(stdout);强制刷新到显示器
#include"mytest.h"
#include<unistd.h>
int main()
printf("hello world");
fflush(stdout);
sleep(5);
return 0;
刷新的意思:把数据真正的写入磁盘、显示器、网络等设备或者文件
任何一个C程序,启动的时候,会默认打开三个输入输出流(文件)
stdin 键盘
stdout 显示器
stderr 显示器
回车和换行和回车换行
回车:你正在写某一行,回到该行的起始位置。注意不是下一行的起始位置
换行:你正在写某一行,另起一行,光标往下一行,不一定是在行首
回车并换行:你正在写某一行,另起一行,光标处在行首
在C语言当中:\\n其实是回车并换行,\\r是回车
我们掌握上面的知识来写一个倒计时小程序:
int main()
int count = 9;
while(count>=0)
printf("%d\\r",count);
fflush(stdout);
count--;
sleep(1);
return 0;

将count改为10:

这时出现了问题,为什么呢?
往显示器上打印的并不是数字,而是一个一个的字符,所以在count大于一位数的时候就会出现这样的问题
在printf那里改正为%2d就可以了,每个count以2个字符进行打印:

进度条小程序
procbar.c
#include<stdio.h>
#include<string.h>
#inclkude<unistd.h>
#define NUM 100
int main()
char bar[NUM+1];
memset(bar,0,sizeof(bar));//首先将该数组初始化为NULL
const char*lable = "|/-\\\\";//加载标志,g转圈圈
int i=0;
while(i<=NUM)
bar[i] = '#';
printf("[%-101s][%d%%][%c]\\r",bar,i,label[i%4]);
fflush(stdout);
usleep(100000);
i++;
printf("\\n");
return 0;
进度条程序演示:

git和gitee
git是怎么来的?
雷纳斯托瓦斯写了Linux操作系统,因为Linux是开源项目,所以很多人提交代码给托瓦斯,托瓦斯需要进行手动式的代码合并,雷纳斯托瓦斯就写了git,git是一款软件,既可以充当客户端又可以充当服务器,进行代码托管,版本管理和控制,以及多人协作,Github与Gitee是一类,在云端。区别是Github是国外的,Gitee是国内的。二者的使用需要借助Git。
使用git命令行
安装git
yum install git
在Gitee创建项目
首先进入Gitee,创建好账户进入之后,来到我的,点击创建仓库:
进入之后填写信息:

添加.gitignore的意思是忽略某些文件,避免其提交,可选择性的对仓库初始化。
创建完成后,在创建好的项目页面中复制项目的链接, 以备接下来进行下载:

下载项目到本地
在你本地创建一个存放你代码的目录,然后输入命令:
git clone +项目的链接

git三板斧
git add
git add procbar.c(这是文件名)

git commit
git commit -m "描述性语句"

如果不能commit出现下面情况:

那么你需要先设置一下你的邮箱和用户名:
git config --global user.email "you@example.com"
git config --global user.name "Your Name"
git push
git push
会提示你输入用户名和密码:

输入即可提交成功。
欢迎大家学习讨论!
以上是关于Git 以及 Vim 常见命令整理的主要内容,如果未能解决你的问题,请参考以下文章