Pytorch CIFAR10图像分类 ZFNet篇
Posted 风信子的猫Redamancy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch CIFAR10图像分类 ZFNet篇相关的知识,希望对你有一定的参考价值。
Pytorch CIFAR10图像分类 ZFNet篇
文章目录
再次介绍一下我的专栏,很适合大家初入深度学习或者是Pytorch和Keras,希望这能够帮助初学深度学习的同学一个入门Pytorch或者Keras的项目和在这之中更加了解Pytorch&Keras和各个图像分类的模型。
他有比较清晰的可视化结构和架构,除此之外,我是用jupyter写的,所以说在文章整体架构可以说是非常清晰,可以帮助你快速学习到各个模块的知识,而不是通过python脚本一行一行的看,这样的方式是符合初学者的。
除此之外,如果你需要变成脚本形式,也是很简单的。
这里贴一下汇总篇:汇总篇
4. 定义网络(ZFNet)
ZFNet介绍
首先简单介绍一下ZFNet吧,ZFNet来源于2013的Matthew D. Zeiler和Rob Fergus的Visualizing and Understanding Convolutional Networks论文,为什么叫ZFNet也很简单,作者的两个名的首字母加起来就是啦,这里也给出论文地址,有兴趣可以看看论文https://arxiv.org/abs/1311.2901v3
在 2013 年 ImageNet 大规模视觉识别挑战赛 (ILSVRC) 中,ZFNet 比 AlexNet 有了显着改进,成为众人瞩目的焦点。 这篇论文是非常重要的基石,它提供了许多概念的起点,例如深度特征可视化、特征不变性、特征演化和特征重要性。
在我看来,他在深度学习初期描述了几个很重要的点
- 提出了ZFNet,一种比AlexNet性能更好的网络架构
- 与其在模型中不断试错,不如可视化了中间的feature maps,进行了深度特征可视化,并据此来分析和理解网络
- 进行了许多的消融实验,让CNN的解释性更加形象化,还做了很多特征演化的实验,都是非常好的。
- 探究了预训练大模型的泛化能力,可以进行fine tuning,类似于迁移学习
实际上来说,在近期的发展来说,我们也知道,海量数据,大模型是一种趋势,早在2013年的时候,实际上大家就已经知道预训练大模型,然后迁移到其他相关任务上是非常有用的,即使放在现在来看,我认为这些任务都是make sense的。
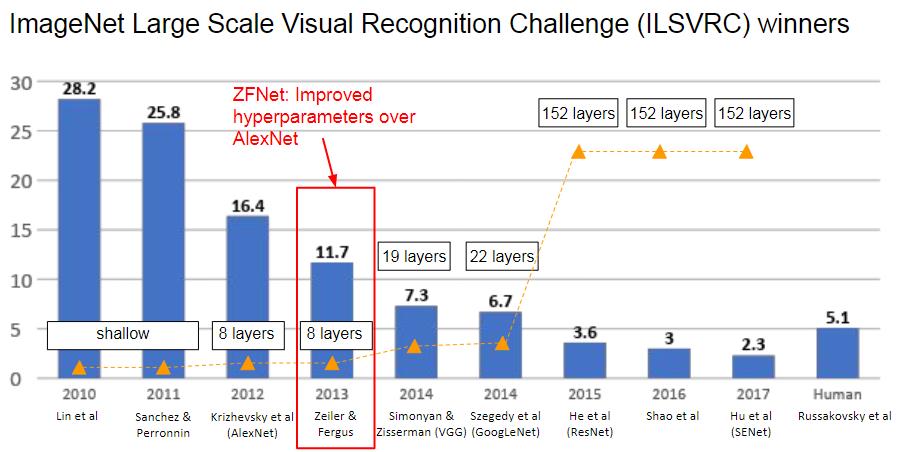
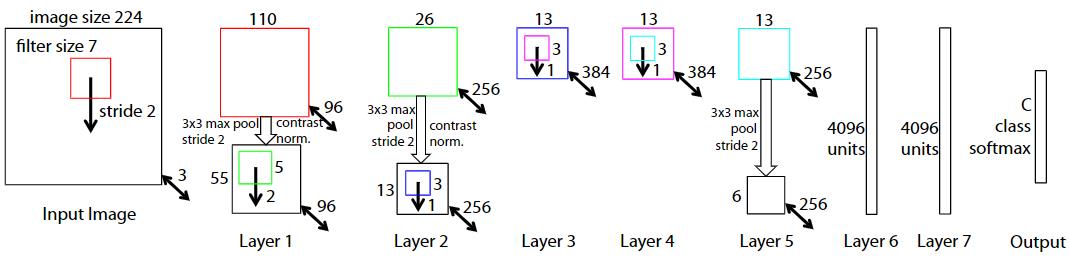
ZFNet结构
实际上的ZFNet是改进了一下AlexNet,第一个11x11的卷积核换为了7x7的卷积核,并且步长从4换成了2,为什么这样做呢,实际上是因为,作者通过对AlexNet的特征进行可视化,文章作者发现第2层出现了aliasing,有些卷积核是无效的,而换成7x7后,无效的卷积核少了,并且步长为4的时候,会出现一些网格状的feature map,这是不利于网络进行学习和判断的,所以也将步长为4换成了2。

最后可以总结一下ZFNet的改进
- 第1个卷积层,kernel size从11减小为7,将stride从4减小为2(这将导致feature map增大1倍)
- 为了让后续feature map的尺寸保持一致,第2个卷积层的stride从1变为2
判断是否使用GPU
首先我们还是得判断是否可以利用GPU,因为GPU的速度可能会比我们用CPU的速度快20-100倍左右,特别是对卷积神经网络来说,更是提升特别明显。
device = 'cuda' if torch.cuda.is_available() else 'cpu'
在定义的时候,为了和论文中的一样,虽然我这里不做反卷积的可视化,但是为了大家可视化ZFNet的feature map,我还是实现了论文中的Switch,他可以记录Maxpool后的最大值的位置,以方便反卷积的时候复原,恢复到原来的像素空间,到我们可以理解的空间中去
class ZFNet(nn.Module):
def __init__(self, num_classes=10):
super(ZFNet, self).__init__()
self.features = nn.Sequential(
# layer 1
nn.Conv2d(3, 96, kernel_size=7, stride=2, padding=1),
nn.ReLU(inplace=True),
# Local contrast norm.
nn.MaxPool2d(kernel_size=3, stride=2, padding=1, return_indices=True), # return_indices – if True, will return the max indices along with the outputs. Useful for torch.nn.MaxUnpool2d later
# layer 2
nn.Conv2d(96, 256, kernel_size=5, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1, return_indices=True),
# layer 3
nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
# layer 4
nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
# layer 5
nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, return_indices=True),
)
self.classifier = nn.Sequential(
# layer 6
nn.Linear(9216, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
# layer 7
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
self.feature_outputs = [0]*len(self.features)
self.switch_indices = dict()
self.sizes = dict()
def forward(self, x):
for i, layer in enumerate(self.features):
if isinstance(layer, nn.MaxPool2d):
x, indices = layer(x)
self.feature_outputs[i] = x
self.switch_indices[i] = indices
else:
x = layer(x)
self.feature_outputs[i] = x
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
net = ZFNet(num_classes=10).to(device)
summary查看网络
我们可以通过summary来看到,模型的维度的变化,这个也是和论文是匹配的,经过层后shape的变化,是否最后也是输出(batch,shape)
summary(net,(2,3,224,224))
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ZFNet [2, 10] --
├─Sequential: 1-1 -- --
│ └─Conv2d: 2-1 [2, 96, 110, 110] 14,208
│ └─ReLU: 2-2 [2, 96, 110, 110] --
│ └─MaxPool2d: 2-3 [2, 96, 55, 55] --
│ └─Conv2d: 2-4 [2, 256, 26, 26] 614,656
│ └─ReLU: 2-5 [2, 256, 26, 26] --
│ └─MaxPool2d: 2-6 [2, 256, 13, 13] --
│ └─Conv2d: 2-7 [2, 384, 13, 13] 885,120
│ └─ReLU: 2-8 [2, 384, 13, 13] --
│ └─Conv2d: 2-9 [2, 384, 13, 13] 1,327,488
│ └─ReLU: 2-10 [2, 384, 13, 13] --
│ └─Conv2d: 2-11 [2, 256, 13, 13] 884,992
│ └─ReLU: 2-12 [2, 256, 13, 13] --
│ └─MaxPool2d: 2-13 [2, 256, 6, 6] --
├─Sequential: 1-2 [2, 10] --
│ └─Linear: 2-14 [2, 4096] 37,752,832
│ └─ReLU: 2-15 [2, 4096] --
│ └─Dropout: 2-16 [2, 4096] --
│ └─Linear: 2-17 [2, 4096] 16,781,312
│ └─ReLU: 2-18 [2, 4096] --
│ └─Dropout: 2-19 [2, 4096] --
│ └─Linear: 2-20 [2, 10] 40,970
==========================================================================================
Total params: 58,301,578
Trainable params: 58,301,578
Non-trainable params: 0
Total mult-adds (G): 2.33
==========================================================================================
Input size (MB): 1.20
Forward/backward pass size (MB): 24.25
Params size (MB): 233.21
Estimated Total Size (MB): 258.67
==========================================================================================
测试和定义网络
我们也可以打印出我们的模型观察一下
print(net)
ZFNet(
(features): Sequential(
(0): Conv2d(3, 96, kernel_size=(7, 7), stride=(2, 2), padding=(1, 1))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(3): Conv2d(96, 256, kernel_size=(5, 5), stride=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(6): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=9216, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
接下来可以简单测试一下,是否输入后能得到我们的正确的维度shape
test_x = torch.randn(2,3,224,224).to(device)
test_y = net(test_x)
print(test_y.shape)
torch.Size([2, 10])
定义网络和设置类别
net = ZFNet(num_classes=10)
5. 定义损失函数和优化器
pytorch将深度学习中常用的优化方法全部封装在torch.optim之中,所有的优化方法都是继承基类optim.Optimizier
损失函数是封装在神经网络工具箱nn中的,包含很多损失函数
这里我使用的是AdamW算法,并且我们损失函数定义为交叉熵函数,除此之外学习策略定义为动态更新学习率,如果5次迭代后,训练的损失并没有下降,那么我们便会更改学习率,会变为原来的0.5倍,最小降低到0.00001
如果想更加了解优化器和学习率策略的话,可以参考以下资料
- Pytorch Note15 优化算法1 梯度下降(Gradient descent varients)
- Pytorch Note16 优化算法2 动量法(Momentum)
- Pytorch Note34 学习率衰减
这里决定迭代10次
import torch.optim as optim
optimizer = optim.SGD(net.parameters(), lr=1e-3, momentum=0.9, weight_decay=5e-4)
optimizer = optim.AdamW(net.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', factor=0.94 ,patience = 1,min_lr = 0.000001) # 动态更新学习率
# scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[75, 150], gamma=0.5)
import time
epoch = 10
6. 训练及可视化(增加TensorBoard可视化)
首先定义模型保存的位置
import os
if not os.path.exists('./model'):
os.makedirs('./model')
else:
print('文件已存在')
save_path = './model/ZFNet.pth'
文件已存在
这次更新了tensorboard的可视化,可以得到更好看的图片,并且能可视化出不错的结果
# 使用tensorboard
from torch.utils.tensorboard import SummaryWriter
os.makedirs("./logs", exist_ok=True)
tbwriter = SummaryWriter(log_dir='./logs/ZFNet', comment='ZFNet') # 使用tensorboard记录中间输出
tbwriter.add_graph(model= net, input_to_model=torch.randn(size=(2, 3, 224, 224)))
如果存在GPU可以选择使用GPU进行运行,并且可以设置并行运算
if device == 'cuda':
net.to(device)
net = nn.DataParallel(net) # 使用并行运算
开始训练
我定义了一个train函数,在train函数中进行一个训练,并保存我们训练后的模型,这一部分一定要注意,这里的utils文件是我个人写的,所以需要下载下来
或者可以参考我们的工具函数篇,我还更新了结果和方法。
from utils import plot_history
from utils import train
Acc, Loss, Lr = train(net, trainloader, testloader, epoch, optimizer, criterion, scheduler, save_path, tbwriter, verbose = True)
Train Epoch 1/10: 100%|██████████| 196/196 [02:18<00:00, 1.41it/s, Train Acc=0.335, Train Loss=1.79]
Test Epoch 1/10: 100%|██████████| 40/40 [00:08<00:00, 4.92it/s, Test Acc=0.465, Test Loss=1.47]
Epoch [ 1/ 10] Train Loss:1.785667 Train Acc:33.51% Test Loss:1.467122 Test Acc:46.50% Learning Rate:0.001000
Train Epoch 2/10: 100%|██████████| 196/196 [02:18<00:00, 1.42it/s, Train Acc=0.532, Train Loss=1.3]
Test Epoch 2/10: 100%|██████████| 40/40 [00:08<00:00, 4.96it/s, Test Acc=0.606, Test Loss=1.13]
Epoch [ 2/ 10] Train Loss:1.299966 Train Acc:53.20% Test Loss:1.129006 Test Acc:60.57% Learning Rate:0.001000
Train Epoch 3/10: 100%|██████████| 196/196 [02:18<00:00, 1.42it/s, Train Acc=0.624, Train Loss=1.06]
Test Epoch 3/10: 100%|██████████| 40/40 [00:08<00:00, 4.96it/s, Test Acc=0.641, Test Loss=1.02]
Epoch [ 3/ 10] Train Loss:1.061436 Train Acc:62.44% Test Loss:1.019601 Test Acc:64.07% Learning Rate:0.001000
Train Epoch 4/10: 100%|██████████| 196/196 [02:18<00:00, 1.42it/s, Train Acc=0.682, Train Loss=0.913]
Test Epoch 4/10: 100%|██████████| 40/40 [00:08<00:00, 4.91it/s, Test Acc=0.677, Test Loss=0.94]
Epoch [ 4/ 10] Train Loss:0.912664 Train Acc:68.17% Test Loss:0.940289 Test Acc:67.74% Learning Rate:0.001000
Train Epoch 5/10: 100%|██████████| 196/196 [02:18<00:00, 1.42it/s, Train Acc=0.722, Train Loss=0.792]
Test Epoch 5/10: 100%|██████████| 40/40 [00:08<00:00, 4.90it/s, Test Acc=0.716, Test Loss=0.841]
Epoch [ 5/ 10] Train Loss:0.791988 Train Acc:72.17% Test Loss:0.840765 Test Acc:71.60% Learning Rate:0.001000
Train Epoch 6/10: 100%|██████████| 196/196 [02:18<00:00, 1.41it/s, Train Acc=0.765, Train Loss=0.676]
Test Epoch 6/10: 100%|██████████| 40/40 [00:08<00:00, 4.94it/s, Test Acc=0.704, Test Loss=0.872]
Epoch [ 6/ 10] Train Loss:0.675561 Train Acc:76.46% Test Loss:0.871565 Test Acc:70.39% Learning Rate:0.001000
Train Epoch 7/10: 100%|██████████| 196/196 [02:18<00:00, 1.42it/s, Train Acc=0.797, Train Loss=0.581]
Test Epoch 7/10: 100%|██████████| 40/40 [00:08<00:00, 4.88it/s, Test Acc=0.716, Test Loss=0.858]
Epoch [ 7/ 10] Train Loss:0.580848 Train Acc:79.69% Test Loss:0.857795 Test Acc:71.61% Learning Rate:0.001000
Train Epoch 8/10: 100%|██████████| 196/196 [02:18<00:00, 1.41it/s, Train Acc=0.828, Train Loss=0.49]
Test Epoch 8/10: 100%|██████████| 40/40 [00:08<00:00, 4.87it/s, Test Acc=0.724, Test Loss=0.856]
Epoch [ 8/ 10] Train Loss:0.489913 Train Acc:82.77% Test Loss:0.855748 Test Acc:72.39% Learning Rate:0.001000
Train Epoch 9/10: 100%|██████████| 196/196 [02:18<00:00, 1.42it/s, Train Acc=0.854, Train Loss=0.418]
Test Epoch 9/10: 100%|██████████| 40/40 [00:08<00:00, 4.94it/s, Test Acc=0.733, Test Loss=0.873]
Epoch [ 9/ 10] Train Loss:0.418106 Train Acc:85.44% Test Loss:0.872757 Test Acc:73.29% Learning Rate:0.001000
Train Epoch 10/10: 100%|██████████| 196/196 [02:18<00:00, 1.42it/s, Train Acc=0.871, Train Loss=0.367]
Test Epoch 10/10: 100%|██████████| 40/40 [00:08<00:00, 4.92it/s, Test Acc=0.738, Test Loss=0.854]
Epoch [ 10/ 10] Train Loss:0.367293 Train Acc:87.15% Test Loss:0.853627 Test Acc:73.83% Learning Rate:0.001000
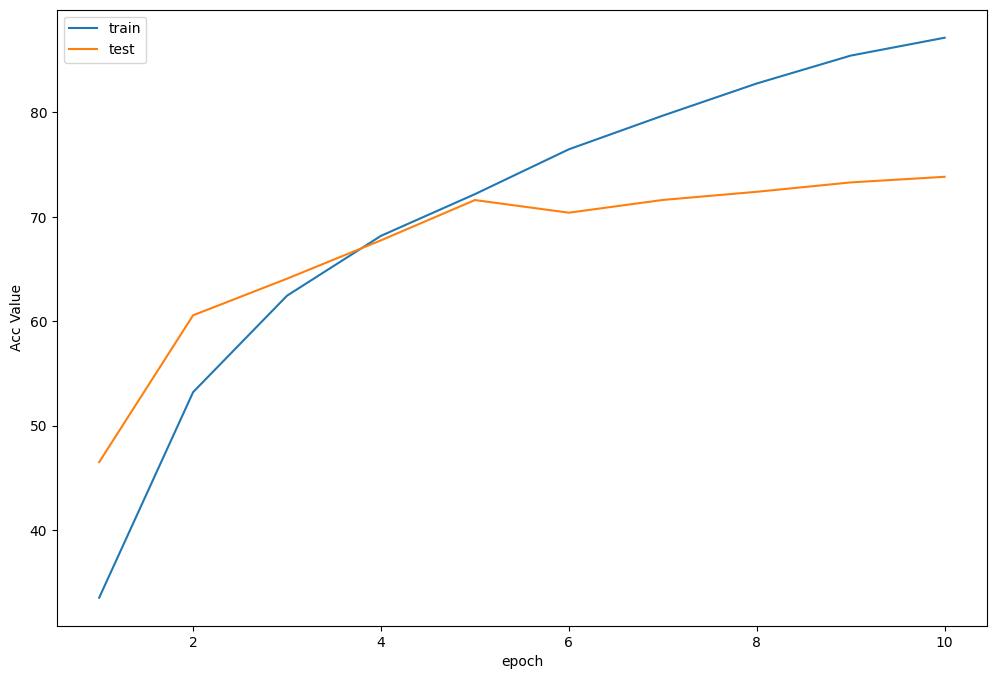
训练曲线可视化
plot_history(epoch ,Acc, Loss, Lr)


可以运行以下代码进行tensorboard可视化
tensorboard --logdir logs
7. 测试
查看准确率
correct = 0 # 定义预测正确的图片数,初始化为0
total = 0 # 总共参与测试的图片数,也初始化为0
for data in testloader: # 循环每一个batch
images, labels = data
images = images.to(device)
labels = labels.to(device)
net.eval() # 把模型转为test模式
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
outputs = net(images) # 输入网络进行测试
# outputs.data是一个4x10张量,将每一行的最大的那一列的值和序号各自组成一个一维张量返回,第一个是值的张量,第二个是序号的张量。
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0) # 更新测试图片的数量
correct += (predicted == labels).sum() # 更新正确分类的图片的数量
print('Accuracy of the network on the 10000 test images: %.2f %%' % (100 * correct / total))
Accuracy of the network on the 10000 test images: 73.95 %
程序中的 torch.max(outputs.data, 1) ,返回一个tuple (元组)
而这里很明显,这个返回的元组的第一个元素是image data,即是最大的 值,第二个元素是label, 即是最大的值 的 索引!我们只需要label(最大值的索引),所以就会有_,predicted这样的赋值语句,表示忽略第一个返回值,把它赋值给 _, 就是舍弃它的意思;
查看每一类的准确率
# 定义2个存储每类中测试正确的个数的 列表,初始化为0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
net.eval()
with torch.no_grad():
for data in testloader:
images, labels = data
images = images.to(device)
labels = labels.to(device)
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
#(batch_size)数据中,输出于label相同的,标记为1,否则为0
c = (predicted == labels).squeeze()
for i in range(len(images)): # 因为每个batch都有len(iamges)张图片,所以还需要一个len(iamges)的小循环
label = labels[i] # 对各个类的进行各自累加
class_correct[label] += c[i]
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %.2f %%' % (classes[i], 100 * class_correct[i] / class_total[i]))
Accuracy of airplane : 75.30 %
Accuracy of automobile : 83.70 %
Accuracy of bird : 66.50 %
Accuracy of cat : 62.10 %
Accuracy of deer : 66.70 %
Accuracy of dog : 62.80 %
Accuracy of frog : 78.50 %
Accuracy of horse : 75.80 %
Accuracy of ship : 84.20 %
Accuracy of truck : 83.90 %
抽样测试并可视化一部分结果
dataiter = iter(testloader)
images, labels = dataiter.next()
images_,labels = images.to(device),labels.to(device)
val_output = net(images_)
_, val_preds = torch.max(val_output, 1)
correct = torch.sum(val_preds == labels.data).item()
val_preds,labels = val_preds.cpu(),labels.cpu()
print("Accuracy Rate = %".format(correct/len(images) * 100))
fig = plt.figure(figsize=(25,25))
for idx in np.arange(64):
ax = fig.add_subplot(8, 8, idx+1, xticks=[], yticks=[])
imshow(images[idx])
ax.set_title(", ()".format(classes[val_preds[idx].item()], classes[labels[idx].item()]),
color = ("green" if val_preds[idx].item()==labels[idx].item() else "red"))
Accuracy Rate = 75.390625%

8. 保存模型
这里保存成前面设定的模型的名字
torch.save(net,save_path[:-4]+'_'+str(epoch)+'.pth')
9. 预测
import torch
from PIL import Image
from torch.autograd import Variable
import torch.nn.functional as F
from torchvision import datasets, transforms
import numpy as np
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = ZFNet(num_classes=10)
model = torch.load(save_path, map_location="cpu") # 加载模型
model.to(device)
model.eval() # 把模型转为test模式
DataParallel(
(module): ZFNet(
(features): Sequential(
(0): Conv2d(3, 96, kernel_size=(7, 7), stride=(2, 2), padding=(1, 1))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(3): Conv2d(96, 256, kernel_size=(5, 5), stride=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(6): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=9216, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
)
并且为了方便,定义了一个predict函数,简单思想就是,先resize成网络使用的shape,然后进行变化tensor输入即可,不过这里有一个点,我们需要对我们的图片也进行transforms,因为我们的训练的时候,对每个图像也是进行了transforms的,所以我们需要保持一致
def predict(img):
trans = transforms.Compose([transforms.Resize((224,<以上是关于Pytorch CIFAR10图像分类 ZFNet篇的主要内容,如果未能解决你的问题,请参考以下文章