gcc 编译多文件批处理文件
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了gcc 编译多文件批处理文件相关的知识,希望对你有一定的参考价值。
例如 我的一个 A文件夹下存放着多个 .c 文件 而这些.c文件需要 B文件夹下.h的支持才能编译
问题: 写一个批处理文件 以对C文件进行批量编译 需要具体的实现代码 谢谢
CFLAGS= -O2 -g -Wall
LIBS= -lsqlite3
LIB_DIR= -L../sqlite3/lib/
INCLUD_DIR= -I../sqlite3/include
test:test.c
$(CC) $^ $(CFLAGS) -o $@ \
$(LIBS) $(INCLUD_DIR) $(LIB_DIR)
.PHONY:clean
clean:
-rm test
1.解释:编译器是gcc(可选)
2.CFLAGS= -O2 -g -Wall 是gcc的参数 -O2优化,-g 加调试信息, -Wall(警告)---CFLAGS项可选
3.LIBS= -lsqlite3(库名)有就写没有就不要写,一般的库编译器自己去系统找,特殊的库要自己加。如:pthread线程库。
4.LIB_DIR= -L../sqlite3/lib/,指定库的路径
5.INCLUD_DIR= -I../sqlite3/include,指定头文件的路径.(I是大写的i)
6.
test:test.c
$(CC) $^ $(CFLAGS) -o $@ \
$(LIBS) $(INCLUD_DIR) $(LIB_DIR)
展开就是:gcc -O2 -g -Wall -o test -L../sqlite3/lib/ -I../sqlite3/include
针对你的问题:
先进你的A文件夹
all:test.o
cc *.o -I../B/include/(写绝对路径)
%*.o:%*.c 参考技术A 可以提供些Windows下可用的GCC的参数信息么?
GCC编译器原理------编译原理三:编译过程---预处理
-
Gcc的编译流程分为了四个步骤:
- 预处理,生成预编译文件(.文件):gcc –E hello.c –o hello.i
- 编译,生成汇编代码(.s文件):gcc –S hello.i –o hello.s
- 汇编,生成目标文件(.o文件):gcc –c hello.s –o hello.o
- 链接,生成可执行文件:gcc hello.o –o hello
一、预处理
预编译程序读出源代码,对其中内嵌的指示字进行响应,产生源代码的修改版本,修改后的版本会被编译程序读入。
在 GNU 术语中,预处理程序叫做 CPP。而 GNU 的可执行程序叫做 cpp。
简单来说,预处理就是将要包含(include)的文件插入原文件中、将宏定义展开、根据条件编译命令选择要使用的代码,最后将这些代码输出到一个 ".i" 文件中等待进一步处理。
预编译过程主要处理那些源代码文件中以 "#"开始的预编译指令。比如"#include"、"#define"等,主要处理规则如下:
- 将所有的 "#define" 删除,并且展开所有的宏定义
- 处理所有条件预编译指令,比如"#if"、"#ifdef"、"#elif"、"#else"、"#endif"
- 处理"#include"预编译指令,将被包含的文件插入到该预编译指令的位置。注意,这个过程是递归进行的,也就是说被包含的文件可能还包含其他文件
- 删除所有的注释"//"和"/* */"
- 添加行号和文件名标识,比如 #2 "hello.c" 2,以便于编译时编译器产生调试用的行号信息及用于编译时产生编译错误或警告时能够显示行号
- 保留所有的 #pragma 编译器指令,因为编译器需要使用它们
经过预编译后的 .i 文件不包含任何宏定义,因为所有的宏已经被展开,并且包含的文件也已经被插入到 .i 文件中。所以当我们无法判断宏定义是否正确或头文件包含是否正确的时候,可以查看预编译后的文件来确定问题。
对 hello.c 进行预编译:gcc -E hello.c -o hello .i

# 28 指的是文件 /usr/include/stdio.h 中的第 28 行,后面的是文件标识
1.1 预处理指令
源代码中的预处理指令叫做指示字(directive) ,从源代码中可以轻易发现,它们以井号(#)开始,在每行都是第一个非空字符。而井号通常都在第一列,后面紧跟着指示字的关键字。
|
指示字 |
描述 |
|
#define |
定义宏名字,预处理程序会把这个宏扩展到使用该名字的位置 |
|
#elif |
由#if 指示字提供一个用于计算的可选表达式 |
|
#else |
如果#if、#ifdef 或#ifndef 为假,提供一个用于编译的可选代码集合 |
|
#error |
产生出错消息,挂起预处理程序 |
|
#if |
如果计算算术表达式的结果为非零值,就编译指示字和它匹配的#endif 之间的代码 |
|
#ifdef |
如果已经定义了指定的宏,就编译指示字和它匹配的#endif 之间的代码 |
|
#ifndef |
如果没有定义指定的宏,就编译指示字和它匹配的#endif 之间的代码 |
|
#include |
查找指示字列表,直到找到指定的文件,然后将文件内容插入,就好像在文本编辑器中插入一样 |
|
#include_next |
和#include 一样,但该指示字从找到当前文件的目录之后的目录开始查找 |
|
#line |
指出行号以及可能的文件名,报告给编译程序,用于创建目标文件中的调试信息 |
|
#pragma |
提供额外信息的标准方法,可用来指出一个编译程序或一个平台 |
|
#undef |
删除前面用#define 指示字创建的定义 |
|
#warning |
由预处理程序创建一个警告消息 |
|
## |
连接操作符,可用于宏内将两个字符串连接成一个 |
1.1.1 #define
- 通过处理传递给宏的参数名字,加上井号(#)就可将其"字符串化"

- 可变的宏是具有可变数目参数的宏。这些参数由省略号代表,被保存在一个由逗号分隔的字符串中作为变量__VA_ARGS__,它会在宏的内部进行扩展。例如,下面的宏接受任何数目的参数:

- 可变的宏可以包含命名的参数(只要随后有参数的变量长度列表) 。例如,下面的宏有两个固定参数,以及一个变量列表:

前面所有形式的可变宏至少有一个参数需要满足参数变量列表的需求,因为__VA_ARGS__前面是一个逗号,它用于宏内部的 fprintf()函数调用。作为连接操作符的一个特例,可以要求在__VA_ARGS__为空时,将它插入变量列表可以去掉逗号,如下:
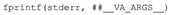
1.1.2 #error 和 #warning
#error 指示字会引起预处理程序报告致命错误或中断。它可用来捕获尝试按照某种不可能工作的形式进行编译的条件。例如,下面的例子只有在定义了__unix__的情况下才能成功编译:
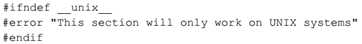
#warning 指示字和#error 指示字的工作原理一样
1.1.3 #include_next
#include_next 指示字只用于某些特殊情况。它用在头文件内部来包含其他头文件,会令新头文件的查找由找到当前头文件的目录之后的目录开始
1.1.4 #line
调试器需要将文件名和行号与数据项和可执行代码关联起来,因此预处理程序会将这类信息插入编译程序的输出结果。有必要按这种方式跟踪原始名字和行号,因为预处理程序会组合一些文件。编译程序在编译插入目标代码中的表时,会使用这些数字。
通常,允许预处理程序通过计算来确定行号,这正是需要的,但也有可能用其他一些处理来去掉这些行号。例如,实现 SQL 语句的通常方法就是将它们写成宏,然后用特殊的处理器将这些宏扩展成具体的 SQL 函数调用。这些扩展可在很多行中运行,这样计算行号就很困难。SQL 处理会通过在输出中插入#line 指示字进行更正,这样预处理程序就会跟踪原始源代码的行号。
-
可用于#line 指示字的特征和规则的列表:
- 为#line 指示字指定一个数字,会令预处理程序将当前行号替换为指定行号;指示字设置当前行号为 137:#line 137
- 为#line 指示字指定行号和文件名,会令预处理程序改变行号以及当前文件的名字。指示字会设置当前位置为文件 muggles.h 的第一行:#line 1 "muggles.h"
- #line 指示字修改预定义宏__LINE__ 和 __FILE__的内容。
- #line 指示字对由#include 指示字查找到的文件名或目录没有影响。
1.1.5 #pragma 和_Pragma
指示字#pragma 提供一种标准方法用来指定特定于编译程序的信息。根据标准,编译程序可以附带#pragma 指示字希望的任何意义。
所有 GCC pragma 都定义了两个词——第一个为 GCC,第二个为指定 pragma 的名字。
-
#pragma GCC dependency
- dependency pragma 测试当前文件的时间戳,对比其他文件的时间戳。如果其他文件更新,就会发出警告消息。测试文件 lexgen.tbl 的时间戳:
- #pragma GCC dependency "lexgen.tbl"
- 如果 lexgen.tbl 比当前文件新,预处理程序就会产生如下消息:
- warning: current file is older than "lexgen.tbl"
- 可在 pragma 指示字中加入其他文本,它会作为警告消息的一部分,如下例所示:
- #pragma GCC dependency "lexgen.tbl" Header lex.h needs to be updated
- 它会创建下面的警告消息:
- show.c:26: warning: current file is older than "lexgen.tbl"
- show.c:26: warning: Header lex.h needs to be updated
-
#pragma GCC poison
- poison pragma 在每次使用指定名字的时候都会发出消息。例如,可用它确保从未调用指定函数。
- 下面的 pragma 在调用 memcpy 复本函数时就会发出警告消息:
- #pragma GCC poison memcpy memmove
- memcpy(target,source,size);
- 预处理程序会为该代码产生如下警告消息:
- show.c:38:9: attempt to use poisoned "memcpy
-
#pragma GCC system_header
- 由 system_header pragma 打头并随后继续到文件尾的代码被看作是系统头文件的一部分。编译系统头文件代码有一些不同,因为运行时库不能被写,因此它们是严格的纯 C 标准格式。限制所有警告消息(除了#warnings 指示字) 。特殊情况下,一定的宏定义和扩展不会发出警告消息。
_Pragma
通常的#pragma 指示字不能作为宏扩展中的一部分包含进来,因此设计_Pragma 操作符是为了生成宏内部的#pragma 指示字。为创建宏内部的 poison pragma,代码如下:_Pragma("GCC poison printf")
反斜线字符用作转义字符,因此可用这种方式插入引用的字符串来创建 dependency
pragma:
_Pragma("GCC dependency "lexgen.tbl"")
1.1.6 ##
可用于宏内部将两个源代码权标连接成一个的连接指示字。可用来构造不会被解析器错误解释的名字。
1.2 预定义宏
GCC中包含了很多的预定义宏,常用的预定义宏如下:
|
宏 |
描述 |
|
__BASE_FILE__ |
引用的字符串,包含的是命令行中指定源文件的完整路径名(不一定是使用宏的所有文件)。参见__FILE__ |
|
__CHAR_UNSIGNED__ |
定义该宏用来指出目标机器的字符数据类型是无符号的。limits.h中用它来确定CHAR_MIN和CHAR_MAX的值 |
|
__cplusplus |
只在C++程序中由定义。如果编译程序不完全符合标准,该宏定义为1,否则它会定义为标准的年和月,格式符合C中的__STDC_VERSION__ |
|
__DATA__ |
11个字符的引用字符串,包括编译程序的日期。它的格式为"May 3 2017" |
|
__FILE__ |
引用字符串,包含使用宏的源文件名。参见__BASE_FILE__ |
|
__func__ |
同__FUNCTION__ |
|
__FUNCTION__ |
引用字符串,包含当前函数的名字 |
|
__GNUC__ |
该宏总是定义为编译程序的主要版本号。例如,如果编译程序版本 |
|
__GNUC_MINOR__ |
该宏总是定义为编译程序的次要版本号。例如,如果编译程序版本 |
|
__GNUC_PATCHLEVEL__ |
该宏总是定义为编译程序的修正版本号。例如,如果编译程序版本 |
|
__GNUG__ |
由 C++编译程序定义。无论何时定义了__cplusplus 和__GNUC__, |
|
__INCLUDE_LEVEL__ |
指出 include 文件当前深度的整数值。该值在基本文件(命令行中指定的文件)时为 0,而每次#include 指示字输入文件就会加 1 |
|
__LINE__ |
使用宏的文件的行号 |
|
__NO_INLINE__ |
在没有扩展内嵌函数的时候,该宏定义为 1,这可能因为没有优化或者不允许进行内嵌函数 |
|
__OBJC__ |
如果程序被编译成 Objective-C,该宏定义为 1 |
|
__OPTIMIZE__ |
无论何时只要指定任何级别的优化处理,该宏就会定义为 1 |
|
__OPTIMIZE_SIZE__ |
如果设置进行尺寸上的优化而不是速度上的优化,该宏就会定义为1 |
|
__REGISTER_PREFIX__ |
该宏为一个权标(而不是字符串) ,它是注册器名的前缀。可用来编写能够移植到多种环境中的汇编语言 |
|
__STDC__ |
定义为 1 指出该编译程序符合标准 C。 在编译 C++和 Objective-C 时不定义该宏,而且在指定-traditional 选项的时候也不会定义该宏 |
|
__STDC_HOSTED__ |
定义为 1 指出"宿主"的环境(其中含有完整的标准 C 库) |
|
__STDC_VERSION__ |
长整数,指出标准版本号,形式为它的年和月。例如,标准的 1999年修正版为 199901L。在编译 C++和 Objective-C 时不会定义该宏,而且在指定-traditional 选项的时候也不会定义该宏 |
|
__STRICT_ANSI__ |
只有在命令行中指定-ansi 或-std 的时候,会定义该宏。在 GNU 头文件中使用它来限制标准中的那些定义 |
|
__TIME__ |
引用 7 个字符的字符串,包含编译程序的时间。格式为"18:10:34" |
|
__USER_LABEL_PREFIX__ |
该宏是一个权标(而不是字符串) ,用作汇编语言中的符号前缀。该权标依平台有所变化,但它通常是个下划线字符 |
|
__USING_SJLJ_EXCEPTIONS__ |
如果异常处理机制为 setjmp 和 longjmp,该宏定义为 1 |
|
__VERSION__ |
完整版本号。该信息没有特殊格式,但它至少含有主要和次要版本号 |
以上是关于gcc 编译多文件批处理文件的主要内容,如果未能解决你的问题,请参考以下文章
GCC编译器原理------编译原理三:编译过程---预处理