图解:Elasticsearch 8.X 如何求解环比上升比例?
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解:Elasticsearch 8.X 如何求解环比上升比例?相关的知识,希望对你有一定的参考价值。
1、企业级Elasticsearch 8.X 实战问题
问题描述:有个聚合的需求,问下大家,一个索引中有时间字段 要求 计算本月和上月相比的环比上升比例?——来自GPVIP群
2、问题释义
2.1 啥叫环比?
环比是统计学术语,表示连续2个统计周期内的量的变化比。
2.2 Elasticsearch 怎么做计算问题?
其实这个问题比较大,从大的角度讲:Elasticsearch 更适合做检索,能做脚本计算处理,但会有性能问题。
官方明确强调:
Avoid script——If possible, avoid using script-based sorting, scripts in aggregations, and the script_score query.
通俗点说,避免使用脚本,除非特殊情况必须使用。
Elasticsearch 能支持的计算问题如下几种方式:
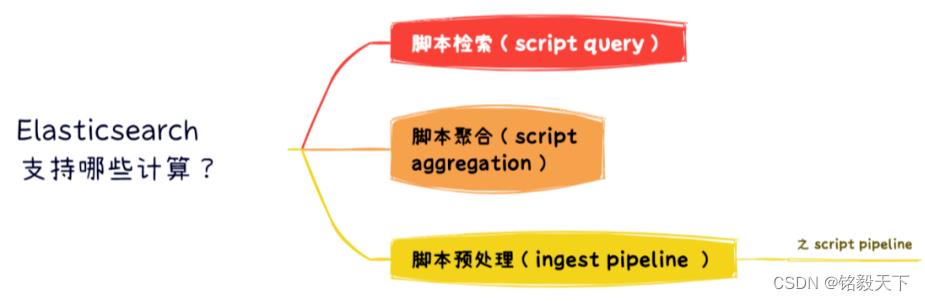
脚本检索(script query) 脚本检索参见:
脚本聚合(script aggregation)参见:
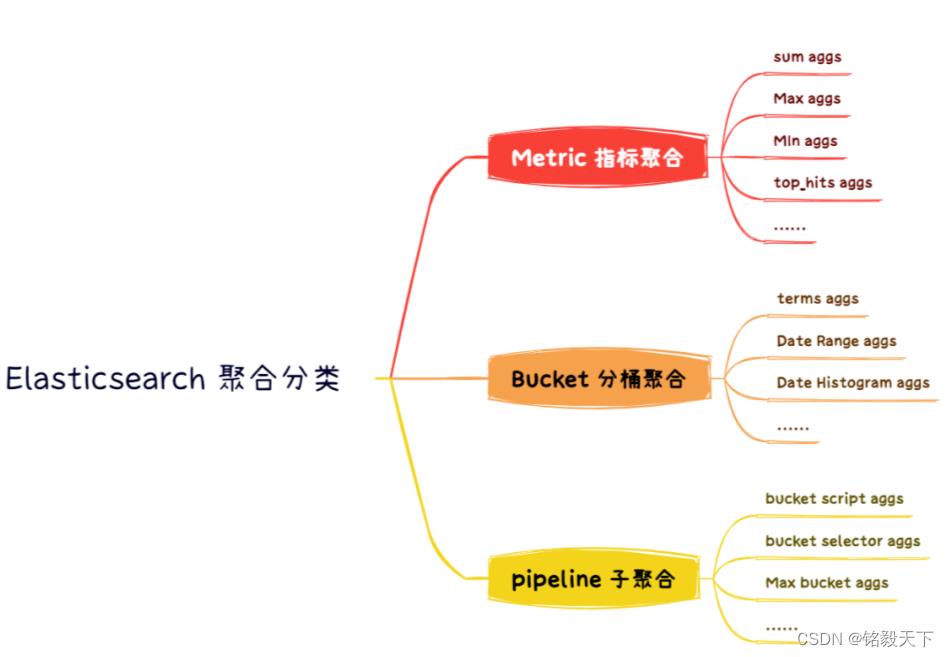
脚本预处理(ingest pipeline 之 script pipeline)。
预处理参见:
Elasticsearch 预处理没有奇技淫巧,请先用好这一招!
Elasticsearch的ETL利器——Ingest节点
3、问题拆解
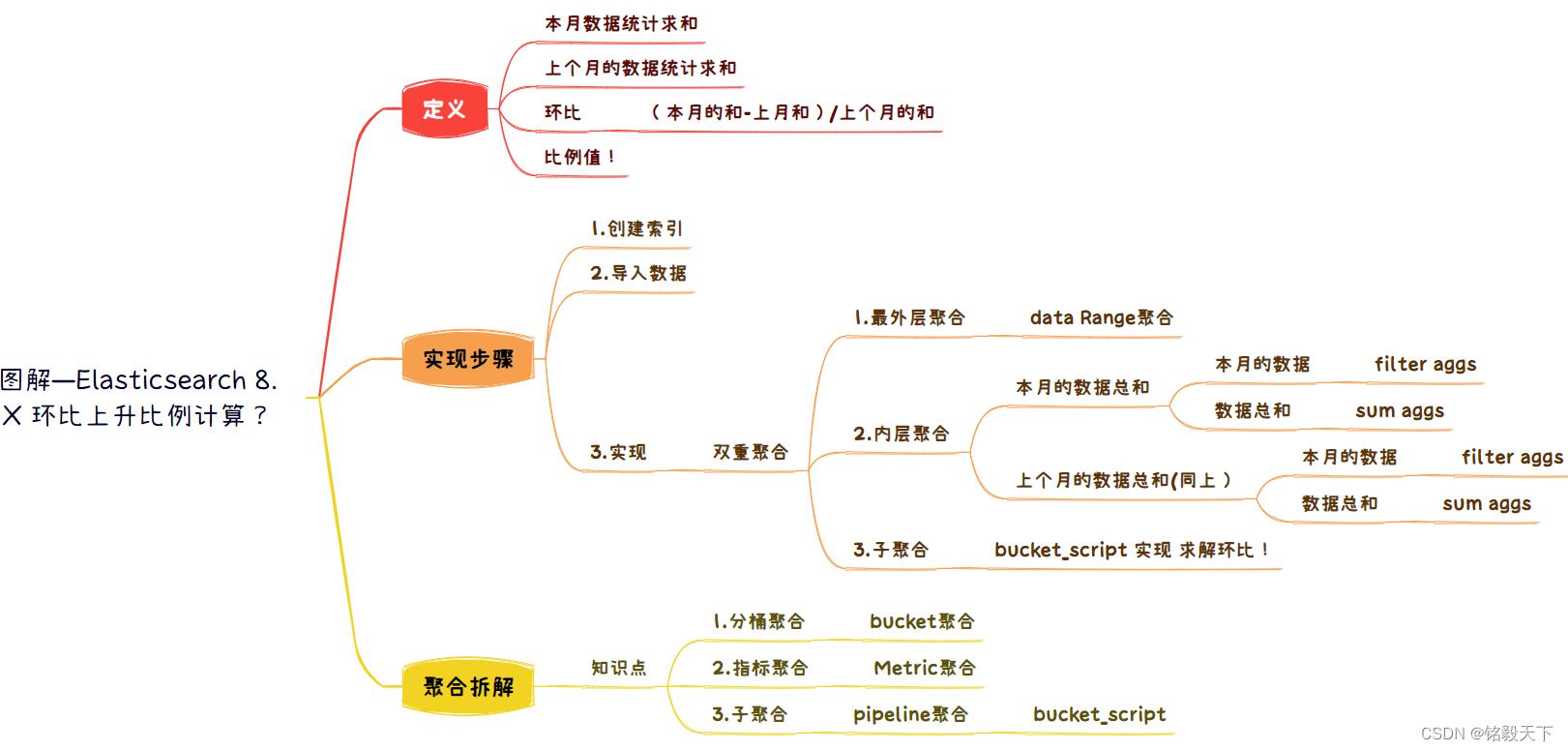
回归我们的问题,分两个维度拆解。
维度1:从数据到结果。
原始的数据至少包含两个字段:日期字段和数据字段,并没有基于日期的汇总数据。
也就是说,汇总结果数据,需要我们借助聚合实现。
维度2:从结果到数据。
最终结果需要临近的两个月份的汇总结果计算求得,需要借助:bucket_script 子聚合实现。而bucket_script 需要两重聚合,且嵌套到内层实现。
可以通过如下三个步骤实现,如下脑图梳理。
- 步骤1:创建索引。
- 步骤2:导入数据(自己构造)。
- 步骤3:聚合实现(最核心)。
聚合的实现是问题求解的关键。
最外层聚合:时间范围聚合,借助Date Range筛选近两个月的数据。
内层聚合:分别求解出本月和前一个月的数据。其实又需要拆解为两层聚合。
第一层:过滤当月和前一个月的时间范围。借助:filter aggs 实现。
第二层:指标 sum aggs 聚合实现结果求和统计。
与上内层同级实现 bucket_script 结果求解,计算环比!
4、问题求解
按照上面脑图拆解的三个步骤搞定实现。视频如下:
4.1:step1 创建索引且指定Mapping!
DELETE test-20221109
PUT test-20221109
"mappings":
"properties":
"insert_date":
"type": "date"
,
"count":
"type": "integer"
4.2 step2 :写入数据
POST test-20221109/_bulk
"index":"_id":1
"insert_date":"2022-11-09T12:00:00Z","count":5
"index":"_id":2
"insert_date":"2022-11-08T12:00:00Z","count":150
"index":"_id":3
"insert_date":"2022-12-09T12:00:00Z","count":33
"index":"_id":4
"insert_date":"2022-12-08T12:00:00Z","count":44
"index":"_id":5
"insert_date":"2022-12-09T12:00:00Z","count":55
"index":"_id":6
"insert_date":"2022-12-08T12:00:00Z","count":66
4.3 step3:聚合求解环比
POST test-20221109/_search
"size": 0,
"aggs":
"range_aggs":
"range":
"field": "insert_date",
"format": "yyyy-MM-dd",
"ranges": [
"from": "2022-11-01",
"to": "2022-12-31"
]
,
"aggs":
"11month_count":
"filter":
"range":
"insert_date":
"gte": "2022-11-01",
"lte": "2022-11-30"
,
"aggs":
"sum_aggs":
"sum":
"field": "count"
,
"12month_count":
"filter":
"range":
"insert_date":
"gte": "2022-12-01",
"lte": "2022-12-31"
,
"aggs":
"sum_aggs":
"sum":
"field": "count"
,
"bucket_division":
"bucket_script":
"buckets_path":
"pre_month_count": "11month_count > sum_aggs",
"cur_month_count": "12month_count > sum_aggs"
,
"script": "(params.cur_month_count - params.pre_month_count) / params.pre_month_count"
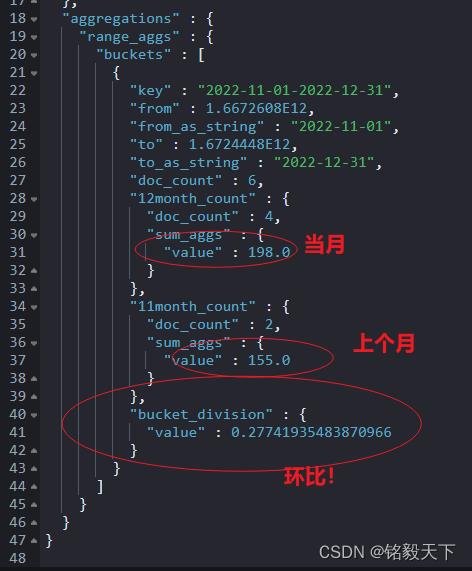
求解结果如下:

5、小结
其实这个聚合实现相当复杂,且不够灵活,可扩展性不强。
业务选型层面,如果非实时求解的场景,真的不建议这么做。
我们可以定时离线计算结果统计,借助 Java 或者 python 等代码实现更为顺畅和“丝滑”。
你的业务层面有没有遇到类似问题?欢迎留言说一下你的方案。
以上是关于图解:Elasticsearch 8.X 如何求解环比上升比例?的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch:如何在 Docker 上运行 Elasticsearch 8.x 进行本地开发
Elasticsearch:如何在 Docker 上运行 Elasticsearch 8.x 进行本地开发
Elasticsearch:如何在 CentOS 上创建多节点的 Elasticsearch 集群 - 8.x
Elasticsearch:如何在 CentOS 上创建多节点的 Elasticsearch 集群 - 8.x
Logstash:如何配置 Metricbeat 及 Logstash 为 Elasticsearch 8.x 收集数据