Elasticsearch 8.X DSL 如何优化更有助于提升检索性能?
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 8.X DSL 如何优化更有助于提升检索性能?相关的知识,希望对你有一定的参考价值。
1、企业级实战 DSL(数据已经脱敏)
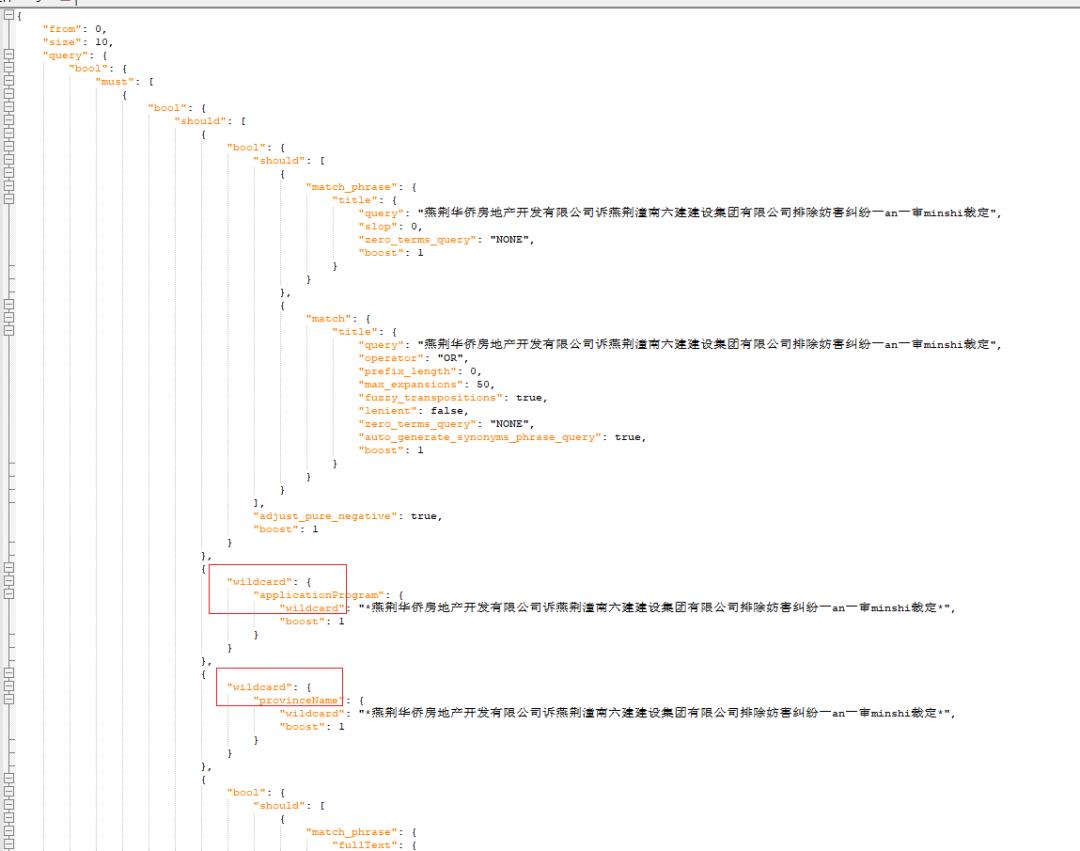

2、大家可以看一下,能发现哪些问题?
根据我的实战和咨询经验,我发现如下几个问题。
当然,这是在和球友交流确认问题之后总结出来的。
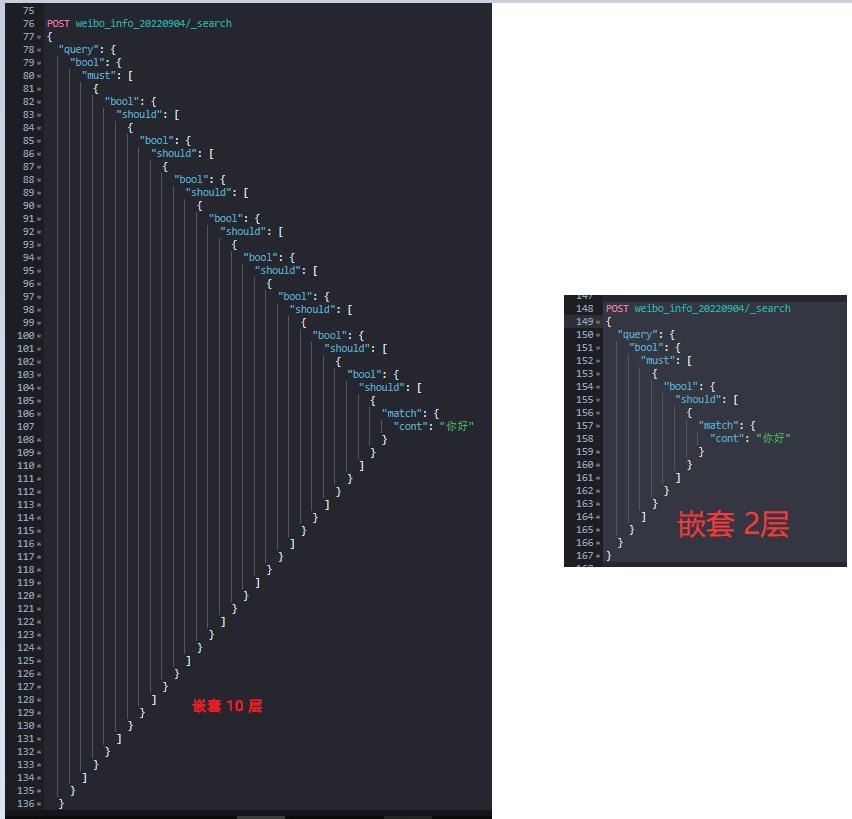
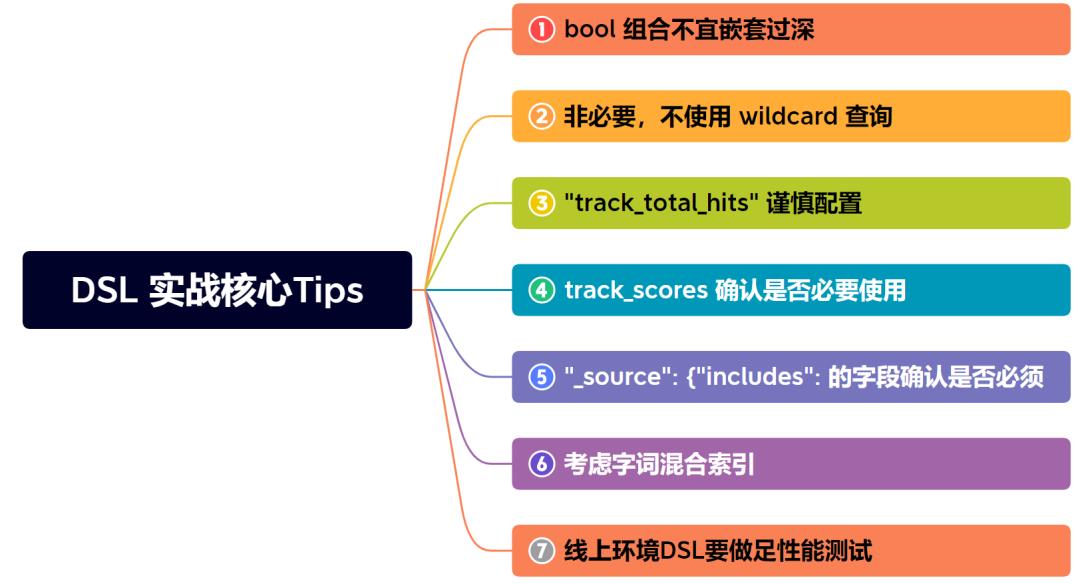
2.1 问题1:bool 组合嵌套过深。
官方实际是有参数来约束的,indices.query.bool.max_nested_depth——bool 最大支持的嵌套层数是 20,并且过大的嵌套层数会导致“堆栈溢出”异常问题。
那 bool 组合嵌套越深是不是越慢呢?
我拿 228 万+的微博数据(JMeter 模拟100用户并发)作为样例索引数据进行验证。
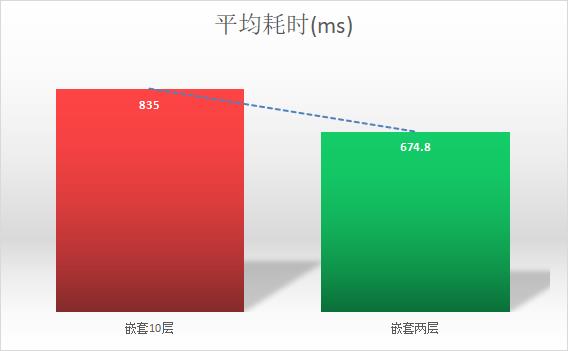
实验1:嵌套 10 层;执行 5 次,平均耗时:835 ms。
实验2:嵌套 2 层;执行 5 次,平均耗时:674.8 ms。
对比看实验 2 执行查询较实验 1 的查询要快!
其实,初步结论是嵌套越深,执行越慢!
2.2 问题2:大量使用 wildcard 查询。
我之前血淋淋的教训告诉大家,非必要不使用 wildcard !
尤其数据量大的场景。
参见:Elasticsearch 警惕使用 wildcard 检索!然后呢?
依然拿 228 万+的微博数据(JMeter 模拟 100 用户并发)作为样例索引数据进行验证。
检索语句如下:
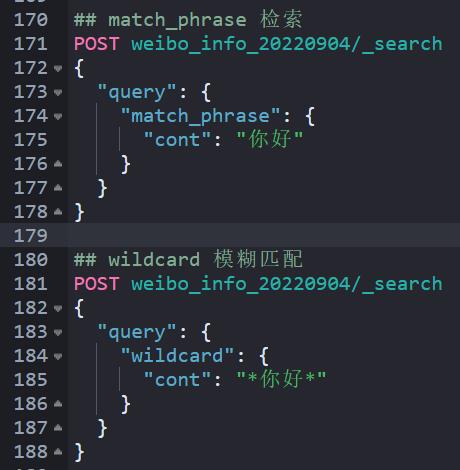
使用:match_phrase 短语匹配较使用 wildcard 模糊匹配效率提升:6.34 倍!
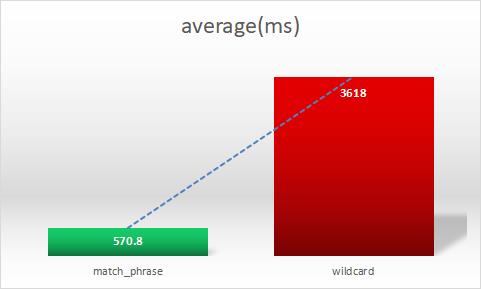
初步结论:非必要,不使用 wildcard。
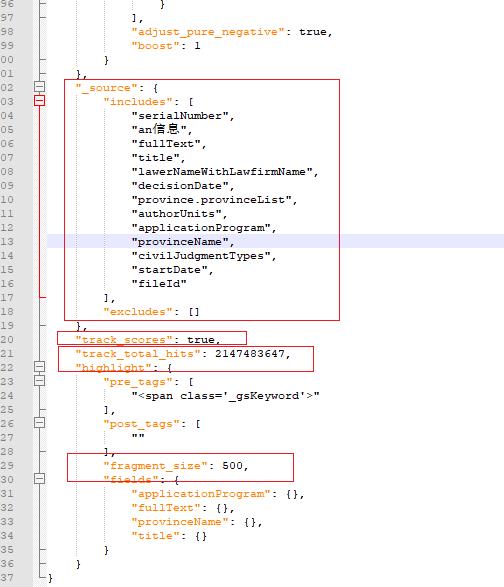
2.3 问题3:"track_total_hits": 2147483647 没有必要搞这么大?
认知前提:Elasticsearch 中 max_result_window 这个参数大家比较熟悉,就是允许 from + size 翻页检索命中的最多文档数为:10000 条记录。
那么问题来了,如果命中数据量超过 10000万怎么办?
一方面:我们可以修改:max_result_window 的默认值,但默认值修改要慎之又慎。
另一方面:我们可以在执行检索的时候加上 track_total_hits 这个参数。
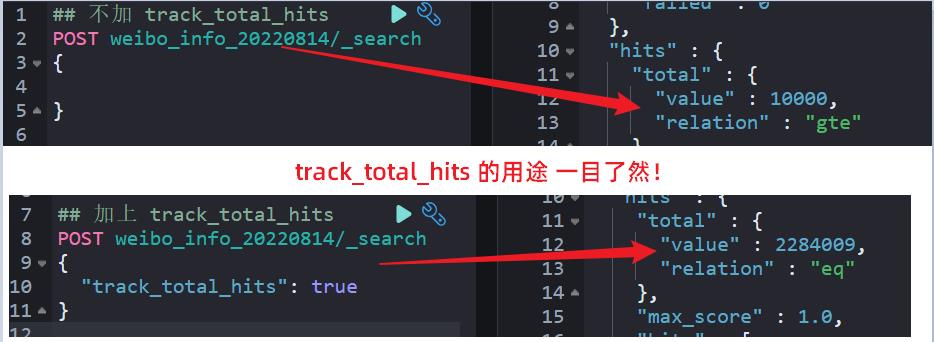
问题来了?什么场景需要单独设置 track_total_hits 参数?什么时候不需要呢?
场景一:当索引设置层面设置了 index.sort 后,本质上写入的数据已经进行了预排序。如果只对前 N 个结果感兴趣,而不关心总命中数,可以简单地将 track_total_hits 设置为 false。
场景二:针对 filter 过滤检索的场景,用户仅关注是否存在,不关注相关性。可以分为如下两种情况:
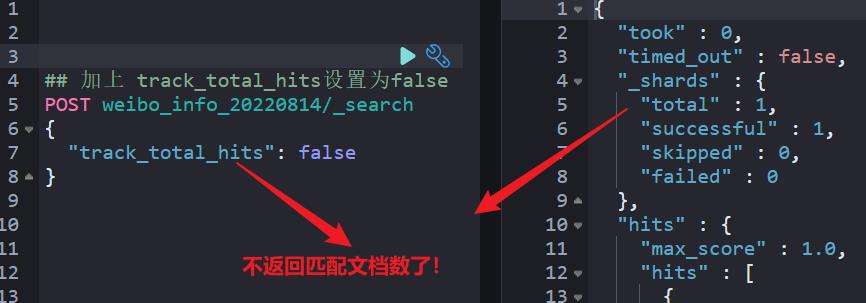
(1)情况2.1:将 track_total_hits 设置为 false,检索结果将不再返回 hits.total 的具体值。
(2)情况2.2:将 track_total_hits 设置为给定的 N, 那么每个分片待召回 N 个文档后就返回。除此之外的业务场景,建议慎用 track_total_hits:true 的场景。
我们同样对比一下性能。
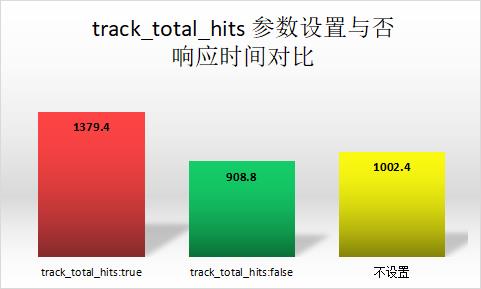
初步结论:加上 track_total_hits,检索会变慢,我们要结合业务场景谨慎使用。
2.4 问题4:track_scores 确认是否必要使用!
track_scores 含义如下:When sorting on a field, scores are not computed. By setting track_scores to true, scores will still be computed and tracked.
也就是说这是个和排序相关的参数,如果走排序,就不计算评分。
如果想对排序加上评分处理,需要加这个参数。
2.5 问题5:"_source": "includes": [ 确认是否必须
其实有更快的建模方式,就是 store 设置 true 对字段单独建模。当然,这涉及到数据建模和写入。
_source 下召回的数据字段越多,肯定会越慢。暂且不说别的,网络传输的角度就可见一斑。
网络传输中,网速一定,但是 _source 字段多,意味着传输的字节数多,必然会越慢。
还是拿微博数据验证一下,
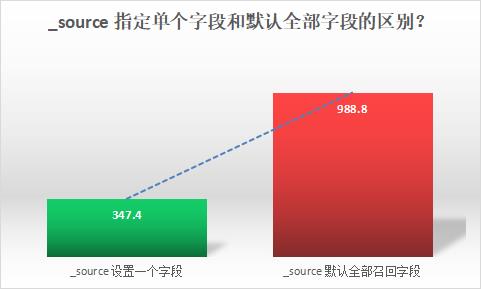
初步结论,仅指定一个字段比全部默认字段(10个以上),影响时间要快很多!
2.6 问题6:match,match_phrase, wildcard 都混合使用,考虑分词问题解决。
推荐:字词混合索引方案。
一个线上问题引发的思考——Elasticsearch 8.X 如何实现更精准的检索?
2.7 问题7:建议线上使用复杂DSL,可以使用性能测试验证一下。
文中 JMeter 测试工具使用,推荐视频:
https://t.zsxq.com/0853Q9epD
3、小结
不要小瞧 DSL 的使用,不要堆砌一些不太理解的参数不加验证直接用于实战环境,后面的风险会变得很大。
DSL 的调优其实直接影响到检索性能。
大家对文中的 DSL 还有哪些调优建议,欢迎留言交流!
推荐阅读

更短时间更快习得更多干货!
和全球 1800+ Elastic 爱好者一起精进!

比同事抢先一步学习进阶干货!
以上是关于Elasticsearch 8.X DSL 如何优化更有助于提升检索性能?的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch 性能调优指南——推荐实战 DSL
Elasticsearch 8.X 检索实战调优锦囊 001
Elasticsearch 8.X 检索实战调优锦囊 001
Elasticsearch 8.X 检索实战调优锦囊 001
如何记录或打印被调用的 python elasticsearch-dsl 查询
我可以将 elasticsearch-dsl 的 IpRange 子类化以供 django-elasticsearch-dsl 使用吗?