自动驾驶技术基本知识介绍
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动驾驶技术基本知识介绍相关的知识,希望对你有一定的参考价值。
参考技术A自动驾驶车,是一种无须人工干预而能够感知其周边环境和导航的车辆。它利用了包括雷达、激光、超声波、GPS、里程计、计算机视觉等多种技术来感知其周边环境,通过先进的计算和控制系统,来识别障碍物和各种标识牌,规划合适的路径来控制车辆行驶。
美国汽车工程师协会(SAE,Society of Automotive Engineers),则将自动驾驶划分为 0~5 共六级。
Level 0:无自动化(No Automation)
没有任何自动驾驶功能或技术,人类驾驶员对汽车所有功能拥有绝对控制权。驾驶员需要负责转向、加速、制动和观察道路状况。任何驾驶辅助技术,例如现有的前向碰撞预警、车道偏离预警,以及自动雨刷和自动前灯控制等,虽然有一定的智能化,但是仍需要人来控制车辆,所以都仍属于 Level 0。
Level 1:驾驶辅助(Driver Assistance)
驾驶员仍然对行车安全负责,不过可以授权部分控制权给系统管理,某些功能可以自动进行,比如常见的自适应巡航(Adaptive Cruise Control,ACC)、应急刹车辅助(Emergency Brake Assist,EBA)和车道保持(Lane-Keep Support,LKS)。Level 1 的特点是只有单一功能,驾驶员无法做到手和脚同时不操控。
Level 2:部分自动化(Partial Automation)
人类驾驶员和汽车来分享控制权,驾驶员在某些预设环境下可以不操作汽车,即手脚同时离开控制,但驾驶员仍需要随时待命,对驾驶安全负责,并随时准备在短时间内接管汽车驾驶权。比如结合了 ACC 和 LKS 形成的跟车功能。Level 2 的核心不在于要有两个以上的功能,而在于驾驶员可以不再作为主要操作者。
Level 3:有条件自动化(Conditional Automation)
在有限情况下实现自动控制,比如在预设的路段(如高速和人流较少的城市路段),汽车自动驾驶可以完全负责整个车辆的操控,但是当遇到紧急情况,驾驶员仍需要在某些时候接管汽车,但有足够的预警时间,如即将进入修路的路段(Road work ahead)。Level 3 将解放驾驶员,即对行车安全不再负责,不必监视道路状况。
Level 4:高度自动化(High Automation)
自动驾驶在特定的道路条件下可以高度自动化,比如封闭的园区、高速公路、城市道路或固定的行车线路等,这这些受限的条件下,人类驾驶员可以全程不用干预。
Level 5:完全自动化(Full Automation)
对行车环境不加限制,可以自动地应对各种复杂的交通状况和道路环境等,在无须人协助的情况下由出发地驶向目的地,仅需起点和终点信息,汽车将全程负责行车安全,并完全不依赖驾驶员干涉,且不受特定道路的限制。
注释:DDT(Dynamic driving task):动态驾驶任务,指汽车在道路上行驶所需的所有实时操作和策略上的功能,不包括行程安排、目的地和途径地的选择等战略上的功能。
无人驾驶系统的核心可以概述为三个部分:感知(Perception),规划(Planning)和控制(Control),这些部分的交互以及其与车辆硬件、其他车辆的交互可以用下图表示:
感知是指无人驾驶系统从环境中收集信息并从中提取相关知识的能力。其中,环境感知(Environmental Perception)特指对于环境的场景理解能力,例如障碍物的位置,道路标志/标记的检测,行人车辆的检测等数据的语义分类。 一般来说,定位(Localization)也是感知的一部分,定位是无人车确定其相对于环境的位置的能力。
为了确保无人车对环境的理解和把握,无人驾驶系统的环境感知部分通常需要获取周围环境的大量信息,具体来说包括:障碍物的位置,速度以及可能的行为,可行驶的区域,交通规则等等。无人车通常是通过融合激光雷达(Lidar),相机(Camera),毫米波雷达(Millimeter Wave Radar)等多种传感器的数据来获取这些信息。
车载雷达传感器功能及优缺点各有不同,相关比较如下表所示:
激光雷达 是一类使用激光进行探测和测距的设备,它能够每秒钟向环境发送数百万光脉冲,它的内部是一种旋转的结构,这使得激光雷达能够实时的建立起周围环境的3维地图。
通常来说,激光雷达以10Hz左右的速度对周围环境进行旋转扫描,其扫描一次的结果为密集的点构成的3维图,每个点具备(x,y,z)信息,这个图被称为点云图(Point Cloud Graph),如下图所示,是使用Velodyne VLP-32c激光雷达建立的一个点云地图:
激光雷达因其可靠性目前仍是无人驾驶系统中最重要的传感器,然而,在现实使用中,激光雷达并不是完美的,往往存在点云过于稀疏,甚至丢失部分点的问题,对于不规则的物体表面,使用激光雷达很难辨别其模式,另一个比较大的挑战是一个比较大的挑战是激光雷达感知范围比较近,感知范围平均在 150m 左右,这取决于环境和障碍物的不同。激光雷达在角分辨度上也远远不及照相机。激光雷达对环境的敏感度也是比较大的,例如雨天中,车辆行驶中溅起来的水花,在激光雷达上都是有噪点的。
毫米波雷达 通过发射电磁波并通过检测回波来探测目标的有无、距离、速度和方位。由于毫米波雷达技术相对成熟,成本较低,并且在不良天气下表现良好,因此成为感知设备中重要的一环。但由于其分辨率较低,因此不能作为激光雷达的替代品,而是激光雷达的重要补充设备。
摄像机 根据镜头和布置方式的不同主要有以下四种:单目摄像机、双目摄像机、三目摄像机和环视摄像机。
单目摄像机 模组只包含一个摄像机和一个镜头。由于很多图像算法的研究都是基于单目摄像机开发的,因此相对于其他类别的摄像机,单目摄像机的算法成熟度更高。但是单目有着两个先天的缺陷。一是它的视野完全取决于镜头。焦距短的镜头,视野广,但缺失远处的信息。反之亦然。因此单目摄像机一般选用适中焦距的镜头。二是单目测距的精度较低。摄像机的成像图是透视图,即越远的物体成像越小。近处的物体,需要用几百甚至上千个像素点描述;而处于远处的同一物体,可能只需要几个像素点即可描述出来。这种特性会导致,越远的地方,一个像素点代表的距离越大,因此对单目来说物体越远,测距的精度越低。
双目摄像机 由于单目测距存在缺陷,双目摄像机应运而生。相近的两个摄像机拍摄物体时,会得到同一物体在摄像机的成像平面的像素偏移量。有了像素偏移量、相机焦距和两个摄像机的实际距离这些信息,根据数学换算即可得到物体的距离。虽然双目能得到较高精度的测距结果和提供图像分割的能力,但是它与单目一样,镜头的视野完全依赖于镜头。而且双目测距原理对两个镜头的安装位置和距离要求较多,这就会给相机的标定带来麻烦。
三目摄像机 由于单目和双目都存在某些缺陷,因此广泛应用于无人驾驶的摄像机方案为三目摄像机。三目摄像机其实就是三个不同焦距单目摄像机的组合。根据焦距不同,每个摄像机所感知的范围也不尽相同。对摄像机来说,感知的范围要么损失视野,要么损失距离。三目摄像机能较好地弥补感知范围的问题。因此在业界被广泛应用。正是由于三目摄像机每个相机的视野不同,因此近处的测距交给宽视野摄像头,中距离的测距交给主视野摄像头,更远的测距交给窄视野摄像头。这样一来每个摄像机都能发挥其最大优势。三目的缺点是需要同时标定三个摄像机,因而工作量更大。其次软件部分需要关联三个摄像机的数据,对算法要求也很高。
环视摄像机, 之前提到的三款摄像机它们所用的镜头都是非鱼眼的,环视摄像机的镜头是鱼眼镜头,而且安装位置是朝向地面的。某些高配车型上会有“360°全景显示”功能,所用到的就是环视摄像机。安装于车辆前方、车辆左右后视镜下和车辆后方的四个鱼眼镜头采集图像,鱼眼摄像机为了获取足够大的视野,代价是图像的畸变严重。环视摄像机的感知范围并不大,主要用于车身5~10米内的障碍物检测、自主泊车时的库位线识别等。
为了理解点云信息,通常来说,我们对点云数据进行两步操作:分割(Segmentation)和分类(Classification)。其中,分割是为了将点云图中离散的点聚类成若干个整体,而分类则是区分出这些整体属于哪一个类别(比如说行人,车辆以及障碍物)。分割算法可以被分类如下几类:
在完成了点云的目标分割以后,分割出来的目标需要被正确的分类,在这个环节,一般使用机器学习中的分类算法,如支持向量机(Support Vector Machine,SVM)对聚类的特征进行分类,最近几年由于深度学习的发展,业界开始使用特别设计的卷积神经网络(Convolutional Neural Network,CNN)对三维的点云聚类进行分类。
实践中不论是提取特征-SVM的方法还是原始点云-CNN的方法,由于激光雷达点云本身解析度低的原因,对于反射点稀疏的目标(比如说行人),基于点云的分类并不可靠,所以在实践中,我们往往融合雷达和相机传感器,利用相机的高分辨率来对目标进行分类,利用Lidar的可靠性对障碍物检测和测距,融合两者的优点完成环境感知。
无人驾驶系统中,我们通常使用图像视觉来完成道路的检测和道路上目标的检测。道路的检测包含对道路线的检测(Lane Detection),可行驶区域的检测(Drivable Area Detection);道路上路标的检测包含对其他车辆的检测(Vehicle Detection),行人检测(Pedestrian Detection),交通标志和信号的检测(Traffic Sign Detection)等所有交通参与者的检测和分类。
车道线的检测涉及两个方面: 第一是识别出车道线,对于弯曲的车道线,能够计算出其曲率,第二是确定车辆自身相对于车道线的偏移(即无人车自身在车道线的哪个位置) 。一种方法是抽取一些车道的特征,包括边缘特征(通常是求梯度,如索贝尔算子),车道线的颜色特征等,使用多项式拟合我们认为可能是车道线的像素,然后基于多项式以及当前相机在车上挂载的位置确定前方车道线的曲率和车辆相对于车道的偏离。
可行驶区域的检测目前的一种做法是采用深度神经网络直接对场景进行分割,即通过训练一个逐像素分类的深度神经网络,完成对图像中可行驶区域的切割。
交通参与者的检测和分类目前主要依赖于深度学习模型,常用的模型包括两类:
传感器层将数据以一帧帧、固定频率发送给下游,但下游是无法拿每帧的数据去进行决策或者融合的。因为传感器的状态不是100%有效的,如果仅根据某一帧的信号去判定前方是否有障碍物(有可能是传感器误检了),对下游决策来说是极不负责任的。因此上游需要对信息做预处理,以保证车辆前方的障得物在时间维度上是一直存在的, 而不是一闪而过。
这里就会使用到智能驾驶领域经常使用到的一个算法 卡尔曼滤波。
卡尔曼滤波(Kalman filter) 是一种高效率的递归滤波器(自回归滤波器),它能够从一系列的不完全及包含噪声的测量中,估计动态系统的状态。卡尔曼滤波会根据各测量量在不同时间下的值,考虑各时间下的联合分布,再产生对未知变数的估计,因此会比只以单一测量量为基础的估计方式要准。
卡尔曼滤波在技术领域有许多的应用。常见的有飞机及太空船的导引、导航及控制。卡尔曼滤波也广为使用在时间序列的分析中,例如信号处理及计量经济学中。卡尔曼滤波也是机器人运动规划及控制的重要主题之一,有时也包括在轨迹最佳化。卡尔曼滤波也用在中轴神经系统运动控制的建模中。因为从给与运动命令到收到感觉神经的回授之间有时间差,使用卡尔曼滤波有助于建立符合实际的系统,估计运动系统的目前状态,并且更新命令。
信息融合是指把相同属性的信息进行多合一操作。
比如摄像机检测到了车辆正前方有一个障碍物,毫米波也检测到车辆前方有一个障碍物,激光雷达也检测到前方有一个障碍物,而实际上前方只有一个障碍物,所以我们要做的是把多传感器下这辆车的信息进行一次融合,以此告诉下游,前面有辆车,而不是三辆车。
坐标转换在自动驾驶领域十分重要。
传感器是安装在不同地方的比如超声波雷达(假如当车辆右方有一个障碍物,距离这个超声波雷达有3米,那么我们就认为这个障碍物距离车有3米吗?并不一定,因为决策控制层做车辆运动规划时,是在车体坐标系下做的(车体坐标系-般以后轴中心为O点)所以最终所有传感器的信息,都是需要转移到自车坐标系下的。因此感知层拿到3m的障碍物位置信息后,必须将该章碍物的位置信息转移到自车坐标系下,才能供规划决策使用。 同理,摄像机一般安装在挡风玻璃下面,拿到的数据也是基于摄像机坐标系的,给下游的数据,同样需要转换到自车坐标系下。
在无人车感知层面,定位的重要性不言而喻,无人车需要知道自己相对于环境的一个确切位置,这里的定位不能存在超过10cm的误差,试想一下,如果我们的无人车定位误差在30厘米,那么这将是一辆非常危险的无人车(无论是对行人还是乘客而言),因为无人驾驶的规划和执行层并不知道它存在30厘米的误差,它们仍然按照定位精准的前提来做出决策和控制,那么对某些情况作出的决策就是错的,从而造成事故。由此可见,无人车需要高精度的定位。
目前使用最广泛的无人车定位方法当属融合 全球定位系统(Global Positioning System,GPS)和惯性导航系统(Inertial Navigation System)定位方法 ,其中,GPS的定位精度在数十米到厘米级别之间,高精度的GPS传感器价格也就相对昂贵。融合GPS/IMU的定位方法在GPS信号缺失,微弱的情况下无法做到高精度定位,如地下停车场,周围均为高楼的市区等,因此只能适用于部分场景的无人驾驶任务。
地图辅助类定位算法是另一类广泛使用的无人车定位算法, 同步定位与地图构建(Simultaneous Localization And Mapping,SLAM) 是这类算法的代表,SLAM的目标即构建地图的同时使用该地图进行定位,SLAM通过利用已经观测到的环境特征确定当前车辆的位置以及当前观测特征的位置。这是一个利用以往的先验和当前的观测来估计当前位置的过程,实践上我们通常使用贝叶斯滤波器(Bayesian filter)来完成,具体来说包括卡尔曼滤波(Kalman Filter),扩展卡尔曼滤波(Extended Kalman Filter)以及粒子滤波(Particle Filter)。SLAM虽然是机器人定位领域的研究热点,但是在实际无人车开发过程中使用SLAM定位却存在问题,不同于机器人,无人车的运动是长距离的,大开放环境的。在长距离的运动中,随着距离的增大,SLAM定位的偏差也会逐渐增大,从而造成定位失败。
在实践中,一种有效的无人车定位方法是改变原来SLAM中的扫描匹配类算法,具体来说,我们不再在定位的同时制图,而是事先使用传感器如激光雷达对区域构建点云地图,通过程序和人工的处理将一部分“语义”添加到地图中(例如车道线的具体标注,路网,红绿灯的位置,当前路段的交通规则等等),这个包含了语义的地图就是我们无人驾驶车的 高精度地图(HD Map) 。实际定位的时候,使用当前激光雷达的扫描和事先构建的高精度地图进行点云匹配,确定我们的无人车在地图中的具体位置,这类方法被统称为扫描匹配方法(Scan Matching),扫描匹配方法最常见的是迭代最近点法(Iterative Closest Point ,ICP),该方法基于当前扫描和目标扫描的距离度量来完成点云配准。
除此以外, 正态分布变换(Normal Distributions Transform,NDT) 也是进行点云配准的常用方法,它基于点云特征直方图来实现配准。基于点云配准的定位方法也能实现10厘米以内的定位精度。虽然点云配准能够给出无人车相对于地图的全局定位,但是这类方法过于依赖事先构建的高精度地图,并且在开放的路段下仍然需要配合GPS定位使用,在场景相对单一的路段(如高速公路),使用GPS加点云匹配的方法相对来说成本过高。
拓展阅读: L4 自动驾驶中感知系统遇到的挑战及解决方案
浅析自动驾驶的重要一环:感知系统发展现状与方向
无人车的规划模块分为三层设计:任务规划,行为规划和动作规划,其中,任务规划通常也被称为路径规划或者路由规划(Route Planning),其负责相对顶层的路径规划,例如起点到终点的路径选择。 我们可以把我们当前的道路系统处理成有向网络图(Directed Graph Network),这个有向网络图能够表示道路和道路之间的连接情况,通行规则,道路的路宽等各种信息,其本质上就是我们前面的定位小节中提到的高精度地图的“语义”部分,这个有向网络图被称为路网图(Route Network Graph),如下图所示:
这样的路网图中的每一个有向边都是带权重的,那么,无人车的路径规划问题,就变成了在路网图中,为了让车辆达到某个目标(通常来说是从A地到B地),基于某种方法选取最优(即损失最小)的路径的过程,那么问题就变成了一个有向图搜索问题,传统的算法如迪科斯彻算法(Dijkstra’s Algorithm)和A 算法(A Algorithm)主要用于计算离散图的最优路径搜索,被用于搜索路网图中损失最小的路径。
行为规划有时也被称为决策制定(Decision Maker),主要的任务是按照任务规划的目标和当前的局部情况(其他的车辆和行人的位置和行为,当前的交通规则等),作出下一步无人车应该执行的决策,可以把这一层理解为车辆的副驾驶,他依据目标和当前的交通情况指挥驾驶员是跟车还是超车,是停车等行人通过还是绕过行人等等。
行为规划的一种方法是使用包含大量动作短语的复杂有限状态机(Finite State Machine,FSM)来实现,有限状态机从一个基础状态出发,将根据不同的驾驶场景跳转到不同的动作状态,将动作短语传递给下层的动作规划层,下图是一个简单的有限状态机:
如上图所示,每个状态都是对车辆动作的决策,状态和状态之间存在一定的跳转条件,某些状态可以自循环(比如上图中的循迹状态和等待状态)。虽然是目前无人车上采用的主流行为决策方法,有限状态机仍然存在着很大的局限性:首先,要实现复杂的行为决策,需要人工设计大量的状态;车辆有可能陷入有限状态机没有考虑过的状态;如果有限状态机没有设计死锁保护,车辆甚至可能陷入某种死锁。
通过规划一系列的动作以达到某种目的(比如说规避障碍物)的处理过程被称为动作规划。通常来说,考量动作规划算法的性能通常使用两个指标:计算效率(Computational Efficiency)和完整性(Completeness),所谓计算效率,即完成一次动作规划的处理效率,动作规划算法的计算效率在很大程度上取决于配置空间(Configuration Space),如果一个动作规划算法能够在问题有解的情况下在有限时间内返回一个解,并且能够在无解的情况下返回无解,那么我们称该动作规划算法是完整的。
配置空间:一个定义了机器人所有可能配置的集合,它定义了机器人所能够运动的维度,最简单的二维离散问题,那么配置空间就是[x, y],无人车的配置空间可以非常复杂,这取决于所使用的运动规划算法。
在引入了配置空间的概念以后,那么无人车的动作规划就变成了:在给定一个初始配置(Start Configuration),一个目标配置(Goal Configuration)以及若干的约束条件(Constraint)的情况下,在配置空间中找出一系列的动作到达目标配置,这些动作的执行结果就是将无人车从初始配置转移至目标配置,同时满足约束条件。在无人车这个应用场景中,初始配置通常是无人车的当前状态(当前的位置,速度和角速度等),目标配置则来源于动作规划的上一层——行为规划层,而约束条件则是车辆的运动限制(最大转角幅度,最大加速度等)。显然,在高维度的配置空间来动作规划的计算量是非常巨大的,为了确保规划算法的完整性,我们不得不搜索几乎所有的可能路径,这就形成了连续动作规划中的“维度灾难”问题。目前动作规划中解决该问题的核心理念是将连续空间模型转换成离散模型,具体的方法可以归纳为两类:组合规划方法(Combinatorial Planning)和基于采样的规划方法(Sampling-Based Planning)。
运动规划的组合方法通过连续的配置空间找到路径,而无需借助近似值。由于这个属性,它们可以被称为精确算法。组合方法通过对规划问题建立离散表示来找到完整的解,如在Darpa城市挑战赛(Darpa Urban Challenge)中,CMU的无人车BOSS所使用的动作规划算法,他们首先使用路径规划器生成备选的路径和目标点(这些路径和目标点事融合动力学可达的),然后通过优化算法选择最优的路径。另一种离散化的方法是网格分解方法(Grid Decomposition Approaches),在将配置空间网格化以后我们通常能够使用离散图搜索算法(如A*)找到一条优化路径。
基于采样的方法由于其概率完整性而被广泛使用,最常见的算法如PRM(Probabilistic Roadmaps),RRT(Rapidly-Exploring Random Tree),FMT(Fast-Marching Trees),在无人车的应用中,状态采样方法需要考虑两个状态的控制约束,同时还需要一个能够有效地查询采样状态和父状态是否可达的方法。
自动驾驶汽车的车辆控制技术旨在环境感知技术的基础之上,根据决策规划出目标轨迹,通过纵向和横向控制系统的配合使汽车能够按照跟踪目标轨迹准确稳定行驶,同时使汽车在行驶过程中能够实现车速调节、车距保持、换道、超车等基本操作。
互联网科技公司主要做软件,以工程机上层为主;而车厂其实以下层的组装为主,也就是OEM,也不是那么懂车。像制动、油门和转向等这些领域,话语权依然集中在博世、大陆这样的Tier 1身上。
自动驾驶控制的核心技术是车辆的纵向控制和横向控制技术。纵向控制,即车辆的驱动与制动控制;横向控制,即方向盘角度的调整以及轮胎力的控制。实现了纵向和横向自动控制,就可以按给定目标和约束自动控制车运行。所以,从车本身来说,自动驾驶就是综合纵向和横向控制。
车辆纵向控制是在行车速度方向上的控制,即车速以及本车与前后车或障碍物距离的自动控制。巡航控制和紧急制动控制都是典型的自动驾驶纵向控制案例。这类控制问题可归结为对电机驱动、发动机、传动和制动系统的控制。各种电机-发动机-传动模型、汽车运行模型和刹车过程模型与不同的控制器算法结合,构成了各种各样的纵向控制模式,典型结构如图所示。
此外,针对轮胎作用力的 滑移率控制 是纵向稳定控制中的关键部分。滑移率控制系统通过控制车轮滑移率调节车辆的纵向动力学特性来防止车辆发生过度驱动滑移或者制动抱死,从而提高车辆的稳定性和操纵性能。制动防抱死系统(antilock brake system)简称 ABS,在汽车制动时,自动控制制动器制动力的大小,使车轮不被抱死,处于边滚边滑(滑移率在 20%左右)的状态,以保证地面能够给车轮提供最大的制动作用力值。一些智能滑移率控制策略利用充足的环境感知信息设计了随道路环境变化的车轮最有滑移率调节器,从而提升轮胎力作用效果。
智能控制策略,如模糊控制、神经网络控制、滚动时域优化控制等,在纵向控制中也得到广泛研究和应用,并取得了较好的效果,被认为是最有效的方法。
而传统控制的方法, 如PID控制和前馈开环控制 ,一般是建立发动机和汽车运动过程的近似线形模型,在此基础上设计控制器,这种方法实现的控制,由于对模型依赖性大及模型误差较大,所以精度差、适应性差。从目前的论文和研究的项目看,寻求简单而准确的电机-发动机-传动、刹车过程和汽车运动模型,以及对随机扰动有鲁棒性和对汽车本身性能变化有适应性的控制器仍是研究的主要内容。
车辆横向控制指垂直于运动方向上的控制,对于汽车也就是转向控制。目标是控制汽车自动保持期望的行车路线,并在不同的车速、载荷、风阻、路况下有很好的乘坐舒适性和稳定性。
车辆横向控制主要有两种基本设计方法,一种是基于驾驶员模拟的方法;另一种是给予汽车横向运动力学模型的控制方法。基于驾驶员模拟的方法,一种策略是使用较简单的运动力学模型和驾驶员操纵规则设计控制器;另一策略是用驾驶员操纵过程的数据训练控制器获取控制算法。基于运动力学模型的方法要建立较精确的汽车横向运动模型。典型模型是所谓单轨模型,或称为自行车模型,也就是认为汽车左右两侧特性相同。横向控制系统基本结构如下图。控制目标一般是车中心与路中心线间的偏移量,同时受舒适性等指标约束。
自动驾驶技术-环境感知篇:基于视觉相关技术介绍
01 概述
在前面的文章介绍了环境感知中不同雷达的作用,一个标准的自动驾驶解决方案需要雷达与视觉技术的配合使用。视觉技术其实是仿生理学的解决方案,因为现实世界中司机驾驶车辆就是依靠视觉去做行车过程中的决策。
在本文会介绍下车载摄像头的基础知识以及视觉算法的基本原理,另外还会对自动驾驶视觉技术的几大经典场景做一个介绍。
02 车载摄像头介绍
从硬件成本分析,车载摄像头是技术相对成熟而成本最低的的一种方案。使用车载摄像头的缺点主要是后续数据的分析,需要依赖大量的标注数据和模型训练资源去训练成熟的用于自动驾驶的各种机器学习相关模型。

常见的车载摄像头功能如下表所示:
| 辅助驾驶功能 | 使用的摄像头类型 | 功能简介 |
| 车道偏离预警(LDW) | 前视 | 车道线检测,当车行驶偏离的时候报警 |
| 前向碰撞预警(FCW) | 前视 | 当车与前车过近时,会预警 |
| 交通标识识别(TSR) | 前视、侧视 | 识别当前道路两侧的标识 |
| 车道保持辅助(LKA) | 前视 | 车偏离轨道,会自动纠正方向 |
| 行人碰撞预警(PCW) | 前视 | 当摄像头识别出行人的时候,需要预警 |
| 盲点监视(BSD) | 侧视 | 利用侧视摄像头找到盲区影像,显示在驾驶舱屏幕 |
| 全景泊车(SVP) | 前视、后视、侧视 | 利用车辆前后摄像头获取的影像和图像拼接技术,输出车辆周边的全景图 |
| 泊车辅助(PA) | 后视 | 泊车时。显示倒车轨迹,方便驾驶员泊车 |
| 驾驶员注意力监测 | 内置 | 检测驾驶员闭眼等行为 |
(1)单目摄像头VS双目摄像头
常见的摄像头分为单目和双目两种摄像头,未来的自动驾驶技术将大概率以单目摄像头为主。
单目摄像头工作流程同样遵循图像输入、预处理、特征提取、特征分类、匹配、完成识别几个步骤,其测距原理是先匹配识别后估算距离:通过图像匹配识别出目标类别,随后根据图像大小估算距离。

单目摄像头的内容分析可以通过经典的深度学习算法实现。
双目摄像头测距原理与人眼类似,通过对图像视差进行计算,直接对前方景物进行距离测量;从视差的大小倒推出物体的距离,视差越大,距离越近;
双目测距步骤:相机标定 —— 双目校正 —— 双目匹配 —— 计算深度信息(测距)。
(2)摄像头的标定
与雷达相似,摄像头也需要做标定,需要把世界坐标系、摄像头坐标系、摄像头内的图像坐标和像素坐标做统一标定,这样识别出来的内容才可以正确的应用到自动驾驶流程中。
因为摄像头拍摄的图像是二维的,而真实世界是三维的,需要通过算法将二维空间的信息转换为三维。类似于下图这种方案:
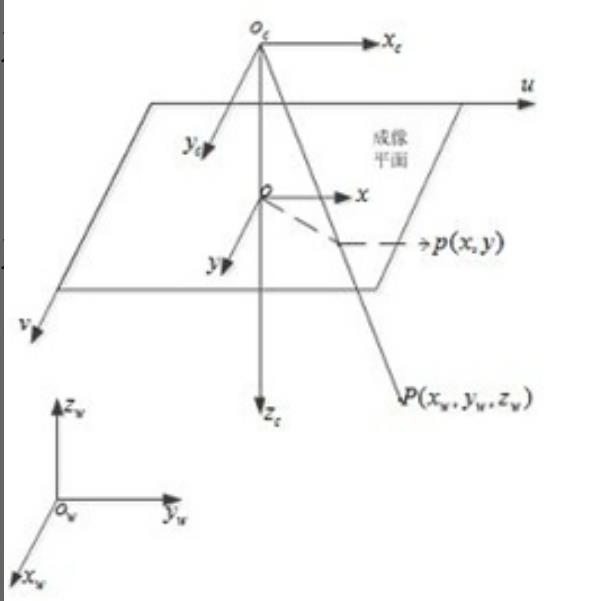
03 视觉算法基本原理
既然摄像头识别对象是依赖深度学习算法,那么视觉相关算法的基本原理也需要大致介绍下。目前各种车载自动驾驶摄像头里面用的图像识别类算法基本上都是CNN的结构,就是卷积神经网络。
卷积神经网络在认知图像的过程其实跟人大脑认知图像的原理类似。大脑识别图像的过程其实是将图片在人脑的各级神经元抽象成各种小的元素,比如棱角、直线等等,然后将这些元素所在的神经突触激活,最终信息传导下去形成认知。卷积神经网络模仿了这种图像识别的流程,通过卷积的各层将图像全部细节元素识别出来,形成最终的认知。

一个标准的CNN的网络结构如图所示:
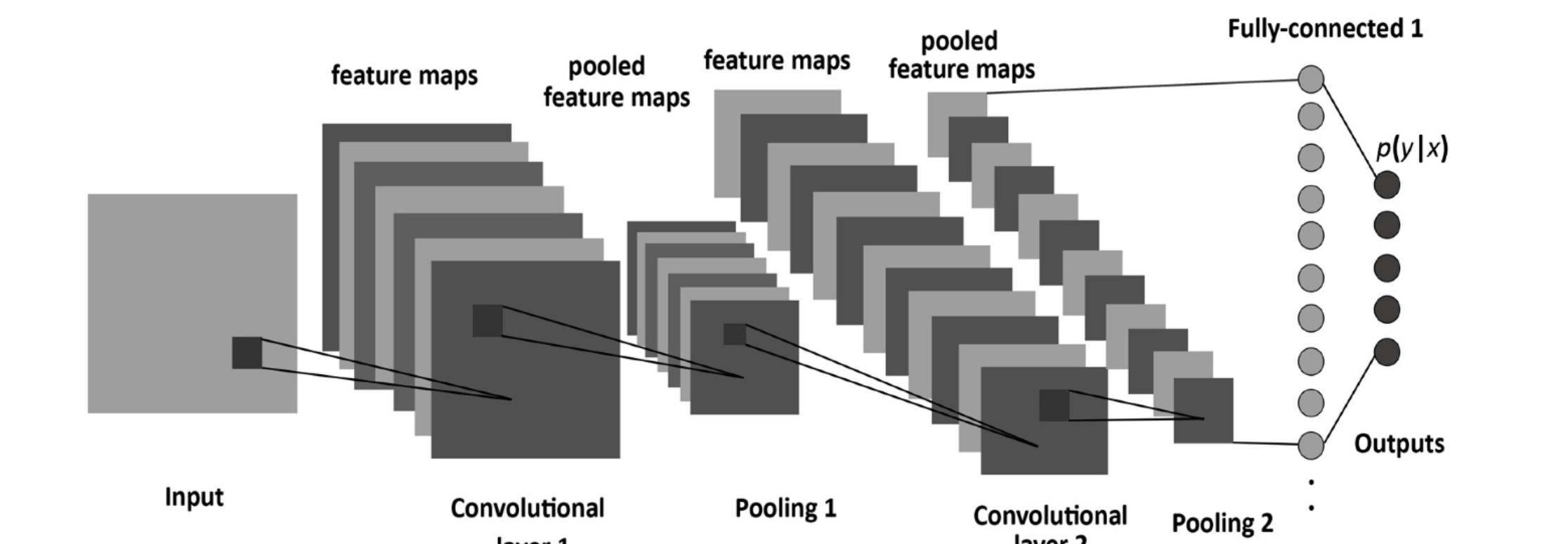
是由很多的层组成的,有卷积层、池化层、全连接层组成。每一层对应很多小的feature maps,feature maps有宽度和高度,可以对应到图像的宽和高。
在卷积神经网络中各个层都有不同的功能。
(1)卷积层
卷积层是CNN中的核心层,卷积层核心是一个滤波器。比如原始图像的像素是32*32,那么卷积层可以做一个5*5的滤波器,去扫描整个图像,抽取出各个原子部分的信息。
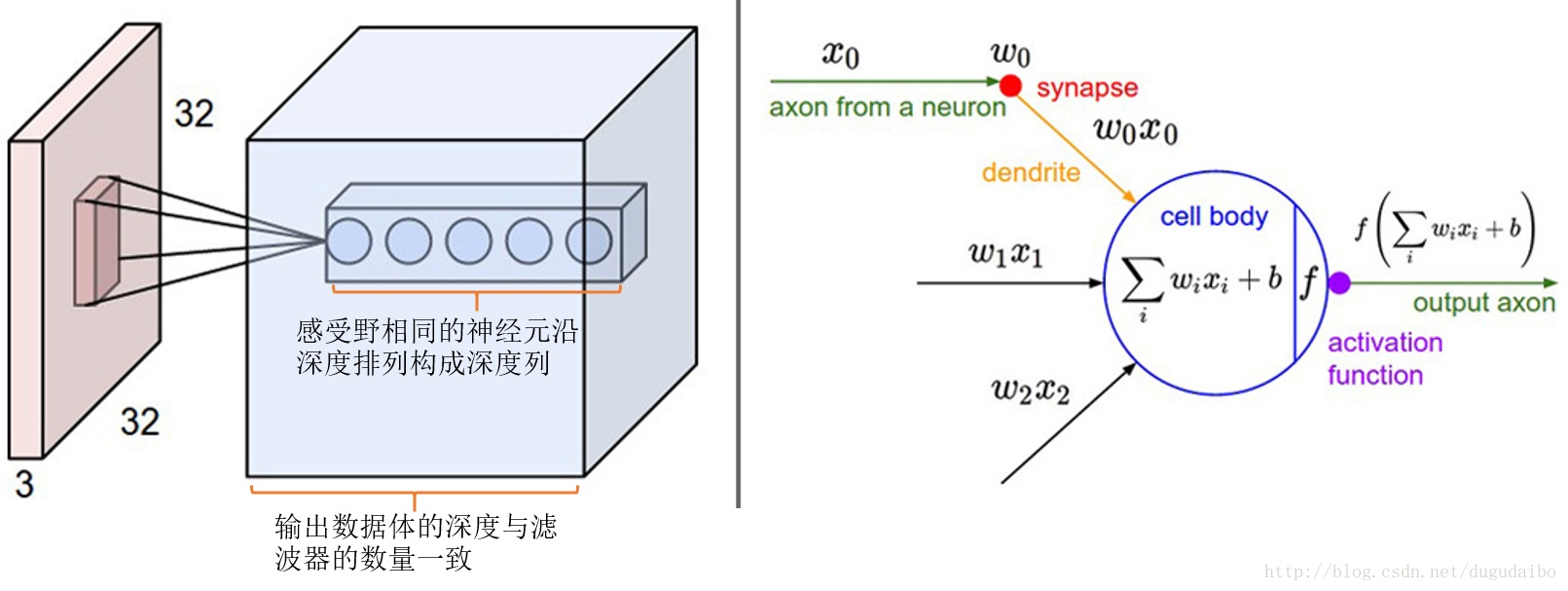
假设5*5的卷积滤波的深度是3,那么一个卷积核就包含了5*5*3=75个权重值,这些个卷积的权重值就是模型训练过程中要学习的。
(2)池化层
接下来介绍下池化层,如果没有池化层,一个5*5深度是3的卷积核,就要有75个参数,整个卷积神经网络由无数个卷积核组成,那么总的模型参数会爆炸。
在卷积层之间补充池化层的作用是减少参数的个数,另外也是减少整体训练过程中的计算量。池化的方案有很多,比如在max-pooling中可以只挑选每个2*2的小方格中最大的cell值。

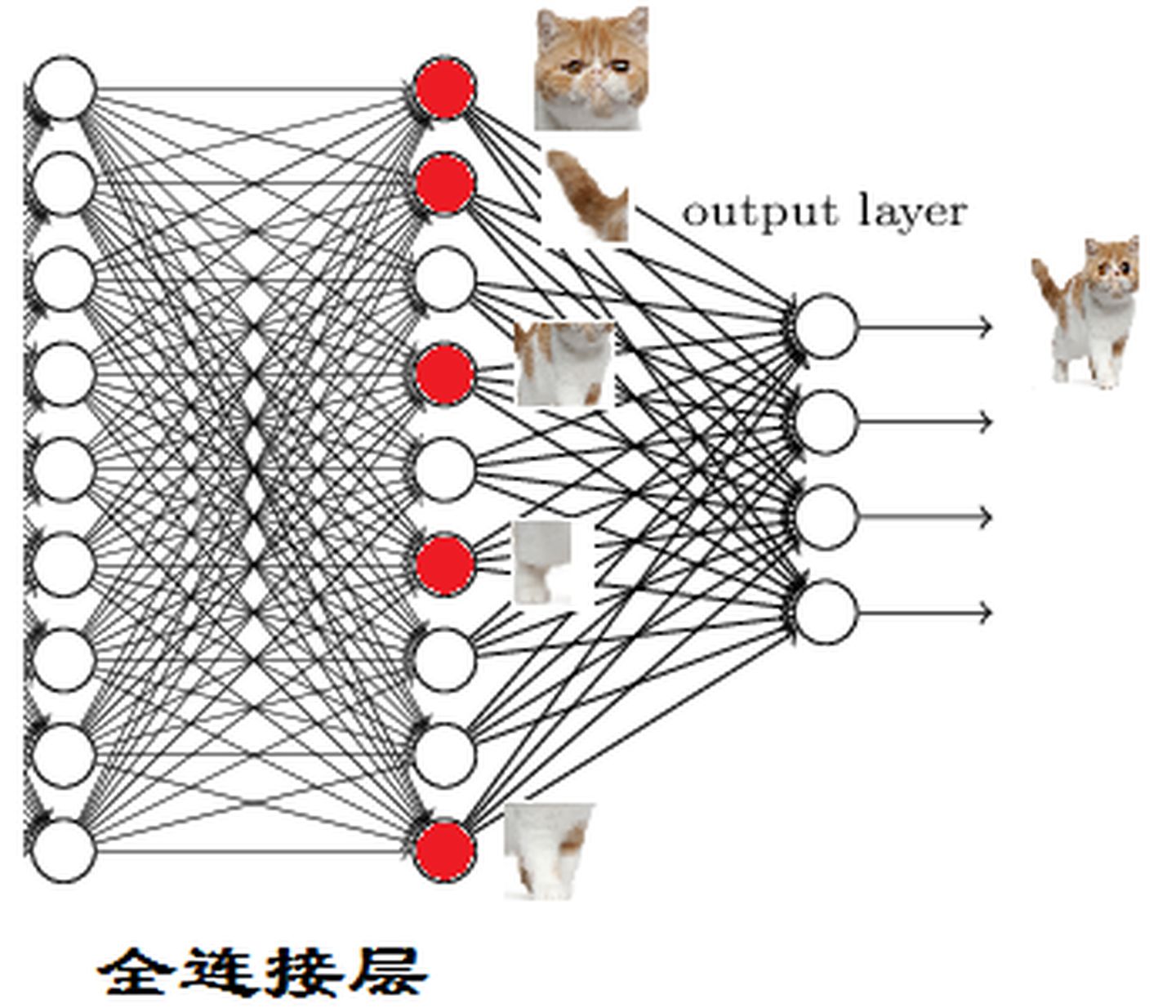
(3)全连接层
全连接层的主要作用就是分类,假设知道具备猫的眼睛、尾巴这些元素就能识别出猫。
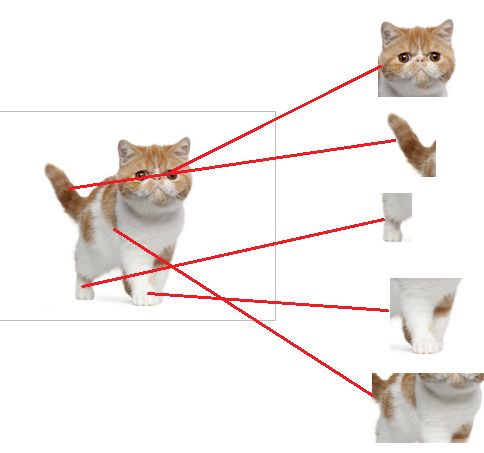
全连接层一般作为整个神经网络的最后一层,将关键要素激活,最终帮助网络判断出最终的结果。
04 视觉技术的基本场景
目前视觉技术在自动驾驶领域的识别主要分以下几个核心场景,分别是雷达云图的识别、行驶途中障碍物的识别、行驶区域的识别、交通标识的识别以及光流识别。
(1)雷达云图识别
上一篇文章介绍过,激光雷达会通过雷达波将行驶过程中道路信息的云图绘制出来。

图像识别技术可以基于这种云图找出道路轨迹、车辆等信息,从而做驾驶决策。
(2)障碍物识别

通过摄像头捕获实时视频流,然后通过CNN模型可以实时对视频流图像进行识别,然后指导驾驶决策。
(3)行驶区域识别
形势区域识别主要解决的问题是对车道线进行识别,并且标记出继续前行的方向。

(4)交通牌识别
如果说车道线识别和障碍物识别还可以通过雷达做补强,那么交通牌识别是只有视觉技术配合摄像头可以解决的问题。自动驾驶过程中需要配合摄像头找到每个标识牌的内容,比如限速、红绿灯识别、禁行标识等。

交通牌识别的技术问题是交通标识物通常并不出现在视频的主要方位,一般只在视频的边缘位置占据很小的一块区域,所以要通过特殊的图像分割技术解决。
(5)光流识别
光流指的是图像中每个像素点的二维瞬时速度,通常来讲就是图像中每个像素点在图中的移动速度。通过光流识别可以清楚的判断道路中的人、车辆的行驶速度。
光流是可以通过图像可视化的,如下图:

左边是输入的移动的图像,右边是转化为光流的表视图,可以通过不同的颜色标识不同的运动方向,通过深浅标识局部的速度。

基于光流场景有专业的FlowNet网络,也是一种基于卷积神经网络的变种。
以上是关于自动驾驶技术基本知识介绍的主要内容,如果未能解决你的问题,请参考以下文章