数字图像处理--车牌识别
Posted MZYYZT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数字图像处理--车牌识别相关的知识,希望对你有一定的参考价值。
数字图像处理–车牌识别
主要内容
实现车牌识别
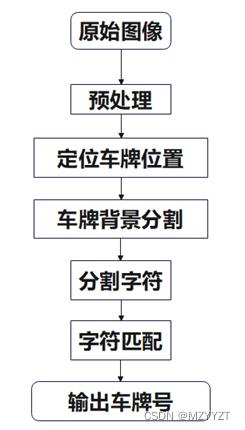
算法流程
本文中,车牌识别具体流程设计以及算法使用主要分为以下几步。
1、读取源车牌图像。
2、对原始车牌图像进行预处理:灰度化,运用基于几何运算的滤波器(开运算)消除毛刺噪声。
3、二值化操作。
4、利用canny边缘检测算法消除小的区域保留大的区域。
5、通过颜色识别判断定位车牌位置。
6、利用掩膜处理对定位车牌后的图像进行分割,直接分割出车牌。
7、再次对车牌进行二值化处理。
8、分割字符。
9、对分割字符进行神经网络模型匹配,输出车牌字符串。
针对上述实验设计步骤,做出实验流程图,如下图所示。
源代码
上代码
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import font_manager
import ddddocr
#读取字体文件
font = font_manager.FontProperties(fname=r".\\OPPOSans-Heavy.ttf")
class Get_license():
#图像拉伸函数
def stretch(self, img):
maxi = float(img.max())
mini = float(img.min())
for i in range(img.shape[0]):
for j in range(img.shape[1]):
img[i, j] = (255 / (maxi - mini) * img[i, j] - (255 * mini) / (maxi - mini))
return img
#二值化处理函数
def dobinaryzation(self, img):
maxi = float(img.max())
mini = float(img.min())
x = maxi - ((maxi - mini) / 2)
#二值化,返回阈值ret和二值化操作后的图像thresh
ret, thresh = cv2.threshold(img, x, 255, cv2.THRESH_BINARY)
#返回二值化后的黑白图像
return thresh
#寻找矩形的轮廓
def find_rectangle(self, contour):
y, x = [],[]
for p in contour:
y.append(p[0][0])
x.append(p[0][1])
return [min(y), min(x), max(y), max(x)]
#定位车牌号
def locate_license(self, img, afterimg):
contours, hierarchy = cv2.findContours(img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
#找出最大的三个区域
block = []
for c in contours:
#找出轮廓的左上点和右下点
#由此计算它的面积和长度比
r = self.find_rectangle(c)
a = (r[2] - r[0]) * (r[3] - r[1]) #面积
s = (r[2] - r[0]) * (r[3] - r[1]) #长度比
block.append([r, a, s])
#选出面积最大的3个区域
block = sorted(block, key=lambda b: b[1])[-3:]
#使用颜色识别判断找出最像车牌的区域
maxweight, maxindex = 0, -1
for i in range(len(block)):
b = afterimg[block[i][0][1]:block[i][0][3], block[i][0][0]:block[i][0][2]]
#BGR转HSV
hsv = cv2.cvtColor(b, cv2.COLOR_BGR2HSV)
#蓝色车牌的范围
lower = np.array([100, 50, 50])
upper = np.array([140, 255, 255])
#根据阈值构建掩膜
mask = cv2.inRange(hsv, lower, upper)
#统计权值
w1 = 0
for m in mask:
w1 += m / 255
w2 = 0
for n in w1:
w2 += n
#选出最大权值的区域
if w2 > maxweight:
maxindex = i
maxweight = w2
return block[maxindex][0]
#预处理函数
def find_license(self, img):
m = 400 * img.shape[0] / img.shape[1]
#压缩图像
img = cv2.resize(img, (400, int(m)), interpolation=cv2.INTER_CUBIC)
#BGR转换为灰度图像
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#灰度拉伸
stretchedimg = self.stretch(gray_img)
'''进行开运算,用来去除噪声'''
r = 16
h = w = r * 2 + 1
kernel = np.zeros((h, w), np.uint8)
cv2.circle(kernel, (r, r), r, 1, -1)
#开运算
openingimg = cv2.morphologyEx(stretchedimg, cv2.MORPH_OPEN, kernel)
#获取差分图,两幅图像做差 cv2.absdiff('图像1','图像2')
strtimg = cv2.absdiff(stretchedimg, openingimg)
#图像二值化
binaryimg = self.dobinaryzation(strtimg)
#canny边缘检测
canny = cv2.Canny(binaryimg, binaryimg.shape[0], binaryimg.shape[1])
'''消除小的区域,保留大块的区域,从而定位车牌'''
#进行闭运算
kernel = np.ones((5, 19), np.uint8)
closingimg = cv2.morphologyEx(canny, cv2.MORPH_CLOSE, kernel)
#进行开运算
openingimg = cv2.morphologyEx(closingimg, cv2.MORPH_OPEN, kernel)
#再次进行开运算
kernel = np.ones((11, 5), np.uint8)
openingimg = cv2.morphologyEx(openingimg, cv2.MORPH_OPEN, kernel)
#消除小区域,定位车牌位置
rect = self.locate_license(openingimg, img)
return rect, img
#图像分割函数
def cut_license(self, afterimg, rect):
#转换为宽度和高度
rect[2] = rect[2] - rect[0]
rect[3] = rect[3] - rect[1]
rect_copy = tuple(rect.copy())
#创建掩膜
mask = np.zeros(afterimg.shape[:2], np.uint8)
#创建背景模型 大小只能为13*5,行数只能为1,单通道浮点型
bgdModel = np.zeros((1, 65), np.float64)
#创建前景模型
fgdModel = np.zeros((1, 65), np.float64)
#分割图像
cv2.grabCut(afterimg, mask, rect_copy, bgdModel, fgdModel, 5, cv2.GC_INIT_WITH_RECT)
mask2 = np.where((mask == 2) | (mask == 0), 0, 1).astype('uint8')
img_show = afterimg * mask2[:, :, np.newaxis]
#cv2.imshow('111',img_show)
return img_show
class Segmentation():
def __init__(self, cutimg):
#1、读取图像,并把图像转换为灰度图像并显示
# cutimg = cv2.imread("3.jpg") #读取图片
img_gray = cv2.cvtColor(cutimg, cv2.COLOR_BGR2GRAY) #转换了灰度化
#cv2.imshow('gray', img_gray) #显示图片
#cv2.waitKey(0)
#2、将灰度图像二值化,设定阈值是100
self.img_thre = img_gray
cv2.threshold(img_gray, 100, 255, cv2.THRESH_BINARY_INV, self.img_thre)
#cv2.waitKey(0)
#3、保存黑白图片
cv2.imwrite('thre_res.png', self.img_thre)
#4、分割字符
self.white = [] #记录每一列的白色像素总和
self.black = [] #黑色
self.height = self.img_thre.shape[0]
self.width = self.img_thre.shape[1]
self.white_max = 0
self.black_max = 0
#计算每一列的黑白色像素总和
for i in range(self.width):
s = 0 #这一列白色总数
t = 0 #这一列黑色总数
for j in range(self.height):
if self.img_thre[j][i] == 255:
s += 1
if self.img_thre[j][i] == 0:
t += 1
self.white_max = max(self.white_max, s)
self.black_max = max(self.black_max, t)
self.white.append(s)
self.black.append(t)
self.arg = False #False表示白底黑字;True表示黑底白字
if self.black_max > self.white_max:
self.arg = True
def heibai(self):
return self.img_thre
def find_end(self, start_):
end_ = start_ + 1
for m in range(start_ + 1, self.width - 1):
if (self.black[m] if self.arg else self.white[m]) > (
0.85 * self.black_max if self.arg else 0.85 * self.white_max):
end_ = m
break
return end_
def display(self):
#img_list = []
n = 1
plt.figure()
img_num = 0
while n < self.width - 2:
n += 1
if (self.white[n] if self.arg else self.black[n]) > (
0.15 * self.white_max if self.arg else 0.15 * self.black_max):
#上面这些判断用来辨别是白底黑字还是黑底白字
start = n
end = self.find_end(start)
n = end
if end - start > 5:
cj = self.img_thre[1:self.height, start:end]
img_num += 1
cj = cv2.cvtColor(cj, cv2.COLOR_RGB2BGR)
plt.figure(2)
plt.subplot(2, 4, img_num)
plt.title(''.format(img_num))
plt.imshow(cj)
plt.show()
return self.img_thre
if __name__ == '__main__':
#读取源图像
img = cv2.imread('8.png')
img1 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
#绘图
plt.figure(1)
plt.suptitle('车牌识别',fontproperties=font)
plt.subplot(2, 3, 1)
plt.title('原始图像', fontproperties=font)
plt.imshow(img1)
#预处理图像
license = Get_license()
rect, afterimg = license.find_license(img)
afterimg = cv2.cvtColor(afterimg, cv2.COLOR_RGB2BGR)
plt.subplot(2, 3, 2)
plt.title('预处理后图像', fontproperties=font)
plt.imshow(afterimg)
#车牌号打框
cv2.rectangle(afterimg, (rect[0], rect[1]), (rect[2], rect[3]), (0, 255, 0), 1)
x1, y1, x2, y2 = int(rect[0]), int(rect[1]), int(rect[2]), int(rect[3])
print('车牌框出:',x1, x2, y1, y2)
plt.subplot(2, 3, 3)
plt.title('车牌框出', fontproperties=font)
plt.imshow(afterimg)
#背景去除
cutimg = license.cut_license(afterimg, rect)
plt.subplot(2, 3, 4)
plt.title('车牌背景去除', fontproperties=font)
plt.imshow(cutimg)
# print(int(_rect[0]), int(_rect[3]), int(_rect[2]), int(_rect[1]))
print('车牌背景去除',x1, y1, x2, y2)
#开始分割车牌
# cutimg = cutimg[140:165, 151:240]
cutimg = cutimg[y1 + 3:y2 - 3, x1 - 1:x2 - 3]
# cutimg = cutimg[int(_rect[0]):int(_rect[3]),int(_rect[2]):int(_rect[1])]
print('cutimg:',cutimg)
height, width = cutimg.shape[:2]
cutimg1 = cv2.resize(cutimg, (2 * width, 2 * height), interpolation=cv2.INTER_CUBIC)
plt.subplot(2, 3, 5)
plt.title('分割车牌与背景', fontproperties=font)
plt.imshow(cutimg)
#字符切割
seg = Segmentation(cutimg)
plt.subplot(2, 3, 6)
img_hei = seg.heibai()
img_hei = cv2.cvtColor(img_hei, cv2.COLOR_RGB2BGR)
plt.title('车牌二值化处理', fontproperties=font)
plt.imshow(img_hei)
seg.display()
plt.show()
#打印车牌
ocr = ddddocr.DdddOcr()
with open('thre_res.png', 'rb') as f:
image = f.read()
res = ocr.classification(image)
print(res)
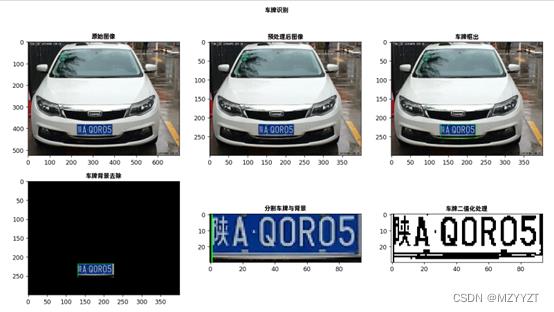
实现结果
选取车牌照片,成功完成了对车牌号码的识别。如下图所示,即是原始图像到最后分割车牌与背景后的图片显示。
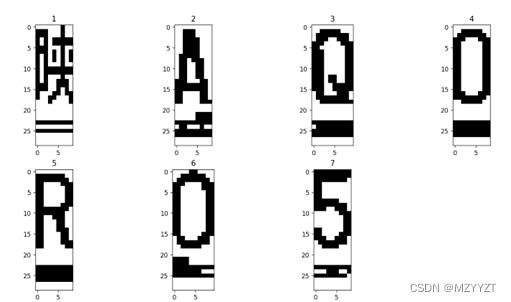
接着,对二值化处理过后的图片进行字符分割,所得结果如下图所示。
最后,通过利用ddddocr图片识别库对每个字符进行匹配。从而,实现字符图片到文本转换,成功打印输出车牌号码。

注意:选取其他照片后,可能需要微调代码里面 (车牌号打框)的参数值。就是图片局限性有点大。希望后续有小伙伴提出更泛化的代码实现!!!
以上是关于数字图像处理--车牌识别的主要内容,如果未能解决你的问题,请参考以下文章