C 语言基础,来喽
Posted 程序员cxuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C 语言基础,来喽相关的知识,希望对你有一定的参考价值。
大家好,我是程序员cxuan!今天和大家一起学习C 语言基础!
前言
C 语言是一门抽象的、面向过程的语言,C 语言广泛应用于底层开发,C 语言在计算机体系中占据着不可替代的作用,可以说 C 语言是编程的基础,也就是说,不管你学习任何语言,都应该把 C 语言放在首先要学的位置上。下面这张图更好的说明 C 语言的重要性

可以看到,C 语言是一种底层语言,是一种系统层级的语言,操作系统就是使用 C 语言来编写的,比如 Windows、Linux、UNIX 。如果说其他语言是光鲜亮丽的外表,那么 C 语言就是灵魂,永远那么朴实无华。
C 语言特性
那么,既然 C 语言这么重要,它有什么值得我们去学的地方呢?我们不应该只因为它重要而去学,我们更在意的是学完我们能学会什么,能让我们获得什么。
C 语言的设计
C 语言是 1972 年,由贝尔实验室的丹尼斯·里奇(Dennis Ritch)和肯·汤普逊(Ken Thompson)在开发 UNIX 操作系统时设计了C语言。C 语言是一门流行的语言,它把计算机科学理论和工程实践理论完美的融合在一起,使用户能够完成模块化的编程和设计。
计算机科学理论:简称 CS、是系统性研究信息与计算的理论基础以及它们在计算机系统中如何实现与应用的实用技术的学科。
C 语言具有高效性
C 语言是一门高效性语言,它被设计用来充分发挥计算机的优势,因此 C 语言程序运行速度很快,C 语言能够合理了使用内存来获得最大的运行速度
C 语言具有可移植性
C 语言是一门具有可移植性的语言,这就意味着,对于在一台计算机上编写的 C 语言程序可以在另一台计算机上轻松地运行,从而极大的减少了程序移植的工作量。
C 语言特点
- C 语言是一门简洁的语言,因为 C 语言设计更加靠近底层,因此不需要众多 Java 、C# 等高级语言才有的特性,程序的编写要求不是很严格。
- C 语言具有结构化控制语句,C 语言是一门结构化的语言,它提供的控制语句具有结构化特征,如 for 循环、if⋯ else 判断语句和 switch 语句等。
- C 语言具有丰富的数据类型,不仅包含有传统的字符型、整型、浮点型、数组类型等数据类型,还具有其他编程语言所不具备的数据类型,比如指针。
- C 语言能够直接对内存地址进行读写,因此可以实现汇编语言的主要功能,并可直接操作硬件。
- C 语言速度快,生成的目标代码执行效率高。
下面让我们通过一个简单的示例来说明一下 C 语言
入门级 C 语言程序
下面我们来看一个很简单的 C 语言程序,我觉得工具无所谓大家用着顺手就行。
第一个 C 语言程序
#include <stdio.h>
int main(int argc, const char * argv[])
printf("Hello, World!\\n");
printf("my Name is cxuan \\n")
printf("number = %d \\n", number);
return 0;
你可能不知道这段代码是什么意思,不过别着急,我们先运行一下看看结果。
这段程序输出了 Hello,World! 和 My Name is cxuan,下面我们解释一下各行代码的含义。
首先,第一行的 #include <stdio.h>, 这行代码包含另一个文件,这一行告诉编译器把 stdio.h 的内容包含在当前程序中。 stdio.h 是 C 编译器软件包的标准部分,它能够提供键盘输入和显示器输出。
什么是 C 标准软件包?C 是由 Dennis M 在1972年开发的通用,过程性,命令式计算机编程语言。C标准库是一组 C 语言内置函数,常量和头文件,例如<stdio.h>,<stdlib.h>,<math.h>等。此库将用作 C 程序员的参考手册。
我们后面会介绍 stdio.h ,现在你知道它是什么就好。
在 stdio.h 下面一行代码就是 main 函数。
C 程序能够包含一个或多个函数,函数是 C 语言的根本,就和方法是 Java 的基本构成一样。main() 表示一个函数名,int 表示的是 main 函数返回一个整数。void 表明 main() 不带任何参数。这些我们后面也会详细说明,只需要记住 int 和 void 是标准 ANSI C 定义 main() 的一部分(如果使用 ANSI C 之前的编译器,请忽略 void)。
然后是 /*一个简单的 C 语言程序*/ 表示的是注释,注释使用 /**/ 来表示,注释的内容在两个符号之间。这些符号能够提高程序的可读性。
注意:注释只是为了帮助程序员理解代码的含义,编译器会忽略注释
下面就是 ,这是左花括号,它表示的是函数体的开始,而最后的右花括号 表示函数体的结束。 中间是书写代码的地方,也叫做代码块。
int number 表示的是将会使用一个名为 number 的变量,而且 number 是 int 整数类型。
number = 11 表示的是把值 11 赋值给 number 的变量。
printf(Hello,world!\\n); 表示调用一个函数,这个语句使用 printf() 函数,在屏幕上显示 Hello,world , printf() 函数是 C 标准库函数中的一种,它能够把程序运行的结果输出到显示器上。而代码 \\n 表示的是 换行,也就是另起一行,把光标移到下一行。
然后接下来的一行 printf() 和上面一行是一样的,我们就不多说了。最后一行 printf() 有点意思,你会发现有一个 %d 的语法,它的意思表示的是使用整形输出字符串。
代码块的最后一行是 return 0,它可以看成是 main 函数的结束,最后一行是代码块 ,它表示的是程序的结束。
好了,我们现在写完了第一个 C 语言程序,有没有对 C 有了更深的认识呢?肯定没有。。。这才哪到哪,继续学习吧。
现在,我们可以归纳为 C 语言程序的几个组成要素,如下图所示
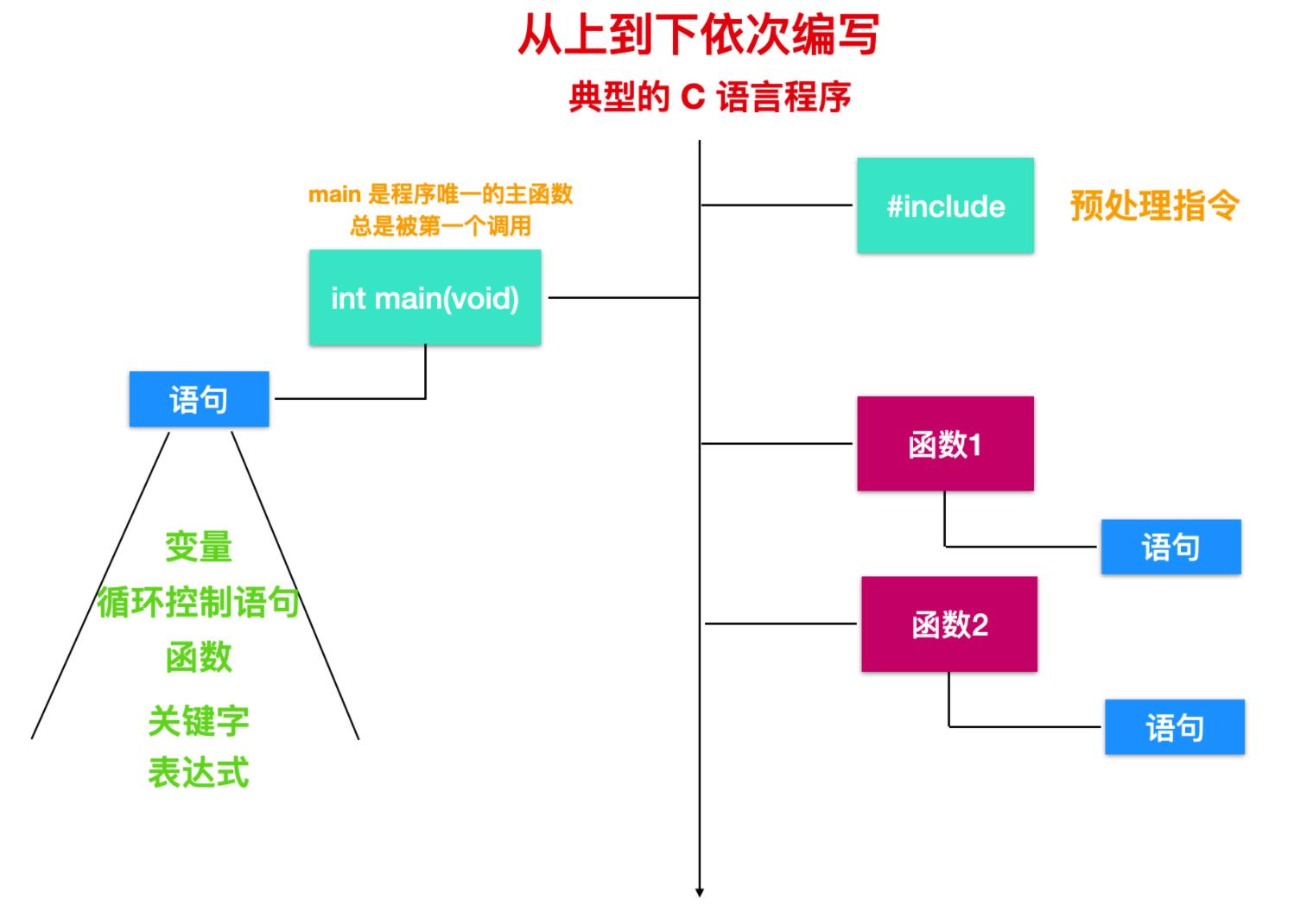
C 语言执行流程
C 语言程序成为高级语言的原因是它能够读取并理解人们的思想。然而,为了能够在系统中运行 hello.c 程序,则各个 C 语句必须由其他程序转换为一系列低级机器语言指令。这些指令被打包作为可执行对象程序,存储在二进制磁盘文件中。目标程序也称为可执行目标文件。
在 UNIX 系统中,从源文件到对象文件的转换是由编译器执行完成的。
gcc -o hello hello.c
gcc 编译器驱动从源文件读取 hello.c ,并把它翻译成一个可执行文件 hello。这个翻译过程可用如下图来表示
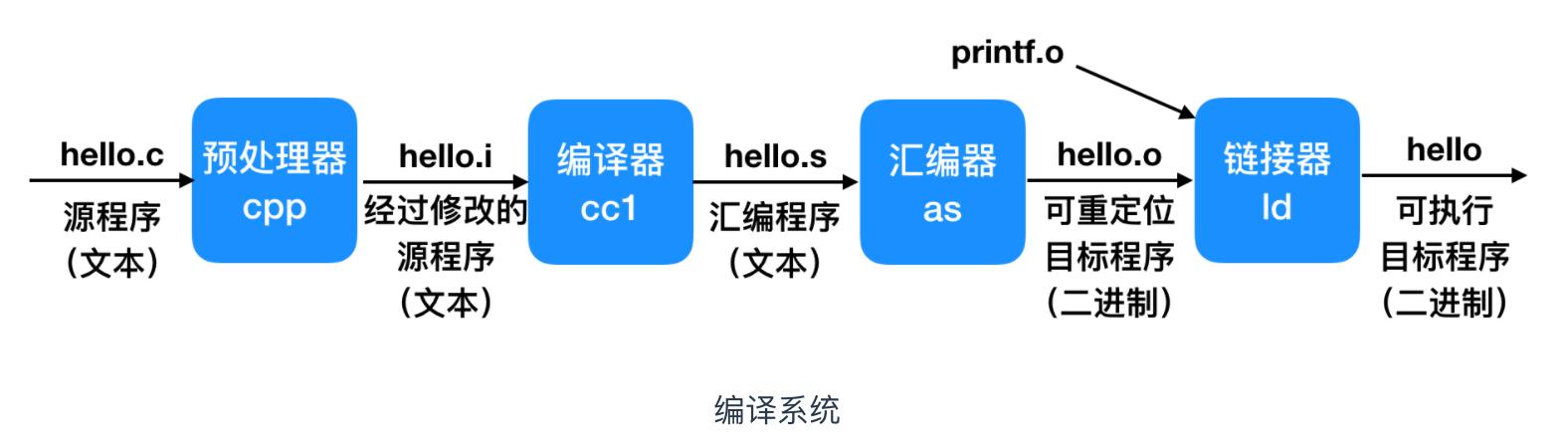
这就是一个完整的 hello world 程序执行过程,会涉及几个核心组件:预处理器、编译器、汇编器、连接器,下面我们逐个击破。
-
预处理阶段(Preprocessing phase),预处理器会根据开始的#字符,修改源 C 程序。#include <stdio.h> 命令就会告诉预处理器去读系统头文件stdio.h中的内容,并把它插入到程序作为文本。然后就得到了另外一个 C 程序hello.i,这个程序通常是以.i为结尾。 -
然后是
编译阶段(Compilation phase),编译器会把文本文件hello.i翻译成文本hello.s,它包括一段汇编语言程序(assembly-language program)。 -
编译完成之后是
汇编阶段(Assembly phase),这一步,汇编器 as会把 hello.s 翻译成机器指令,把这些指令打包成可重定位的二进制程序(relocatable object program)放在 hello.c 文件中。它包含的 17 个字节是函数 main 的指令编码,如果我们在文本编辑器中打开 hello.o 将会看到一堆乱码。 -
最后一个是
链接阶段(Linking phase),我们的 hello 程序会调用printf函数,它是 C 编译器提供的 C 标准库中的一部分。printf 函数位于一个叫做printf.o文件中,它是一个单独的预编译好的目标文件,而这个文件必须要和我们的 hello.o 进行链接,连接器(ld)会处理这个合并操作。结果是,hello 文件,它是一个可执行的目标文件(或称为可执行文件),已准备好加载到内存中并由系统执行。
你需要理解编译系统做了什么
对于上面这种简单的 hello 程序来说,我们可以依赖编译系统(compilation system)来提供一个正确和有效的机器代码。然而,对于我们上面讲的程序员来说,编译器有几大特征你需要知道
优化程序性能(Optimizing program performance),现代编译器是一种高效的用来生成良好代码的工具。对于程序员来说,你无需为了编写高质量的代码而去理解编译器内部做了什么工作。然而,为了编写出高效的 C 语言程序,我们需要了解一些基本的机器码以及编译器将不同的 C 语句转化为机器代码的过程。理解链接时出现的错误(Understanding link-time errors),在我们的经验中,一些非常复杂的错误大多是由链接阶段引起的,特别是当你想要构建大型软件项目时。避免安全漏洞(Avoiding security holes),近些年来,缓冲区溢出(buffer overflow vulnerabilities)是造成网络和 Internet 服务的罪魁祸首,所以我们有必要去规避这种问题。
系统硬件组成
为了理解 hello 程序在运行时发生了什么,我们需要首先对系统的硬件有一个认识。下面这是一张 Intel 系统产品的模型,我们来对其进行解释
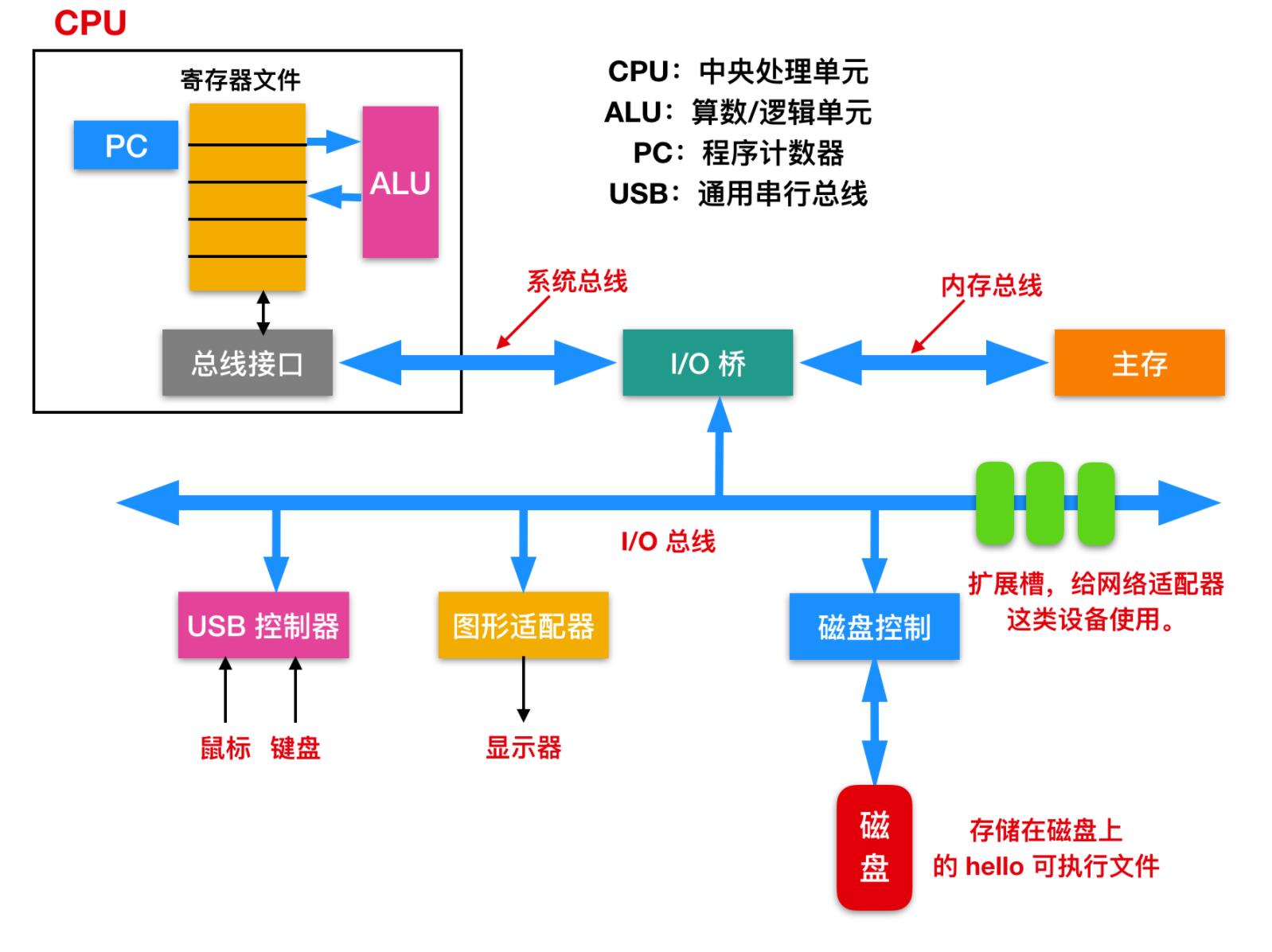
总线(Buses):在整个系统中运行的是称为总线的电气管道的集合,这些总线在组件之间来回传输字节信息。通常总线被设计成传送定长的字节块,也就是字(word)。字中的字节数(字长)是一个基本的系统参数,各个系统中都不尽相同。现在大部分的字都是 4 个字节(32 位)或者 8 个字节(64 位)。
-
I/O 设备(I/O Devices):Input/Output 设备是系统和外部世界的连接。上图中有四类 I/O 设备:用于用户输入的键盘和鼠标,用于用户输出的显示器,一个磁盘驱动用来长时间的保存数据和程序。刚开始的时候,可执行程序就保存在磁盘上。每个I/O 设备连接 I/O 总线都被称为
控制器(controller)或者是适配器(Adapter)。控制器和适配器之间的主要区别在于封装方式。控制器是 I/O 设备本身或者系统的主印制板电路(通常称作主板)上的芯片组。而适配器则是一块插在主板插槽上的卡。无论组织形式如何,它们的最终目的都是彼此交换信息。 -
主存(Main Memory),主存是一个临时存储设备,而不是永久性存储,磁盘是永久性存储的设备。主存既保存程序,又保存处理器执行流程所处理的数据。从物理组成上说,主存是由一系列DRAM(dynamic random access memory)动态随机存储构成的集合。逻辑上说,内存就是一个线性的字节数组,有它唯一的地址编号,从 0 开始。一般来说,组成程序的每条机器指令都由不同数量的字节构成,C 程序变量相对应的数据项的大小根据类型进行变化。比如,在 Linux 的 x86-64 机器上,short 类型的数据需要 2 个字节,int 和 float 需要 4 个字节,而 long 和 double 需要 8 个字节。 -
处理器(Processor),CPU(central processing unit)或者简单的处理器,是解释(并执行)存储在主存储器中的指令的引擎。处理器的核心大小为一个字的存储设备(或寄存器),称为程序计数器(PC)。在任何时刻,PC 都指向主存中的某条机器语言指令(即含有该条指令的地址)。从系统通电开始,直到系统断电,处理器一直在不断地执行程序计数器指向的指令,再更新程序计数器,使其指向下一条指令。处理器根据其指令集体系结构定义的指令模型进行操作。在这个模型中,指令按照严格的顺序执行,执行一条指令涉及执行一系列的步骤。处理器从程序计数器指向的内存中读取指令,解释指令中的位,执行该指令指示的一些简单操作,然后更新程序计数器以指向下一条指令。指令与指令之间可能连续,可能不连续(比如 jmp 指令就不会顺序读取)
下面是 CPU 可能执行简单操作的几个步骤
-
加载(Load):从主存中拷贝一个字节或者一个字到内存中,覆盖寄存器先前的内容 -
存储(Store):将寄存器中的字节或字复制到主存储器中的某个位置,从而覆盖该位置的先前内容 -
操作(Operate):把两个寄存器的内容复制到ALU(Arithmetic logic unit)。把两个字进行算术运算,并把结果存储在寄存器中,重写寄存器先前的内容。
算术逻辑单元(ALU)是对数字二进制数执行算术和按位运算的组合数字电子电路。
跳转(jump):从指令中抽取一个字,把这个字复制到程序计数器(PC)中,覆盖原来的值
剖析 hello 程序的执行过程
前面我们简单的介绍了一下计算机的硬件的组成和操作,现在我们正式介绍运行示例程序时发生了什么,我们会从宏观的角度进行描述,不会涉及到所有的技术细节
刚开始时,shell 程序执行它的指令,等待用户键入一个命令。当我们在键盘上输入了 ./hello 这几个字符时,shell 程序将字符逐一读入寄存器,再把它放到内存中,如下图所示
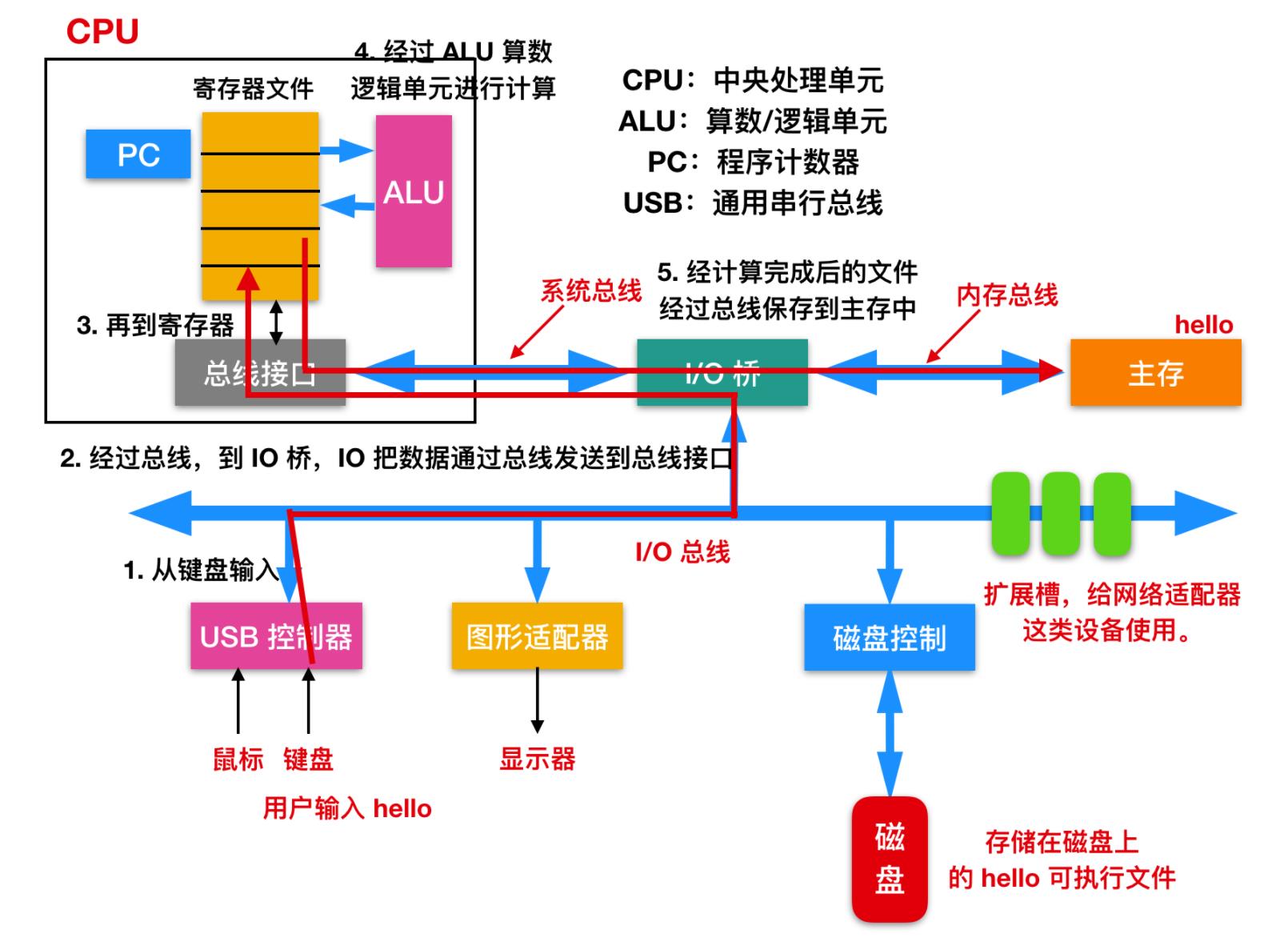
当我们在键盘上敲击回车键的时候,shell 程序就知道我们已经结束了命令的输入。然后 shell 执行一系列指令来加载可执行的 hello 文件,这些指令将目标文件中的代码和数据从磁盘复制到主存。
利用 DMA(Direct Memory Access) 技术可以直接将磁盘中的数据复制到内存中,如下
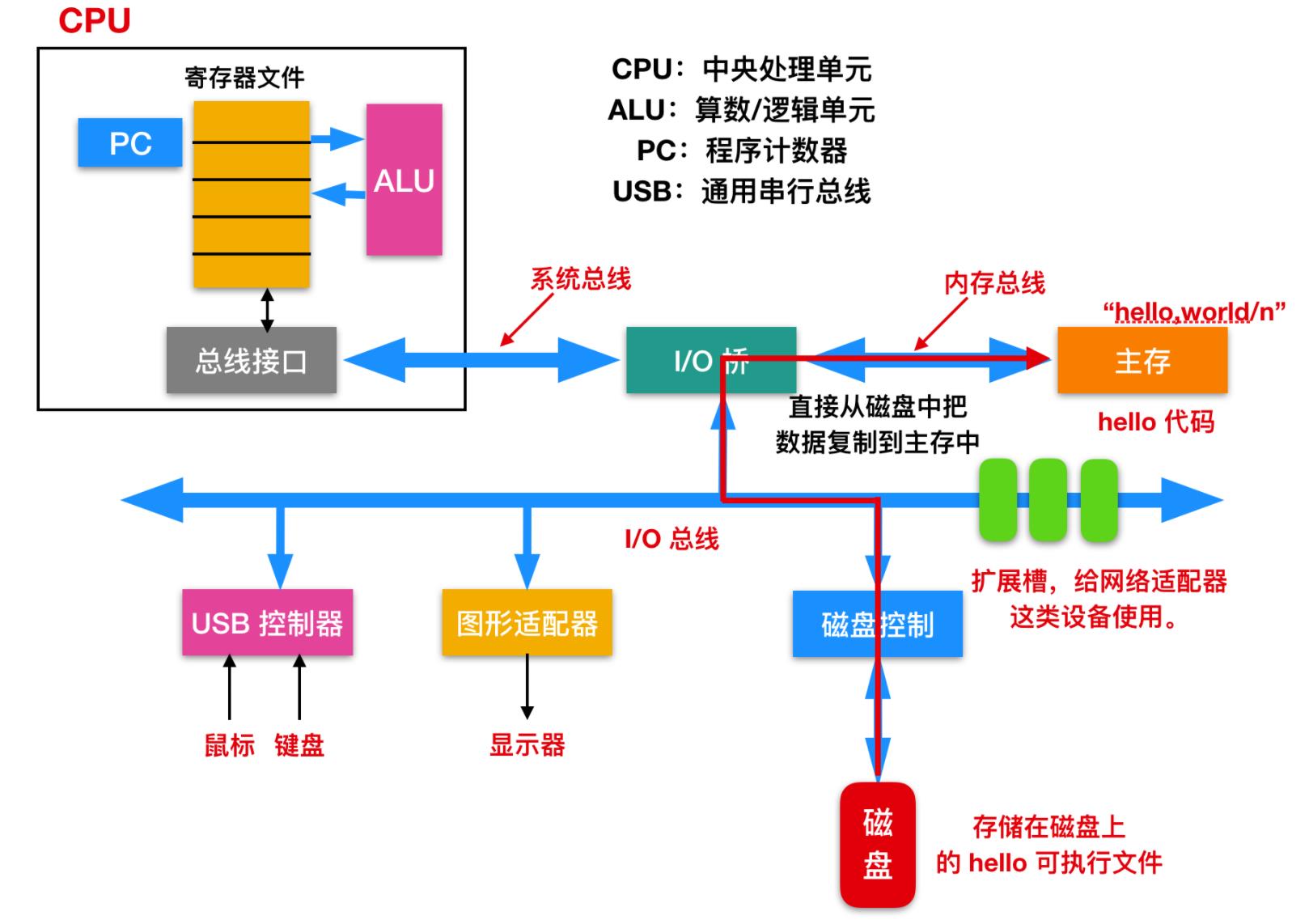
一旦目标文件中 hello 中的代码和数据被加载到主存,处理器就开始执行 hello 程序的 main 程序中的机器语言指令。这些指令将 hello,world\\n 字符串中的字节从主存复制到寄存器文件,再从寄存器中复制到显示设备,最终显示在屏幕上。如下所示
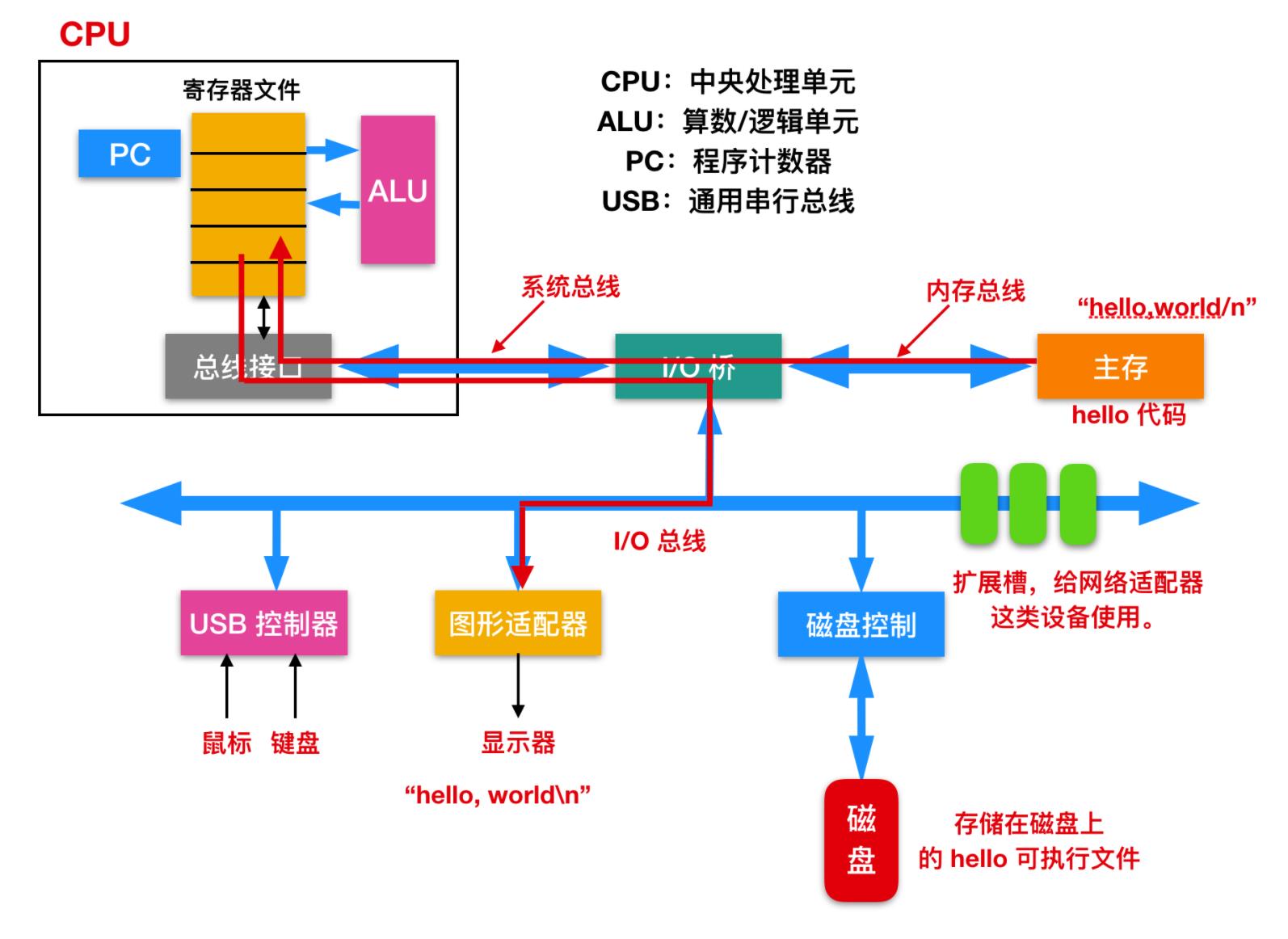
高速缓存是关键
上面我们介绍完了一个 hello 程序的执行过程,系统花费了大量时间把信息从一个地方搬运到另外一个地方。hello 程序的机器指令最初存储在磁盘上。当程序加载后,它们会拷贝到主存中。当 CPU 开始运行时,指令又从内存复制到 CPU 中。同样的,字符串数据 hello,world \\n 最初也是在磁盘上,它被复制到内存中,然后再到显示器设备输出。从程序员的角度来看,这种复制大部分是开销,这减慢了程序的工作效率。因此,对于系统设计来说,最主要的一个工作是让程序运行的越来越快。
由于物理定律,较大的存储设备要比较小的存储设备慢。而由于寄存器和内存的处理效率在越来越大,所以针对这种差异,系统设计者采用了更小更快的存储设备,称为高速缓存存储器(cache memory, 简称为 cache 高速缓存),作为暂时的集结区域,存放近期可能会需要的信息。如下图所示
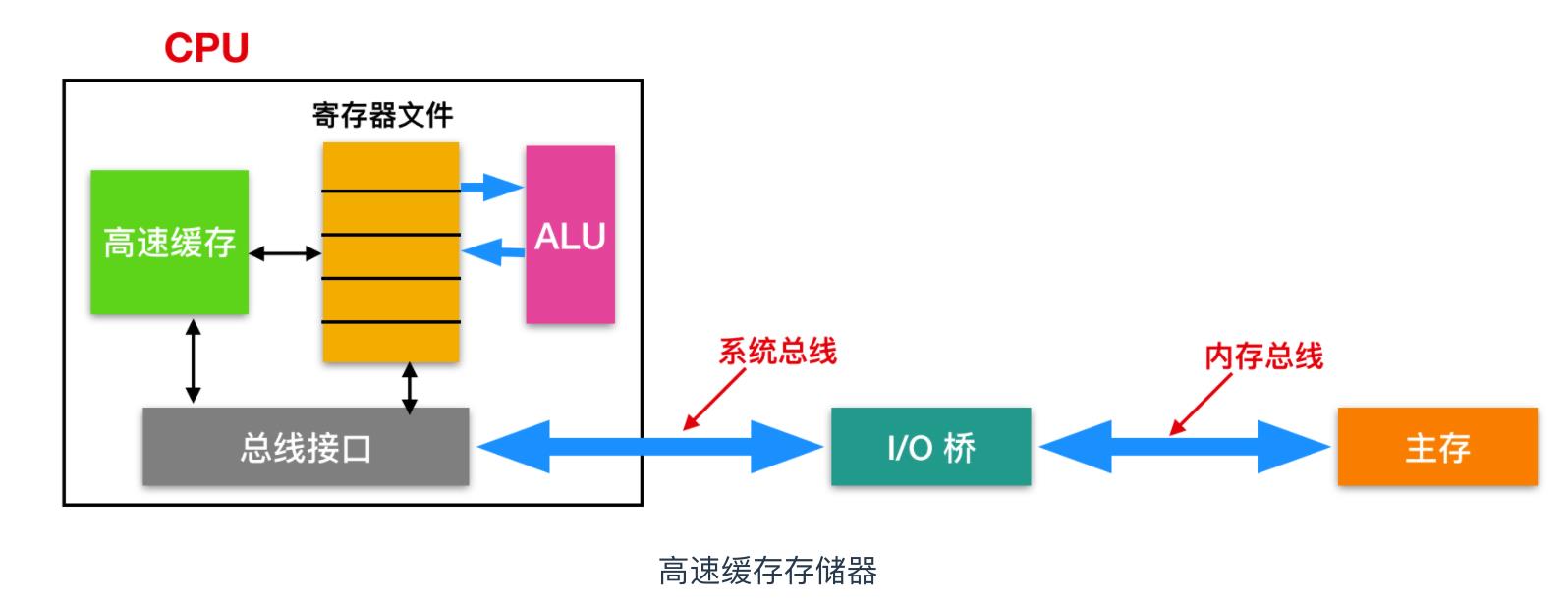
图中我们标出了高速缓存的位置,位于高速缓存中的 L1高速缓存容量可以达到数万字节,访问速度几乎和访问寄存器文件一样快。容量更大的 L2 高速缓存通过一条特殊的总线链接 CPU,虽然 L2 缓存比 L1 缓存慢 5 倍,但是仍比内存要哦快 5 - 10 倍。L1 和 L2 是使用一种静态随机访问存储器(SRAM) 的硬件技术实现的。最新的、处理器更强大的系统甚至有三级缓存:L1、L2 和 L3。系统可以获得一个很大的存储器,同时访问速度也更快,原因是利用了高速缓存的 局部性原理。
Again:入门程序细节
现在,我们来探讨一下入门级程序的细节,由浅入深的来了解一下 C 语言的特性。
#include<stdio.h>
我们上面说到,#include<stdio.h> 是程序编译之前要处理的内容,称为编译预处理命令。
预处理命令是在编译之前进行处理。预处理程序一般以 # 号开头。
所有的 C 编译器软件包都提供 stdio.h 文件。该文件包含了给编译器使用的输入和输出函数,比如 println() 信息。该文件名的含义是标准输入/输出 头文件。通常,在 C 程序顶部的信息集合被称为 头文件(header)。
C 的第一个标准是由 ANSI 发布的。虽然这份文档后来被国际标准化组织(ISO)采纳并且 ISO 发布的修订版也被 ANSI 采纳了,但名称 ANSI C(而不是 ISO C) 仍被广泛使用。一些软件开发者使用ISO C,还有一些使用 Standard C。
C 标准库
除了 <sdtio.h> 外,C 标准库还包括下面这些头文件

<assert.h>
提供了一个名为 assert 的关键字,它用于验证程序作出的假设,并在假设为假输出诊断消息。
<ctype.h>
C 标准库的 ctype.h 头文件提供了一些函数,可以用于测试和映射字符。
这些字符接受 int 作为参数,它的值必须是 EOF 或者是一个无符号字符
EOF是一个计算机术语,为 End Of File 的缩写,在操作系统中表示资料源无更多的资料可读取。资料源通常称为档案或串流。通常在文本的最后存在此字符表示资料结束。
<errno.h>
C 标准库的 errno.h 头文件定义了整数变量 errno,它是通过系统调用设置的,这些库函数表明了什么发生了错误。
<float.h>
C 标准库的 float.h 头文件包含了一组与浮点值相关的依赖于平台的常量。
<limits.h>
limits.h 头文件决定了各种变量类型的各种属性。定义在该头文件中的宏限制了各种变量类型(比如 char、int 和 long)的值。
<locale.h>
locale.h 头文件定义了特定地域的设置,比如日期格式和货币符号
<math.h>
math.h 头文件定义了各种数学函数和一个宏。在这个库中所有可用的功能都带有一个 double 类型的参数,且都返回 double 类型的结果。
<setjmp.h>
setjmp.h 头文件定义了宏 setjmp()、函数 longjmp() 和变量类型 jmp_buf,该变量类型会绕过正常的函数调用和返回规则。
<signal.h>
signal.h 头文件定义了一个变量类型 sig_atomic_t、两个函数调用和一些宏来处理程序执行期间报告的不同信号。
<stdarg.h>
stdarg.h 头文件定义了一个变量类型 va_list 和三个宏,这三个宏可用于在参数个数未知(即参数个数可变)时获取函数中的参数。
<stddef.h>
stddef .h 头文件定义了各种变量类型和宏。这些定义中的大部分也出现在其它头文件中。
<stdlib.h>
stdlib .h 头文件定义了四个变量类型、一些宏和各种通用工具函数。
<string.h>
string .h 头文件定义了一个变量类型、一个宏和各种操作字符数组的函数。
<time.h>
time.h 头文件定义了四个变量类型、两个宏和各种操作日期和时间的函数。
main() 函数
main 函数听起来像是调皮捣蛋的孩子故意给方法名起一个 主要的 方法,来告诉他人他才是这个世界的中心。但事实却不是这样,而 main() 方法确实是世界的中心。
C 语言程序一定从 main() 函数开始执行,除了 main() 函数外,你可以随意命名其他函数。通常,main 后面的 () 中表示一些传入信息,我们上面的那个例子中没有传递信息,因为圆括号中的输入是 void 。
除了上面那种写法外,还有两种 main 方法的表示方式,一种是 void main() ,一种是 int main(int argc, char* argv[])
- void main() 声明了一个带有不确定参数的构造方法
- int main(int argc, char* argv[]) 其中的 argc 是一个非负值,表示从运行程序的环境传递到程序的参数数量。它是指向 argc + 1 指针数组的第一个元素的指针,其中最后一个为null,而前一个(如果有的话)指向表示从主机环境传递给程序的参数的字符串。 如果argv [0]不是空指针(或者等效地,如果argc> 0),则指向表示程序名称的字符串,如果在主机环境中无法使用程序名称,则该字符串为空。
注释
在程序中,使用 /**/ 的表示注释,注释对于程序来说没有什么实际用处,但是对程序员来说却非常有用,它能够帮助我们理解程序,也能够让他人看懂你写的程序,我们在开发工作中,都非常反感不写注释的人,由此可见注释非常重要。

C 语言注释的好处是,它可以放在任意地方,甚至代码在同一行也没关系。较长的注释可以多行表示,我们使用 /**/ 表示多行注释,而 // 只表示的是单行注释。下面是几种注释的表示形式
// 这是一个单行注释
/* 多行注释用一行表示 */
/*
多行注释用多行表示
多行注释用多行表示
多行注释用多行表示
多行注释用多行表示
*/
函数体
在头文件、main 方法后面的就是函数体(注释一般不算),函数体就是函数的执行体,是你编写大量代码的地方。
变量声明
在我们入门级的代码中,我们声明了一个名为 number 的变量,它的类型是 int,这行代码叫做 声明,声明是 C 语言最重要的特性之一。这个声明完成了两件事情:定义了一个名为 number 的变量,定义 number 的具体类型。
int 是 C 语言的一个 关键字(keyword),表示一种基本的 C 语言数据类型。关键字是用于语言定义的。不能使用关键字作为变量进行定义。
示例中的 number 是一个 标识符(identifier),也就是一个变量、函数或者其他实体的名称。
###变量赋值
在入门例子程序中,我们声明了一个 number 变量,并为其赋值为 11,赋值是 C 语言的基本操作之一。这行代码的意思就是把值 1 赋给变量 number。在执行 int number 时,编译器会在计算机内存中为变量 number 预留空间,然后在执行这行赋值表达式语句时,把值存储在之前预留的位置。可以给 number 赋不同的值,这就是 number 之所以被称为 变量(variable) 的原因。
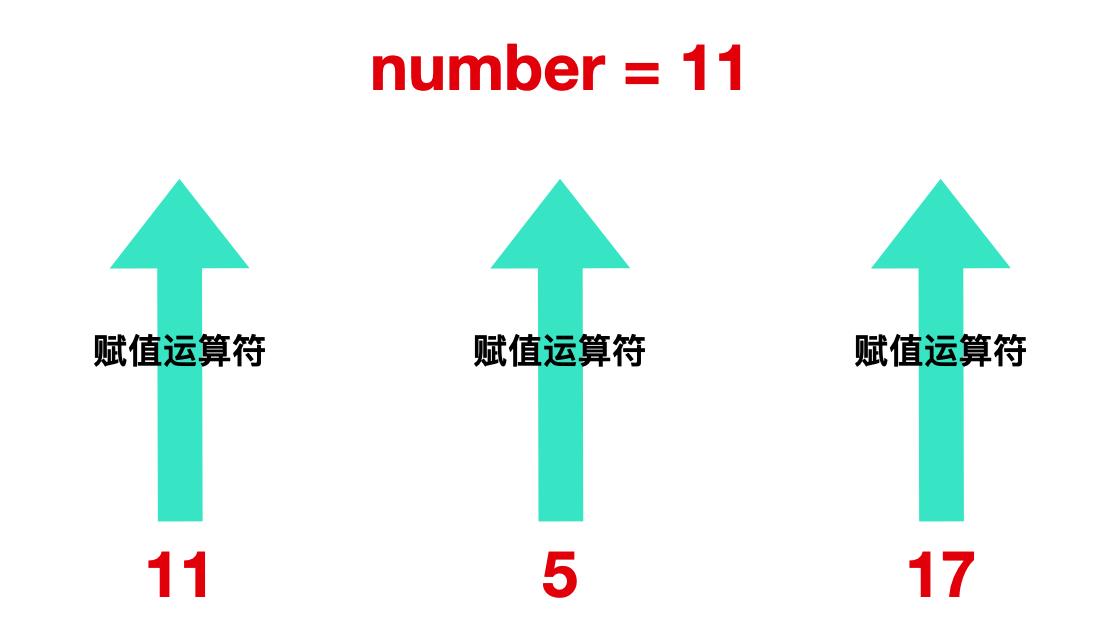
printf 函数
在入门例子程序中,有三行 printf(),这是 C 语言的标准函数。圆括号中的内容是从 main 函数传递给 printf 函数的。参数分为两种:实际参数(actual argument) 和 形式参数(formal parameters)。我们上面提到的 printf 函数括号中的内容,都是实参。
return 语句
在入门例子程序中,return 语句是最后一条语句。int main(void) 中的 int 表明 main() 函数应返回一个整数。有返回值的 C 函数要有 return 语句,没有返回值的程序也建议大家保留 return 关键字,这是一种好的习惯或者说统一的编码风格。
分号
在 C 语言中,每一行的结尾都要用 ; 进行结束,它表示一个语句的结束,如果忘记或者会略分号会被编译器提示错误。
关键字
下面是 C 语言中的关键字,C 语言的关键字一共有 32 个,根据其作用不同进行划分
数据类型关键字
数据类型的关键字主要有 12 个,分别是
char: 声明字符型变量或函数double: 声明双精度变量或函数float: 声明浮点型变量或函数int: 声明整型变量或函数long: 声明长整型变量或函数short: 声明短整型变量或函数signed: 声明有符号类型变量或函数_Bool: 声明布尔类型_Complex:声明复数_Imaginary: 声明虚数unsigned: 声明无符号类型变量或函数void: 声明函数无返回值或无参数,声明无类型指针
控制语句关键字
控制语句循环的关键字也有 12 个,分别是
循环语句
for: for 循环,使用的最多do:循环语句的前提条件循环体while:循环语句的循环条件break: 跳出当前循环continue:结束当前循环,开始下一轮循环
条件语句
if:条件语句的判断条件else: 条件语句的否定分支,与 if 连用goto: 无条件跳转语句
开关语句
switch: 用于开关语句case:开关语句的另外一种分支default: 开关语句中的其他分支
返回语句
retur:子程序返回语句(可以带参数,也看不带参数)
存储类型关键字
auto: 声明自动变量 一般不使用extern: 声明变量是在其他文件正声明(也可以看做是引用变量)register: 声明寄存器变量static: 声明静态变量
其他关键字
const: 声明只读变量sizeof: 计算数据类型长度typedef: 用以给数据类型取别名volatile: 说明变量在程序执行中可被隐含地改变
后记
这篇文章我们先介绍了 C 语言的特性,C 语言为什么这么火,C 语言的重要性,之后我们以一道 C 语言的入门程序讲起,我们讲了 C 语言的基本构成要素,C 语言在硬件上是如何运行的,C 语言的编译过程和执行过程等,在这之后我们又加深讲解了一下入门例子程序的组成特征。
如果你觉得这篇文章不错的的话,欢迎小伙伴们四连走起:点赞、在看、留言、分享。你的四连是我更文的动力。
C 中的数据
我们在了解完上面的入门例子程序后,下面我们就要全面认识一下 C 语言程序了,首先我们先来认识一下 C 语言最基本的变量与常量。
变量和常量
变量和常量是程序处理的两种基本对象。
有些数据类型在程序使用之前就已经被设定好了,在整个过程中没有变化(这段话描述不准确,但是为了通俗易懂,暂且这么描述),这种数据被称为常量(constant)。另外一种数据类型在程序执行期间可能会发生改变,这种数据类型被称为 变量(variable)。例如 int number 就是一个变量,而3.1415 就是一个常量,因为 int number 一旦声明出来,你可以对其任意赋值,而 3.1415 一旦声明出来,就不会再改变。
变量名
有必要在聊数据类型之前先说一说变量名的概念。变量名是由字母和数字组成的序列,第一个字符必须是字母。在变量名的命名过程中,下划线 _ 被看作字母,下划线一般用于名称较长的变量名,这样能够提高程序的可读性。变量名通常不会以下划线来开头。在 C 中,大小写是有区别的,也就是说,a 和 A 完全是两个不同的变量。一般变量名使用小写字母,符号常量(#define 定义的)全都使用大写。选择变量名的时候,尽量能够从字面上描述出变量的用途,切忌起这种 abc 毫无意义的变量。
还需要注意一般局部变量都会使用较短的变量名,外部变量使用较长的名字。
数据类型
在了解数据类型之前,我们需要先了解一下这些概念 位、字节和字。
位、字节和字都是对计算机存储单元的描述。在计算机世界中,最小的单元是
位(bit),一个位就表示一个 0 或 1,一般当你的小伙伴问你的电脑是 xxx 位,常见的有 32 位或者 64 位,这里的位就指的是比特,比特就是 bit 的中文名称,所以这里的 32 位或者 64 位指的就是 32 bit 或者 64 bit。字节是基本的存储单元,基本存储单元说的是在计算机中都是按照字节来存储的,一个字节等于 8 位,即 1 byte = 8 bit。字是自然存储单位,在现代计算机中,一个字等于 2 字节。
C 语言的数据类型有很多,下面我们就来依次介绍一下。
整型
C 语言中的整型用 int 来表示,可以是正整数、负整数或零。在不同位数的计算机中其取值范围也不同。不过在 32 位和 64 位计算机中,int 的取值范围是都是 2^32 ,也就是 -2147483648 ~ +2147483647,无符号类型的取值范围是 0 ~ 4294967295。
整型以二进制整数存储,分为有符号数和无符号数两种形态,有符号数可以存储正整数、负整数和零;无符号只能存储正整数和零。
可以使用 printf 打印出来 int 类型的值,如下代码所示。
#include <stdio.h>
int main()
int a = -5;
printf("%d\\n",a);
unsigned int b = 6;
printf("%d\\n",b);
C 语言还提供 3 个附属关键字修饰整数类型,即 short、long 和 unsigned。
- short int 类型(或者简写为 short)占用的存储空间
可能比 int 类型少,适合用于数值较小的场景。 - long int 或者 long 占用的存储空间
可能比 int 类型多,适合用于数值较大的场景。 - long long int 或者 long long(C99 加入)占用的存储空间比 long 多,适用于数值更大的场合,至少占用 64 位,与 int 类似,long long 也是有符号类型。
- unsigned int 或 unsigned 只用于非负值的场景,这种类型的取值范围有所不同,比如 16 位的 unsigned int 表示的范围是 0 ~ 65535 ,而不是 -32768 ~ 32767。
- 在 C90 标准中,添加了 unsigned long int 或者 unsigned long 和 unsigned short int 或 unsigned short 类型,在 C99 中又添加了 unsigned long long int 或者 unsigned long long 。
- 在任何有符号类型前面加 signed ,可强调使用有符号类型的意图。比如 short、short int、signed short、signed short int 都表示一种类型。
比如上面这些描述可以用下面这些代码来声明:
long int lia;
long la;
long long lla;
short int sib;
short sb;
unsigned int uic;
unsigned uc;
unsigned long uld;
unsigned short usd;
这里需要注意一点,unsigned 定义的变量,按照 printf 格式化输出时,是能够显示负值的,为什么呢?不是 unsigned 修饰的值不能是负值啊,那是因为 unsigned 修饰的变量,在计算时会有用,输出没什么影响,这也是 cxuan 刚开始学习的时候踩的坑。
我们学过 Java 的同学刚开始都对这些定义觉得莫名其妙,为什么一个 C 语言要对数据类型有这么多定义?C 语言真麻烦,我不学了!
千万不要有这种想法,如果有这种想法的同学,你一定是被 JVM 保护的像个孩子!我必须从现在开始纠正你的这个想法,因为 Java 有 JVM 的保护,很多特性都做了优化,而 C 就像个没有伞的孩子,它必须自己和这个世界打交道!
上面在说 short int 和 long int 的时候,都加了一个可能,怎么,难道 short int 和 long int 和 int 还不一样吗?
这里就是 C 语言数据类型一个独特的风格。
为什么说可能,这是由于 C 语言为了适配不同的机器来设定的语法规则,在早起的计算机上,int 类型和 short 类型都占 16 位,long 类型占 32 位,在后来的计算机中,都采用了 16 位存储 short 类型,32 位存储 int 类型和 long 类型,现在,计算机普遍使用 64 位 CPU,为了存储 64 位整数,才引入了 long long 类型。所以,一般现在个人计算机上常见的设置是 long long 占用 64 位,long 占用 32 位,short 占用 16 位,int 占用 16 位或者 32 位。
char 类型
char 类型一般用于存储字符,表示方法如下
char a = 'x';
char b = 'y';
char 被称为字符类型,只能用单引号 ‘’ 来表示,而不能用双引号 “” 来表示,这和字符串的表示形式相反。
char 虽然表示字符,但是 char 实际上存储的是整数而不是字符,计算机一般使用 ASCII 来处理字符,标准 ASCII 码的范围是 0 - 127 ,只需 7 位二进制数表示即可。C 语言中规定 char 占用 1 字节。
其实整型和字符型是相通的,他们在内存中的存储本质是相通的,编译器发现 char ,就会自动转换为整数存储,相反的,如果给 int 类型赋值英文字符,也会转换成整数存储,如下代码
#include <stdio.h>
int main()
char a = 'x';
int b;
b = 'y';
printf("%d\\n%d\\n",a,b);
输出
120
121
所以,int 和 char 只是存储的范围不同,整型可以是 2 字节,4 字节,8 字节,而字符型只占 1 字节。
有些 C 编译器把 char 实现为有符号类型,这意味着 char 可表示的范围是 -128 ~ 127,而有些编译器把 char 实现为无符号类型,这种情况下 char 可表示的范围是 0 - 255。signed char 表示的是有符号类型,unsigned char 表示的是无符号类型。
_Bool 类型
_Bool 类型是 C99 新增的数据类型,用于表示布尔值。也就是逻辑值 true 和 false。在 C99 之前,都是用 int 中的 1 和 0 来表示。所以 _Bool 在某种程度上也是一种数据类型。表示 0 和 1 的话,用 1 bit(位)表示就够了。
float、double 和 long double
整型对于大多数软件开发项目而言就已经够用了。然而,在金融领域和数学领域还经常使用浮点数。C 语言中的浮点数有 float、double 和 long double 类型。浮点数类型能够表示包括小数在内更大范围的数。浮点数能表示小数,而且表示范围比较大。浮点数的表示类似于科学技术法。下面是一些科学记数法示例:
| 数字 | 科学记数法 | 指数记数法 |
|---|---|---|
| 1000000000 | 1 * 10^9 | 1.0e9 |
| 456000 | 4.56 * 10^5 | 4.56e5 |
| 372.85 | 3.7285 * 10 ^ 2 | 3.7285e2 |
| 0.0025 | 2.5 * 10 ^ -3 | 2.5e-3 |
C 规定 float 类型必须至少能表示 6 位有效数字,而且取值范围至少是 10^-37 ~ 10^+37。通常情况下,系统存储一个浮点数要占用 32 位。
C 提供的另一种浮点类型是 double(双精度类型)。一般来说,double 占用的是 64 位而不是 32 位。
C 提供的第三种类型是 long double ,用于满足比 double 类型更高的精度要求。不过,C 只保证了 long double 类型至少与 double 类型相同。
浮点数的声明方式和整型类似,下面是一些浮点数的声明方式。
#include <stdio.h>
int main()
float aboat = 2100.0;
double abet = 2.14e9;
long double dip = 5.32e-5;
printf("%f\\n", aboat);
printf("%e\\n", abet);
printf("%Lf\\n", dip);
printf() 函数使用 %f 转换说明打印十进制计数法的 float 和 double 类型浮点数,用 %e 打印指数记数法的浮点数。打印 long double 类型要使用 %Lf 转换说明。
关于浮点数,还需要注意其上溢和下溢的问题。
上溢指的是是指由于数字过大,超过当前类型所能表示的范围,如下所示
float toobig = 3.4E38 * 100.0f;
printf("%e\\n",toobig);
输出的内容是 inf,这表示 toobig 的结果超过了其定义的范围,C 语言就会给 toobig 赋一个表示无穷大的特定值,而且 printf 显示值为 inf 或者 infinity 。
下溢:是指由于数值太小,低于当前类型所能表示的最小的值,计算机就只好把尾数位向右移,空出第一个二进制位,但是与此同时,却损失了原来末尾有效位上面的数字,这种情况就叫做下溢。比如下面这段代码
float toosmall = 0.1234e-38/10;
printf("%e\\n", toosmall);
复数和虚数类型
许多科学和工程计算都需要用到复数和虚数,C99 标准支持复数类型和虚数类型,C 语言中有 3 种复数类型:float _Complex、double _Complex 和 long double _Complex。
C 语言提供的 3 种虚数类型:float _Imaginary、 double _Imaginary 和 long double _Imaginary。
如果包含 complex.h 头文件的话,便可使用 complex 替换 _Complex,用 imaginary 替代 _Imaginary。
其他类型
除了上述我们介绍过的类型之外,C 语言中还有其他类型,比如数组、指针、结构和联合,虽然 C 语言没有字符串类型,但是 C 语言却能够很好的处理字符串。
常量
在很多情况下我们需要常量,在整个程序的执行过程中,其值不会发生改变,比如一天有 24 个小时,最大缓冲区的大小,滑动窗口的最大值等。这些固定的值,即称为常量,又可以叫做字面量。
常量也分为很多种,整型常量,浮点型常量,字符常量,字符串常量,下面我们分别来介绍
整数常量
整数常量可以表示为十进制、八进制或十六进制。前缀指定基数:0x 或 0X 表示十六进制,0 表示八进制,不带前缀则默认表示十进制。整数常量也可以带一个后缀,后缀是 U 和 L 的组合,U 表示无符号整数(unsigned),L 表示长整数(long)。
330 /* 合法的 */
315u /* 合法的 */
0xFeeL /* 合法的 */
048 /* 非法的:8 进制不能定义 8 */
浮点型常量
浮点型常量由整数部分、小数点、小数部分和指数部分组成。你可以使用小数形式或者指数形式来表示浮点常量。
当使用小数形式表示时,必须包含整数部分、小数部分,或同时包含两者。当使用指数形式表示时, 必须包含小数点、指数,或同时包含两者。带符号的指数是用 e 或 E 引入的。
3.14159 /* 合法的 */
314159E-5L /* 合法的 */
510E /* 非法的:不完整的指数 */
210f /* 非法的:没有小数或指数 */
字符常量
C 语言中的字符常量使用单引号(即撇号)括起来的一个字符。如‘a’,‘x’,‘D’,‘?’,‘$’ 等都是字符常量。注意,‘a’ 和 ‘A’ 是不同的字符常量。
除了以上形式的字符常量外,C 还允许用一种特殊形式的字符常量,就是以一个 “\\” 开头的字符序列。例如,前面已经遇到过的,在 printf 函数中的‘\\n’,它代表一个换行符。这是一种控制字符,在屏幕上是不能显示的。
常用的以 “\\” 开头的特殊字符有
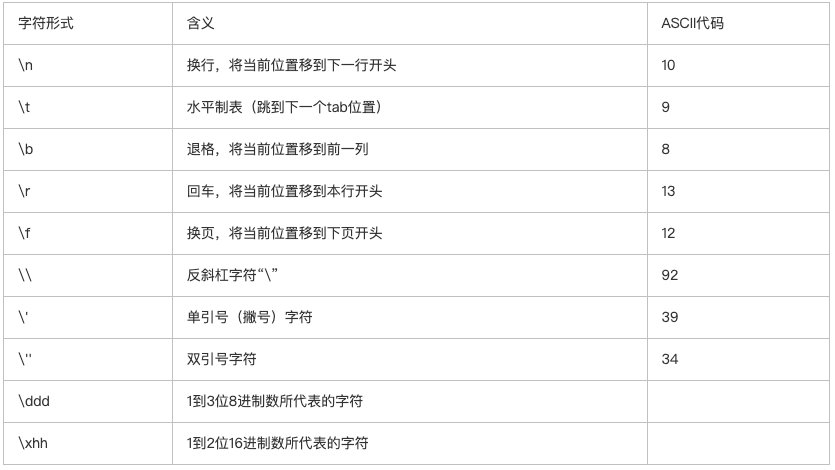
表中列出的字符称为“转义字符”,意思是将反斜杠(\\)后面的字符转换成另外的意义。如 ‘\\n’ 中的 “n” 不代表字母 n 而作为“换行”符。
表中最后第 2 行是用ASCII码(八进制数)表示一个字符,例如 ‘\\101’ 代表 ASCII 码(十进制数)为 65 的字符 “A”。‘\\012’(十进制 ASCII 码为 10)代表换行。
需要注意的是 ‘\\0’ 或 ‘\\000’ 代表 ASCII 码为 0 的控制字符,它用在字符串中。
字符串常量
字符串常量通常用 “” 进行表示。字符串就是一系列字符的集合。一个字符串包含类似于字符常量的字符:普通的字符、转义序列和通用的字符。
常量定义
C 语言中,有两种定义常量的方式。
- 使用
#define预处理器进行预处理 - 使用
const关键字进行处理
下面是使用 #define 预处理器进行常量定义的代码。
#include <stdio.h>
#define LENGTH 5
#define WIDTH 10
int main()
int area = LENGTH * WIDTH;
printf("area = %d\\n", area);
同样的,我们也可以使用 const 关键字来定义常量,如下代码所示
#include <stdio.h>
int main()
const int LENGTH = 10;
const int WIDTH = 5;
int area;
area = LENGTH * WIDTH;
printf("area = %d\\n", area);
那么这两种常量定义方式有什么不同呢?
编译器处理方式不同
使用 #define 预处理器是在预处理阶段进行的,而 const 修饰的常量是在编译阶段进行。
类型定义和检查不同
使用 #define 不用声明数据类型,而且不用类型检查,仅仅是定义;而使用 const 需要声明具体的数据类型,在编译阶段会进行类型检查。
文章参考:
https://www.zhihu.com/question/19668080
我自己写了四本 PDF ,非常硬核,链接如下
最后给大家推荐一下我自己的 Github,里面有非常多的硬核文章,绝对会对你有帮助。
以上是关于C 语言基础,来喽的主要内容,如果未能解决你的问题,请参考以下文章