极智AI | 三谈昇腾CANN量化
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了极智AI | 三谈昇腾CANN量化相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
大家好,我是极智视界,本文介绍一下 三谈昇腾CANN量化。
在之前我已经从原理和命令行的量化执行方面介绍了昇腾CANN的量化,有兴趣的同学可以去查看,附上:
- 《谈谈昇腾CANN量化》 ==> 昇腾CANN量化原理;
- 《再谈昇腾CANN量化》 ==> 昇腾CANN命令行量化执行;
这里我们来谈谈CANN量化的Python API,当然这跟命令行的量化执行一样,功能上也是进行量化操作。
先来一个resnet101的python量化的完整代码,然后再慢慢解释:
import os
import argparse
import cv2
import numpy as np
import onnxruntime as ort
import amct_onnx as amct
PATH = os.path.realpath('./')
IMG_DIR = os.path.join(PATH, 'data/images')
LABLE_FILE = os.path.join(IMG_DIR, 'image_label.txt')
PARSER = argparse.ArgumentParser(description='amct_onnx resnet-101 quantization sample.')
PARSER.add_argument('--nuq', dest='nuq', action='store_true', help='whether use nuq')
ARGS = PARSER.parse_args()
if ARGS.nuq:
OUTPUTS = os.path.join(PATH, 'outputs/nuq')
else:
OUTPUTS = os.path.join(PATH, 'outputs/calibration')
TMP = os.path.join(OUTPUTS, 'tmp')
def get_labels_from_txt(label_file):
"""Read all images' name and label from label_file"""
images = []
labels = []
with open(label_file, 'r') as file:
lines = file.readlines()
for line in lines:
images.append(line.split(' ')[0])
labels.append(int(line.split(' ')[1]))
return images, labels
def prepare_image_input(
images, height=256, width=256, crop_size=224, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):
"""Read image files to blobs [batch_size, 3, 224, 224]"""
input_tensor = np.zeros((len(images), 3, crop_size, crop_size), np.float32)
imgs = np.zeros((len(images), 3, height, width), np.float32)
for index, im_file in enumerate(images):
im_data = cv2.imread(im_file)
im_data = cv2.resize(im_data, (256, 256), interpolation=cv2.INTER_CUBIC)
cv2.cvtColor(im_data, cv2.COLOR_BGR2RGB)
imgs[index, :, :, :] = im_data.transpose(2, 0, 1).astype(np.float32)
h_off = int((height - crop_size) / 2)
w_off = int((width - crop_size) / 2)
input_tensor = imgs[:, :, h_off: (h_off + crop_size), w_off: (w_off + crop_size)]
# trans uint8 image data to float
input_tensor /= 255
# do channel-wise reduce mean value
for channel in range(input_tensor.shape[1]):
input_tensor[:, channel, :, :] -= mean[channel]
# do channel-wise divide std
for channel in range(input_tensor.shape[1]):
input_tensor[:, channel, :, :] /= std[channel]
return input_tensor
def img_postprocess(probs, labels):
"""Do image post-process"""
# calculate top1 and top5 accuracy
top1_get = 0
top5_get = 0
prob_size = probs.shape[1]
for index, label in enumerate(labels):
top5_record = (probs[index, :].argsort())[prob_size - 5: prob_size]
if label == top5_record[-1]:
top1_get += 1
top5_get += 1
elif label in top5_record:
top5_get += 1
return float(top1_get) / len(labels), float(top5_get) / len(labels)
def onnx_forward(onnx_model, batch_size=1, iterations=160):
"""forward"""
ort_session = ort.InferenceSession(onnx_model, amct.AMCT_SO)
images, labels = get_labels_from_txt(LABLE_FILE)
images = [os.path.join(IMG_DIR, image) for image in images]
top1_total = 0
top5_total = 0
for i in range(iterations):
input_batch = prepare_image_input(images[i * batch_size: (i + 1) * batch_size])
output = ort_session.run(None, 'input': input_batch)
top1, top5 = img_postprocess(output[0], labels[i * batch_size: (i + 1) * batch_size])
top1_total += top1
top5_total += top5
print('****************iteration:*****************'.format(i))
print('top1_acc:'.format(top1))
print('top5_acc:'.format(top5))
print('******top1:'.format(top1_total / iterations))
print('******top5:'.format(top5_total / iterations))
return top1_total / iterations, top5_total / iterations
def main():
"""main"""
model_file = './model/resnet-101.onnx'
print('[INFO] Do original model test:')
ori_top1, ori_top5 = onnx_forward(model_file, 32, 5)
config_json_file = os.path.join(TMP, 'config.json')
skip_layers = []
batch_num = 1
if ARGS.nuq:
amct.create_quant_config(
config_file=config_json_file, model_file=model_file, skip_layers=skip_layers, batch_num=batch_num,
activation_offset=True, config_defination='./src/nuq_conf/nuq_quant.cfg')
else:
amct.create_quant_config(
config_file=config_json_file, model_file=model_file, skip_layers=skip_layers, batch_num=batch_num,
activation_offset=True, config_defination=None)
# Phase1: do conv+bn fusion, weights calibration and generate
# calibration model
scale_offset_record_file = os.path.join(TMP, 'record.txt')
modified_model = os.path.join(TMP, 'modified_model.onnx')
amct.quantize_model(
config_file=config_json_file, model_file=model_file, modified_onnx_file=modified_model,
record_file=scale_offset_record_file)
onnx_forward(modified_model, 32, batch_num)
# Phase3: save final model, one for onnx do fake quant test, one
# deploy model for ATC
result_path = os.path.join(OUTPUTS, 'resnet-101')
amct.save_model(modified_model, scale_offset_record_file, result_path)
# Phase4: run fake_quant model test
print('[INFO] Do quantized model test:')
quant_top1, quant_top5 = onnx_forward('%s_%s' % (result_path, 'fake_quant_model.onnx'), 32, 5)
print('[INFO] ResNet101 before quantize top1::>10 top5::>10'.format(ori_top1, ori_top5))
print('[INFO] ResNet101 after quantize top1::>10 top5::>10'.format(quant_top1, quant_top5))
if __name__ == '__main__':
main()关于量化数据集的制作同样可以参考《再谈昇腾CANN量化》里的方法。
以上完整的量化过程,有三个主要的python接口,分别是:create_quant_config、quantize_model、save_model,来分别介绍一下。
create_quant_config的作用是根据graph的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置因子写入文件,函数接口如下:
create_quant_config(config_file, model_file, skip_layers=None, batch_unm=1, activation_offset=True, config_defination=None, updated_model=None)其中:

这个函数会输出一个json格式的量化配置文件,一个简单的调用方法如下:
import amct_onnx
model_file = "resnet101.onnx"
# 生成量化配置文件
amct_onnx.create_quant_config(config_file="config.json",
model_file=model_file,
skip_layers=None,
batch_num=1,
activation_offset=True)接着咱们来看quantize_model,顾铭思议,这个接口就是在做量化。将输入的待量化的graph结构按照create_quant_config生成的量化配置文件进行量化处理,在传入的graph结构中插入量化算子如quant/dequant,然后生成量化因子记录文件record_file,返回修改后的onnx量化校准模型。函数的接口如下:
quantize_model(config_file, model_file, modified_onnx_file, record_file)其中:

这个函数会返回modified_onnx_file待量化模型 和 record_file量化因子记录文件,以用于下一步生成量化模型。一个简单的调用示例如下:
import amct_onnx
model_file = "resnet101.onnx"
scale_offset_record_file = os.path.join(TMP, 'scale_offset_record.txt')
modified_model = os.path.join(TVM, 'modified_model.onnx')
config_file = "config.json"
# 量化
amct_onnx.quantize_model(config_file,
model_file,
modified_model,
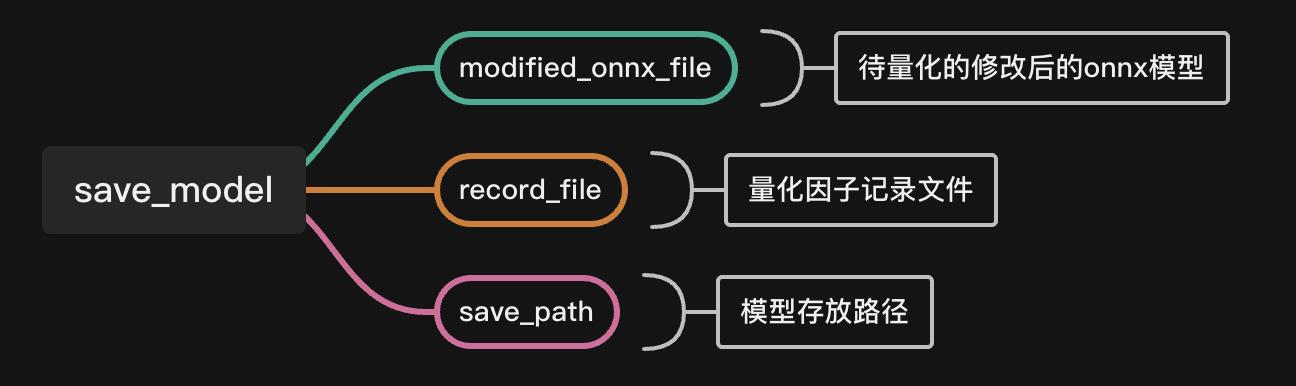
scale_offset_record_file)最后来看save_model,这个函数的功能是根据量化因子文件record_file和修改后的量化模型modified_model,插入AscendQuant和AscendDequant等量化相关算子,生成可以在onnx runtime环境进行精度仿真的face_quant模型 以及 可以在昇腾上推理的deploy模型。函数接口如下:
save_model(modified_onnx_file, record_file, save_path)其中:
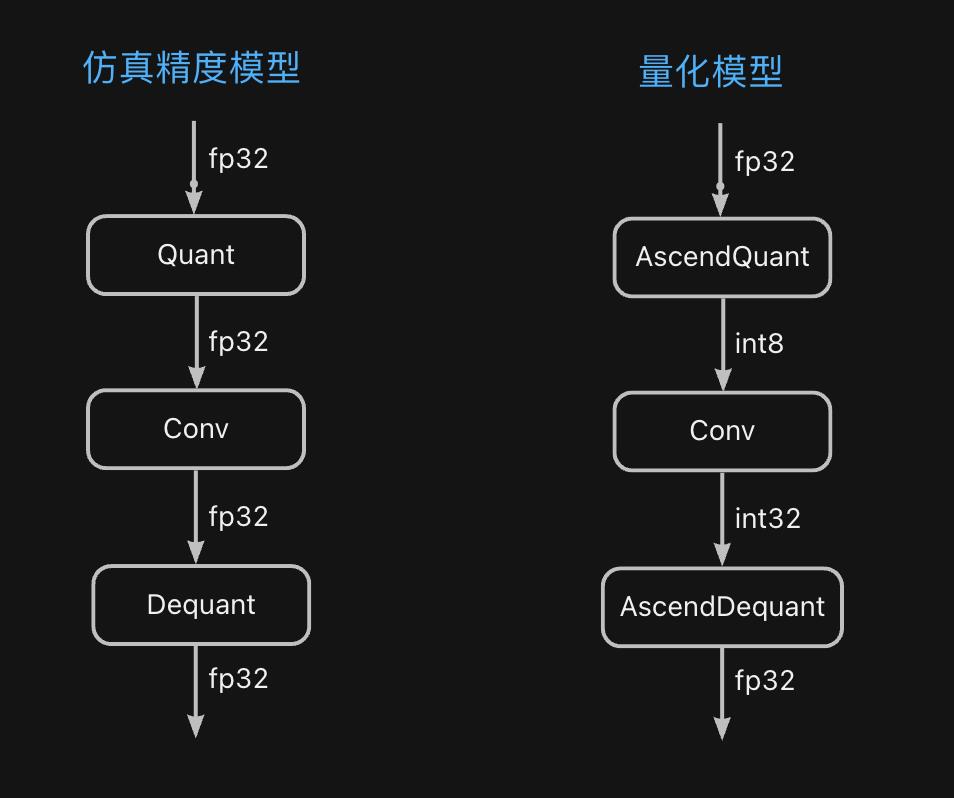
生成的精度仿真模型和推理模型在结构上有什么区别呢,来看:
一个简单的调用示例如下:
import amct_onnx
# 保存量化模型
amct_onnx.save_model(modified_onnx_file="modified_model.onnx",
record_file="scale_offset_record_file.txt",
save_path="res")这样整个CANN量化的Python API实现方式就介绍完了。
好了,以上分享三谈昇腾CANN量化,希望我的分享能对你的学习有一点帮助。
【极智视界】

搜索关注我的微信公众号「极智视界」,获取我的更多经验分享,让我们用极致+极客的心态来迎接AI !
以上是关于极智AI | 三谈昇腾CANN量化的主要内容,如果未能解决你的问题,请参考以下文章