kafka安装到实战教程(Python版)
Posted 大数据学编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka安装到实战教程(Python版)相关的知识,希望对你有一定的参考价值。
Kafka精华笔记从安装到实战(Python版)
1.kafka简介
kafaka是Apache旗下的顶级开业产品,的本质就是一个消息队列,把数据的实时处理转变为异步处理,也是当下最常用的一款产品
1.1 kafka的应用场景
1.应用解耦合
2.同步处理转换为异步处理
3.限流削峰(秒杀活动)
1.2 Kafka架构图
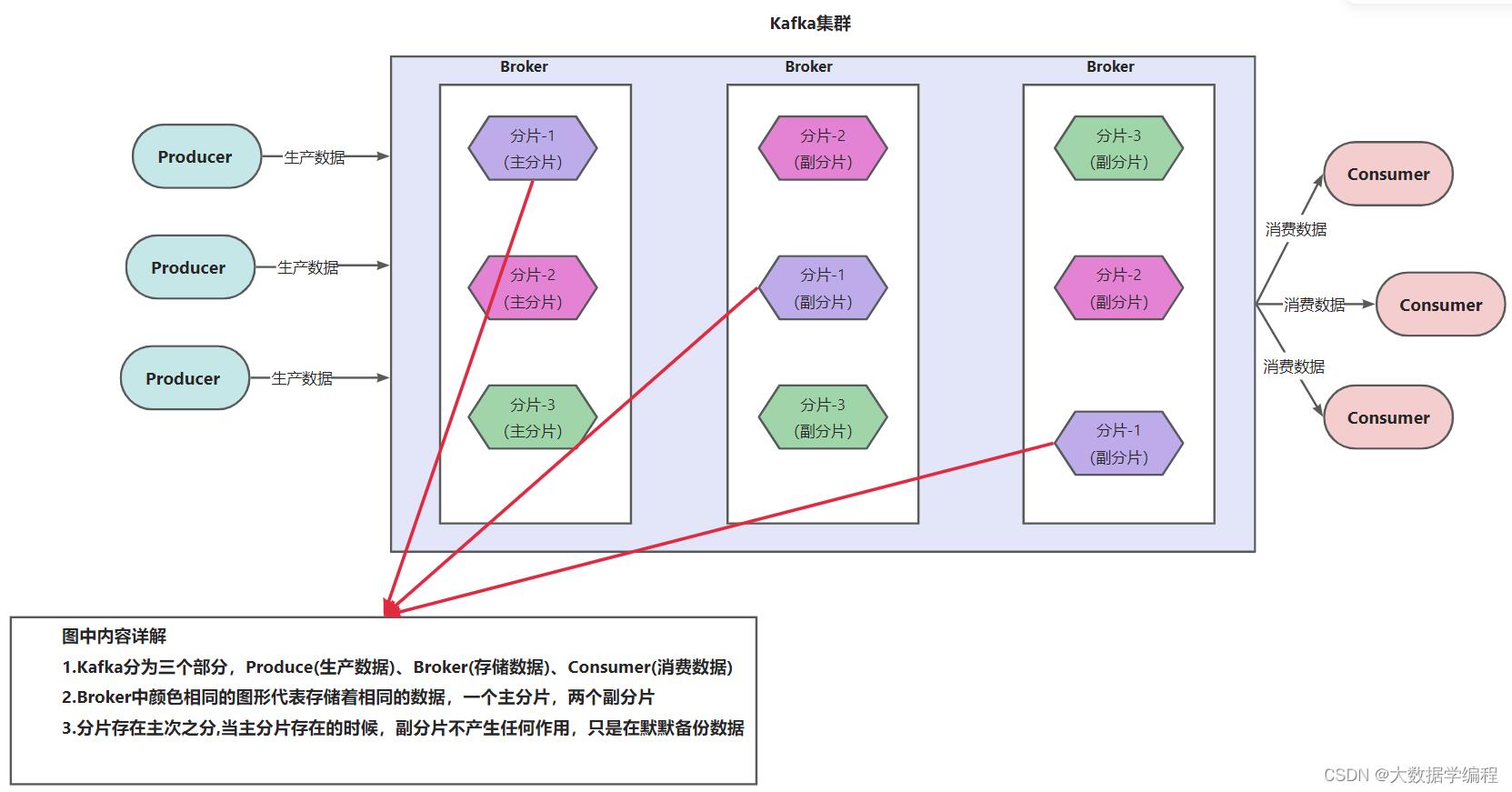
Producer : 向Topic中生产数据
Broker: Kafka的节点,负责存储数据
Consumer: 从Topic中获取数据,再消费数据
Topic: 话题/主题 可以理解为一个逻辑容器,Producer向Topic中生产数据,Consumer向Topic中获取数据
分片:一个Topic可以划分为N个分片,数量没有限制,分片可以理解为把数据拆分成多个小块进行存储
副本: 每个分片都可以构建副本,但副本数量最大不能超过节点的数量,也就是说副本数量最多和节点数量一致,最少可以没有副本
2.Kafka的安装
软件安装包链接:https://pan.baidu.com/s/1sIZu7Lw6t8mRmvYaebQdaA?pwd=1111
提取码:1111
2.1 将Kafka的安装包上传到虚拟机,并解压
cd /export/software/
tar -zxf kafka_2.12-2.4.1.tgz -C ../server/
配置软连接:
cd /export/server
ln -s kafka_2.12-2.4.1 kafka
2.2 修改文件 server.properties
cd /export/server/kafka/config
vim server.properties
# 指定broker的id
broker.id=0
# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT://192.168.88.161:9092
# 指定Kafka数据存放的位置
log.dirs=/export/server/kafka/data
# 配置zookeeper节点
zookeeper.connect=192.168.88.161:2181
2.3 配置KAFKA_HOME环境变量
vim /etc/profile
# 内容如下
# KAFKA_HOME
export KAFKA_HOME=/export/server/kafka
export PATH=:$PATH:$KAFKA_HOME
# 加载环境变量
source /etc/profile
2.4 启动服务器
注意:在启动Kafka之前,先得启动Zookeeper,这里就没论述Zookeeper相关知识了
# 前台启动:
./kafka-server-start.sh ../config/server.properties
# 后台启动:
nohup ./kafka-server-start.sh ../config/server.properties 2>&1 &
#推荐使用后台启动
# 验证是否启动成功
jps
3.Kafka实战
3.1 创建Topic
# 1.cd 进入kafka的bin目录
cd /export/server/kafka/bin
# 2.通过 kafka-topics.sh 创建Topic
./kafka-topics.sh --create --zookeeper node1:2181 --topic test01 --partitions 3 --replication-factor 2
# 注意:一定要写zookeeper的地址,副本数量,分片数量
3.2 通过Python模拟消费者和生产者
3.1 生产者:以同步发送为演示
import os
import kafka
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 1. 创建 kafka 生产者
Producer = kafka.KafkaProducer(bootstrap_servers='node1:9092')
# 2- 执行数据发送(生产)的操作
# 发送 0~20的数据
# 2.1 同步发送
for i in range(20):
# 数据是往Topic中发送
data = Producer.send(topic='test01', value=f'i'.encode('utf8')).get() # get() 啥也不加,就是同步发送
print(data.topic) # 发送给那个topic
print(data.partition) # 发送到了那个分片上
print(data.offset) # 偏移量是多少
Producer.close()

3.2消费者:消费数据
import os
import kafka
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 指定Topic,绑定地址
Consumer = kafka.KafkaConsumer('test01',
bootstrap_servers='node1:9092',
group_id='g_1') # group_id 给消费者分类
for message in Consumer:
topic = message.topic
partition = message.partition
offset = message.offset
key = message.key
value = message.value.decode('UTF-8')
print(f'从topic的partition分片上,获取第offset偏移量的消息为key-value')

以上是关于kafka安装到实战教程(Python版)的主要内容,如果未能解决你的问题,请参考以下文章