Beam Search(集束搜索/束搜索/定向搜索)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Beam Search(集束搜索/束搜索/定向搜索)相关的知识,希望对你有一定的参考价值。
参考技术A 应用:1、机器翻译:找到最可能的翻译结果
2、语音识别:找到最可能的识别生成结果
集束搜索(beam search):
第一步:用编码器解码器,给定输入的语法句子,输出第一个单词最可能的概率值。
贪心算法只会挑出最可能的一个单词,然后继续。而集束搜索则会考虑多个选择,集束搜索算法有一个参数B,叫做集束宽。假设将B设为3,则集束搜索会一次考虑3个可能的结果。比如对第一个单词,从一万个语料库单词中找出概率最高的三个词,将可能的结果存入计算机内存,以便后面尝试用这三个词。如果集束宽设的不一样,如B=10,则需要跟踪的不仅仅是3个,而是10个第一个单词的最可能的选择。要明白要完成集束搜索的第一步,需要先将法语句子输入到编码器中,然后解码器的softmax层会输出一万个概率值,取前三个存起来。
第二步:针对每个已经选出的第一个可能的单词,考虑第二个单词是什么。
如下图神经网络,可找出在给定法语句子和给定第一个单词的情况下,输出第二个单词的概率。但是我们需要的是<第一个单词,第二个单词>对的条件概率最大,利用条件概率法则:
即将两步结果相乘即可。由于B=3,则同样找出三个最可能的单词对,保存起来,用于寻找第三个词。可能这三个最可能的单词对不是每一个词(第一个词的三个)对应一个,则第一个词的可能性就变成了2个或者1个。由于B=3,所以有三个网络副本,每个副本评估一万个单词,共评估三万个单词。
第三步:针对每个已经选出的第一个和第二个单词的单词对,考虑第三个单词是什么。
最终一次增加一个单词,直至找到一个句子。如果B=1,则退化成贪心搜索。若同时考虑多个可能的结果,集束搜索通常会找到比贪心算法更好的输出结果。
beam search
机器学习中常用到的一种搜索算法beam search(束搜索)。为了方便大家理解,这里先假设一个非常简单的搜索任务。
设想了 简单的一个搜索任务
假设现在有一个简化版的中文翻译英文任务,输入和输出如下,为了方便描述搜索算法,限制输出词典只有"I", "H", "U" 这3个候选词,限制1个时间步长翻译1个汉字,1个汉字对应1个英文单词,这里总共3个汉字,所以只有3个时间步长。
中文输入:"我" "恨" "你"
英文输出:"I" "H" "U"
目标:得到最优的翻译序列 I-H-U
exhaustive search(穷举搜索)
最直观的方法就是穷举所有可能的输出序列,3个时间步长,每个步长3种选择,共计 3*3*3 = 27种排列组合。
I-I-I
I-I-H
I-I-U
I-H-I
I-H-H
I-H-U
I-U-I
I-U-H
I-U-U
H-I-I
H-I-H
H-I-U
H-H-I
H-H-H
H-H-U
H-U-I
H-U-H
H-U-U
U-I-I
U-I-H
U-I-U
U-H-I
U-H-H
U-H-U
U-U-I
U-U-H
U-U-U从所有的排列组合中找到输出条件概率最大的序列。穷举搜索能保证全局最优,但计算复杂度太高,当输出词典稍微大一点根本无法使用。
greedy search(贪心搜索)
贪心算法在翻译每个字的时候,直接选择条件概率最大的候选值作为当前最优。如下图所以,
- 第1个时间步长:首先翻译"我",发现候选"I"的条件概率最大为0.6,所以第一个步长直接翻译成了"I"。
- 第2个时间步长:翻译"我恨",发现II概率0.2,IH概率0.7,IU概率0.1,所以选择IH作为当前步长最优翻译结果。
- 第3个时间步长:翻译"我恨你",发现IHI概率0.05,IHH概率0.05,IHU概率0.9,所以选择IHU作为最终的翻译结果。
PS:图中的概率如何得来的?不同的模型有不同的算法,我自己随便填的。

greedy search
贪心算法每一步选择中都采取在当前状态下最好或最优的选择,通过这种局部最优策略期望产生全局最优解。但是期望是好的,能不能实现是另外一回事了。贪心算法本质上没有从整体最优上加以考虑,并不能保证最终的结果一定是全局最优的。但是相对穷举搜索,搜索效率大大提升。
beam search(束搜索)
beam search是对greedy search的一个改进算法。相对greedy search扩大了搜索空间,但远远不及穷举搜索指数级的搜索空间,是二者的一个折中方案。
beam search有一个超参数beam size(束宽),设为 k 。第一个时间步长,选取当前条件概率最大的 k 个词,当做候选输出序列的第一个词。之后的每个时间步长,基于上个步长的输出序列,挑选出所有组合中条件概率最大的 k 个,作为该时间步长下的候选输出序列。始终保持 k 个候选。最后从 k 个候选中挑出最优的。
还是以上面的任务为例,假设 k ,我们走一遍这个搜索流程。
- 第一个时间步长:如下图所示,I和H的概率是top2,所以第一个时间步长的输出的候选是I和H,将I和H加入到候选输出序列中。
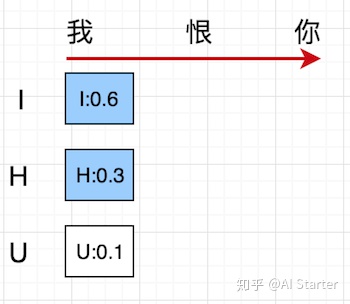
beam search 第一个时间步长
- 第2个时间步长:如下图所示,以I开头有三种候选II, IH, IU,以H开头有三种候选HI, HH, HU。从这6个候选中挑出条件概率最大的2个,即IH和HI,作为候选输出序列。

beam search 第二个时间步长
- 第3个时间步长:同理,以IH开头有三种候选IHI, IHH, IHU,以HI开头有三种候选HII, HIH, HIU。从这6个候选中挑出条件概率最大的2个,即IHH和HIU,作为候选输出序列。因为3个步长就结束了,直接从IHH和IHU中挑选出最优值IHU作为最终的输出序列。

beam search 第三个时间步长
- beam search不保证全局最优,但是比greedy search搜索空间更大,一般结果比greedy search要好。
- greedy search 可以看做是 beam size = 1时的 beam search。
以上是关于Beam Search(集束搜索/束搜索/定向搜索)的主要内容,如果未能解决你的问题,请参考以下文章