主键顺序影响——如何优化 ClickHouse 索引
Posted FesonX
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了主键顺序影响——如何优化 ClickHouse 索引相关的知识,希望对你有一定的参考价值。
回顾一下上一篇文章,ClickHouse 的存储设计,从存储目录出发,讲 ClickHouse 的数据读取:
- 第一阶段,通过隐含的 granule 单位读取主键索引 idx 文件
- 通过二分搜索过滤不需要的 Granule,再关联对应的 mk2 文件,映射 Granule 和数据文件的 offset
- 进入第二阶段,并发解压、读取 bin 数据文件,进一步排除数据,完成读取。
一. mysql 索引原则能挪用到 ClickHouse 吗
然而,这一切建立在查询条件为主键或主键最左前缀 (prefix) 的一部分,请注意,是最左前缀的一部分,而不是一部分。你可能想到了 MySQL 使用索引的最左前缀匹配原则,这里先给结论,虽然 ClickHouse 不是 BTree,但在这里的确也适用。
你可能还想到 MySQL 建立索引的数据区分度原则,区分度高的列可以减少扫描的行。但是,ClickHouse 数据存储是按主键排序的,它的隐含读取单位是 Granule,默认情况下,8192 行只有一个主键标记,即主键是稀疏的,这时候数据区分度高还要优先考虑吗?
有关 MySQL 索引,参见 MySQL索引原理及慢查询优化-美团技术
二. 当查询条件不满足最左匹配主键时
- 同为高基数,主键顺序影响不大
- 先低后高,低基数在次级排序中效率降低
- 不同基数排序顺序还影响压缩效率
2.1 实验环境准备
- Docker 搭建 ClickHouse
docker run -d --name clickhouse-local --ulimit nofile=262144:262144 -p 9000:9000 --volume=/Users/abc/clickhouse-local/:/var/lib/clickhouse yandex/clickhouse-server
默认情况下,ClickHouse Docker 已经打开 trace log,方便查看查询执行详细日志:
# /etc/clickhouse-server/config.xml
<logger>
<!-- 等级需为 trace -->
<level>trace</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>10</count>
</logger>
- 准备数据
这里创建一个先按 UserID, 再按 URL 排序主键表,同时数据插入按照 UserID, URL, EventTime 排序
-- 建表
CREATE TABLE hits_UserID_URL
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;
-- 导入数据
INSERT INTO hits_UserID_URL SELECT
intHash32(c11::UInt64) AS UserID,
c15 AS URL,
c5 AS EventTime
FROM url('https://datasets.clickhouse.com/hits/tsv/hits_v1.tsv.xz')
WHERE URL != '';
-- 线上大表谨慎操作
OPTIMIZE TABLE hits_UserID_URL FINAL;
2.2 高基数列未命中主键情形
为了更好地查看日志,这里只过滤查询部分日志
tail -f /var/log/clickhouse-server/clickhouse-server.log | grep generic -C 5
下方的查询条件 URL 为主键的第二列
SELECT
UserID,
count(UserID) AS Count
FROM hits_UserID_URL
WHERE URL = 'http://public_search'
GROUP BY UserID
ORDER BY Count DESC
LIMIT 10
会看到类似输出,关键信息是使用 generic exclusion search 查询,索引 url_skipping_index 过滤了 0/273 个 Granule,1076/1083 由主键选中的标记,即仅有 7 个被过滤,1076 个需要读取。约 881 万数据被四个流并行读取,接近全表扫描。
...Key condition: (column 1 in ['http://public_search', 'http://public_search'])
...Used generic exclusion search over index for part all_10_18_2 with 1537 steps
...Index `url_skipping_index` has dropped 0/273 granules.
... Selected 1/1 parts by partition key, 1 parts by primary key, 1076/1083 marks by primary key, 1076 marks to read from 5 ranges
...Reading approx. 8814592 rows with 4 streams
当查询条件为第一列 UserID,满足最左匹配原则,此时使用二分搜索
# 此时查看日志时过滤 binary
tail -f /var/log/clickhouse-server/clickhouse-server.log | grep binary -C 5
执行:
SELECT
URL,
count(URL) AS cnt
FROM hits_UserID_URL
WHERE UserID = 2459550954
GROUP BY URL
ORDER BY cnt DESC
LIMIT 10
可以看到 ClickHouse 用二分搜索找到单增区间(这里的 continuous range)的标记,最终过滤了 1081 个标记,读取约 1.6 w条,过滤效率很高。
Key condition: (column 0 in [2459550954, 2459550954])
(SelectExecutor): Running binary search on index range for part all_10_18_2 (1083 marks)
...Found (LEFT) boundary mark: 610
...Found (RIGHT) boundary mark: 612
... Found continuous range in 19 steps
...Selected 1/1 parts by partition key, 1 parts by primary key, 2/1083 marks by primary key, 2 marks to read from 1 ranges
Reading 1 ranges in order from part all_10_18_2, approx. 16384 rows starting from 4997120
这个时候你可能会想,把主键顺序换过来,是不是就变快了?
验证一下:
CREATE TABLE hits_URL_UserID
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (URL, UserID)
ORDER BY (URL, UserID, EventTime)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;
数据和查询保持一致
-- 线上大表谨慎操作
INSERT INTO hits_URL_UserID(UserID, URL, EventTime) SELECT
UserID, URL, EventTime FROM hits_UserID_URL;
-- 再次提醒!线上大表谨慎操作
OPTIMIZE TABLE hits_URL_UserID FINAL;
SELECT UserID, count(UserID) AS Count FROM hits_URL_UserID WHERE URL = 'http://public_search' GROUP BY UserID ORDER BY Count DESC LIMIT 10;
再次查看日志,执行的算法由 Generic Search 换为二分搜索,使用主键过滤,需要读取 39 个标记块
... Key condition: (column 0 in ['http://public_search', 'http://public_search'])
... Running binary search on index range for part all_1_9_2 (1083 marks)
... Selected 1/1 parts by partition key, 1 parts by primary key, 39/1083 marks by primary key, 39 marks to read from 1 ranges
同样地,查询非最左的 UserID,又回到 generic exclusion search,比前一张表好一些,过滤 96 个 parts,但读取 808 万行和 880 万行实际是同一个量级。
对数据唯一值计数得到基数,一个十万级别,另一个达到百万级别。
SELECT
uniq(UserID) AS uid_cardinality,
uniq(URL) AS url_cardinality
FROM hits_URL_UserID
Query id: fc18a45d-43e1-42d5-9e34-c70601ec04a2
┌─uid_cardinality─┬─url_cardinality─┐
│ 119217 │ 2391374 │
└─────────────────┴─────────────────┘
ClickHouse 低基数 (LowCardinality) 类型中提到 10000 这个阈值,一个列的基数超过此值,使用此类型将变得低效,我们可以把 UserID, URL 视为高基数列。
对于高基数列,主键排序顺序对于未命中主键的搜索性能的影响不大,接近全表扫描。
LowCardinality 使用基于字典的(Dictionary Coder)无损压缩算法
Ref: LowCardinality Data Type
2.3 低基数列未命中主键
SELECT
uniq(UserID) AS uid_cardinality,
uniq(URL) AS url_cardinality,
uniq(IsRobot) AS robot_cardinality
FROM hits_IsRobot_UserID_URL
┌─uid_cardinality─┬─url_cardinality─┬─robot_cardinality─┐
│ 119217 │ 2391374 │ 4 │
└─────────────────┴─────────────────┴───────────────────┘
根据基数大小,分别以升序排列和降序排列建表,升序排列的表,查询非最左主键的 UserID 扫描行数降了一个量级:
SELECT count()
FROM hits_URL_UserID_IsRobot
WHERE UserID = 3731416266
┌─count()─┐
│ 31519 │
└─────────┘
1 rows in set. Elapsed: 0.137 sec. Processed 8.07 million rows, 32.29 MB (58.75 million rows/s., 234.99 MB/s.)
SELECT count()
FROM hits_IsRobot_UserID_URL
WHERE UserID = 3731416266
┌─count()─┐
│ 31519 │
└─────────┘
1 rows in set. Elapsed: 0.029 sec. Processed 126.82 thousand rows, 507.27 KB (4.31 million rows/s., 17.23 MB/s.)
而对于低基数的 IsRobot 字段,尤其是查询的某个值出现频率低时,将更为明显。
SELECT
IsRobot,
count() AS cnt
FROM hits_IsRobot_UserID_URL
GROUP BY IsRobot
ORDER BY cnt DESC
LIMIT 10
┌─IsRobot─┬─────cnt─┐
│ 0 │ 8606048 │
│ 2 │ 261083 │
│ 3 │ 471 │
│ 4 │ 79 │
└─────────┴─────────┘
SELECT count()
FROM hits_IsRobot_UserID_URL
WHERE IsRobot = 4
┌─count()─┐
│ 79 │
└─────────┘
1 rows in set. Elapsed: 0.055 sec. Processed 28.51 thousand rows, 28.51 KB (514.68 thousand rows/s., 514.68 KB/s.)
SELECT count()
FROM hits_URL_UserID_IsRobot
WHERE IsRobot = 4
┌─count()─┐
│ 79 │
└─────────┘
1 rows in set. Elapsed: 0.074 sec. Processed 8.87 million rows, 8.87 MB (120.24 million rows/s., 120.24 MB/s.)
这很像典型的 Web 日志场景,碰到 API 出错,需要去查的是不常见的错误码 400、422 等,正常情况下,出现的比例比较低,如果查一次触发一次全表扫描,可能容易引发 OOM。
三. 高低基数对数据的影响
可以简化为两个
- 压缩效率
- 存储效率
3.1 数据的局部性
内存访问、程序等局部性原理,在压缩算法中有类似的表述。
压缩算法将单个数据值及其连续的计数称为运行长度编码(Run length of Data),同一数据值在原始数据中连续出现的长度越长,压缩效果越好。
把某压缩算法简化,下方的例子:
- 压缩 LOAOWOAOO 得到 LOAOWOAO2
- 压缩 OOOOAALW 得到 O4A2LW
在数据局部性差的例1,数据压缩前后的大小没有差别,而例子2减少20%
前面我们已经知道,ClickHouse 的数据是按主键排列存储,主键第一列,已经排好顺序,对于数据例子 OOOOAALW 可能存储数据中是 A2LO4W,压缩效率是最好的。在查询中,也可以排除尽可能多的数据。
3.2 次级数据的排列
同等数据量,数据有序,对高基数的列而言,压缩效果提升有限,对于低基数的列,压缩效果较好。
高低基数典型的例子是同等像素拍摄一张五彩的花海和拍摄一张白纸。后者的大小是显著小于前者的。而同等基数的情况下,一张太极图和一张东京涩谷十字路口的黑白照片,可能黑白像素总体是各50%,但图片大小却相差甚远。
讲述例子前,明确一下,查询条件为次级主键索引列时,使用 Generic Exclude Search 算法而不是二分搜索来排除数据块(前面我们已经提过,数据读取是两步),该算法排除前提是:两个直接后续索引标记的最左主键值与当前标记相同,否则,该块会被选中。
为什么是连续两个,因为只有一个时,这个块可能包含了其他主键值,导致次级索引不是单增,若为范围查询,需解压读取该块数据后才可以判断。
回到测试数据,假定用户 ID 是低基数的,那么,对于按 UserID, URL 排序的数据:
- 相同用户 ID 数据很可能覆盖多个 Granule 和 index mark
- 同用户 ID 的数据里,URL 升序排列。不同用户 ID 的数据,URL 顺序则无法保证。相同用户 ID 的数据块,可以排除值不等于查询 URL 的块。
例如,查询 W3,对于 U1 用户,覆盖 W1 到 W6 的 URL,那么mark0 最大值 W2 < W3,可以排除,mark2 最小值 W4 > W3, 则 mark 2 之后的 U1 块都可以排除。

反之,假定用户 ID 是高基数的,那么,对于按 UserID,URL 排序的数据,相同用户 ID 不能覆盖多个块,同个块中 URL 不是单调递增,导致查询 URL 时有更多的块被选中。包括下图中 Granule1 和 Granule3 这两个我们认为可以直接排除的块也被选中了。
同样的查询 W3,U1 mark0 包含了 W3 范围,不能排除,U2 mark1 包含 U1,不能排除,同样地,U3、U4 也不能排除。
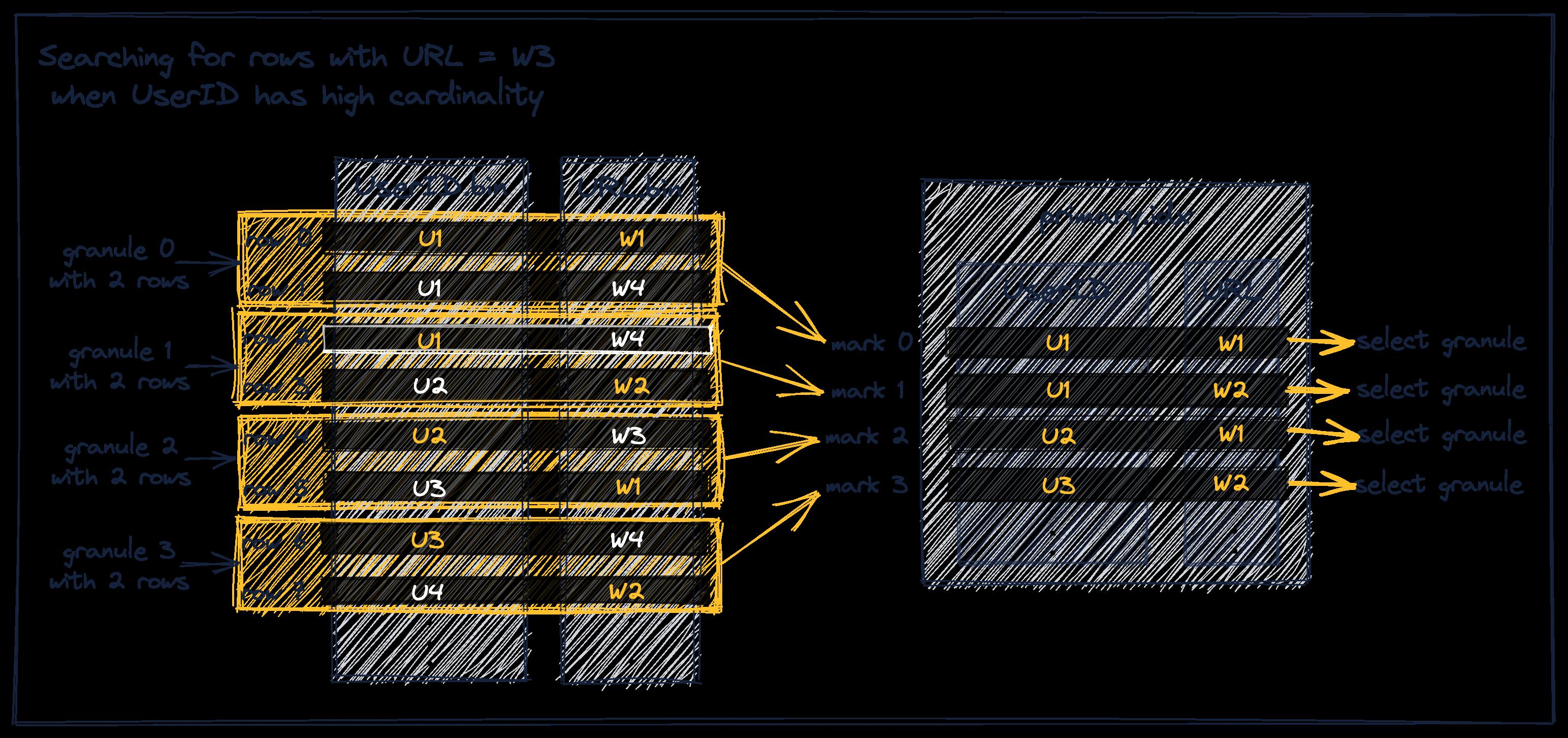
因此,对于低基高基混合的数据,如果均有查询、排序需求,应当按先低基再高基的主键顺序。否则低基的列查询会容易触发全表扫描。
3.3 主键排列对数据压缩率的影响
前面提到了数据的局部性,以及排序对此值的影响。
对比高低基列排序下,对 UserID 存储(因为它是次级索引)的影响,先低后高的 hits_IsRobot_UserID_URL 表,未压缩的数据是压缩后的 28 倍,而先高后低的 hits_URL_UserID_IsRobot 则只有 3 倍,压缩效率很低。查询时解压所需的内存也会随着上升。
SELECT
table AS Table,
name AS Column,
formatReadableSize(data_uncompressed_bytes) AS Uncompressed,
formatReadableSize(data_compressed_bytes) AS Compressed,
round(data_uncompressed_bytes / data_compressed_bytes, 0) AS Ratio
FROM system.columns
WHERE ((table = 'hits_URL_UserID_IsRobot') OR (table = 'hits_IsRobot_UserID_URL')) AND (name = 'UserID')
ORDER BY Ratio ASC
Query id: e8a8973b-b466-475d-9f54-fb15998a5a79
┌─Table───────────────────┬─Column─┬─Uncompressed─┬─Compressed─┬─Ratio─┐
│ hits_URL_UserID_IsRobot │ UserID │ 33.83 MiB │ 11.79 MiB │ 3 │
│ hits_IsRobot_UserID_URL │ UserID │ 33.71 MiB │ 1.19 MiB │ 28 │
└─────────────────────────┴────────┴──────────────┴────────────┴───────┘
作为最低基数的 IsRobot,则影响更大
SELECT
table AS Table,
name AS Column,
formatReadableSize(data_uncompressed_bytes) AS Uncompressed,
formatReadableSize(data_compressed_bytes) AS Compressed,
round(data_uncompressed_bytes / data_compressed_bytes, 0) AS Ratio
FROM system.columns
WHERE ((table = 'hits_URL_UserID_IsRobot') OR (table = 'hits_IsRobot_UserID_URL')) AND (name = 'IsRobot')
ORDER BY Ratio ASC
Query id: 608474b3-6699-4055-9352-df2045c53364
┌─Table───────────────────┬─Column──┬─Uncompressed─┬─Compressed─┬─Ratio─┐
│ hits_URL_UserID_IsRobot │ IsRobot │ 8.46 MiB │ 338.76 KiB │ 26 │
│ hits_IsRobot_UserID_URL │ IsRobot │ 8.43 MiB │ 38.49 KiB │ 224 │
└─────────────────────────┴─────────┴──────────────┴────────────┴───────┘
而高基数的 URL,如何排序,在哪个表,对存储效率的影响则很不明显
SELECT
table AS Table,
name AS Column,
formatReadableSize(data_uncompressed_bytes) AS Uncompressed,
formatReadableSize(data_compressed_bytes) AS Compressed,
round(data_uncompressed_bytes / data_compressed_bytes, 0) AS Ratio
FROM system.columns
WHERE ((table = 'hits_URL_UserID_IsRobot') OR (table = 'hits_IsRobot_UserID_URL')) AND (name = 'URL')
ORDER BY Ratio ASC
Query id: 2b6c5e4b-5d78-4d69-8664-431c04454c1b
┌─Table───────────────────┬─Column─┬─Uncompressed─┬─Compressed─┬─Ratio─┐
│ hits_IsRobot_UserID_URL │ URL │ 663.07 MiB │ 183.61 MiB │ 4 │
│ hits_URL_UserID_IsRobot │ URL │ 665.62 MiB │ 139.80 MiB │ 5 │
└─────────────────────────┴────────┴──────────────┴────────────┴───────┘
SELECT
table AS Table,
name AS Column,
formatReadableSize(data_uncompressed_bytes) AS Uncompressed,
formatReadableSize(data_compressed_bytes) AS Compressed,
round(data_uncompressed_bytes / data_compressed_bytes, 0) AS Ratio
FROM system.columns
WHERE ((table = 'hits_URL_UserID') OR (table = 'hits_UserID_URL')) AND (name = 'URL')
ORDER BY Ratio ASC
Query id: 8f42d6b7-a930-440b-9217-4e3cec638662
┌─Table───────────┬─Column─┬─Uncompressed─┬─Compressed─┬─Ratio─┐
│ hits_UserID_URL │ URL │ 665.62 MiB │ 174.01 MiB │ 4 │
│ hits_URL_UserID │ URL │ 665.62 MiB │ 131.09 MiB │ 5 │
└─────────────────┴────────┴──────────────┴────────────┴───────┘
3.4 多个高基数高效查询
多个高基数主键情况下,无论哪种主键顺序,查询次级主键都可能触发全表扫描。
还有什么方法优化呢?ClickHouse 并没有像 MySQL 一样提供立竿见影的二级索引。只有:
- 同为稀疏索引的 DataSkippingIndexes (之后展开)
- 创建多个主键索引。
创建多个主键索引的名字很有迷惑性,ClickHouse 还提供了三种方式,但其本质都是创建一张影子表,区别只是影子表对于客户端是否透明。即:客户端发起请求,服务端能否根据查询条件自动选择命中最左索引的表。
**注:**在 MySQL 等数据库,影子表可能是服务于表切换等过程的中间表,用后即弃,但此处是服务于真实请求的隐藏表
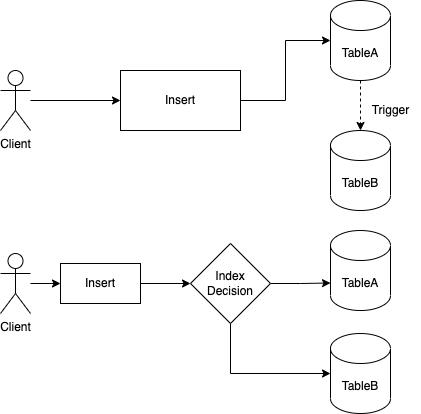
-
创建另一张相同的表,通过物化视图同步写入,但客户端需要根据查询手动指定表
-
通过隐藏的存储数据的物化视图同步写入,只需要在创建物化视图时使用 POPULATE 参数,ClickHouse 就会自动创建一张隐藏表,源表的写入会自动触发写入到隐藏表(包括旧数据,一般的物化视图只从创建时触发)。但客户端仍需手动指定。
-- POPULATE
CREATE MATERIALIZED VIEW mv_hits_URL_UserID
ENGINE = MergeTree()
PRIMARY KEY (URL, UserID)
ORDER BY (URL, UserID, EventTime)
POPULATE
AS SELECT * FROM hits_UserID_URL;
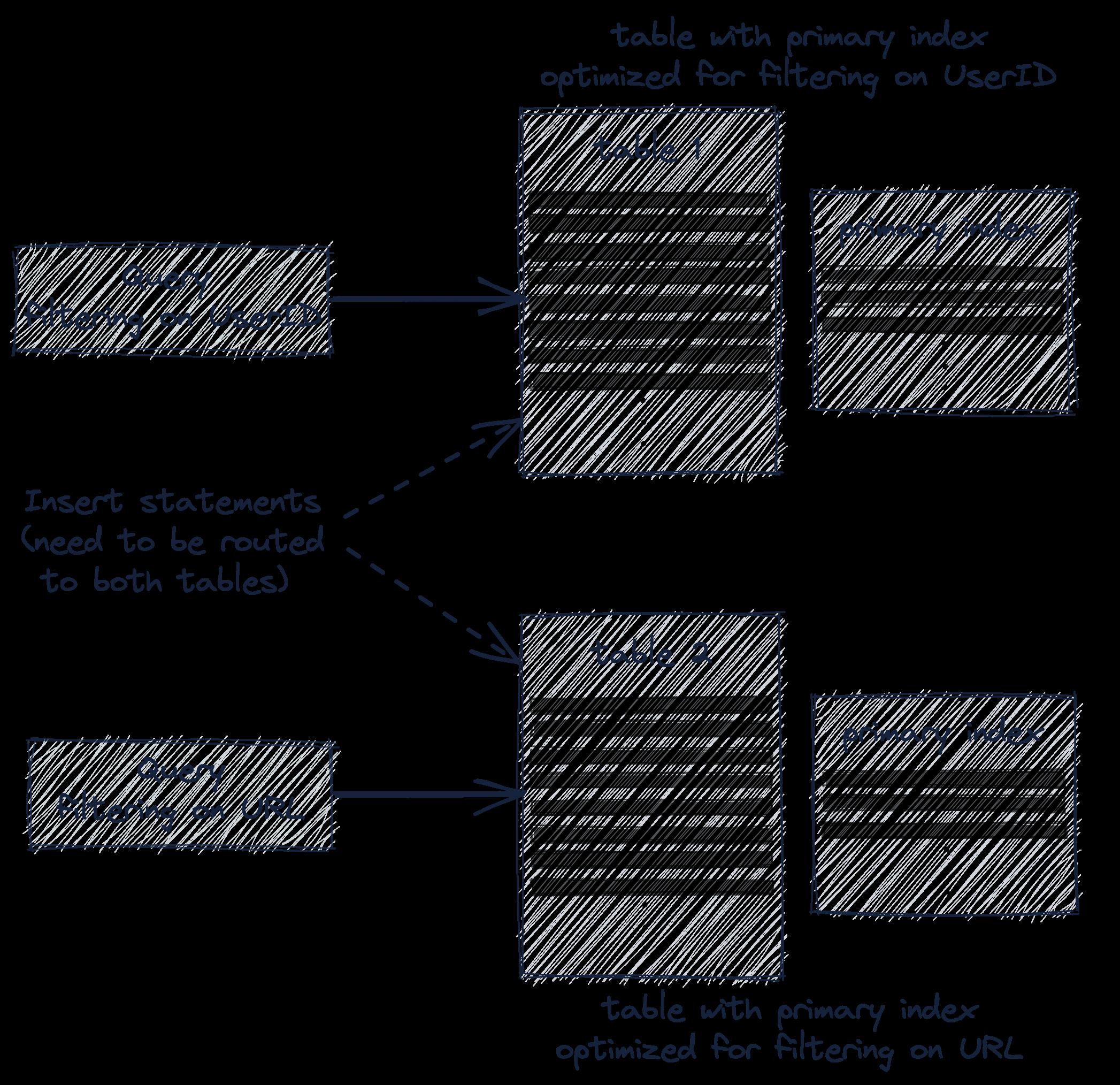
- 通过投影(Projection)创建隐藏表
下面的语句表示创建按 URL,UserID 排序的隐藏表
ALTER TABLE hits_UserID_URL
ADD PROJECTION prj_url_userid
(
SELECT *
ORDER BY (URL, UserID)
);
下面的语句表示立刻同步数据到隐藏表
ALTER TABLE hits_UserID_URL
MATERIALIZE PROJECTION prj_url_userid;
创建完毕后,ClickHouse 将自动根据语句估计扫描的数据量,选择扫描数据量低的表。
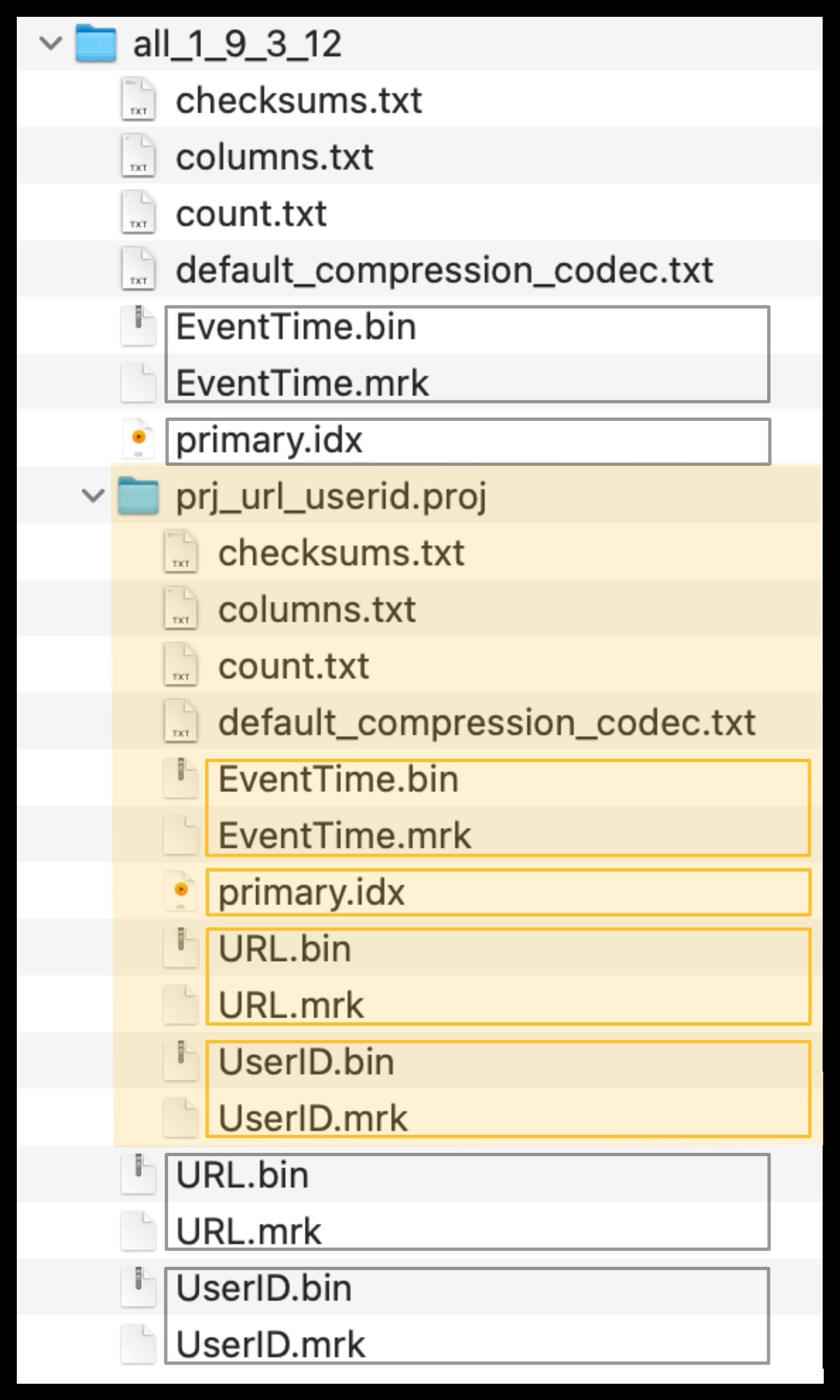
可见,无论哪种方式,都是以空间换时间,且换的效率远不如 MySQL。这也是在选型数据库时,需要考虑的一个方面:有查询多列高基数需求时,能接受多大的空间冗余?
以上是关于主键顺序影响——如何优化 ClickHouse 索引的主要内容,如果未能解决你的问题,请参考以下文章