“无架构”和“MVP”都救不了业务代码,MVVM能力挽狂澜?
Posted bug樱樱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了“无架构”和“MVP”都救不了业务代码,MVVM能力挽狂澜?相关的知识,希望对你有一定的参考价值。
复杂度
android 架构演进系列是围绕着复杂度向前推进的。
软件的首要技术使命是“管理复杂度” —— 《代码大全》
因为低复杂度才能降低理解成本和沟通难度,提升应对变更的灵活性,减少重复劳动,最终提高代码质量。
架构的目的在于“将复杂度分层”
复杂度为什么要被分层?
若不分层,复杂度会在同一层次展开,这样就太 … 复杂了。
举一个复杂度不分层的例子:
小李:“你会做什么菜?”
小明:“我会做用土鸡生的土鸡蛋配上切片的番茄,放点油盐,开火翻炒的番茄炒蛋。”
听了小明的回答,你还会和他做朋友吗?
小明把不同层次的复杂度以不恰当的方式揉搓在一起,让人感觉是一种由“没有必要的具体”导致的“难以理解的复杂”。
小李其实并不关心土鸡蛋的来源、番茄的切法、添加的佐料、以及烹饪方式。
这样的回答除了难以理解之外,局限性也很大。因为它太具体了!只要把土鸡蛋换成洋鸡蛋、或是番茄片换成块、或是加点糖、或是换成电磁炉,其中任一因素发生变化,小明就不会做番茄炒蛋了。
再举个正面的例子,TCP/IP 协议分层模型自下到上定义了五层:
- 物理层
- 数据链路成
- 网络层
- 传输层
- 应用层
其中每一层的功能都独立且明确,这样设计的好处是缩小影响面,即单层的变动不会影响其他层。
这样设计的另一个好处是当专注于一层协议时,其余层的技术细节可以不予关注,同一时间只需要关注有限的复杂度,比如传输层不需要知道自己传输的是 HTTP 还是 FTP,传输层只需要专注于端到端的传输方式,是建立连接,还是无连接。
有限复杂度的另一面是“下层的可重用性”。当应用层的协议从 HTTP 换成 FTP 时,其下层的内容不需要做任何更改。
引子
该系列的前三篇结合“搜索”这个业务场景,讲述了不使用架构写业务代码会产生的痛点:
- 低内聚高耦合的绘制:控件的绘制逻辑散落在各处,散落在各种 Activity 的子程序中(子程序间相互耦合),分散在现在和将来的逻辑中。这样的设计增加了界面刷新的复杂度,导致代码难以理解、容易改出 Bug、难排查问题、无法复用。
- 耦合的非粘性通信:Activity 和 Fragment 通过获取对方引用并互调方法的方式完成通信。这种通信方式使得 Fragment 和 Activity 耦合,从而降低了界面的复用度。并且没有一种内建的机制来轻松的实现粘性通信。
- 上帝类:所有细节都在界面被铺开。比如数据存取,网络访问这些和界面无关的细节都在 Activity 被铺开。导致 Activity 代码不单纯、高耦合、代码量大、复杂度高、变化源不单一、改动影响范围大。
- 界面 & 业务:界面展示和业务逻辑耦合在一起。“界面该长什么样?”和“哪些事件会触发界面重绘?”这两个独立的变化源没有做到关注点分离。导致 Activity 代码不单纯、高耦合、代码量大、复杂度高、变化源不单一、改动影响范围大、易改出 Bug、界面和业务无法单独被复用。
详细分析过程可以点击下面的链接:
紧接着又用了三篇讲述了如何使用 MVP 架构对该业务场景的重构过程。MVP 的确解决了一些问题,但也引入了新问题:
- 分层:MVP 最大的贡献在于将界面绘制与业务逻辑分层,前者是 MVP 中的 V(View),后者是 MVP 中的 P(Presenter)。分层实现了业务逻辑和界面绘制的解耦,让各自更加单纯,降低了代码复杂度。
- 面向接口通信:MVP 将业务和界面分层之后,各层之间就需要通信。通信通过接口实现,接口把做什么和怎么做分离,使得关注点分离成为可能:接口的持有者只关心做什么,而怎么做留给接口的实现者关心。界面通过业务接口向 Presenter 发出请求以触发业务逻辑,这使得它不需要关心业务逻辑的实现细节。Presenter 通过 view 层接口返回响应以指导界面刷新,这使得它不需要关心界面绘制的细节。
- 有限的解耦:因为 View 层接口的存在,迫使 Presenter 得了解该把哪个数据塞给哪个 View 层接口。这是一种耦合,Presenter 和这个具体的 View 层接口耦合,较难复用于其他业务。
- 有限内聚的界面绘制:MVP 并未向界面提供唯一 Model,而是将描述一个完整界面的 Model 分散在若干 View 层接口回调中。这使得界面的绘制无法内聚到一点,增加了界面绘制逻辑维护的复杂度。
- 困难重重的复用:理论上,界面和业务分层之后,各自都更加单纯,为复用提供了可能性。但不管是业务接口的复用,还是View层接口的复用都相当别扭。
- Presenter 与界面共存亡:这个特性使得 MVP 无法应对横竖屏切换的场景。
- 无内建跨界面(粘性)通信机制:MVP 无法优雅地实现跨界面通信,也未内建粘性通信机制,得借助第三方库实现。
- 生命周期不友好:MVP 并未内建生命周期管理机制,易造成内存泄漏、crash、资源浪费。
详细分析过程可以点击下面的链接:
从这一篇开始,试着引入 MVVM 架构的思想进行搜索业务场景的重构,看看是否能解决一些痛点。
在重构之前,再介绍下搜索的业务场景,该功能示意图如下:
业务流程如下:在搜索条中输入关键词并同步展示联想词,点联想词跳转搜索结果页,若无匹配结果则展示推荐流,返回时搜索历史以标签形式横向铺开。点击历史可直接发起搜索跳转到结果页。
将搜索业务场景的界面做了如下设计:
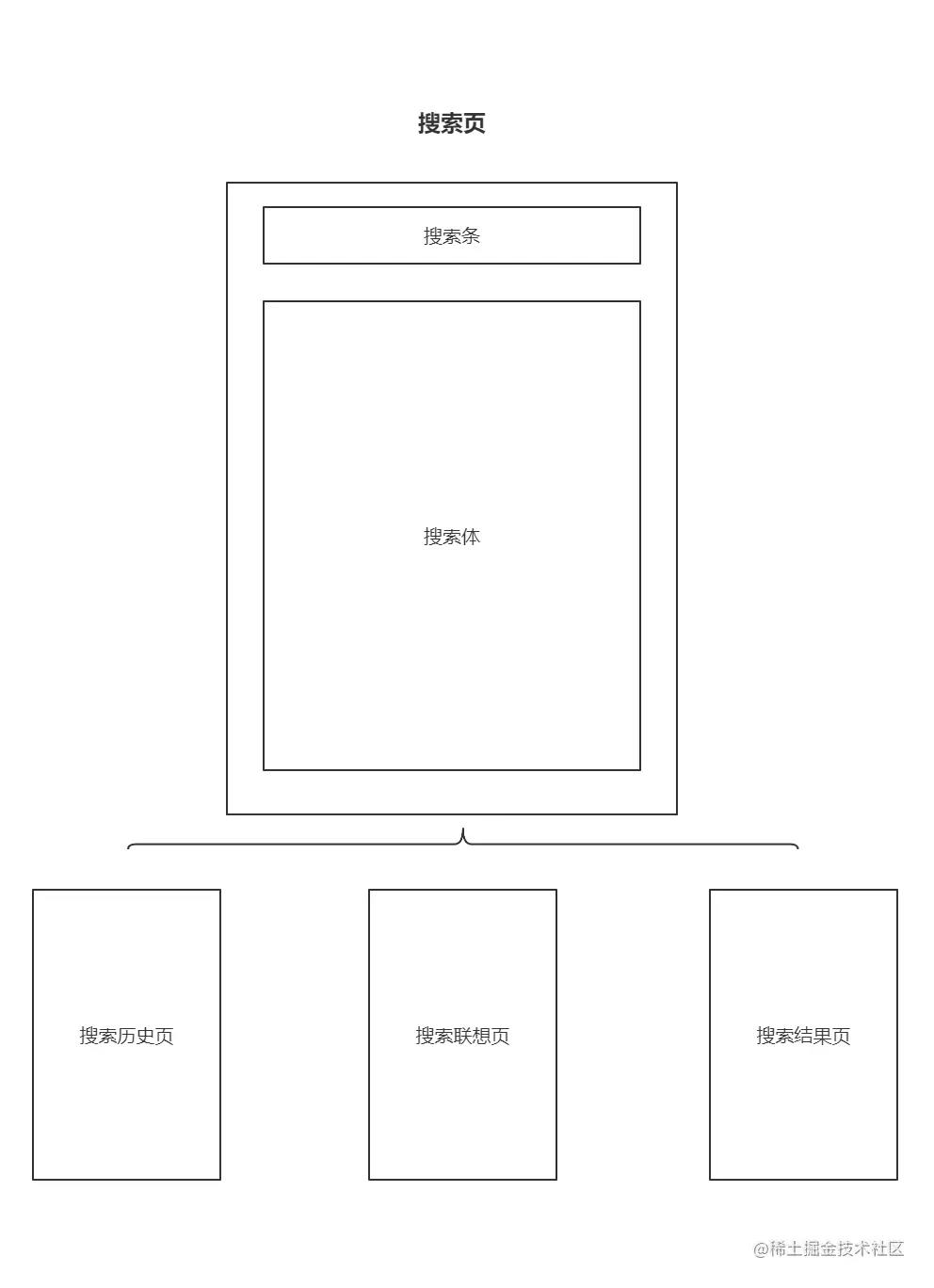
搜索页用Activity来承载,它被分成两个部分,头部是常驻在 Activity 的搜索条。下面的“搜索体”用Fragment承载,它可能出现三种状态 1.搜索历史页 2.搜索联想页 3.搜索结果页。
Fragment 之间的切换采用 Jetpack 的Navigation。关于 Navigation 详细的介绍可以点击Navigation 组件使用入门 | Android 开发者 | Android Developers
上一篇引入了 MVVM 中两个重要的概念 ViewModel 和 LiveData。它俩搭配实现了“生命周期更长的数据持有者”并“以数据驱动的方式”刷新界面,使得界面和业务逻辑更加解耦。
让人又爱又恨的数据重放
输入关键词后会自动拉取接口并展示联想词。
这是一个跨界面通信的场景,因为搜索框在 Activity 而联想页是子 Fragment。拉取接口的动作在 Activity 触发,它得把数据传递给 Fragment 进行展示。
在没有粘性通信加持的情况下,可以有下面两个解决方案:
- 发广播:但这里有一个坑,会导致 Fragment 接收不到广播。(因为发送动作在注册广播之前)
- 通过界面跳转时携带参数:会引入参数的序列化和反序列化,略耗性能。
关于上两个解决方案缺点的详细分析可以点击写业务不用架构会怎么样?(三)
若觉得第二点的性能损耗不是问题的话,它也不是一个通用的方案。当没有发生界面跳转时,就无法使用该方案。比如,当点击联想词时是从联想页跳到结果页,但数据传递却需要从联想页到历史页(点击联想词也视为一次搜索行为,得更新历史),此时界面跳转和数据传递的方向不一致。
爱
粘性通信是这个场景的最优解。因为粘性意味着数据可以重放,即使在数据发送之后才注册观察者,刚发送的数据照样会重新分发给新的观察者。
对于当前场景来说,Activity 只管拉取联想词并递交给一个粘性的数据持有者,然后触发跳转联想页,待联想页构建完毕后才观察已生成的联想词。
输入联想这个场景需要对拉接口做限频,若每次输入变化都拉接口的话,太耗性能及流量了。遂将输入关键词组织成一个流:
etSearch.textChangeFlow b, input -> input.toString()
// 刷新搜索条
.onEach searchViewModel.input(it)
.flowOn(Dispatchers.Main)
.filter it.isNotEmpty()
.debounce(300) // 300 ms 限频
.flatMapLatest
flow
// 拉取联想词
emit(searchViewModel.fetchHint(it))
.flowOn(Dispatchers.IO)
.onEach hints ->
// 跳转到联想页
searchViewModel.setHints(etSearch.text.toString(), hints)
.launchIn(lifecycleScope)
上述代码将 EditText 的输入组织成了一个 Flow,这样就可以使用 debounce() 方便地限制拉取联想词的频次。关于流的详细分析可以点击Kotlin 异步 | Flow 限流的应用场景及原理
同时得为 SearchViewModel 新增和搜索联想相关的两个业务动作及对应的数据:
class SearchViewModel : ViewModel()
private val repository: SearchRepository = SearchRepository()
// 联想词数据
val hintsLiveData = MutableLiveData<List<SearchHint>>()
// 拉取联想词
suspend fun fetchHint(keyword: String): List<String>
return repository.fetchSearchHint(keyword)
// 跳转联想页
fun setHints(keyword: String, hints: List<String>)
hintsLiveData.value = hints.map SearchHint(keyword, it)
其中 Repository 是对访问数据的封装,这里用到它访问接口拉取联想词的能力。这个层次结构和 MVP 一模一样:
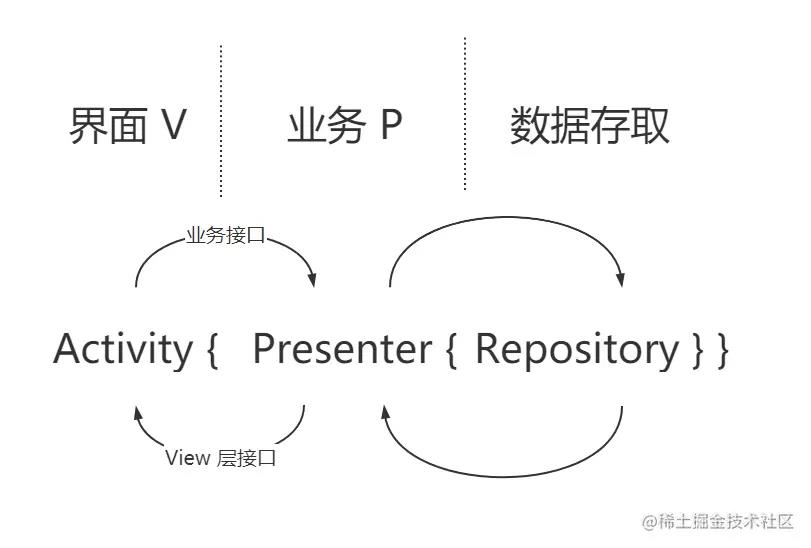
只不过现在中间的 Presenter 被换成了 ViewModel。
关于数据访问层的设计详解可以点击MVP 架构最终审判 —— MVP 解决了哪些痛点,又引入了哪些坑?(二)
最后只需要在联想页中观察粘性数据即可:
class SearchHintFragment : BaseSearchFragment()
val searchViewModel: SearchViewModel by activityViewModels<SearchViewModel>()
override fun onViewCreated(view: View, savedInstanceState: Bundle?)
super.onViewCreated(view, savedInstanceState)
// 观察联想数据并传递给列表的 Adapter
searchViewModel.hintsLiveData.observe(viewLifecycleOwner)
hintsAdapter.dataList = it
此处的 onViewCreated() 必然晚于 hintsLiveData 被设值的时刻。粘性的 LiveData 保证了联想词正确地展示。
粘性是 LiveData 自带的属性,它是怎么实现粘性的?
- LiveData 的值被存储在内部的字段中,直到有更新的值覆盖,所以值是持久的。
- 两种场景下 LiveData 会将存储的值分发给观察者。一是值被更新,此时会遍历所有观察者并分发之。二是新增观察者或观察者生命周期发生变化(至少为 STARTED),此时只会给单个观察者分发值。
- LiveData 的观察者会维护一个“值的版本号”,用于判断上次分发的值是否是最新值。该值的初始值是-1,每次更新 LiveData 值都会让版本号自增。
- LiveData 并不会无条件地将值分发给观察者,在分发之前会经历三道坎:1. 数据观察者是否活跃。2. 数据观察者绑定的生命周期组件是否活跃。3. 数据观察者的版本号是否是最新的。
- “新观察者”被“老值”通知的现象叫“粘性”。因为新观察者的版本号总是小于最新版号,且添加观察者时会触发一次老值的分发。
关于 LiveData 粘性更详细的源码分析可以点击LiveData 面试题库、解答、源码分析
恨
但粘性有时候会产生麻烦.
先搜索“1”,然后返回到历史页,弹出 toast “新搜索词排在最前面”,继续输入“2”,此时并未触发搜索行为,只是进行了联想(2不会被记入历史),但当返回历史,上一次的 toast 再次弹出。
代码实现如下:
class SearchViewModel : ViewModel()
val rearrangeLiveData = MutableLiveData<String>()
val historyLiveData = MutableLiveData<HistoryModel>()
fun search(keyword: String)
...
historyLiveData.value =
historyLiveData.value?.addHistory(keyword) ?: HistoryModel(mutableListOf(keyword),false)
// 在触发新搜索时提示
rearrangeLiveData.value = "新搜索词汇排在最前面"
在 SearchViewModel 中新增了一个数据,它表示 toast 的内容。
然后在历史页观察该数据,并弹出 toast:
class SearchHistoryFragment : BaseSearchFragment()
override fun onViewCreated(view: View, savedInstanceState: Bundle?)
super.onViewCreated(view, savedInstanceState)
searchViewModel.rearrangeLiveData.observe(viewLifecycleOwner)
Toast.makeText(context,it,Toast.LENGTH_SHORT).show()
之所以会弹两次 toast 是因为“历史页被重建+粘性数据”。
当从历史页跳转到联想页时,它的 onDestroyView() 会被调用,所以返回时得重新构建视图,即会触发 onCreateView() -> onViewCreated()。和 toast 相关的 LiveData 正好是在 onViewCreated() 中注册观察者的,重新构建意味着重新注册了一个观察者,又因为 LiveData 是粘性的,所以老数据会分发给新观察者,遂 toast 又弹了一次。
这个 case 中,粘性对历史数据是友好的,因为当历史页重建时,需要重新绘制既有的历史搜索标签。真实让人又爱又恨的粘性。
针对 LiveData 的粘性,网上有各种解决方案,关于它们孰优孰劣的详细分析可以点击LiveData 面试题库、解答、源码分析
生命周期安全 & 无内存泄漏
上面弹 toast 的 gif 图中有一个细节,触发搜索行为的瞬间并未弹出 toast,而是等到界面返回了历史页才弹出。
但代码明明是在触发搜索行为的时候就调用了的:
class SearchViewModel : ViewModel()
val rearrangeLiveData = MutableLiveData<String>()
fun search(keyword: String)
...
// 在触发新搜索时提示
rearrangeLiveData.value = "新搜索词汇排在最前面"
因为观察数据是在历史页进行的。触发搜索联想的时候,历史页的生命周期已经走到了 onDestroyView(),即处于不活跃状态。
此时 LiveData 内部会对处于 destroy 状态的观察者进行清理。以保证数据不会再推送给不活跃的观察者,造成不必要的 crash。及时移除观察者也避免了更长生命周期的观察者持有界面造成内存泄漏的风险。(ViewModel 持有 LiveData,LiveData 持有观察者,观察者是匿名内部类,所以它持有界面引用)
关于这一点源码级别的分析可以点击LiveData 面试题库、解答、源码分析
所以使用 LiveData 时就特别省心,只管赋值就好,不用担心界面生命周期以及内存泄漏问题。
多界面共享业务逻辑
整个搜索业务中,触发搜索行为的有3个地方,分别是搜索页的搜索按钮(搜索 Activity)、点击搜索历史标签(历史 Fragment)、点击搜索联想词(联想 Fragment)。这三个触发点分别位于三个不同的界面。
在 MVP 架构中触发搜索的业务逻辑被封装在 SearchPresenter 的业务接口中:
class SearchPresenterImpl(private val searchView: SearchView) : SearchPresenter
// 历史列表
private val historys = mutableListOf<String>()
override fun search(keyword: String, from: SearchFrom)
// 跳转到搜索结果页
searchView.gotoSearchPage(keyword, from)
// 拉升搜索条
searchView.stretchSearchBar(true)
// 隐藏搜索按钮
searchView.showSearchButton(false)
// 更新历史
if (historys.contains(keyword))
historys.remove(keyword)
historys.add(0, keyword)
else
historys.add(0, keyword)
if (historys.size > 11) historys.removeLast()
// 刷新搜索历史
searchView.showHistory(historys)
// 搜索历史持久化
scope.launch searchRepository.putHistory(historys)
理论上,三个不同的界面应该都调用这个方法触发搜索,这使得搜索这个动作的业务实现内聚于一个方法内。但在 MVP 中要实现这一点不太容易。
最简单的办法是在 Fragment 中获取 Activity 实例,然后再获取其成员变量 SearchPresenter:
// SearchHintFragment.kt
private val presenter by lazy
(requireActivity() as? TemplateSearchActivity)?.searchPresenter
类型强转的代码都是耦合的,强转为 TemplateSearchActivity 就意味着和这个具体的 Activity 耦合,使得 SearchHintFragment 不能脱离它存在,也就没有单独复用的可能性(比如另一个搜索场景中联想页一模一样,它就无法被复用)
ViewModel 巧妙地解决了这个问题。
虽然 ViewModel 还是在 Activity 中构建,但它并不是直接存储在 Activity 中,而是存在了一个叫ViewModelStore的类中:
public class ViewModelStore
// 存放 ViewModel 的 HashMap
private final HashMap<String, ViewModel> mMap = new HashMap<>();
// 存 ViewModel
final void put(String key, ViewModel viewModel)
ViewModel oldViewModel = mMap.put(key, viewModel);
if (oldViewModel != null)
oldViewModel.onCleared();
// 取 ViewModel
final ViewModel get(String key)
return mMap.get(key);
Activity 负责提供 ViewModelStore:
// Activity 基类实现了 ViewModelStoreOwner 接口
public class ComponentActivity
extends androidx.core.app.ComponentActivity
implements LifecycleOwner, ViewModelStoreOwner
// Activity 持有 ViewModelStore 实例
private ViewModelStore mViewModelStore;
public ViewModelStore getViewModelStore()
if (mViewModelStore == null)
// 获取配置无关实例
NonConfigurationInstances nc =
(NonConfigurationInstances) getLastNonConfigurationInstance();
if (nc != null)
// 从配置无关实例中恢复 ViewModel商店
mViewModelStore = nc.viewModelStore;
if (mViewModelStore == null)
mViewModelStore = new ViewModelStore();
return mViewModelStore;
// 静态的配置无关实例
static final class NonConfigurationInstances
// 持有 ViewModel 商店实例
ViewModelStore viewModelStore;
...
其中 ViewModelStoreOwner 用于描述如何构建 ViewModelStore:
public interface ViewModelStoreOwner
ViewModelStore getViewModelStore();
Activity 中通过如下代码构建 ViewModel 实例:
// TemplateSearchActivity.kt
val searchViewModel: SearchViewModel =
ViewModelProvider(this)[SearchViewModel::class.java]
这行代码构建了 ViewModel 的实例,再把它存放在 TemplateSearchActivity 提供的 ViewModelStore 中。
子 Fragment 通过如下代码获取 父 Activity 的 ViewModel 实例:
val searchViewModel: SearchViewModel by activityViewModels<SearchViewModel>()
其中activityViewModels()是 androidx.fragment:fragment-ktx 提供的一个扩展方法:
public inline fun <reified VM : ViewModel> Fragment.activityViewModels(
noinline factoryProducer: (() -> Factory)? = null
): Lazy<VM> = createViewModelLazy(
VM::class, requireActivity().viewModelStore ,
requireActivity().defaultViewModelCreationExtras ,
// 默认使用 activity 提供的 ViewModelProvider.Factory
factoryProducer ?: requireActivity().defaultViewModelProviderFactory
)
// 惰性构建 ViewModel
public fun <VM : ViewModel> Fragment.createViewModelLazy(
viewModelClass: KClass<VM>,
storeProducer: () -> ViewModelStore,
extrasProducer: () -> CreationExtras = defaultViewModelCreationExtras ,
factoryProducer: (() -> Factory)? = null
): Lazy<VM>
val factoryPromise = factoryProducer ?:
defaultViewModelProviderFactory
return ViewModelLazy(viewModelClass, storeProducer, factoryPromise, extrasProducer)
// 惰性的 ViewModel
public class ViewModelLazy<VM : ViewModel> (
private val viewModelClass: KClass<VM>,
private val storeProducer: () -> ViewModelStore,
private val factoryProducer: () -> ViewModelProvider.Factory
) : Lazy<VM>
// ViewModel 实例缓存
private var cached: VM? = null
override val value: VM
get()
val viewModel = cached
return if (viewModel == null)
val factory = factoryProducer()
val store = storeProducer()
// 构建 ViewModel 实例
ViewModelProvider(store, factory).get(viewModelClass.java).also
cached = it // 缓存 ViewModel 实例
else
viewModel
override fun isInitialized(): Boolean = cached != null
activityViewModels() 将 ViewModel 的构建封装在一个Lazy里面,表示会惰性计算一次,计算完成后会存入缓存,下次直接获取。所以它必须配合关键词by一起使用。
构建 ViewModel 时传入的 ViewModelProvider.Factory 和 ViewModelStore 都是 activity 的,这样就可以在子 Fragment 中轻松的获取父 Activity 的声明的 ViewModel 了,实现 ViewModel 的共享。
共享 ViewModel 使得 Activity 和 Fragment 可以轻松地获取同一个 ViewModel 实例,所以在它们之间共享业务逻辑或传输数据都变得易如反掌。
新的复杂度
攻击窗口
那些介于同一变量多个引用点之间的代码称为 “攻击窗口”。可能会有新代码加到这种窗口中,不当地修改了这个变量,或者阅读代码的人可能会我忘记该变量应有的值。
一般而言,把对一个变量的引用局部化,即把引用点尽可能集中在一起总是一种很好的做法。这使得代码的阅读者,能每次只关注一部分代码。而如果这些引用点之间的距离非常远,那你就要迫使阅读者的目光在程序里跳来跳去。一个允许任何子程序在任何时间使用任何变量的程序是难于理解的。对于这种程序,你不能只去理解一个子程序,你还必须要理解区域所有使用了相同全局变量的子程序才行,这种程序无论阅读、调试还是修改起来都非常困难。
当代码迁移或重构时,若变量的引用点非常靠近,把相关代码片断重构成独立的子程序就非常容易。
因此,把变量的引用点集中起来除了能降低错误赋值的可能,还能增加代码的可读性,降低代码重构的难度。——《代码大全》
基于上述原因,在定义变量时,应该采用最严格的可见性,然后根据需求扩展变量的作用域:首选将变量局限于某个特定的循环中,然后是局限于某个子程序,其次成为类的私有成员变量,protected 变量,再其次对包可见,最后在迫不得已的情况下再把它作为全局变量。
很不幸 MVVM 架构中,ViewModel 持有的 LiveData 的作用域比想象中的要大,这会带来不可预期的错误。
一开始我是这样定义 LiveData 的:
class SearchViewModel : ViewModel()
val liveData1 = MutableLiveData<String>()
val liveData2 = MutableLiveData<Boolean>()
val liveData3 = MutableLiveData<Int>()
val liveData4 = MutableLiveData<Long>()
这意味着,在界面可以轻松地拿到 MutableLiveData 的引用,然后改变其值。若这种写法泛滥的话,修改 LiveData 值的代码就会散落在各处,增加阅读代码、修改代码、调试代码的困难。
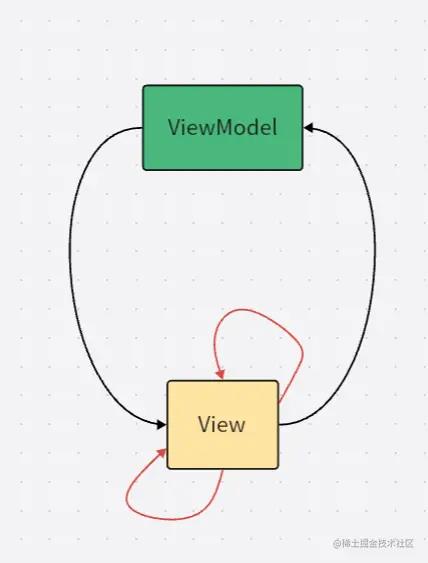
图中的红色线条表示界面通过拿到 LiveData 的引用并修改其值。
不可预期的错误是指,当你通过图中的黑线修改 LiveData 值时,它的值可能和你预期不一致,因为还有 N 个别的地方在偷偷的地修改它。
于是乎有了下面这种写法:
class SearchViewModel : ViewModel()
private val _liveData1 = MutableLiveData<String>()
val liveData1: LiveData<String> = _liveData1
private val liveData2 = MutableLiveData<Boolean>()
val liveData2: LiveData<Boolean> = _liveData2
private val liveData3 = MutableLiveData<Int>()
val liveData3: LiveData<Int> = _liveData3
private val liveData4 = MutableLiveData<Long>()
val liveData4: LiveData<Long> = _liveData4
只暴露 LiveData 给界面,这样界面就不能擅自修改其值。这样写的好处是所有对 LiveData 的写操作都内聚在 ViewModel 内部,而所有消费 LiveData 的观察者都在 ViewModel 外部。 这降低了维护数据的难度:
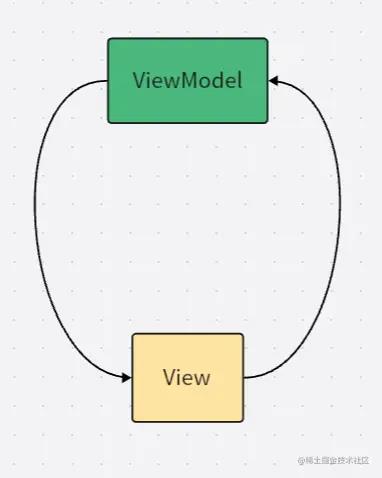
如图所示这就形成了一条“单线数据流”。
为啥单向数据流复杂度就比较低?举个例子,当排查问题时,你想知道到底是哪里修改了 LiveData 的值,在单向数据流的架构中只需要在一个地方打断点就好,因为所有的修改点都收口于此。
上面通过将 MutableLiveda 的作用域收窄简化了数据流动的复杂度。但还有一个复杂度 MVVM 没法化解,因为 LiveData 被定义为 ViewModel 的成员变量,而成员变量的攻击窗口是整个类,因为任何类方法都可以轻松的访问到成员变量。
一个 LiveData 携带着一个 Model,一个 Model 表达这一个界面状态。当新增业务逻辑界面状态发生变化时,首先是在 ViewModel 中新增一个方法以触发业务逻辑,然后在新方法中去修改与该界面状态相关的 LiveData,此时 LiveData 攻击窗口 + 1,处理不好就会变成新增功能导致功能衰退。
纯函数 & 副作用
再从“纯函数 & 副作用”的角度重新审视上述问题:
fun add(a: Int, b: Int)
return a+b
这是一个无副作用的方法,它的结果是可预测的,不会受到除了参数a,b之外其他任何因素的影响。如果输入参数是两个9,返回值必然是18,这个方法执行一万遍结果还是不变,即使方法执行的时候,奥特曼突然出现,结果还是不变。无副作用即可预测,不会发生意料之外的事情。
如果所有的方法都是可以预测的,不会发生意料之外的事情,那该是多美好的一件事情。但往往事与愿违:
var c = 2
fun add(a: Int, b: Int)
return a+b+c
这是一个有副作用的方法,它的结果是不可预测的,因为 c 是一个公共变量,它可能被其他方法访问,其值可能随时发生变化,这导致 add() 的返回值不可预测。
c = 2
add(9,9) // 返回 20
c = 3
add(9,9) // 返回 21
上述代码的执行结果是反直觉的,为啥两次调用 add 的返回值不同?
因为 add() 方法不仅依赖入参还依赖公共变量。你不得不点开 add(),去细究实现细节才能搞懂真相。就好比作者使用晦涩难懂的比喻,为了看明白,不得不逐个百度,再把他们拼凑起来,才能看懂。
除了语义上的难懂,返回值的不可预期也使得程序更容易出错。
更好的写法如下:
fun add(a: Int, b: Int, c: Int)
return a+b+c
var c = 2
add(9, 9, c)
把可能产生副作用的因子作为参数传入,保证方法内部的“无副作用”,这样该方法就可以被安心地调用了。而且该方法也更容易被单元测试了。
但 ViewModel 中所有操纵 LiveData 的函数都不是纯函数,因为 LiveData 是成员变量,这就会发生不可预期的错误。比如测试和你做了同样一段操作,你俩的界面状态就是不一样。因为表面上看执行了相同函数去更新界面状态,但因为它是有副作用的函数,所以不能保证执行两遍就得出相同的结果。这样就为问题的排查设置了重重障碍。
总结
上一篇引入了 MVVM 架构的两个重要概念 ViewModel 以及 LiveData。
通过这一篇的讲述,ViewModel 不仅使得“有免死金牌的业务层”成为可能,也使得跨界面之间的业务逻辑共享以及通信变得轻松。
而 LiveData 不仅使得业务层成为数据持有者以数据驱动刷新界面,还避免了生命周期问题以及内存泄漏风险。
但是 MVVM 引入了新的复杂度,因为更新数据的方法是带有副作用的,与之对应的不可预期的界面状态。看看下一篇的 MVI 是否能药到病除。
作者:唐子玄
链接:https://juejin.cn/post/7175901192650752056
最后
如果想要成为架构师或想突破20~30K薪资范畴,那就不要局限在编码,业务,要会选型、扩展,提升编程思维。此外,良好的职业规划也很重要,学习的习惯很重要,但是最重要的还是要能持之以恒,任何不能坚持落实的计划都是空谈。
如果你没有方向,这里给大家分享一套由阿里高级架构师编写的《Android八大模块进阶笔记》,帮大家将杂乱、零散、碎片化的知识进行体系化的整理,让大家系统而高效地掌握Android开发的各个知识点。
相对于我们平时看的碎片化内容,这份笔记的知识点更系统化,更容易理解和记忆,是严格按照知识体系编排的。
全套视频资料:
一、面试合集
二、源码解析合集
三、开源框架合集

欢迎大家一键三连支持,若需要文中资料,直接点击文末CSDN官方认证微信卡片免费领取↓↓↓
以上是关于“无架构”和“MVP”都救不了业务代码,MVVM能力挽狂澜?的主要内容,如果未能解决你的问题,请参考以下文章