架构师必知必会常见的NoSQL数据库种类以及使用场景
Posted 禅与计算机程序设计艺术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构师必知必会常见的NoSQL数据库种类以及使用场景相关的知识,希望对你有一定的参考价值。

前言
NoSQL数据库是构建高并发大数据互联网应用的必备组件,熟悉理解各种类型nosql数据的特点和应用场景,对提高架构能力有巨大帮助,是高级后端架构师必须理解的知识点。
NoSQL 不是一个工具,而是由多个互补和竞争的工具组成的生态系统。标有NoSQL绰号的工具,提供了一种替代“基于SQL的关系数据库系统”来存储数据的方法。
NoSQL is not a tool, but an ecosystem composed of several complimentary and competing tools.The tools branded with the NoSQL monicker provide an alternative to SQL-based relational database systems for storing data.
NoSQL 前传:SQL 和关系模型
SQL (结构化查询语言)数据库在二十世纪 70 年代初开始流行。
当时,存储非常昂贵,因此软件工程师对其数据库进行规范化以减少数据重复。
此外,二十世纪70年代的软件工程师,通常也遵循瀑布式软件开发模型。在开始开发之前详细规划项目。软件工程师精心创建复杂的实体关系 (E-R) 图,确保已仔细考虑需要存储的所有数据。
由于采用了这种预先计划模型,因此如果开发周期中的需求发生变化,软件工程师就难以调整适应。结果,项目经常超出预算,超过截止日期,无法满足用户需求。

SQL 是一种用于查询数据的声明性语言。声明式语言是一种程序员指定他们希望系统做什么的语言,而不是程序性地定义系统应该如何做的语言。一些示例包括:找到员工 39 的记录,从他们的整个记录中仅投影出员工姓名和电话号码,将员工记录过滤到从事会计工作的员工记录,计算每个部门的员工人数,或加入员工的数据表与经理表。
SQL is a declarative language for querying data. A declarative language is one in which a programmer specifies what they want the system to do, rather than procedurally defining how the system should do it. A few examples include: find the record for employee 39, project out only the employee name and phone number from their entire record, filter employee records to those that work in accounting, count the employees in each department, or join the data from the employees table with the managers table.
大致上,SQL 允许您提出这些问题,而无需考虑数据在磁盘上的布局方式、使用哪些索引来访问数据或使用哪些算法来处理数据。大多数关系数据库的一个重要架构组件是 查询优化器,它决定执行许多逻辑上等效的查询计划中的哪一个以最快地回答查询。这些优化器通常比普通数据库用户更好,但有时他们没有足够的信息或系统模型过于简单,无法生成最有效的执行。
To a first approximation, SQL allows you to ask these questions without thinking about how the data is laid out on disk, which indices to use to access the data, or what algorithms to use to process the data. A significant architectural component of most relational databases is a query optimizer, which decides which of the many logically equivalent query plans to execute to most quickly answer a query. These optimizers are often better than the average database user, but sometimes they do not have enough information or have too simple a model of the system in order to generate the most efficient execution.
关系数据库是实践中最常用的数据库,遵循关系数据模型。在这个模型中,不同的现实世界实体存储在不同的表中。例如,所有员工都可能存储在 Employees 表中,所有部门都可能存储在 Departments 表中。表的每一行都有存储在列中的各种属性。例如,员工可能有员工 ID、薪水、出生日期和名字/姓氏。这些属性中的每一个都将存储在 Employees 表的一列中。
Relational databases, which are the most common databases used in practice, follow the relational data model. In this model, different real-world entities are stored in different tables. For example, all employees might be stored in an Employees table, and all departments might be stored in a Departments table. Each row of a table has various properties stored in columns. For example, employees might have an employee id, salary, birth date, and first/last names. Each of these properties will be stored in a column of the Employees table.
关系模型与 SQL 密切相关。简单的 SQL 查询,例如过滤器,检索其字段匹配某些测试的所有记录(例如,employeeid = 3,或薪水 > $20000)。更复杂的构造会导致数据库做一些额外的工作,例如连接来自多个表的数据(例如,员工 3 工作的部门名称是什么?)。其他复杂的结构,如聚合(例如,我员工的平均工资是多少?)可以导致全表扫描。
The relational model goes hand-in-hand with SQL. Simple SQL queries, such as filters, retrieve all records whose field matches some test (e.g., employeeid = 3, or salary > $20000). More complex constructs cause the database to do some extra work, such as joining data from multiple tables (e.g., what is the name of the department in which employee 3 works?). Other complex constructs such as aggregates (e.g., what is the average salary of my employees?) can lead to full-table scans.
关系数据模型定义了高度结构化的实体,它们之间具有严格的关系。使用 SQL 查询此模型允许复杂的数据遍历,而无需过多的自定义开发。但是,这种建模和查询的复杂性有其局限性:
复杂性导致不可预测性。SQL 的表现力使得推断每个查询的成本以及工作负载的成本具有挑战性。虽然更简单的查询语言可能会使应用程序逻辑复杂化,但它们可以更轻松地配置仅响应简单请求的数据存储系统。
有很多方法可以对问题进行建模。关系数据模型是严格的:分配给每个表的模式指定每一行中的数据。如果我们存储结构化程度较低的数据,或者存储的列中变化较大的行,则关系模型可能会受到不必要的限制。同样,应用程序开发人员可能不会发现关系模型非常适合对每种数据进行建模。例如,很多应用程序逻辑是用面向对象的语言编写的,包括列表、队列和集合等高级概念,一些程序员希望他们的持久层对此进行建模。
如果数据增长超过了一台服务器的容量,那么数据库中的表将不得不跨计算机进行分区。为避免 JOIN 必须跨网络获取不同表中的数据,我们必须对其进行非规范化。非规范化将人们可能想要一次查找的不同表中的所有数据存储在一个地方。这使我们的数据库看起来像一个键查找存储系统,让我们想知道其他数据模型可能更适合这些数据。
任意丢弃多年的设计考虑通常是不明智的。当您考虑将数据存储在数据库中时,请考虑 SQL 和关系模型,它们以数十年的研究和开发为后盾,提供丰富的建模功能,并为复杂的操作提供易于理解的保证。当您遇到特定问题时,NoSQL 是一个不错的选择,例如大量数据、大量工作负载或 SQL 和关系数据库可能未针对其进行优化的困难数据建模决策。
The relational data model defines highly structured entities with strict relationships between them. Querying this model with SQL allows complex data traversals without too much custom development. The complexity of such modeling and querying has its limits, though:
Complexity leads to unpredictability. SQL's expressiveness makes it challenging to reason about the cost of each query, and thus the cost of a workload. While simpler query languages might complicate application logic, they make it easier to provision data storage systems, which only respond to simple requests.
There are many ways to model a problem. The relational data model is strict: the schema assigned to each table specifies the data in each row. If we are storing less structured data, or rows with more variance in the columns they store, the relational model may be needlessly restrictive. Similarly, application developers might not find the relational model perfect for modeling every kind of data. For example, a lot of application logic is written in object-oriented languages and includes high-level concepts such as lists, queues, and sets, and some programmers would like their persistence layer to model this.
If the data grows past the capacity of one server, then the tables in the database will have to be partitioned across computers. To avoid JOINs having to cross the network in order to get data in different tables, we will have to denormalize it. Denormalization stores all of the data from different tables that one might want to look up at once in a single place. This makes our database look like a key-lookup storage system, leaving us wondering what other data models might better suit the data.
It's generally not wise to discard many years of design considerations arbitrarily. When you consider storing your data in a database, consider SQL and the relational model, which are backed by decades of research and development, offer rich modeling capabilities, and provide easy-to-understand guarantees about complex operations. NoSQL is a good option when you have a specific problem, such as large amounts of data, a massive workload, or a difficult data modeling decision for which SQL and relational databases might not have been optimized.
SQL vs NoSQL - Difference B/W SQL & NoSQL Databases

什么是NoSQL?
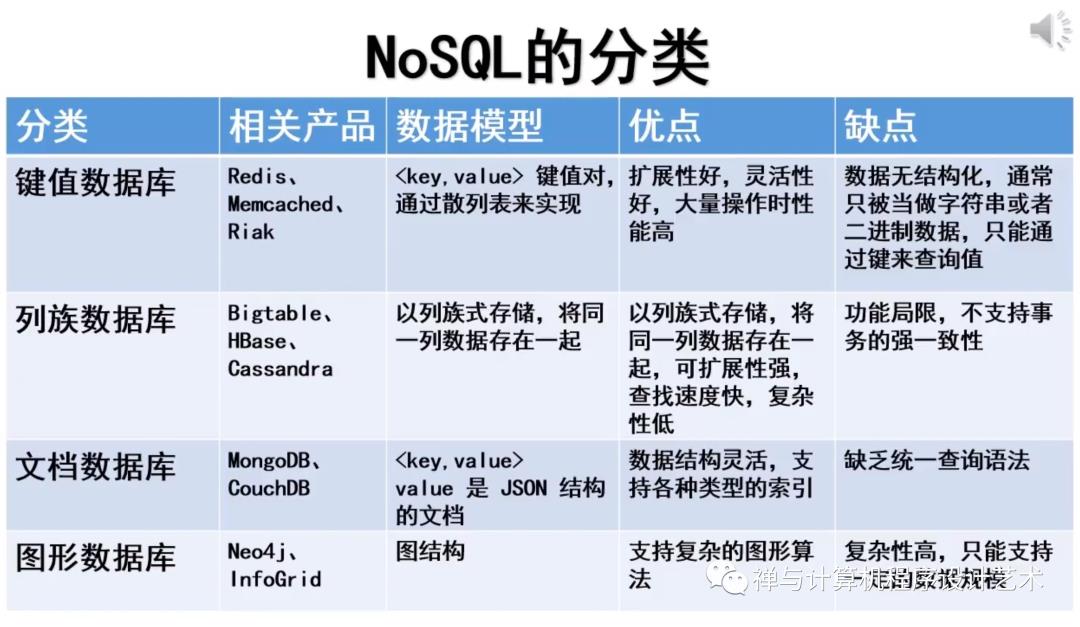
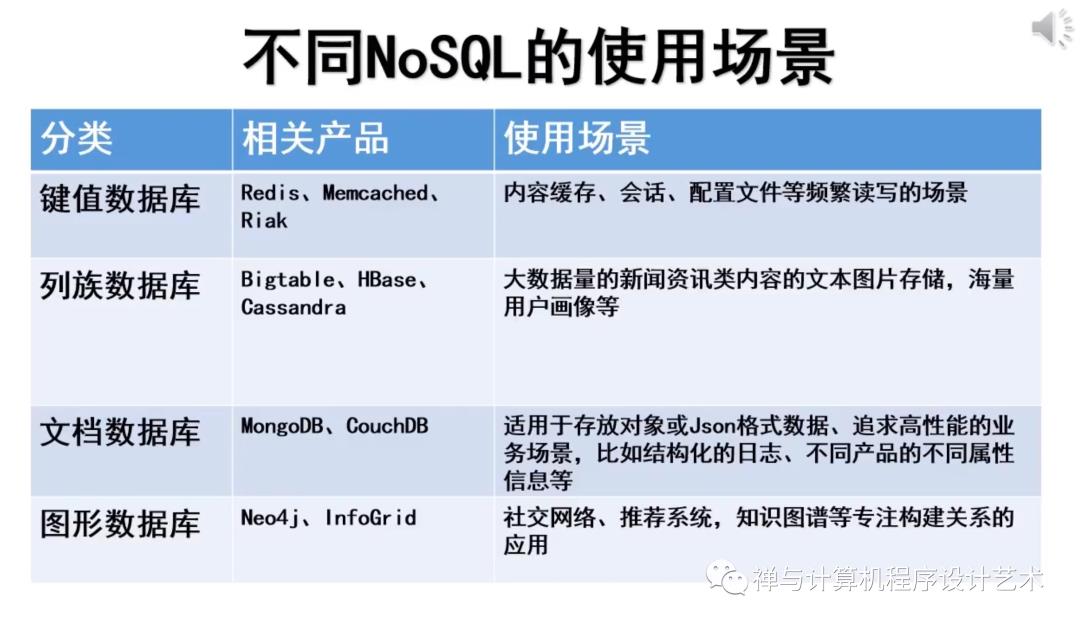
NoSQL 数据库有哪些类型?
随着时间的推移,出现了四种主要的 NoSQL 数据库类型:[文档数据库] (https://www.mongodb.com/document-databases),[键值数据库] (https://www.mongodb.com/key-value-database),宽列存储数据库和图形数据库让我们一起来看看每种类型。
NoSQL 灵感(NoSQL Inspirations)
NoSQL 运动的大部分灵感来自研究社区的论文。虽然许多论文都是 NoSQL 系统设计决策的核心,但有两篇论文尤为突出。
The NoSQL movement finds much of its inspiration in papers from the research community. While many papers are at the core of design decisions in NoSQL systems, two stand out in particular.
Google 的 BigTable [ CDG+06 ] 提出了一个有趣的数据模型,它有助于对多列历史数据进行排序存储。使用基于范围的分层分区方案将数据分发到多个服务器,并以严格的一致性更新数据(我们最终将在 第 13.5 节中定义的概念)。
Google's BigTable [CDG+06] presents an interesting data model, which facilitates sorted storage of multi-column historical data. Data is distributed to multiple servers using a hierarchical range-based partitioning scheme, and data is updated with strict consistency (a concept that we will eventually define in Section 13.5).
Amazon 的 Dynamo [ DHJ+07 ] 使用不同的面向密钥的分布式数据存储。Dynamo 的数据模型更简单,将键映射到特定于应用程序的数据块。分区模型对故障更具弹性,但通过称为最终一致性的更宽松的数据一致性方法来实现该目标。
Amazon's Dynamo [DHJ+07] uses a different key-oriented distributed datastore. Dynamo's data model is simpler, mapping keys to application-specific blobs of data. The partitioning model is more resilient to failure, but accomplishes that goal through a looser data consistency approach called eventual consistency.
我们将更详细地研究这些概念中的每一个,但重要的是要了解其中的许多概念可以混合和匹配。一些 NoSQL 系统(例如 HBase 1)与 BigTable 设计密切相关。另一个名为 Voldemort 2的 NoSQL 系统复制了 Dynamo 的许多功能。还有其他 NoSQL 项目,如 Cassandra 3,从 BigTable(其数据模型)和 Dynamo(其分区和一致性方案)中获取了一些功能。
We will dig into each of these concepts in more detail, but it is important to understand that many of them can be mixed and matched. Some NoSQL systems such as HBase sticks closely to the BigTable design. Another NoSQL system named Voldemort replicates many of Dynamo's features. Still other NoSQL projects such as Cassandra have taken some features from BigTable (its data model) and others from Dynamo (its partitioning and consistency schemes).
特点和注意事项 Characteristics and Considerations
NoSQL 系统与庞大的 SQL 标准分道扬镳,并为构建存储解决方案提供更简单但零碎的解决方案。构建这些系统的信念是,通过简化数据库对数据的操作方式,架构师可以更好地预测查询的性能。在许多 NoSQL 系统中,复杂的查询逻辑留给了应用程序,由于查询中缺乏可变性,导致数据存储具有更可预测的查询性能。
NoSQL systems part ways with the hefty SQL standard and offer simpler but piecemeal solutions for architecting storage solutions. These systems were built with the belief that in simplifying how a database operates over data, an architect can better predict the performance of a query. In many NoSQL systems, complex query logic is left to the application, resulting in a data store with more predictable query performance because of the lack of variability in queries.
NoSQL 系统不仅仅是对关系数据的声明性查询。事务语义、一致性和持久性是银行等组织对数据库需求的保证。 当将几个潜在的复杂操作合并为一个时,事务(Transaction)提供了一种全有或全无的保证,例如从一个账户中扣除资金并将资金添加到另一个账户中。 一致性 确保当值更新时,后续查询将看到更新后的值。 持久性保证一旦一个值被更新,它将被写入稳定的存储(例如硬盘)并且在数据库崩溃时可以恢复。
NoSQL systems part with more than just declarative queries over the relational data. Transactional semantics, consistency, and durability are guarantees that organizations such as banks demand of databases. Transactions provide an all-or-nothing guarantee when combining several potentially complex operations into one, such as deducting money from one account and adding the money to another. Consistency ensures that when a value is updated, subsequent queries will see the updated value. Durability guarantees that once a value is updated, it will be written to stable storage (such as a hard drive) and recoverable if the database crashes.
NoSQL 系统放宽了其中一些保证,对于许多非银行应用程序来说,这一决定可以提供可接受和可预测的行为以换取改进的性能。这些放松与数据模型和查询语言的变化相结合,通常可以在数据增长超出单台机器的能力时,更轻松地跨多台机器安全地分区数据库。
NoSQL systems relax some of these guarantees, a decision which, for many non-banking applications, can provide acceptable and predictable behavior in exchange for improved performance. These relaxations, combined with data model and query language changes, often make it easier to safely partition a database across multiple machines when the data grows beyond a single machine's capability.
NoSQL 系统仍处于起步阶段。本章描述的系统的架构决策证明了不同用户的需求。总结几个开源项目的架构特点最大的挑战是每一个都是一个移动的目标。请记住,各个系统的细节会发生变化。当您在 NoSQL 系统之间进行选择时,您可以使用本章来指导您的思考过程,而不是您的逐个功能产品选择。
NoSQL systems are still very much in their infancy. The architectural decisions that go into the systems described in this chapter are a testament to the requirements of various users. The biggest challenge in summarizing the architectural features of several open source projects is that each one is a moving target. Keep in mind that the details of individual systems will change. When you pick between NoSQL systems, you can use this chapter to guide your thought process, but not your feature-by-feature product selection.
当您考虑 NoSQL 系统时,这里有一个注意事项路线图:
数据和查询模型:您的数据是表示为行、对象、数据结构还是文档?你能要求数据库计算多条记录的聚合吗?
持久性:当你改变一个值时,它会立即进入稳定存储吗?它是否存储在多台机器上以防其中一台机器崩溃?
可扩展性:您的数据是否适合单个服务器?读写量是否需要多个磁盘来处理工作负载?
分区:出于可扩展性、可用性或持久性的原因,数据是否需要存在于多个服务器上?您如何知道哪个记录在哪个服务器上?
一致性:如果您在多个服务器上对记录进行分区和复制,当记录更改时服务器如何协调?
事务语义:当你运行一系列操作时,一些数据库允许你将它们包装在一个事务中,这为事务和当前运行的所有其他事务提供了 ACID(原子性、一致性、隔离性和持久性)保证的一些子集。您的业务逻辑是否需要这些通常伴随性能权衡的保证?
单服务器性能:如果您想将数据安全地存储在磁盘上,哪些磁盘数据结构最适合读取密集型或写入密集型工作负载?写入磁盘是您的瓶颈吗?
分析工作负载:我们将非常关注运行响应式的以用户为中心的 Web 应用程序所需的那种查找繁重的工作负载。在许多情况下,您将希望构建数据集大小的报告,例如聚合多个用户的统计数据。您的用例和工具链是否需要此类功能?
As you think about NoSQL systems, here is a roadmap of considerations:
Data and query model: Is your data represented as rows, objects, data structures, or documents? Can you ask the database to calculate aggregates over multiple records?
Durability: When you change a value, does it immediately go to stable storage? Does it get stored on multiple machines in case one crashes?
Scalability: Does your data fit on a single server? Do the amount of reads and writes require multiple disks to handle the workload?
Partitioning: For scalability, availability, or durability reasons, does the data need to live on multiple servers? How do you know which record is on which server?
Consistency: If you've partitioned and replicated your records across multiple servers, how do the servers coordinate when a record changes?
Transactional semantics: When you run a series of operations, some databases allow you to wrap them in a transaction, which provides some subset of ACID (Atomicity, Consistency, Isolation, and Durability) guarantees on the transaction and all others currently running. Does your business logic require these guarantees, which often come with performance tradeoffs?
Single-server performance: If you want to safely store data on disk, what on-disk data structures are best-geared toward read-heavy or write-heavy workloads? Is writing to disk your bottleneck?
Analytical workloads: We're going to pay a lot of attention to lookup-heavy workloads of the kind you need to run a responsive user-focused web application. In many cases, you will want to build dataset-sized reports, aggregating statistics across multiple users for example. Does your use-case and toolchain require such functionality?







There are various ways to classify NoSQL databases, with different categories and subcategories, some of which overlap. What follows is a non-exhaustive classification by data model, with examples:
| Type | Notable examples of this type |
|---|---|
| Key–value cache | Apache Ignite, Couchbase, Coherence, eXtreme Scale, Hazelcast, Infinispan, Memcached, Redis, Velocity |
| Key–value store | Azure Cosmos DB, ArangoDB, Amazon DynamoDB, Aerospike, Couchbase, ScyllaDB |
| Key–value store (eventually consistent) | Azure Cosmos DB, Oracle NoSQL Database, Riak, Voldemort |
| Key–value store (ordered) | FoundationDB, InfinityDB, LMDB, MemcacheDB |
| Tuple store | Apache River, GigaSpaces, Tarantool, TIBCO ActiveSpaces, OpenLink Virtuoso |
| Triplestore | AllegroGraph, MarkLogic, Ontotext-OWLIM, Oracle NoSQL database, Profium Sense, Virtuoso Universal Server |
| Object database | Objectivity/DB, Perst, ZopeDB, db4o, GemStone/S, InterSystems Caché, JADE, ObjectDatabase++, ObjectDB, ObjectStore, ODABA, Realm, OpenLink Virtuoso, Versant Object Database, ZODB |
| Document store | Azure Cosmos DB, ArangoDB, BaseX, Clusterpoint, Couchbase, CouchDB, DocumentDB, eXist-db, IBM Domino, MarkLogic, MongoDB, RavenDB, Qizx, RethinkDB, Elasticsearch, OrientDB |
| Wide Column Store | Azure Cosmos DB, Amazon DynamoDB, Bigtable, Cassandra, Google Cloud Datastore, HBase, Hypertable, ScyllaDB |
| Native multi-model database | ArangoDB, Azure Cosmos DB, OrientDB, MarkLogic, Apache Ignite,[22][23] Couchbase, FoundationDB, Oracle Database |
| Graph database | Azure Cosmos DB, AllegroGraph, ArangoDB, InfiniteGraph, Apache Giraph, MarkLogic, Neo4J, OrientDB, Virtuoso |
| Multivalue database | D3 Pick database, Extensible Storage Engine (ESE/NT), InfinityDB, InterSystems Caché, jBASE Pick database, mvBase Rocket Software, mvEnterprise Rocket Software, Northgate Information Solutions Reality (the original Pick/MV Database), OpenQM, Revelation Software's OpenInsight (Windows) and Advanced Revelation (DOS), UniData Rocket U2, UniVerse Rocket U2 |
NoSQL 数据和查询模型
NoSQL Data and Query Models
数据库的数据模型指定数据的逻辑组织方式。它的查询模型规定了如何检索和更新数据。常见的数据模型有关系模型、面向键的存储模型或各种图形模型。您可能听说过的查询语言包括 SQL、键查找和 MapReduce。NoSQL 系统结合了不同的数据和查询模型,导致了不同的架构考虑。
The data model of a database specifies how data is logically organized. Its query model dictates how the data can be retrieved and updated. Common data models are the relational model, key-oriented storage model, or various graph models.Query languages you might have heard of include SQL, key lookups, and MapReduce. NoSQL systems combine different data and query models, resulting in different architectural considerations.
基于键的 NoSQL 数据模型——一切皆是映射
Key-based NoSQL Data Models——All is mapping.
NoSQL 系统通常通过将对数据集的查找限制在单个字段中来脱离关系模型和 SQL 的完整表达能力。例如,即使员工有很多属性,您也可能只能通过她的 ID 检索员工。因此,NoSQL 系统中的大多数查询都是基于键查找的。程序员选择一个键来标识每个数据项,并且在大多数情况下,只能通过在数据库中查找键来检索项目。
NoSQL systems often part with the relational model and the full expressivity of SQL by restricting lookups on a dataset to a single field. For example, even if an employee has many properties, you might only be able to retrieve an employee by her ID. As a result, most queries in NoSQL systems are key lookup-based. The programmer selects a key to identify each data item, and can, for the most part, only retrieve items by performing a lookup for their key in the database.
在基于键查找的系统中,复杂的连接操作或相同数据的多键检索可能需要创造性地使用键名。希望通过员工 ID 查找员工和查找部门中所有员工的程序员可能会创建两个键类型。例如,键employee:30将指向员工 ID 为 30 的员工记录,并且employee_departments:20可能包含部门 20 中所有员工的列表。连接操作被推送到应用程序逻辑中:要检索部门 20 中的员工,应用程序首先检索列表来自 key 的员工 ID employee_departments:20,然后循环查找employee:ID员工列表中的每个员工 ID。
In key lookup-based systems, complex join operations or multiple-key retrieval of the same data might require creative uses of key names. A programmer wishing to look up an employee by his employee ID and to look up all employees in a department might create two key types. For example, the key employee:30 would point to an employee record for employee ID 30, and employee_departments:20 might contain a list of all employees in department 20. A join operation gets pushed into application logic: to retrieve employees in department 20, an application first retrieves a list of employee IDs from key employee_departments:20, and then loops over key lookups for each employee:ID in the employee list.
键查找模型是有益的,因为它意味着数据库具有一致的查询模式——整个工作负载由性能相对统一且可预测的键查找组成。分析以查找应用程序的缓慢部分更简单,因为所有复杂的操作都驻留在应用程序代码中。另一方面,数据模型逻辑和业务逻辑现在更加紧密地交织在一起,这混淆了抽象。
The key lookup model is beneficial because it means that the database has a consistent query pattern—the entire workload consists of key lookups whose performance is relatively uniform and predictable. Profiling to find the slow parts of an application is simpler, since all complex operations reside in the application code. On the flip side, the data model logic and business logic are now more closely intertwined, which muddles abstraction.
让我们快速了解与每个键关联的数据。各种 NoSQL 系统在此领域提供不同的解决方案。
Let's quickly touch on the data associated with each key. Various NoSQL systems offer different solutions in this space.
键值存储
NoSQL 存储的最简单形式是键值存储。每个键都映射到一个包含任意数据的值。NoSQL 存储不知道其有效负载的内容,只是将数据传递给应用程序。在我们的员工数据库示例中,可以将密钥映射employee:30到包含 JSON 或二进制格式(例如 Protocol Buffers 4、Thrift 5或 Avro 6 )的 blob ,以便封装有关员工 30 的信息。
如果开发人员使用结构化格式为键存储复杂数据,她必须对应用程序空间中的数据进行操作:键值数据存储通常不提供基于键值的某些属性查询键的机制。键值存储以其查询模型的简单性而著称,通常由 set、get和delete原语组成,但由于其值的不透明性而放弃了添加简单的数据库内过滤功能的能力。Voldemort 基于亚马逊的 Dynamo,提供分布式键值存储。BDB 7提供了一个具有键值接口的持久性库。
Key-Value Stores
The simplest form of NoSQL store is a key-value store. Each key is mapped to a value containing arbitrary data. The NoSQL store has no knowledge of the contents of its payload, and simply delivers the data to the application. In our Employee database example, one might map the key employee:30 to a blob containing JSON or a binary format such as Protocol Buffers4, Thrift5, or Avro6 in order to encapsulate the information about employee 30.
If a developer uses structured formats to store complex data for a key, she must operate against the data in application space: a key-value data store generally offers no mechanisms for querying for keys based on some property of their values. Key-value stores shine in the simplicity of their query model, usually consisting of set, get, and delete primitives, but discard the ability to add simple in-database filtering capabilities due to the opacity of their values. Voldemort, which is based on Amazon's Dynamo, provides a distributed key-value store. BDB7 offers a persistence library that has a key-value interface.
关键数据结构存储
键数据结构存储,由 Redis 8流行起来,为每个值分配一个类型。在 Redis 中,值可以采用的可用类型有整数、字符串、列表、集合和有序集合。除了 set/ get/之外delete,特定于类型的命令(例如整数的递增/递减或列表的推送/弹出)向查询模型添加功能,而不会显着影响请求的性能特征。通过提供简单的特定于类型的功能,同时避免聚合或连接等多键操作,Redis 平衡了功能和性能。
Key-Data Structure Stores
Key-data structure stores, made popular by Redis8, assign each value a type. In Redis, the available types a value can take on are integer, string, list, set, and sorted set. In addition to set/get/delete, type-specific commands, such as increment/decrement for integers, or push/pop for lists, add functionality to the query model without drastically affecting performance characteristics of requests. By providing simple type-specific functionality while avoiding multi-key operations such as aggregation or joins, Redis balances functionality and performance.
关键文件存储
密钥文档存储,例如 CouchDB 9、MongoDB 10和 Riak 11,将密钥映射到一些包含结构化信息的文档。这些系统以 JSON 或类似 JSON 的格式存储文档。它们存储列表和字典,它们可以递归地嵌入到另一个中。
MongoDB 将键空间分成多个集合,这样 Employees 和 Department 的键就不会发生冲突。CouchDB 和 Riak 将类型跟踪留给了开发人员。文档存储的自由性和复杂性是一把双刃剑:应用程序开发人员在建模文档方面有很大的自由度,但基于应用程序的查询逻辑可能会变得极其复杂。
Key-Document Stores
Key-document stores, such as CouchDB9, MongoDB10, and Riak11, map a key to some document that contains structured information. These systems store documents in a JSON or JSON-like format. They store lists and dictionaries, which can be embedded recursively inside one-another.
MongoDB separates the keyspace into collections, so that keys for Employees and Department, for example, do not collide. CouchDB and Riak leave type-tracking to the developer. The freedom and complexity of document stores is a double-edged sword: application developers have a lot of freedom in modeling their documents, but application-based query logic can become exceedingly complex.
BigTable 列族存储
HBase 和 Cassandra 的数据模型基于 Google 的 BigTable 使用的模型。在此模型中,一个键标识一行,其中包含存储在一个或多个列族 (CF) 中的数据。在 CF 中,每一行可以包含多列。每列中的值都带有时间戳,因此行-列映射的多个版本可以存在于一个 CF 中。
从概念上讲,可以将列族视为存储形式复杂的键(行 ID、CF、列、时间戳),映射到按键排序的值。这种设计导致将大量功能推入键空间的数据建模决策。它特别擅长对带有时间戳的历史数据进行建模。该模型自然支持稀疏列放置,因为没有某些列的行 ID 不需要这些列的显式 NULL 值。另一方面,具有很少或没有 NULL 值的列仍必须在每一行中存储列标识符,这会导致更大的空间消耗。
每个项目数据模型都与原始 BigTable 模型有很多不同,但 Cassandra 的变化最为显着。Cassandra 在每个 CF 中引入了超级列的概念,以允许另一个级别的映射、建模和索引。它还取消了局部性组的概念,出于性能原因,局部性组可以物理地将多个列族存储在一起。
BigTable Column Family Stores
HBase and Cassandra base their data model on the one used by Google's BigTable. In this model, a key identifies a row, which contains data stored in one or more Column Families (CFs). Within a CF, each row can contain multiple columns. The values within each column are timestamped, so that several versions of a row-column mapping can live within a CF.
Conceptually, one can think of Column Families as storing complex keys of the form (row ID, CF, column, timestamp), mapping to values which are sorted by their keys. This design results in data modeling decisions which push a lot of functionality into the keyspace. It is particularly good at modeling historical data with timestamps. The model naturally supports sparse column placement since row IDs that do not have certain columns do not need an explicit NULL value for those columns. On the flip side, columns which have few or no NULL values must still store the column identifier with each row, which leads to greater space consumption.
Each project data model differs from the original BigTable model in various ways, but Cassandra's changes are most notable. Cassandra introduces the notion of a supercolumn within each CF to allow for another level of mapping, modeling, and indexing. It also does away with a notion of locality groups, which can physically store multiple column families together for performance reasons.
图存储
一类 NoSQL 存储是图形存储。并非所有数据都是生来平等的,存储和查询数据的关系和面向键的数据模型并非对所有数据都是最佳的。图是计算机科学中的基本数据结构,HyperGraphDB 12 和 Neo4J 13等系统是两种流行的用于存储图结构数据的 NoSQL 存储系统。图存储在几乎所有方面都与我们迄今为止讨论的其他存储不同:数据模型、数据遍历和查询模式、磁盘上数据的物理布局、多台机器的分布以及查询的事务语义。鉴于篇幅所限,我们无法公正地看待这些明显的差异,但您应该知道,某些类别的数据可能更适合作为图形进行存储和查询。
Graph Storage
One class of NoSQL stores are graph stores. Not all data is created equal, and the relational and key-oriented data models of storing and querying data are not the best for all data. Graphs are a fundamental data structure in computer science, and systems such as HyperGraphDB12 and Neo4J13 are two popular NoSQL storage systems for storing graph-structured data. Graph stores differ from the other stores we have discussed thus far in almost every way: data models, data traversal and querying patterns, physical layout of data on disk, distribution to multiple machines, and the transactional semantics of queries. We can not do these stark differences justice given space limitations, but you should be aware that certain classes of data may be better stored and queried as a graph.
复杂查询
NoSQL 系统中的仅键查找有明显的例外。MongoDB 允许您根据任意数量的属性为您的数据编制索引,并具有一种相对高级的语言来指定您要检索的数据。基于 BigTable 的系统支持扫描器迭代列族并通过列上的过滤器选择特定项目。CouchDB 允许您创建不同的数据视图,并在您的表中运行 MapReduce 任务以促进更复杂的查找和更新。大多数系统都绑定到 Hadoop 或其他 MapReduce 框架以执行数据集规模的分析查询。
Complex Queries
There are notable exceptions to key-only lookups in NoSQL systems. MongoDB allows you to index your data based on any number of properties and has a relatively high-level language for specifying which data you want to retrieve. BigTable-based systems support scanners to iterate over a column family and select particular items by a filter on a column. CouchDB allows you to create different views of the data, and to run MapReduce tasks across your table to facilitate more complex lookups and updates. Most of the systems have bindings to Hadoop or another MapReduce framework to perform dataset-scale analytical queries.
事务
NoSQL 系统通常将性能优先于 事务语义。其他基于 SQL 的系统允许将任何语句集(从简单的主键行检索到多个表之间的复杂连接,然后对多个字段进行平均)放置在一个事务中。
这些 SQL 数据库将在事务之间提供 ACID 保证。在事务中运行多个操作是原子的(ACID 中的 A),这意味着所有操作都发生或都不发生。一致性(C)确保事务使数据库处于一致、未损坏的状态。隔离(I)确保如果两个事务触及相同的记录,它们将不会踩到对方的脚。持久性(D,在下一节中广泛介绍)确保事务一旦提交,就会存储在安全的地方。
符合 ACID 的事务使开发人员可以轻松地推断出他们的数据状态,从而使开发人员保持理智。想象多笔交易,每笔交易都有多个步骤(例如,首先检查银行账户的价值,然后减去 60 美元,然后更新价值)。符合 ACID 的数据库通常在交错这些步骤的同时仍能跨所有事务提供正确结果方面受到限制。这种对正确性的推动导致了经常出乎意料的性能特征,在这种情况下,缓慢的交易可能会导致原本快速的交易排队等候。
大多数 NoSQL 系统选择性能而不是完整的 ACID 保证,但确实在键级别提供保证:对同一键的两个操作将被序列化,避免键值对的严重损坏。对于许多应用程序,此决定不会造成明显的正确性问题,并且可以更规律地执行快速操作。但是,它确实将应用程序设计和正确性的更多考虑事项留给了开发人员。
Redis 是无事务趋势的明显例外。在单个服务器上,它提供了一个MULTI以原子方式一致地组合多个操作的WATCH命令,以及一个允许隔离的命令。其他系统提供较低级别的 测试和设置功能,提供一些隔离保证。
Transactions
NoSQL systems generally prioritize performance over transactional semantics. Other SQL-based systems allow any set of statements—from a simple primary key row retrieval, to a complicated join between several tables which is then subsequently averaged across several fields—to be placed in a transaction.
These SQL databases will offer ACID guarantees between transactions. Running multiple operations in a transaction is Atomic (the A in ACID), meaning all or none of the operations happen. Consistency (the C) ensures that the transaction leaves the database in a consistent, uncorrupted state. Isolation (the I) makes sure that if two transactions touch the same record, they will do without stepping on each other's feet. Durability (the D, covered extensively in the next section), ensures that once a transaction is committed, it's stored in a safe place.
ACID-compliant transactions keep developers sane by making it easy to reason about the state of their data. Imagine multiple transactions, each of which has multiple steps (e.g., first check the value of a bank account, then subtract $60, then update the value). ACID-compliant databases often are limited in how they can interleave these steps while still providing a correct result across all transactions. This push for correctness results in often-unexpected performance characteristics, where a slow transaction might cause an otherwise quick one to wait in line.
Most NoSQL systems pick performance over full ACID guarantees, but do provide guarantees at the key level: two operations on the same key will be serialized, avoiding serious corruption to key-value pairs. For many applications, this decision will not pose noticeable correctness issues, and will allow quick operations to execute with more regularity. It does, however, leave more considerations for application design and correctness in the hands of the developer.
Redis is the notable exception to the no-transaction trend. On a single server, it provides a MULTI command to combine multiple operations atomically and consistently, and a WATCH command to allow isolation. Other systems provide lower-level test-and-set functionality which provides some isolation guarantees.
无模式存储
许多 NoSQL 系统的一个交叉属性是数据库中缺乏模式实施。即使在文档存储和面向列族的存储中,相似实体的属性也不需要相同。这样做的好处是支持较少的结构化数据要求,并且在动态修改模式时需要较少的性能开销。该决定将更多责任留给了应用程序开发人员,他们现在必须更加谨慎地进行编程。例如,lastname 员工记录中缺少某个属性是需要纠正的错误,还是当前正在通过系统传播的架构更新?在依赖 sloppy-schema NoSQL系统的项目进行几次迭代后,数据和模式版本控制在应用程序级代码中很常见。
Schema-free Storage
A cross-cutting property of many NoSQL systems is the lack of schema enforcement in the database. Even in document stores and column family-oriented stores, properties across similar entities are not required to be the same. This has the benefit of supporting less structured data requirements and requiring less performance expense when modifying schemas on-the-fly. The decision leaves more responsibility to the application developer, who now has to program more defensively. For example, is the lack of a lastname property on an employee record an error to be rectified, or a schema update which is currently propagating through the system? Data and schema versioning is common in application-level code after a few iterations of a project which relies on sloppy-schema NoSQL systems.
数据持久性 Data Durability
理想情况下,存储系统上的所有数据修改都将立即安全地持久化并复制到多个位置以避免数据丢失。但是,保证数据安全与性能存在一定的张力,不同的NoSQL系统 为了提升性能做出不同的数据持久化保证。失败场景多种多样,并非所有 NoSQL 系统都能保护您免受这些问题的影响。
一个简单而常见的故障场景是服务器重启或断电。在这种情况下,数据持久性涉及将数据从内存移动到硬盘,硬盘不需要电源来存储数据。硬盘故障是通过将数据复制到辅助设备来处理的,无论是同一台机器中的其他硬盘驱动器(RAID 镜像)还是网络上的其他机器。然而,数据中心可能无法在导致相关故障的事件(例如龙卷风)中幸存下来,并且一些组织甚至将数据复制到相距几个飓风宽度的数据中心的备份。写入硬盘驱动器并将数据复制到多个服务器或数据中心的成本很高,因此不同的 NoSQL 系统会牺牲持久性保证来换取性能。
Ideally, all data modifications on a storage system would immediately be safely persisted and replicated to multiple locations to avoid data loss. However, ensuring data safety is in tension with performance, and different NoSQL systems make different data durability guarantees in order to improve performance. Failure scenarios are varied and numerous, and not all NoSQL systems protect you against these issues.
A simple and common failure scenario is a server restart or power loss. Data durability in this case involves having moved the data from memory to a hard disk, which does not require power to store data. Hard disk failure is handled by copying the data to secondary devices, be they other hard drives in the same machine (RAID mirroring) or other machines on the network. However, a data center might not survive an event which causes correlated failure (a tornado, for example), and some organizations go so far as to copy data to backups in data centers several hurricane widths apart. Writing to hard drives and copying data to multiple servers or data centers is expensive, so different NoSQL systems trade off durability guarantees for performance.
单机持久性 Single-server Durability
最简单的持久性形式是单服务器持久性,它确保任何数据修改都能在服务器重启或断电后继续存在。这通常意味着将更改的数据写入磁盘,这通常会成为您的工作负载的瓶颈。即使您命令操作系统将数据写入磁盘文件,操作系统也可能会缓冲写入,避免立即修改磁盘,以便它可以将多个写入组合成一个操作。只有fsync发出系统调用时,操作系统才会尽最大努力确保缓冲更新持久保存到磁盘。
典型的硬盘驱动器每秒可以执行 100-200 次随机访问(寻道),并且限制为 30-100 MB/秒的顺序写入。在这两种情况下,内存都可以快几个数量级。确保高效的单服务器持久性意味着限制系统产生的随机写入次数,并增加每个硬盘驱动器的顺序写入次数。理想情况下,您希望系统最小化fsync调用之间的写入次数,最大化连续写入的次数,同时永远不要告诉用户他们的数据已成功写入磁盘,直到写入完成fsync。让我们介绍一些提高单服务器持久性保证性能的技术。
The simplest form of durability is a single-server durability, which ensures that any data modification will survive a server restart or power loss. This usually means writing the changed data to disk, which often bottlenecks your workload. Even if you order your operating system to write data to an on-disk file, the operating system may buffer the write, avoiding an immediate modification on disk so that it can group several writes together into a single operation. Only when the fsync system call is issued does the operating system make a best-effort attempt to ensure that buffered updates are persisted to disk.
Typical hard drives can perform 100-200 random accesses (seeks) per second, and are limited to 30-100 MB/sec of sequential writes. Memory can be orders of magnitudes faster in both scenarios. Ensuring efficient single-server durability means limiting the number of random writes your system incurs, and increasing the number of sequential writes per hard drive. Ideally, you want a system to minimize the number of writes between fsync calls, maximizing the number of those writes that are sequential, all the while never telling the user their data has been successfully written to disk until that write has been fsynced. Let's cover a few techniques for improving performance of single-server durability guarantees.
控制fsync频率
Memcached 14是一个系统示例,它不提供磁盘持久性以换取极快的内存操作。当服务器重新启动时,该服务器上的数据就消失了:这导致了良好的缓存和较差的持久数据存储。
Redis 为开发人员提供了何时调用 fsync. 开发人员可以在每次更新后强制fsync调用,这是一种缓慢而安全的选择。为了获得更好的性能,Redis 可以fsync每 N 秒写入一次。在最坏的情况下,您将丢失最后 N 秒的操作,这对于某些用途来说可能是可以接受的。最后,对于持久性不重要的用例(维护粗粒度统计信息,或使用 Redis 作为缓存),开发人员可以fsync完全关闭调用:操作系统最终会将数据刷新到磁盘,但无法保证何时刷新会发生。
Control fsync Frequency
Memcached14 is an example of a system which offers no on-disk durability in exchange for extremely fast in-memory operations. When a server restarts, the data on that server is gone: this makes for a good cache and a poor durable data store.
Redis offers developers several options for when to call fsync. Developers can force an fsync call after every update, which is the slow and safe choice. For better performance, Redis can fsync its writes every N seconds. In a worst-case scenario, the you will lose last N seconds worth of operations, which may be acceptable for certain uses. Finally, for use cases where durability is not important (maintaining coarse-grained statistics, or using Redis as a cache), the developer can turn off fsync calls entirely: the operating system will eventually flush the data to disk, but without guarantees of when this will happen.
通过日志记录增加顺序写入
B+树等多种数据结构可帮助 NoSQL 系统快速从磁盘检索数据。对这些结构的更新会导致数据结构文件中随机位置的更新,如果您fsync在每次更新后进行更新,则会导致每次更新多次随机写入。为了减少随机写入,Cassandra、HBase、Redis 和 Riak 等系统将更新操作附加到称为日志的顺序写入文件中。系统使用的其他数据结构只是定期fsync更新,而日志是频繁 fsync更新的。通过将日志视为崩溃后数据库的真实状态,这些存储引擎能够将随机更新转变为顺序更新。
虽然 MongoDB 等 NoSQL 系统在其数据结构中执行就地写入,但其他系统甚至更进一步进行日志记录。Cassandra 和 HBase 使用了一种从 BigTable 借来的技术,将它们的日志和查找数据结构组合成一个日志结构的合并树。Riak 通过日志结构的哈希表提供了类似的功能。CouchDB 对传统的 B+Tree 进行了修改,使得对数据结构的所有更改都附加到物理存储上的结构中。这些技术提高了写入吞吐量,但需要定期进行日志压缩以防止日志无限增长。
Increase Sequential Writes by Logging
Several data structures, such as B+Trees, help NoSQL systems quickly retrieve data from disk. Updates to those structures result in updates in random locations in the data structures' files, resulting in several random writes per update if you fsync after each update. To reduce random writes, systems such as Cassandra, HBase, Redis, and Riak append update operations to a sequentially-written file called a log. While other data structures used by the system are only periodically fsynced, the log is frequently fsynced. By treating the log as the ground-truth state of the database after a crash, these storage engines are able to turn random updates into sequential ones.
While NoSQL systems such as MongoDB perform writes in-place in their data structures, others take logging even further. Cassandra and HBase use a technique borrowed from BigTable of combining their logs and lookup data structures into one log-structured merge tree. Riak provides similar functionality with a log-structured hash table. CouchDB has modified the traditional B+Tree so that all changes to the data structure are appended to the structure on physical storage. These techniques result in improved write throughput, but require a periodic log compaction to keep the log from growing unbounded.
通过分组写入提高吞吐量
Cassandra 将短窗口内的多个并发更新分组为单个fsync调用。这种称为group commit的设计导致每次更新的延迟更高,因为用户必须等待多个并发更新才能确认他们自己的更新。延迟增加伴随着吞吐量的增加,因为单个fsync. 在撰写本文时,每个 HBase 更新都持久保存到 Hadoop 分布式文件系统 (HDFS) 15提供的底层存储中,该系统最近出现了补丁以允许支持尊重 fsync和组提交的附加。
Increase Throughput by Grouping Writes
Cassandra groups multiple concurrent updates within a short window into a single fsync call. This design, called group commit, results in higher latency per update, as users have to wait on several concurrent updates to have their own update be acknowledged. The latency bump comes at an increase in throughput, as multiple log appends can happen with a single fsync. As of this writing, every HBase update is persisted to the underlying storage provided by the Hadoop Distributed File System (HDFS)15, which has recently seen patches to allow support of appends that respect fsync and group commit.
多服务器持久性
由于硬盘驱动器和机器经常发生无法修复的故障,因此有必要跨机器复制重要数据。许多 NoSQL 系统为数据提供多服务器持久性。
Redis 采用传统的主从方式来复制数据。对主机执行的所有操作都以类似日志的方式传达给从机,从机在自己的硬件上复制操作。如果主服务器发生故障,从服务器可以介入并提供从主服务器接收到的操作日志状态中的数据。此配置可能会导致一些数据丢失,因为主服务器在向用户确认操作之前不会确认从服务器已在其日志中持久化操作。
CouchDB 促进了类似形式的定向复制,其中服务器可以配置为将更改复制到其他存储上的文档。
MongoDB 提供了副本集的概念,其中一些服务器负责存储每个文档。MongoDB 为开发人员提供了确保所有副本都已收到更新或在不确保副本具有最新数据的情况下继续操作的选项。许多其他分布式 NoSQL 存储系统支持数据的多服务器复制。
HBase 建立在 HDFS 之上,通过 HDFS 获得多服务器持久性。在将控制权返回给用户之前,所有写入都被复制到两个或多个 HDFS 节点,确保多服务器持久性。
Riak、Cassandra 和 Voldemort 支持更多可配置的复制形式。有细微差别,这三个系统都允许用户指定N,最终应该拥有数据副本的机器数量,以及W< N,在将控制权返回给用户之前应该确认数据已经写入的机器数量。
为了处理整个数据中心停止服务的情况,需要跨数据中心的多服务器复制。Cassandra、HBase 和 Voldemort 具有机架感知配置,这些配置指定各种机器所在的机架或数据中心。通常,在远程服务器确认更新之前阻止用户的请求会导致过多的延迟。当跨广域网执行更新到备份数据中心时,更新会在没有确认的情况下流式传输。
Multi-server Durability
Because hard drives and machines often irreparably fail, copying important data across machines is necessary. Many NoSQL systems offer multi-server durability for data.
Redis takes a traditional master-slave approach to replicating data. All operations executed against a master are communicated in a log-like fashion to slave machines, which replicate the operations on their own hardware. If a master fails, a slave can step in and serve the data from the state of the operation log that it received from the master. This configuration might result in some data loss, as the master does not confirm that the slave has persisted an operation in its log before acknowledging the operation to the user.
CouchDB facilitates a similar form of directional replication, where servers can be configured to replicate changes to documents on other stores.
MongoDB provides the notion of replica sets, where some number of servers are responsible for storing each document. MongoDB gives developers the option of ensuring that all replicas have received updates, or to proceed without ensuring that replicas have the most recent data. Many of the other distributed NoSQL storage systems support multi-server replication of data.
HBase, which is built on top of HDFS, receives multi-server durability through HDFS. All writes are replicated to two or more HDFS nodes before returning control to the user, ensuring multi-server durability.
Riak, Cassandra, and Voldemort support more configurable forms of replication. With subtle differences, all three systems allow the user to specify N, the number of machines which should ultimately have a copy of the data, and W<N, the number of machines that should confirm the data has been written before returning control to the user.
To handle cases where an entire data center goes out of service, multi-server replication across data centers is required. Cassandra, HBase, and Voldemort have rack-aware configurations, which specify the rack or data center in which various machines are located. In general, blocking the user's request until a remote server has acknowledged an update incurs too much latency. Updates are streamed without confirmation when performed across wide area networks to backup data centers.
扩展性能
刚刚谈到处理失败,让我们想象一个更美好的情况:成功!如果您构建的系统取得成功,您的数据存储将成为承受负载压力的组件之一。解决此类问题的一种廉价而肮脏的解决方案是扩大现有机器的规模:投资更多的 RAM 和磁盘来处理一台机
以上是关于架构师必知必会常见的NoSQL数据库种类以及使用场景的主要内容,如果未能解决你的问题,请参考以下文章