走进 JDK 之 PriorityQueue
Posted u012551350
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了走进 JDK 之 PriorityQueue相关的知识,希望对你有一定的参考价值。
走进 JDK 系列第 16 篇
文章相关源码: PriorityQueue.java
这是 Java 集合框架的第三篇文章了,前两篇分别解析了 ArrayList 和 LinkedList,它们分别是基于动态数组和链表来实现的。今天来说说 Java 中的优先级队列 PriorityQueue,它是基于堆实现的,后面也会介绍堆的相关概念。
概述
PriorityQueue 是基于堆实现的无界优先级队列。优先级队列中的元素顺序根据元素的自然序或者构造器中提供的 Comparator。不允许 null 元素,不允许插入不可比较的元素(未实现 Comparable)。它不保证线程安全,JDK 也提供了线程安全的优先级队列 PriorityBlockingQueue。
划个重点,基于堆实现的优先级队列。首先来看一下什么是队列?什么是堆?
队列
队列其实很好理解,它是一种特殊的线性表。比如食堂排队打饭就是一个队列,先排队的人先打饭,后来的同学在队尾排队,打到饭的同学从对头离开,这就是典型的 先进先出(FIFO)队列。队列一般会提供 入队 和 出队 两个基本操作,入队在队尾进行,出队在对头进行。Java 中队列的父类接口是 Queue。我们来看一下 Queue 的 uml 图,给我们提供了哪些基本方法:
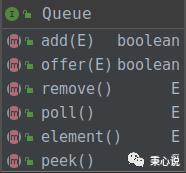
add(E) :在队尾添加元素offer(E) :在队尾添加元素。在容量受限的队列中和 add() 表现一致。remove() :删除并返回队列头,队列为空时抛出异常poll() :删除并返回队列头,队列为空时返回 nullelement():返回队列头,但不删除,队列为空时抛出异常peek() :返回队列头,但不删除,队列为空时返回 null
基本也就是对出队和入队操作进行了细分。PriorityQueue 是一个优先级队列,会按自然序或者提供的 Comparator对元素进行排序,这里使用的是堆排序,所以优先级队列是基于堆来实现的。如果你了解堆的概念,就可以跳过下一节了。如果你不知道什么是堆,仔细阅读下一节,不然是没办法理解 PriorityQueue 的源码的。
堆
堆其实是一种特殊的二叉树,它具备如下两个特征:
堆是一个完全二叉树
堆中每个节点的值都必须小于等于(或者大于等于)其子节点的值
对于一个高度为 k 的二叉树,如果它的 0 到 k-1 层都是满的,且最后一层的所有子节点都是在左边那么他就是完全二叉树。用数组实现的完全二叉树可以很方便的根据父节点的下标获取它的两个子节点。下图就是一个完全二叉树:
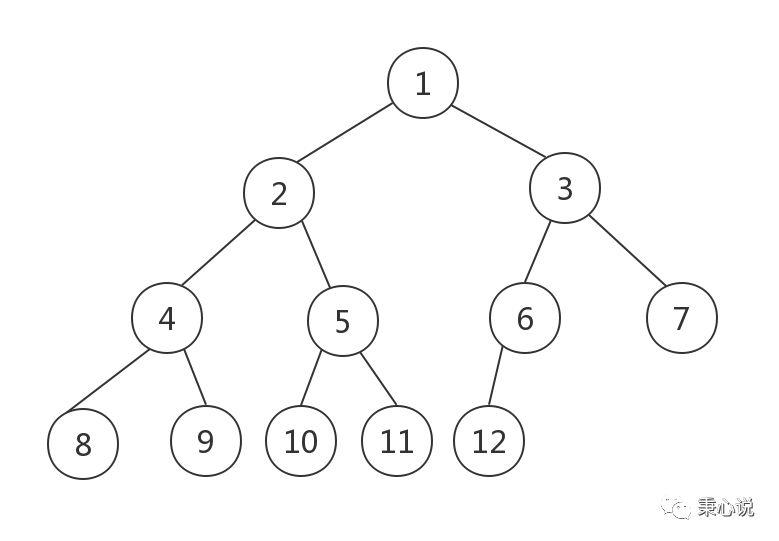
堆就是一个完全二叉树。顶部是最小元素的叫小顶堆,顶部是最大元素的叫大顶堆。PriorityQueue 是小顶堆。对照上面的堆结构,对于任意父节点,以下标为 4 的节点 5 为例,它的两个子节点下标分别为 2*4+1 和 2*4+2。关于完全二叉树和堆,记住下面几个结论,都是后面的源码分析中要用到的:
没有子节点的节点叫做叶子节点
下标为
n的父节点的两个左右子节点的下标分别是2n+1` 和 `2n+2
这就是用数组来构建堆的好处,根据下标就可以快速构建堆结构。堆就先说到这里,记住优先级队列 PriorityQueue 是基于堆实现的队列,堆是一个完全二叉树。下面就根据 PriorityQueue 的源码对堆的操作进行深入解析。
源码解析
类声明
public class PriorityQueue<E> extends AbstractQueue<E> implements java.io.Serializable 成员变量
private static final long serialVersionUID = -7720805057305804111L;private static final int DEFAULT_INITIAL_CAPACITY = 11; // 默认初始容量transient Object[] queue; // 存储队列元素的数组private int size = 0; // 队列元素个数private final Comparator<? super E> comparator; transient int modCount = 0; // fail-fastprivate static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; // 最大容量PriorityQueue 使用数组
queue来存储元素,默认初始容量是 11,最大容量是Integer.MAX_VALUE - 8。comparator若为 null,则按照元素的自然序来排列。modCount用来提供 fail-fast 机制。
构造函数
PriorityQueue 的构造函数有 7 个,可以分为两类,提供初始元素和不提供初始元素。先来看看不提供初始元素的构造函数:
/* * 创建初始容量为 11 的优先级队列,元素按照自然序 */public PriorityQueue() this(DEFAULT_INITIAL_CAPACITY, null);/* * 创建指定初始容量的优先级队列,元素按照自然序 */public PriorityQueue(int initialCapacity) this(initialCapacity, null);/* * 创建初始容量为 11 的优先级队列,元素按照按照给定 comparator 排序 */public PriorityQueue(Comparator<? super E> comparator) this(DEFAULT_INITIAL_CAPACITY, comparator);/* * 创建指定初始容量的优先级队列,元素按照按照给定 comparator 排序 */public PriorityQueue(int initialCapacity, Comparator<? super E> comparator) if (initialCapacity < 1) throw new IllegalArgumentException(); this.queue = new Object[initialCapacity]; this.comparator = comparator;这一类构造函数都很简单,直接给 queue 和 comparator 赋值即可。对于给定初始元素的构造函数就没有这么简单了,因为给定的初始集合并不一定满足堆的结构,我们需要将其构造成堆,这个过程称之为 堆化。
PriorityQueue 可以直接根据 SortedSet 和 PriorityQueue 来构造堆,由于初始集合本来就是有序的,所以无需进行堆化。如果构造器参数是任意 Collection,那么就可能需要堆化了。
public PriorityQueue(Collection<? extends E> c) if (c instanceof SortedSet<?>) // 直接使用 SortedSet 的 comparator SortedSet<? extends E> ss = (SortedSet<? extends E>) c; this.comparator = (Comparator<? super E>) ss.comparator(); initElementsFromCollection(ss); else if (c instanceof PriorityQueue<?>) // 直接使用 PriorityQueue 的 comparator PriorityQueue<? extends E> pq = (PriorityQueue<? extends E>) c; this.comparator = (Comparator<? super E>) pq.comparator(); initFromPriorityQueue(pq); else this.comparator = null; initFromCollection(c); // 需要堆化 我们来看看堆化的具体过程:
private void initFromCollection(Collection<? extends E> c) initElementsFromCollection(c); // 将 c copy 一份直接赋给 queue heapify(); // 堆化private void heapify() for (int i = (size >>> 1) - 1; i >= 0; i--) siftDown(i, (E) queue[i]); // 自上而下堆化堆化的逻辑很短,但是内容很丰富。堆化其实用两种,shiftDown() 是自上而下堆化,shiftUp() 是自下而上堆化。这里使用的是 shiftDown。从上面的代码中你可以看出从哪一个结点开始堆化的吗?并不是从最后一个节点开始堆化,而是从最后一个非叶子节点开始的。还记得什么是叶子节点吗,没有子节点的节点就是叶子节点。所以,对所有非叶子节点进行堆化,就足以处理所有节点了。那么最后一个非叶子节点的下标是多少呢,如果想不出来可以翻到上面的堆的示意图,答案就是 size/2 - 1,源码中使用了无符号移位操作代替了除法。
再来看看 shiftDown() 的具体逻辑:
/* * 自上而下堆化,保证 x 小于等于子节点或者 x 是一个叶子结点 */private void siftDown(int k, E x) if (comparator != null) siftDownUsingComparator(k, x); else siftDownComparable(k, x);x 是要插入的元素,k 是要填充的位置。根据 comparator 是否为空调用不同的方法。这里以 comparator 不为 null 为例:
private void siftDownComparable(int k, E x) Comparable<? super E> key = (Comparable<? super E>)x; int half = size >>> 1; // loop while a non-leaf while (k < half) // 堆的非叶子节点的个数总是小于 half 的。当 k 是叶子节点的时候,直接交换即可 int child = (k << 1) + 1; // 左子节点 Object c = queue[child]; int right = child + 1; // 右子节点 if (right < size && ((Comparable<? super E>) c).compareTo((E) queue[right]) > 0) c = queue[child = right]; // 取子节点中的较小值 if (key.compareTo((E) c) <= 0) // 比较 x 和子节点 break; // x 比子节点大,直接跳出循环 queue[k] = c; // 若 x 比子节点小,和子节点交换 k = child; // 此时 k 等于 child,继续和子节点比较 queue[k] = key;逻辑比较简单。PriorityQueue 是一个小顶堆,父节点总是小于等于子节点。对于每一个非叶子节点,将它和自己的两个左右子节点进行比较,若父节点比两个子节点都大,就要将这个父节点下沉,下沉之后再继续和子节点比较,直到该父节点比两个子节点都小,或者这个父节点已经是叶子结点,没有子节点了。这样循环往复,自上而下的堆化就完成了。
方法
看完了构造函数,我们来看看 PriorityQueue 提供的方法。既然是队列,那就肯定有入队和出队操作。先来看看入队方法 add()。
add(E e)
public boolean add(E e) return offer(e);public boolean offer(E e) if (e == null) throw new NullPointerException(); modCount++; int i = size; if (i >= queue.length) grow(i + 1); // 自动扩容 size = i + 1; if (i == 0) queue[0] = e; // 第一个元素,直接赋值即可 else siftUp(i, e); // 后续元素要保证堆特性,要进行堆化 return true;add() 方法会调用 offer() 方法,它们都是在队尾增加一个元素。offer() 过程可以分为两步:自动扩容 和 堆化。
优先队列也支持自动扩容,但其扩容逻辑和 ArrayList 不同,ArrayList 是直接扩容至原来的 1.5 倍。而 PriorityQueue 根据当前队列大小的不同有不同的表现。
private void grow(int minCapacity) int oldCapacity = queue.length; // Double size if small; else grow by 50% int newCapacity = oldCapacity + ((oldCapacity < 64) ? (oldCapacity + 2) : (oldCapacity >> 1)); // overflow-conscious code if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); queue = Arrays.copyOf(queue, newCapacity);原队列大小小于 64 时,直接翻倍再 +2
原队列大小大于 64 时,增加 50%
第二步就是堆化了。队尾增加元素为什么要重新堆化呢?看下面这个图:
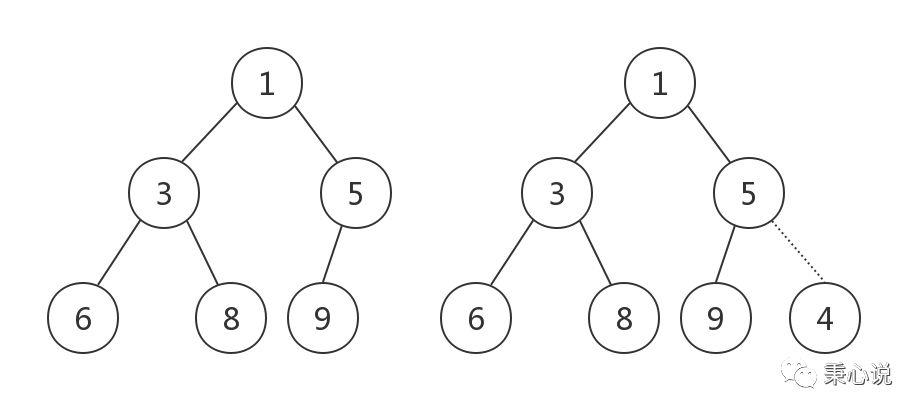
左边是一个堆,我要在队尾添加一个元素 4,如果这样直接加在队尾,还是一堆吗?显然不是的了,因为 4 比 5 小,却排在了 5 的下面。所以这时候就需要堆化了。前面介绍过 shiftDown, 这里还可以自上而下堆化吗?显然不行,因为在队尾添加节点,这个节点肯定是叶子节点,它已经位于最下面一层了,没有子节点了。这就要使用另一种堆化方法,自下而上堆化。拿 4 和其父节点比较,发现 4 比 5 小,和父节点交换,这时候 4 就处在 下标为 2 的位置了。再和父节点比较,发现 4 比 1 大,不交换,结束堆化。这时候 4 就找到自己在堆中正确的位置了。对应源代码中的 shiftUp() 方法:
private void siftUp(int k, E x) if (comparator != null) siftUpUsingComparator(k, x); else siftUpComparable(k, x);private void siftUpUsingComparator(int k, E x) while (k > 0) int parent = (k - 1) >>> 1; // 找到 k 位置的父节点 Object e = queue[parent]; if (comparator.compare(x, (E) e) >= 0) // 比较 x 与父节点值的大小 break; // x 比父节点大,直接跳出循环 queue[k] = e; // 若 x 比父节点小,交换元素 k = parent; // 此时 k 等于 parent,继续和父节点比较 queue[k] = x;根据下标 k 就可以找到 k 位置的父节点,这也是前面介绍堆的时候给出的结论。那么其插入操作的时间复杂度是多少呢?这和堆的高度相关,最好时间复杂度就是 O(1),不需要交换元素,最坏时间复杂度是 O(log(n)),因为堆的高度是 log(n),最坏情况就是一路交换到堆顶。平均时间复杂度也就是 O(log(n))。
说完了入队,下面看一下出队。
poll()
poll() 是出队操作,也就是移除队队头元素。想想一下,一个完全二叉树,你把堆顶移除了,它就不是一个完全二叉树了,也就没办法去堆化了。源码中是这样处理的,移除队头元素之后,暂时把队尾元素移到队头,这样它又是一个完全二叉树了,就可以进行堆化了。下面这个图更容易理解:
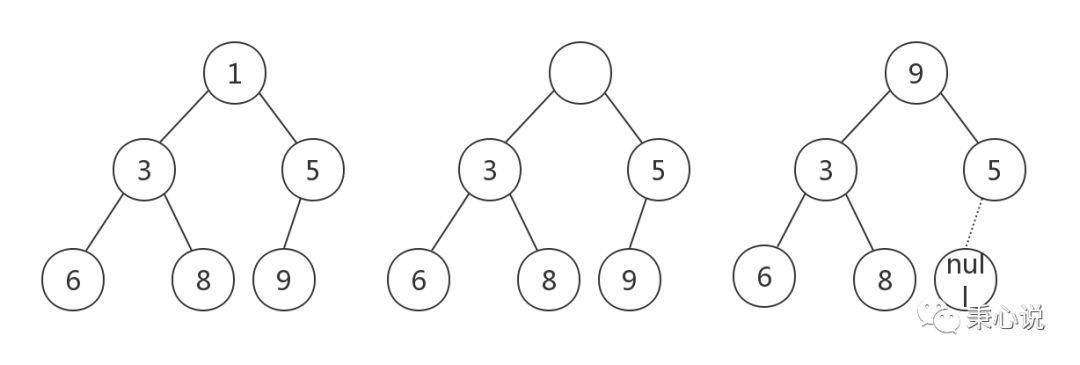
这里的堆化操作很显然应该是 shiftDown() 了,自上而下堆化。
public E poll() // 移除队列头 if (size == 0) return null; int s = --size; modCount++; E result = (E) queue[0]; E x = (E) queue[s]; // 将队尾元素插入队头,再自上而下堆化 queue[s] = null; if (s != 0) siftDown(0, x); return result;除了移除队列头,PriorityQueue 也支持 remove 任意位置的节点,通过 remove() 方法实现。
remove()
private E removeAt(int i) // assert i >= 0 && i < size; modCount++; int s = --size; if (s == i) // removed last element queue[i] = null; // 删除队尾,可直接删除 else // 删除其他位置,为保持堆特性,需要重新堆化 E moved = (E) queue[s]; // moved 是队尾元素 queue[s] = null; siftDown(i, moved); // 将队尾元素插入 i 位置,再自上而下堆化 if (queue[i] == moved) siftUp(i, moved); // moved 没有往下交换,仍然在 i 位置处,此时需要再自下而上堆化以保证堆的正确性 if (queue[i] != moved) return moved; return null;如果是删除队尾,直接删除皆可以了。但如果是删除中间某个节点,就会在堆中形成一个空洞,不再是完全二叉树。其实和 poll 的处理方式一致,将队尾节点暂时填充到删除的位置,形成完全二叉树再进行堆化。
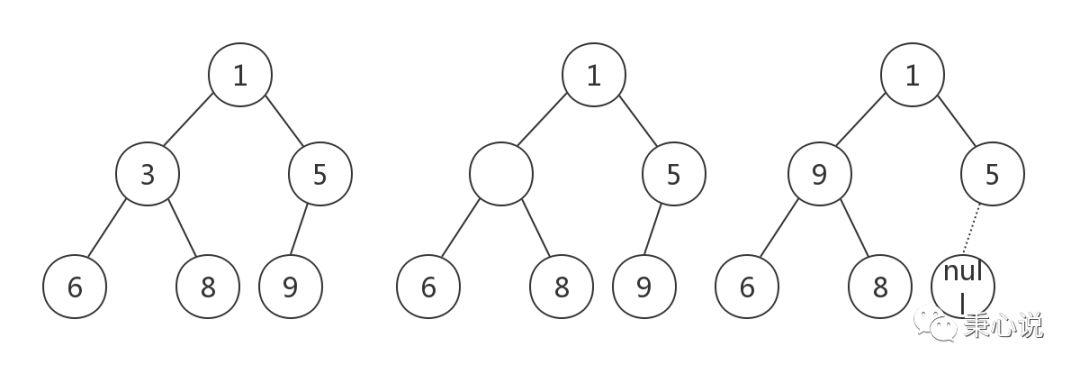
这里的堆化过程和 poll 有一些不一致。首先进行 shiftDown(),自上而下堆化。shiftDown() 完成之后比较 queue[i] == moved,如果不相等,说明节点 i 向下交换了,它找到了自己的位置。但是如果相等,则说明节点 i 没有向下交换,也就是节点 i 的值比它的子节点都要小。但这并不能说明它一定比它的父节点大。所以,这种情况还需要再自下而上堆化,以保证可以完全符合堆的特性。
总结
说了半天 PriorityQueue ,其实都是在说堆。如果你对堆很熟悉的话,PriorityQueue 的源码很好理解。当然不熟悉也没关系,借着源码正好可以学习一下堆的基本概念。最后简单总结一下优先队列:
PriorityQueue 是基于堆的,堆是一个特殊的完全二叉树,它的每一个节点的值都必须小于等于(或大于等于)其子树中每个节点的值
PriorityQueue 的出队和入队操作时间复杂度都是
O(log(n)),仅与堆的高度有关PriorityQueue 初始容量为 11,支持动态扩容。容量小于 64 时,扩容一倍。大于 64 时,扩容 0.5 倍
PriorityQueue 不允许 null 元素,不允许不可比较的元素
PriorityQueue 不是线程安全的,PriorityBlockingQueue 是线程安全的
PriorityQueue 就说到这里了。下一篇应该会写 Set 相关。
推荐阅读
分享一套android快速开发模板,包含常用主流框架,下载即用
微信扫一扫识别小程序
 长按识别小程序,参与抽奖
长按识别小程序,参与抽奖
以上是关于走进 JDK 之 PriorityQueue的主要内容,如果未能解决你的问题,请参考以下文章