网络知识点
Posted 海鲜小王子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络知识点相关的知识,希望对你有一定的参考价值。
网络
HTTP 和 TCP 有什么关系
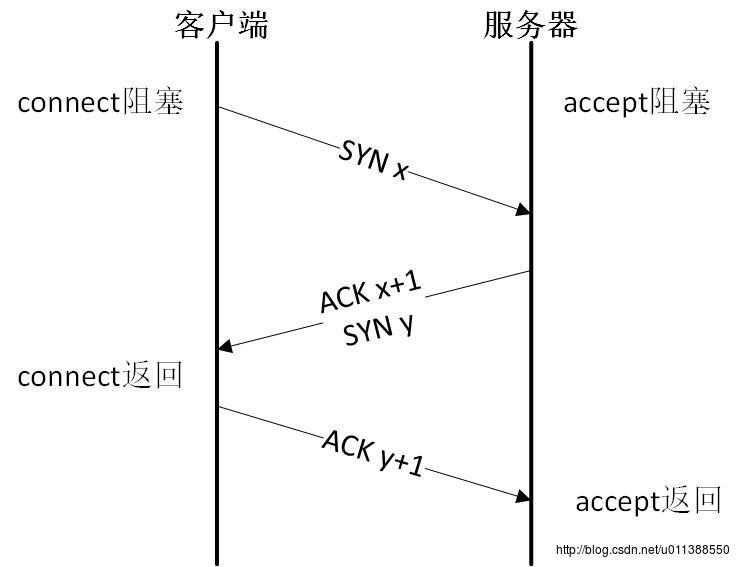
HTTP是应用层的协议,TCP是传输层的协议,HTTP协议是基于TCP协议的。TCP 的三次握手过程
SYN后面的数字属于“序号”,该“序号”是初始序列号(ISN),是随机产生的。ACK后面的数字属于“确认序号”,这两个序号都在TCP的头部,都是32bit长度。
- TCP发起握手时,初始序列号(ISN)为什么要随机?
客户端和服务器的“序号”往往是不一样的,这个“序号”可以看做32bit计数器,随时间增加而增加,这样子主要为什么防止安全问题,如IP欺骗攻击。
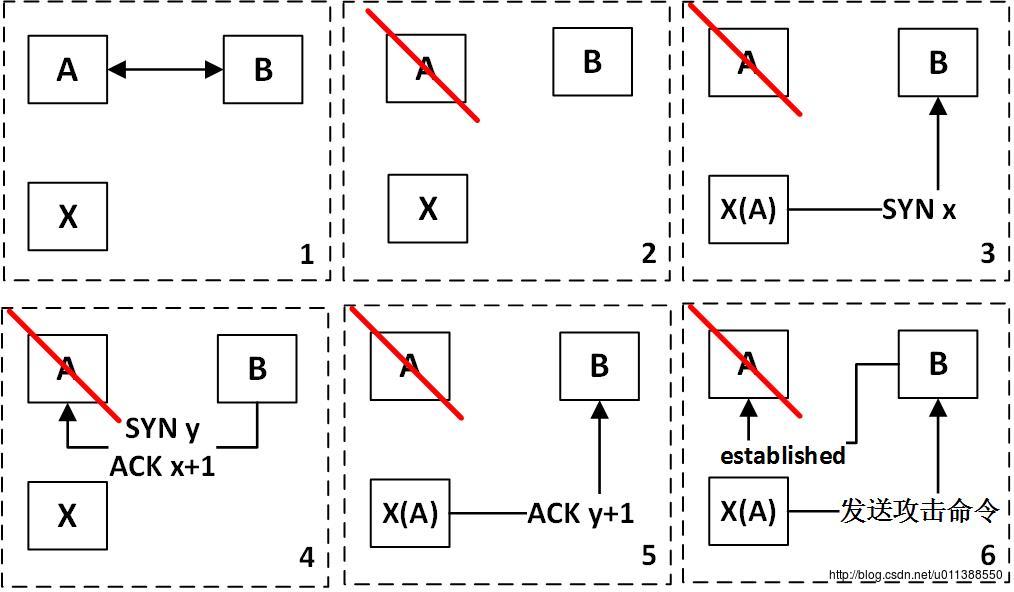
IP欺骗攻击具体步骤:
1. A和B正常通信,此时,攻击者X希望攻击B
2. X先让A瘫痪,可使用DdoS拒绝服务攻击
3. 由于B信任A却不信任X,X需以A的名义发送一个TCP握手请求SYN x
4. B回复TCP握手请求,由于是X以A的名义发起请求,这个响应就应该发送给A
5. X此时要做的事情就是使用某种方法推测出y,这个y是B的初始序列号,X以A的名义发送ACK y+1
6. TCP三次握手过程顺利通过,B以为自己和A建立了连接,但其实A已经瘫痪,发送不了信息,所有发往B的信息都是X冒充A发的。此时X就可以对B发起攻击,如取得管理权限。
TCP 和 UDP 的区别
总的来说,TCP是面向连接且可靠的,UDP是不面向连接且不保证可靠的。- TCP在通信前要经过三次握手,UDP则不需要(参考第2题)
- TCP有超时重传机制,保证每个包可以被收到(参考第6题)
- TCP有确认序号机制,保证把收到的乱序包整理成顺序的包(参考第6题)
- TCP有流量控制机制,防止大量发包导致丢包率上升、网络变差
包为什么会乱序
因为TCP包有最大字节限制,由MSS控制;IP包也有最大限制,由MTU控制。不同的IP包在网络中的路由是不一样的,那么到达时间也就不一样,造成了乱序。在TCP层,乱序的包由seq协助进行重组。TCP 包为什么需要 Seq
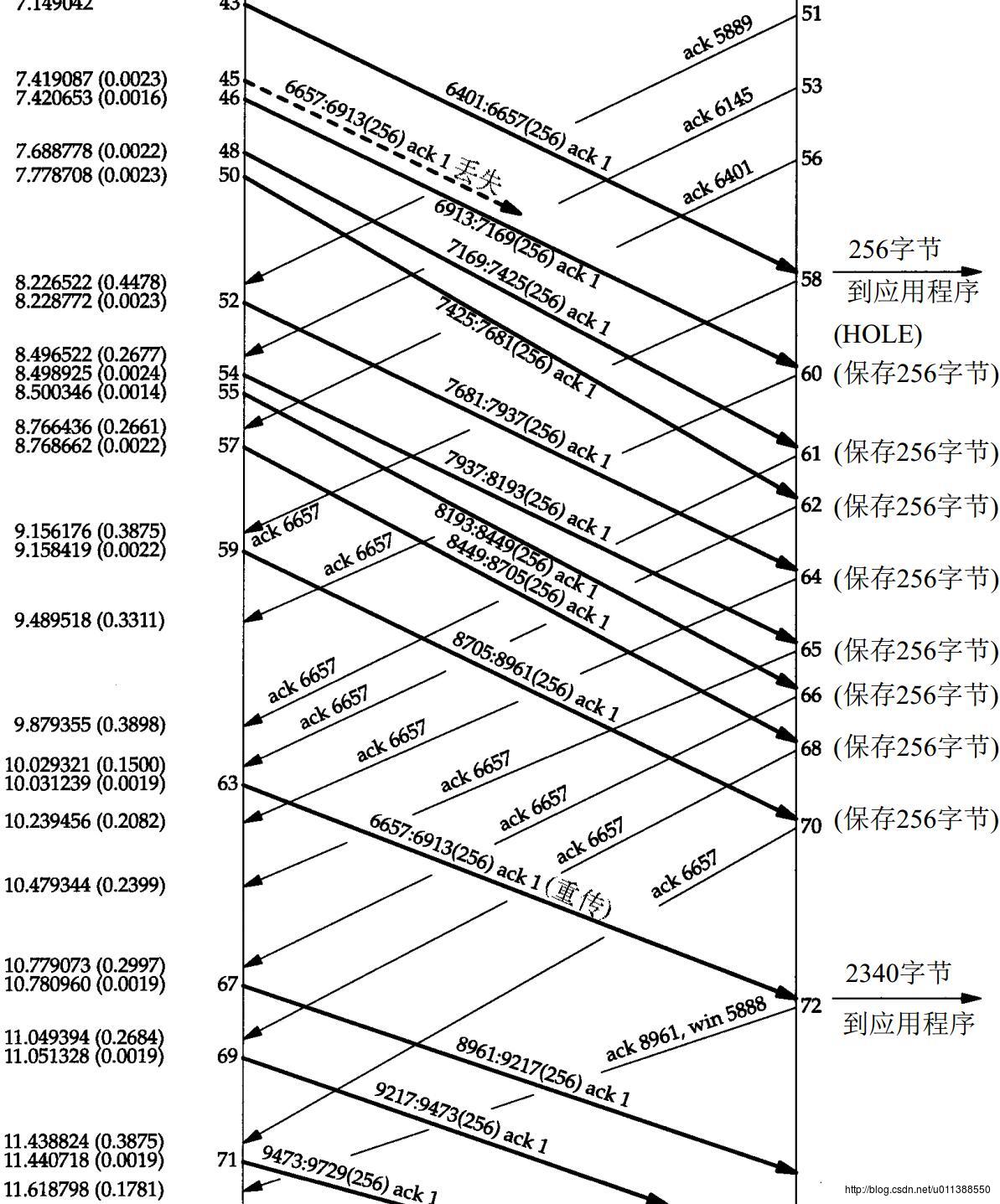
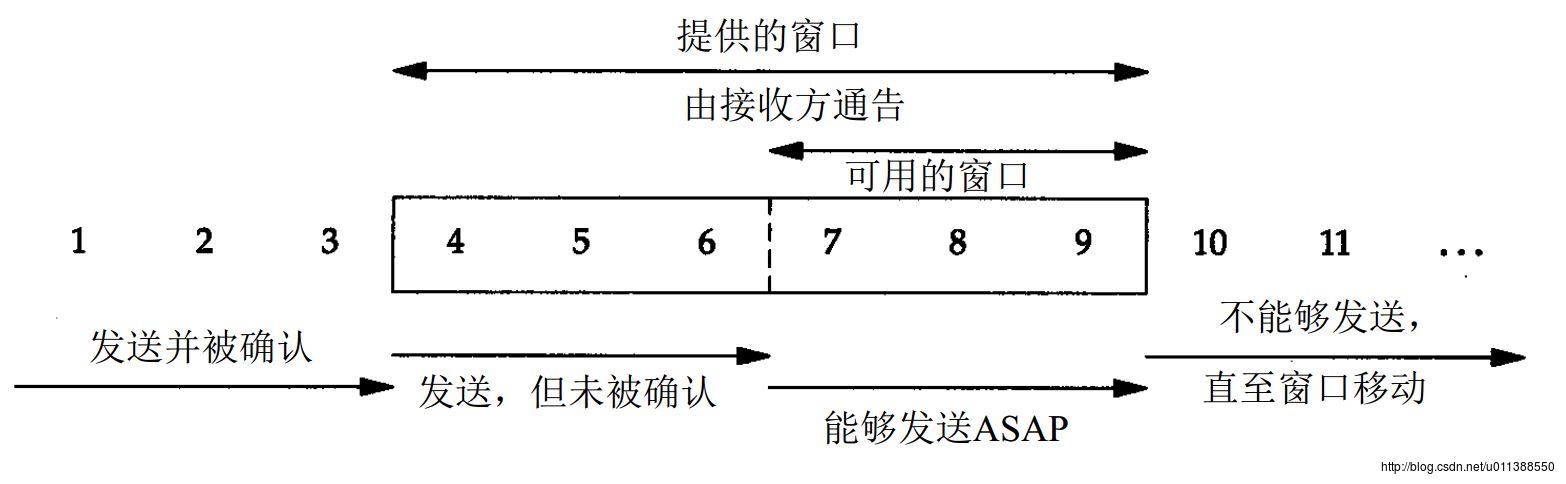
Seq可以帮助两件事:1.可以重组乱序的包;2.可以做到超时重传。直接拿书上的图说明好了。再下面这个例子中,左边发送端A利用seq做到超时重发,后边接收端B利用seq重组乱序包。
包的发送和确认有时间差,在发送包时,45号包丢失了,由于A也知道B的ACK信号不会这么快就到,于是A就接着发送后面的包,直到59号包。此时,A收到3次ACK6657,表示B在最近的几次通话中,6657号字节一直没有收到,期望收到6657号。A想:“不会啊,我明明都发到了8千多号了,怎么确认号还在6657,一直是6657号发丢了,那我重新发一次6657号吧,幸好我有保存6657号,太机智了”。于是A补发了一次6657号,这次B接收到了。后面的7千多,8千多号的信息B已经接收到,然后把缺的6657号补上,组成一个顺序的包,再提交给应用层。如果不管6657号,提早提交7千多号的包,就会造成接收信息无序。
谈谈如何提高UDP的可靠性
在实际生产中,我们可以根据具体业务模式在应用层对UDP进行增强。TCP可靠但效率差,UDP效率好但可靠性差,在效率和可靠性之间我们需要做一个权衡。可以这么认为,TCP和UDP是两个极端,我们没有必要重复造轮子,把UDP提高到TCP那个程度。TCP在许多方面都强于UDP,参考第4题。
最方便提高的一方面是保证每个包都能收到,我们可以先用时间戳计算出RTT,有了RTT就可以确定出超时时间限制。然后我们在应用层给每个包编号,发送端发送了包x,接收端收到包x后,需要告诉发送端“我收到包x了,你可以发下一个包x+1了”。这样就实现了保证每个包可以被收到,如果接收端的确认信息丢包,那么发送端在超时后,会再次发送,这时接收端只要忽略重复序号的包即可。此时相比于TCP,还是会出现乱序包以及发送端狂发包的现象。TCP 对网络拥堵的判断与重传
超时未收到ACK:报文未送达或者ACK丢失,发送端重传,重传时间间隔按照“指数退避”关系求出,从1秒持续增加到64秒。
重复收到确认号一样的ACK:某段报文未送达,发送端重传丢失的报文。
TCP 的流量控制是怎样的?
发送端的流量控制使用拥塞窗口,接收端的流量控制使用滑动窗口。不管哪个窗口,控制的都是发送端,因为流量的源头就是从发送端来的。
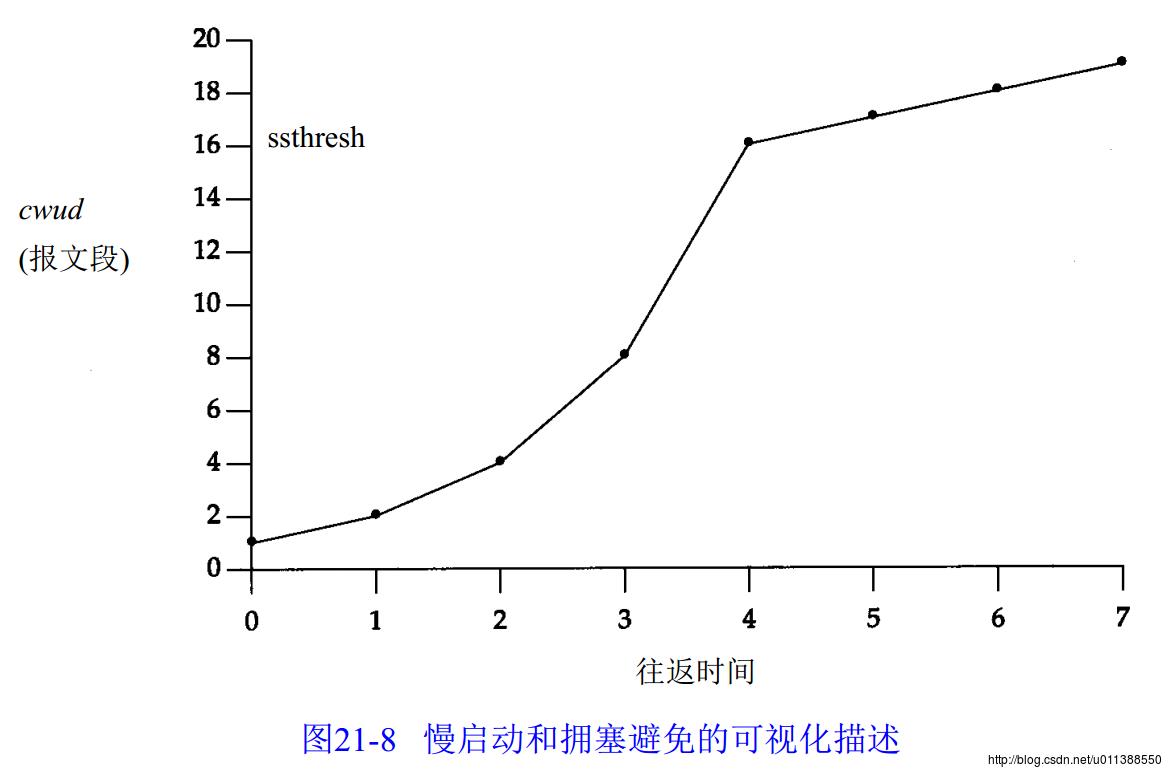
发送端:拥塞窗口cwnd和慢启动门限ssthresh这两个参数配合使用去做拥塞控制。发送端所能发的报文数量应该是滑动窗口和cwnd两者中的较小值。
在发送端发送第一个报文段时,cwnd是1,代表发送端只能发送1个报文,当发送端接收到ACK时,cwnd增加。当cwnd小于ssthresh时,cwnd指数增加,这阶段称为“慢启动”;当cwnd大于ssthresh时,cwnd线性增加,这个阶段称为“拥塞避免”。
接收端:滑动窗口告诉发送端,我就只能接收这么多,不要发太多给我啦。接收端接收到数据并发出ack后,窗口左边沿会右移,如果右边沿不动的话,窗口就变小了。接收端表示已经接收到这么数据啦,但应用层还未取走数据导致接收缓存紧张,接收端只能减小窗口防止后续大量数据过来。如果应用层取走了数据,接收缓存又空出来了,窗口右边沿会右移,接收端表示再来更多的数据吧。
TCP 中客户端发送 SYN 后客户端和服务器分别处在什么状态
客户在syn_sent,服务器还在listen,当服务器发出SYN和ACK后,服务器处于syn_rcvd
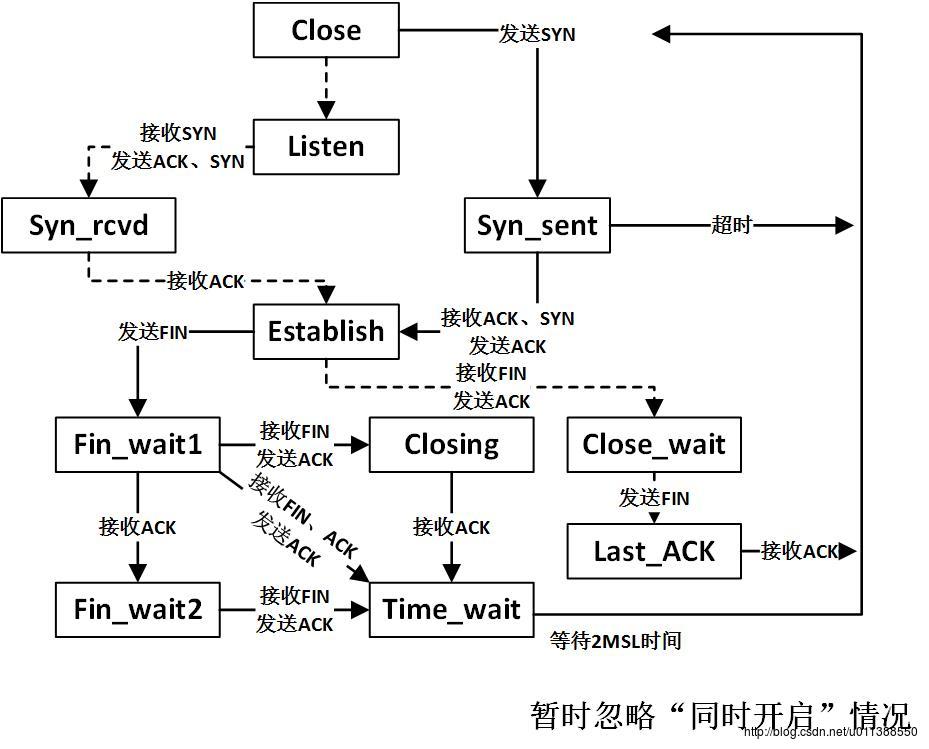
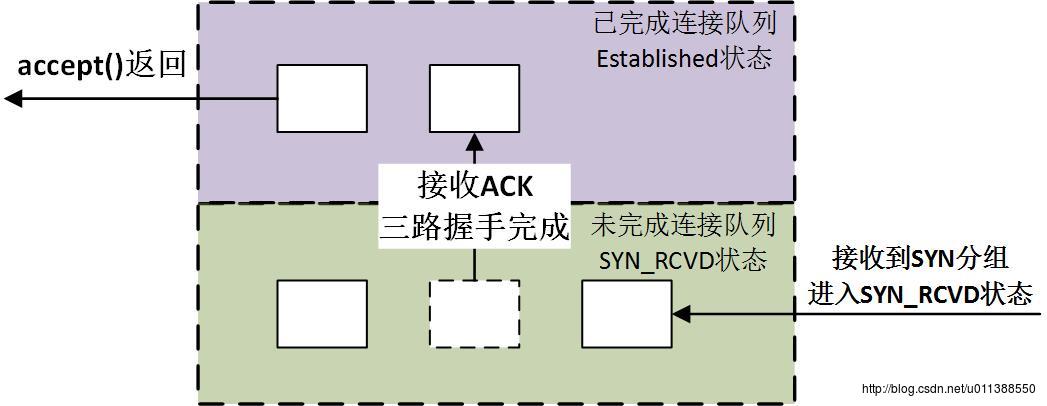
主动执行关闭(FIN)的一方需要等待2*MSL时间,MSL是报文从发送端到接收端的时间,2倍就是一个往返。这个等待时间是为了让发送端发出的ACK能被接收端收到。进程 accept 时在哪里取得套接字?
正如第2题的图所示,当accept返回时,说明该连接在已完成连接的队列中并要被移出。accept返回时,进程从内核取得套接字。
已连接和未连接队列的总长度不能超过参数backlog。
TCP服务器调用 send 后,是否可以认为客户端已收到?如何确保客户端收到数据?
成功调用send后,只是说明数据成功地被拷贝到socket缓冲区,并不能说明客户端成功接收,甚至数据都不一定被发送出去。
假设TCP运行顺利,数据被成功处理了,那也只能说明客户端的TCP协议栈收到了数据,应用程序可能应该死锁或阻塞等原因没有去读数据。要确保客户端收到数据,我们需要在应用层上做ACK。A 类地址和 B 类地址的区别
A类的网络数少,但每个网络数能容纳的主机数多;B类相反,类别以IP地址的第一个数字和子网掩码区分
A类:1-126,子网掩码:255.0.0.0
B类:128-191,子网掩码:255.255.0.0
C类:192-223,子网掩码:255.255.255.0局域网没有 ip 时如何通信?如何得知 mac 地址?
用RARP获取IP,用ARP获取MAC地址。在浏览器中输入url,按下回车后,发生了什么?
- 输入url
- 浏览器根据url查找IP地址,这一步叫DNS。查找顺序为浏览器缓存–>系统缓存–>路由器缓存–>ISP缓存
- 查找到IP地址后,浏览器向服务器发起http请求
- 服务器发送301永久重定向响应
- 浏览器向重定向之后的地址发送请求
- 服务器返回请求响应,状态码200
- 浏览器显示html
- 在HTML里会内嵌图片、CSS、js等文件,浏览器开始获取这些文件
HTTP 1.0 和 HTTP 1.1 的差别
HTTP1.1默认长连接
HTTP1.1首部有host字段
认证方式不一样HTTP 首部有哪些字段
分为3种首部:1.请求首部,只在http请求中出现;2.响应首部,只在http响应中出现;3.通用首部,在请求和响应中都可以出现。
请求首部的字段有:If Modified Since(跟304、缓存有关);User-Agent(浏览器信息)。
响应首部:Location(跟301永久重定向有关)
通用首部:Date(报文产生日期);Cache-Control(缓存控制);Connection(有持久连接Keep-alive选项)如何理解HTTP的无状态无连接
无状态:无状态的HTTP协议比较简单灵活,在早期可以处理大量事务。现在随着网页不断丰富内容,我们可以使用cookie来保存状态(虽然cookie为被列入HTTP1.1标准,但在web方面已经被广泛应用)。
无连接:HTTP协议在连接建立后,完成一次请求和响应,就断开连接,在早期web只有少量文本的时候是可行的,但现在web页面非常丰富,有图片、js、CSS等文件。按照无连接的做法,我们要获得一个丰富的完整的页面,需要多次“建立连接->请求->响应->断开连接”。在http1.1中,默认使用长连接,Connection字段设置Keep-alive选项。建立连接后,可以“请求->响应”多个回合再去断开连接。304 状态码的意义?在 HTTP 协议中的实现
304代表请求的资源没有新的更新,就使用浏览器的缓存好了。在客户端请求资源时,会把资源的Last Modified填入HTTP请求首部的If Modified Since字段,比较浏览器缓存的日期和服务器上的日期,来确定返回200还是304。cookie 和 session 的区别
get 与 post 的区别?访问安全性是否有区别?如何做到真正的访问安全
post将传输内容放在http主体里面;get将传输内容放在url里。两者都是明文传输,都不安全,相对来说get方法把信息暴露得更加彻底。真正的安全需要用https。如果发现网络不能访问会检查哪些方面?如果只有某个网站不能访问
- 没有登陆后台的情况猜测服务器挂掉会是什么原因?如果你是网站管理员用户反馈你的网站不能访问应该怎么做
- 在后台发现运行程序卡时应该怎么做?检查哪些方面
介绍 HTTPS。能否截获 HTTPS 的数据包
HTTPS是增加了加密机制的HTTP,在HTTP外面套了一层SSL协议。这个加密机制是共享加密和公开加密的结合。共享加密是指收发双方有一个相同的密码可以用来加密解密,这个共享密码不能公开;公开加密是指发方用公钥加密,收方用私钥解密,公钥是公开的,私钥是不公开的。HTTPS的加密过程是先使用公开加密的方式交换共享密码,后续的通信都使用共享密码(共享密码的运算比公钥私钥简单)。这样做到了安全和效率的平衡。
简单地总结一下HTTPS连接过程:
1.客户端发起请求
2.服务器响应一个证书
3.客户端验证证书的正确性(浏览器中已经安装了权威靠谱的证书,证书需要向权威机构购买,一般由企业购买,个人一般无公钥/私钥 对)
4.如果证书正确,就拿出证书中的公钥,用公钥加密后续使用的共享密码
5.服务器收到加密的共享密码,用私钥解密
6.双方进入共享加密通信
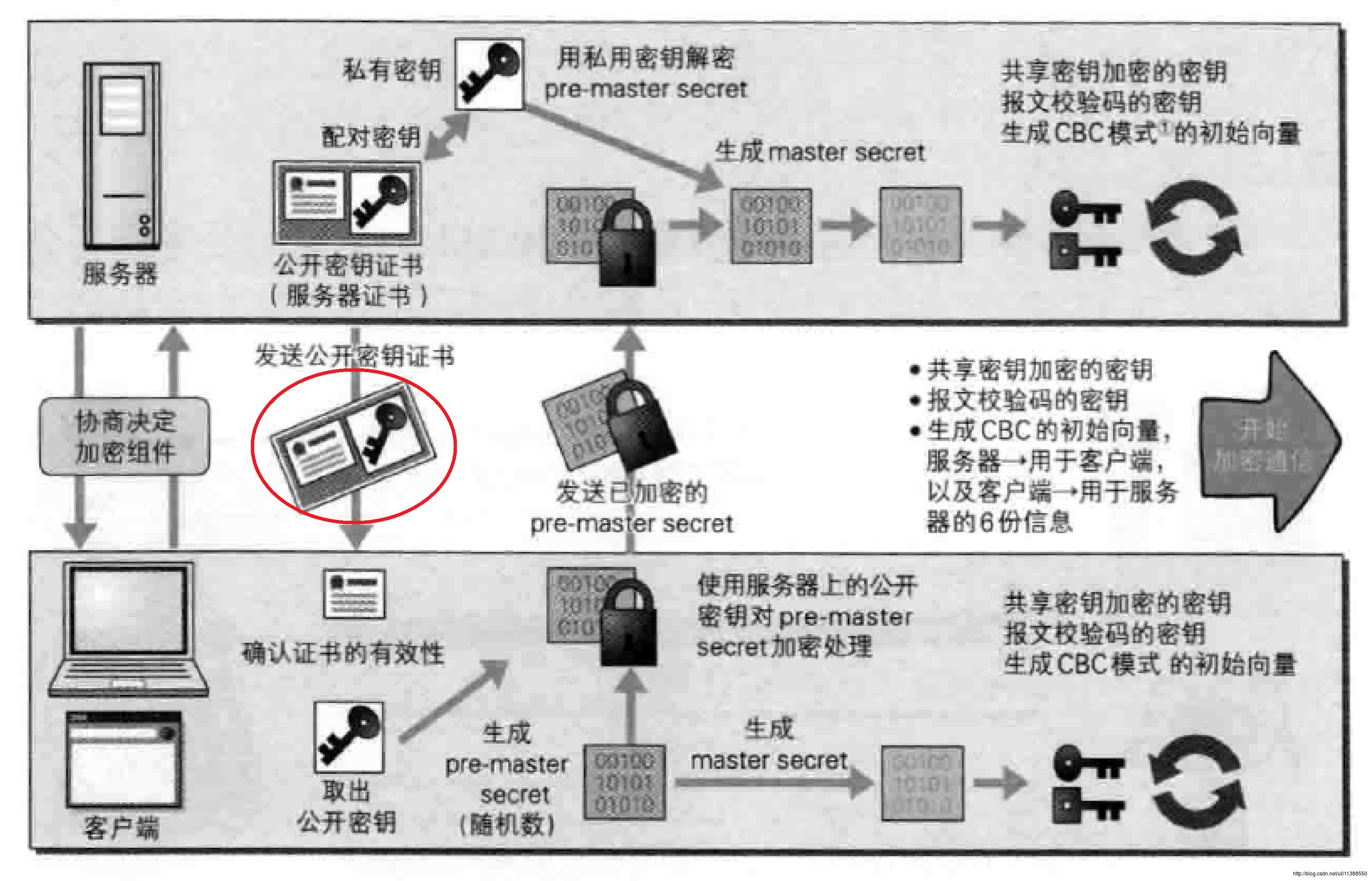
我们要特别注意图上的红圈部分,这个部分是至关重要的部分,如果发生中间人攻击(用户信息泄露且毫不知情),一般就是这个部分出问题。如果我们在浏览器上安装了不靠谱的证书,那么浏览器可能会把中间人认为是安全的。假设红圈处有一个中间人。
1.中间人拦截安全网站的信息,取出正规的证书和公钥,用自己的证书和公钥替换它,发送给客户端
2.客户端验证证书(这个证书是假的,如果浏览器不要安装来路不明的证书,就可以拒接中间人攻击。如果浏览器被安装了不靠谱证书,那么就会认为这个中间人证书是靠谱的),取出中间人的公钥加密后续通信的共享密码。
3.中间人用自己的私钥解密,取出共享密码,再将收到的信息用正规公钥加密,发送给正规服务器。
4.正规服务器收到共享密码,其实这时共享密码已经泄露出去,而且双方毫不知情。vpn 工作原理
VPN是一种代理,把我们的电脑连上VPN,当我们去访问一些网站的时候,就由VPN帮忙去转发请求,那么我们就可以浏览一些本网络不能访问,但VPN可以访问的网站。
【Reference】
可靠UDP http://www.cnblogs.com/adinosaur/p/5983233.html
在浏览器地址栏输入URL,按下回车后究竟发生了什么 http://blog.csdn.net/bruce_6/article/details/39499439
https原理 https://www.zhihu.com/question/24484809
https原理 http://www.cnblogs.com/JohnABC/p/5991988.html
以上是关于网络知识点的主要内容,如果未能解决你的问题,请参考以下文章