PGL图学习之基于UniMP算法的论文引用网络节点分类任务[系列九]
Posted 汀、
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PGL图学习之基于UniMP算法的论文引用网络节点分类任务[系列九]相关的知识,希望对你有一定的参考价值。
项目链接:PGL图学习之基于UniMP算法的论文引用网络节点分类任务[系列九]
1.常规赛:图神经网络入门节点分类介绍
(1)赛题介绍
图神经网络(Graph Neural Network)是一种专门处理图结构数据的神经网络,目前被广泛应用于推荐系统、金融风控、生物计算中。图神经网络的经典问题主要有三种,包括节点分类、连接预测和图分类三种,本次比赛是主要让同学们熟悉如何图神经网络处理节点分类问题。
在过去的一个世纪里,科学出版物的数量每12年增加近一倍,对每一种出版物的主题及领域进行自动分类已成为当下十分重要的工作。本次任务的目标是预测未知论文的主题类别,如软件工程,人工智能,语言计算和操作系统等。比赛所选35个领域标签已得到论文作者和arXiv版主确认并标记。
本次比赛选用的数据集为arXiv论文引用网络——ogbn-arixv数据集的子集。ogbn-arixv数据集由大量的学术论文组成,论文之间的引用关系形成一张巨大的有向图,每一条有向边表示一篇论文引用另一篇论文,每一个节点提供100维简单的词向量作为节点特征。在论文引用网络中,我们已对训练集对应节点做了论文类别标注处理。本次任务希望参赛者通过已有的节点类别以及论文之间的引用关系,预测未知节点的论文类别。
(2)数据描述
本次赛题数据集由学术网络图构成,该图会给出每个节点的特征,以及节点与节点间关系(训练集节点的标注结果已给出)。
1.1 数据集简介
1.学术网络图数据:
该图包含164,7958条有向边,13,0644个节点,参赛者报名成功后即可通过比赛数据集页面提供edges.csv以及feat.npy下载并读取数据。图上的每个节点代表一篇论文,论文从0开始编号;图上的每一条边包含两个编号,例如 3,4代表第3篇论文引用了第4篇论文。图构造可以参照AiStudio上提供的基线系统项目了解数据读取方法。
2.训练集与测试集:
训练集的标注数据有70235条,测试集的标注数据有37311条。训练数据给定了论文编号与类别,如3,15 代表编号为3的论文类别为15。测试集数据只提供论文编号,不提供论文类别,需要参赛者预测其类别。
具体数据介绍:
| 数据集 | 简介 |
|---|---|
| edges.csv | 边数据:用于标记论文间引用关系 |
| feat.npy | 节点数据:每个节点含100维特征 |
| train.csv | 训练集数据 |
| test.csv | 测试集数据 |
1.图数据:
feat.npy为Numpy格式存储的节点特征矩阵,Shape为(130644, 100),即130644个节点,每个节点含100维特征。其中 feat.npy可以用numpy.load(“feat.npy”)读取。edges.csv用于标记论文引用关系,为无向图,且由两列组成,没有表头。
| 字段 | 说明 |
|---|---|
| 第一列 | 边的初始节点 |
| 第二列 | 边的终止节点 |
2.训练集: train.csv
| 字段 | 说明 |
|---|---|
| nid | 训练节点在图上的Id |
| label | 训练节点的标签(类别编号从0开始,共35个类别) |
3.测试集: test.csv
| 字段 | 说明 |
|---|---|
| nid | 测试节点在图上的Id |
相关资料
飞桨PGL图学习框架飞桨PGL图学习框架基本能够覆盖大部分的图网络应用,包括图表示学习以及图神经网络。
节点分类实例分享包含多种引用网络模型,如GCN、GAT、GCNII、APPNP等。
UniMP模型统一消息传递模型UniMP,同时实现了节点的特征与标签传递,显著提升了模型的泛化效果。
提交内容与格式
最终提交的submission.csv 格式如下:
| 字段 | 说明 |
|---|---|
| nid | 测试集节点在图上的id |
| label | 测试集的节点类别 |
特别提示: 提交的结果必须是类别的id,不能是概率。
提交样例:
| nid | label |
|---|---|
| 2 | 34 |
| 3 | 1 |
| 4 | 15 |
| … | … |
注意:选手提交的csv文件的第一行为”nid,label”,顺序调转将视为无效答案。接下来每一行的两个数字依次表示测试集提供的节点id以及对应的预测论文类别,注意给出的预测类别id要属于给定范围值且必须是整数。提交的数据行数要与test.csv一致。
2.BaseLine代码讲解
2.1 代码整体逻辑
-
读取提供的数据集,包含构图以及读取节点特征(用户可自己改动边的构造方式)
-
配置化生成模型,用户也可以根据教程进行图神经网络的实现。
-
开始训练
-
执行预测并产生结果文件
环境配置
该项目依赖飞桨paddlepaddle1.8.4, 以及pgl1.2.0。请按照版本号下载对应版本就可运行。
2.1.1 Config部分注解
from easydict import EasyDict as edict
'''模块说明:
easydict这个模块下的EasyDict,可以使得创建的字典像访问属性一样
eg:
dicts = 'A': 1
print(dicts['A']) => 1
使用EasyDict之后:
dicts = EasyDict(dicts)
print(dicts.A) => 1
'''
#模型参数字典
config =
"model_name": "GCNII", #模型名称,可以参考model.py、modelfied.py文件里面有 gcn gat appnp unimp等模型
"num_layers": 1, # 网络层数--这个实现在模型类的forward里边,通过循环实现
"dropout": 0.5, # 训练时,参数drop概率
"learning_rate": 0.0002, # 训练优化的学习率
"weight_decay": 0.0005, # 权重正则化率
"edge_dropout": 0.00, # 边drop概率
config = edict(config) # 利用EasyDict便利字典的读取
2.1.2 数据读取与处理部分
创建一个命名索引元组
from collections import namedtuple
'''模块说明:
collections是一个python基础数据结构的扩充库:
包含以下几种扩展:
1. namedtuple(): 生成可以使用名字来访问元素内容的tuple子类
2. deque: 双端队列,可以快速的从另外一侧追加和推出对象
3. Counter: 计数器,主要用来计数
4. OrderedDict: 有序字典
5. defaultdict: 带有默认值的字典
而现在用到的namedtuple(): 则是生成可以使用名字来访问元素内容的tuple子类
eg:
websites = [
('math', 98, '张三'),
('physics', 74, '李四'),
('english', 85, '王二')
]
Website = namedtuple('Website', ['class', 'score', 'name'])
for website in websites:
website = Website._make(website)
print website
show:
Website(class='math', score=98, name='张三')
Website(class='physics', score=74, name='李四')
Website(class='english', score=85, name='王二')
'''
#创建一个可以使用名字来访问元素内容的tuple--作为Dataset数据集
#包含图、类别数、训练索引集、训练标签、验证索引集、验证标签、测试索引集
Dataset = namedtuple("Dataset",
["graph", "num_classes", "train_index",
"train_label", "valid_index", "valid_label", "test_index"])
2.1.3 边数据的加载与处理
#加载边数据
def load_edges(num_nodes, self_loop=True, add_inverse_edge=True):
'''
input:
num_nodes: 节点数
self_loop: 是否加载自环边
add_inverse_edge: 是否添加反转的边--我的理解是正反都添加--即对应无向图的情况
'''
#从数据中读取边
edges = pd.read_csv("work/edges.csv", header=None, names=["src", "dst"]).values
#反转边添加
if add_inverse_edge:
edges = np.vstack([edges, edges[:, ::-1]]) # vstack沿竖直方向拼接--如:A =[1, 2] , B = [2, 3]; vstack([A, B]) => [[1, 2], [2, 3]]
# eg: edges=[[1, 3], [2, 5], [6, 7]] => edges[:, ::-1]=[[3, 1], [5, 2], [7, 6]]
# 再拼接就得到了正反边的一个集合了
#自环边添加
if self_loop:
src = np.arange(0, num_nodes) # 定义n和节点作为起点
dst = np.arange(0, num_nodes) # 定义n个节点作为终点--且与src一一对应
self_loop = np.vstack([src, dst]).T # 再将两个行向量拼接(此时shape:[2, num_nodes]), 然后再转置T=>得到shape:[num_node, 2]这是的数据0->0, 1->1 ...就得到了自环边的数据
edges = np.vstack([edges, self_loop]) # 将自环边数据添加到本身的边数据中
return edges
2.1.4 数据的完整加载与处理
def load():
# 从数据中读取点特征和边,以及数据划分
node_feat = np.load("work/feat.npy") # 读取节点特征--每个节点100个特征
num_nodes = node_feat.shape[0] # shape[0] 正好对应节点个数
edges = load_edges(num_nodes=num_nodes, self_loop=True, add_inverse_edge=True) # 根据实际传入的节点数,返回合理的边--这里包含自环边以及正向和反向的边
graph = pgl.graph.Graph(num_nodes=num_nodes, edges=edges, node_feat="feat": node_feat) # 创建图:节点数、边数据、以及节点特征的字典
indegree = graph.indegree() # 计算当前图的所有节点的入度--返回一个list==>等价于graph.indegree(nodes=None),nodes指定,返回指定的入度
norm = np.maximum(indegree.astype("float32"), 1) # 取最大入度中的一个然后返回
norm = np.power(norm, -0.5) # 利用这个最大入读计算一个归一化参数
graph.node_feat["norm"] = np.expand_dims(norm, -1) # 将归一化参数添加到节点的norm特征中, shape[1], 只含有一个元素的序列,但不算标量:如,a 和 [a]
df = pd.read_csv("work/train.csv") # 读取总的训练数据
node_index = df["nid"].values # 读取总的节点的索引序列(集)
node_label = df["label"].values # 读取总的节点的label序列
train_part = int(len(node_index) * 0.8) # 划分训练数据集--80%--这里是计算一个训练集数目值
train_index = node_index[:train_part] # 利用训练集数目进行划分--0:train_part
train_label = node_label[:train_part] # 训练label划分
valid_index = node_index[train_part:] # 验证数据valid_index划分
valid_label = node_label[train_part:] # 验证valid_label划分
test_index = pd.read_csv("work/test.csv")["nid"].values # 读取测试集--也就是赛题提交数据--指定读取['nid']列数据
# 这是一个可以使用名字来访问元素内容的tuple子类
# 所以直接对应传入数据即可
dataset = Dataset(graph=graph,
train_label=train_label,
train_index=train_index,
valid_index=valid_index,
valid_label=valid_label,
test_index=test_index, num_classes=35)
return dataset # 最后返回dataset数据
2.1.5 数据读取与分割
这一部分的分割和load中的命名索引元组有关!
dataset = load() # 执行load函数获取完整的dataset(可命名索引的tuple)数据
# 从dataset中读取出相应数据
train_index = dataset.train_index # 读取训练索引序列
train_label = np.reshape(dataset.train_label, [-1 , 1]) # 读取训练label序列
train_index = np.expand_dims(train_index, -1) # 在最后一位添加一个维度,保证数据向量化[[a]]
val_index = dataset.valid_index # 读取验证索引序列
val_label = np.reshape(dataset.valid_label, [-1, 1]) # 读取训练label序列
val_index = np.expand_dims(val_index, -1) # 在最后一位添加一个维度,保证数据向量化[[a]]
test_index = dataset.test_index # 读取训练索引序列
test_index = np.expand_dims(test_index, -1) # 在最后一位添加一个维度,保证数据向量化[[a]]
test_label = np.zeros((len(test_index), 1), dtype="int64") # 用于保存最终结果--提前用zeros创建一个空白矩阵,并指明数据类型
2.1.6 模型加载部分
为了避免分解太多,这里也包含了执行器相关的部分代码注释!
import pgl
import model # model.py
import paddle.fluid as fluid
import numpy as np
import time
from build_model import build_model # build_model.py
use_gpu = True
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace() # 工作环境--这里有修改--需要用cpu只需要把use_gpu设置为False即可
train_program = fluid.default_main_program() # 创建主program -- paddle静态图都是在相应的program中运行的 -- 通常为start
startup_program = fluid.default_startup_program() # 创建start_program -- 是我们运行的开始
# 以下是配置执行器执行空间(block)的操作部分--个人觉得,如果只是使用,记住使用规范即可
# program_guard接口配合使用python的 with 语句来将 with block 里的算子和变量添加进指定的全局主程序(main program)和启动程序(startup program)。
with fluid.program_guard(train_program, startup_program): # 以下执行的算子等都会放入到train_program->startup_program的block中
with fluid.unique_name.guard(): # 开启一个命名空间--常用program_guard一起使用
# 这里使用到build_model.py中的函数,执行模型和参数的配置,并返回相关的data变量
# 这个过程的算子都会被记录到(train_program, startup_program)对应的工作空间中
gw, loss, acc, pred = build_model(dataset,
config=config,
phase="train",
main_prog=train_program)
# 创建一个新的Program作为test_program
test_program = fluid.Program()
with fluid.program_guard(test_program, startup_program): # 含义如上,这里是开启(test_program, startup_program)的工作空间,并记录相应的算子、变量
with fluid.unique_name.guard(): # 开启一个命名空间
# 返回test的模型参数等
_gw, v_loss, v_acc, v_pred = build_model(dataset,
config=config,
phase="test",
main_prog=test_program)
# 总结——program_guard确定工作环境--unique_name开启一个相应的命名空间,相辅相成。
test_program = test_program.clone(for_test=True) # 克隆test_program
exe = fluid.Executor(place) # 创建一个解释器
2.1.7. 模型训练过程
这个部分就相对比较简单,就是利用执行器喂参数和算子就可以啦!
epoch = 4000 # 训练轮次
exe.run(startup_program) # 执行器运行-->优先执行
# 将图数据变成 feed_dict 用于传入Paddle Excecutor
# 图数据原型:graph = pgl.graph.Graph(num_nodes=num_nodes, edges=edges, node_feat="feat": node_feat) # 创建图:节点数、边数据、以及节点特征的字典
feed_dict = gw.to_feed(dataset.graph) # 调用to_feed方法,将图数据转换为feed_dict,用于执行器的输入参数
# 训练开始
for epoch in range(epoch):
# Full Batch 训练 == 单batch_size训练--全数据一次投入
# 设定图上面那些节点要获取
# node_index: 训练节点的nid
# node_label: 训练节点对应的标签
feed_dict["node_index"] = np.array(train_index, dtype="int64") # 往feed_dict中添加键值对数据--每一个轮次数据都会重新赋值更新
feed_dict["node_label"] = np.array(train_label, dtype="int64")
train_loss, train_acc = exe.run(train_program, # 执行器执行--执行train_program这个program空间内的算子和参数
feed=feed_dict, # 传入的数据:graph..., node_index, node_label
fetch_list=[loss, acc], # 需要计算返回的数据
return_numpy=True) # 返回numpy数据
# Full Batch 验证 == 单batch_size验证--全数据一次投入
# 设定图上面那些节点要获取
# node_index: 训练节点的nid
# node_label: 训练节点对应的标签
feed_dict["node_index"] = np.array(val_index, dtype="int64") # 往feed_dict中添加键值对数据--每一个轮次数据都会重新赋值更新
feed_dict["node_label"] = np.array(val_label, dtype="int64")
val_loss, val_acc = exe.run(test_program, # 执行器执行--执行test_program这个program空间内的算子和参数
feed=feed_dict, # 传入的数据:graph..., node_index, node_label
fetch_list=[v_loss, v_acc], # 需要计算返回的数据
return_numpy=True) # 返回numpy数据
print("Epoch", epoch, "Train Acc", train_acc[0], "Valid Acc", val_acc[0]) # 打印训练数据
2.1.8 模型进阶
- 自己动手实现图神经网络
这里以想自己实现一个CustomGCN为例子,首先,我们在model.py 创建一个类CustomGCN
import paddle.fluid.layers as L
class CustomGCN(object):
"""实现自己的CustomGCN"""
def __init__(self, config, num_class):
# 分类的数目
self.num_class = num_class
# 分类的层数,默认为1
self.num_layers = config.get("num_layers", 1)
# 中间层 hidden size 默认64
self.hidden_size = config.get("hidden_size", 64)
# 默认dropout率0.5
self.dropout = config.get("dropout", 0.5)
def forward(self, graph_wrapper, feature, phase):
"""定义前向图神经网络
graph_wrapper: 图的数据的容器
feature: 节点特征
phase: 标记训练或者测试阶段
"""
# 通过Send Recv来定义GCN
def send_func(src_feat, dst_feat, edge_feat):
# 发送函数简单将输入src发送到输出节点dst。
return "output": src_feat["h"]
def recv_func(msg):
# 对消息函数进行简单求均值
return L.sequence_pool(msg["output"], "average")
# 调用发送
message = graph_wrapper.send(send_func,
nfeat_list=[ ("h", feature)])
# 调用接收
output = graph_wrapper.recv(message, recv_func)
# 对输出过一层MLP
output = L.fc(output, size=self.num_class, name="final_output")
然后,我们只要改一下本notebook脚本的config,把model_type改成CustomGCN就能跑起来了。
config =
"model_name": "CustomGCN",
- 残差-GAT改写
class ResGAT(object):
"""Implement of ResGAT"""
def __init__(self, config, num_class):
self.num_class = num_class
self.num_layers = config.get("num_layers", 1)
self.num_heads = config.get("num_heads", 8)
self.hidden_size = config.get("hidden_size", 8)
self.feat_dropout = config.get("feat_drop", 0.6)
self.attn_dropout = config.get("attn_drop", 0.6)
self.edge_dropout = config.get("edge_dropout", 0.0)
def forward(self, graph_wrapper, feature, phase):
# feature [num_nodes, 100]
if phase == "train":
edge_dropout = self.edge_dropout
else:
edge_dropout = 0
feature = L.fc(feature, size=self.hidden_size * self.num_heads, name="init_feature")
for i in range(self.num_layers):
ngw = pgl.sample.edge_drop(graph_wrapper, edge_dropout)
res_feature = feature
# res_feature [num_nodes, hidden_size * n_heads]
feature = conv.gat(ngw,
feature,
self.hidden_size,
activation=None,
name="gat_layer_%s" % i,
num_heads=self.num_heads,
feat_drop=self.feat_dropout,
attn_drop=self.attn_dropout)
# feature [num_nodes, num_heads * hidden_size]
feature = res_feature + feature
# [num_nodes, num_heads * hidden_size] + [ num_nodes, hidden_size * n_heads]
feature = L.relu(feature)
feature = L.layer_norm(feature, name="ln_%s" % i)
ngw = pgl.sample.edge_drop(graph_wrapper, edge_dropout)
feature = conv.gat(ngw,
feature,
self.num_class,
num_heads=1,
activation=None,
feat_drop=self.feat_dropout,
attn_drop=self.attn_dropout,
name="output")
return feature
更多进阶模型就在2.2节
2.2模型代码讲解:model.py的内容解析
2.2.1 GCN模型代码讲解
- GCN需要用到的一个计算归一参数的方法
def get_norm(indegree):
'''
入度归一化函数: 返回一个浮点数类型的最小值为1.0的入度值序列
入度值:可以表示无向图中当前节点的邻边,而对于有向图则是指向当前节点的边数
'''
float_degree = L.cast(indegree, dtype="float32") # data的类型转换后的值返回给float_degree,值返回
float_degree = L.clamp(float_degree, min=1.0) # 值裁剪--将其中小于1的值赋值为1.0 -->个人的考虑是,添加自环边的入度
norm = L.pow(float_degree, factor=-0.5) # 倒数开根号,获取归一化的入度
# TODO: 度为float类型?
# CALL: 为了后边方便用于计算,float数据更适合后边所需的运算
return norm # 返回一个归一化的度,用于公式计算
- GCN模型代码注解
class GCN(object):
"""Implement of GCN
"""
def __init__(self, config, num_class):
self.num_class = num_class # 节点种类
self.num_layers = config.get("num_layers", 1) # 模型层数
self.hidden_size = config.get("hidden_size", 64) # 中间层输出大小--不一定只有一层中间层哈--跟num_layers有关
self.dropout = config.get("dropout", 0.5) # fc层的drop率
self.edge_dropout = config.get("edge_dropout", 0.0) # 边drop率--为了获取一个忽略指定数目的随机子图(忽略部分边属性,然后生成一个新的子图用于训练--仅仅用于训练而已)
def forward(self, graph_wrapper, feature, phase):
'''
graph_wrapper: 一个图容器,用于存储图信息,并可以迭代训练与预测
feature:图的节点特征
phase:指令--train or eval or test等
功能:
实现将输入的图进行一个简单的处理--通过n层图卷积实现特征提取,然后经过一个dropout层抑制过拟合;
最后经过第二个图卷积获取类别数的输出,根据相应的处理得到需要的预测结果。
如:softmax进行一个类别处理,利用argmax的到分类的类别【具体过程详见build_model.py】
'
注意: 在GCN中,需要计算一个norm值,用于GCN的推断训练,以及后期的预测【详见GCN推导的公式】
'
'''
# GCN这个layer的返回值:张量shape:(num_nodes,hidden_size)
for i in range(self.num_layers): # 根据层数进行迭代
if phase == "train": # 训练模式--才有边drop
# 每次调用edge_drop(graph_wrapper, self.edge_dropout)结果可能不同
ngw = pgl.sample.edge_drop(graph_wrapper, self.edge_dropout) # 传入输入图,然后根据edge_dropout随机生成忽略某些边属性的新子图
norm = get_norm(ngw.indegree()) # 归一化出度--得到计算参数
else: # eval/test模式
ngw = graph_wrapper # 新子图就是原始图
norm = graph_wrapper.node_feat["norm"] #
# 利用pgl自带的网络进行配置
feature = pgl.layers.gcn(ngw, # 传入图
feature, # 相应的特征--训练过程中,最多只是对边有修改,并不涉及节点变化
self.hidden_size, # 输出大小
activation="relu", # 激活函数
norm=norm, # 归一化值--用于gcn公式计算
name="layer_%s" % i) # 层名称
# 在此后紧跟dropout进行,防止过拟合
# 根据给定的丢弃概率,dropout操作符按丢弃概率随机将一些神经元输出设置为0,其他的仍保持不变。
feature = L.dropout(
feature, # 上一级的输出
self.dropout, # drop率
dropout_implementation='upscale_in_train') # drop配置upscale_in_train表示,仅在训练时drop,评估预测不实现drop
# 将以上迭代部分做完后,再通过下边这个部分输出结果
if phase == "train": # 训练模式下
ngw = pgl.sample.edge_drop(graph_wrapper, self.edge_dropout) # 同前边一样的过滤一些边--基本效果同普通的dropout,这里作用于边而已
norm = get_norm(ngw.indegree())
else:
ngw = graph_wrapper
norm = graph_wrapper.node_feat["norm"]
# 再通过一层图卷积层
feature = conv.gcn(ngw,
feature,
self.num_class, # 输出结果就是我们实际节点训练或预测输出的类别情况:详见PS1
activation=None,
norm=norm,
name="output") # 最后返回一个shape[-1]=num_class的数据,然后我们对数据处理只需要经过一个softmax,再argmax就得到了预测得到了节点的类别了
return feature
2.2.2 GAT模型代码讲解
class GAT(object):
#Implement of GAT
def __init__(self, config, num_class):
self.num_class = num_class # 类别数
self.num_layers = config.get("num_layers", 1) # 层数
self.num_heads = config.get("num_heads", 8) # 多头注意力 -- 8*8尽量别改吧,反正我改了效果不好,可能是调参技术不好
self.hidden_size = config.get("hidden_size", 8) # 中间层输出大小--不一定只有一层中间层哈--跟num_layers有关
self.feat_dropout = config.get("feat_drop", 0.6) # 特征drop率
self.attn_dropout = config.get("attn_drop", 0.6) # 参数drop率
self.edge_dropout = config.get("edge_dropout", 0.0) # 边drop率
def forward(self, graph_wrapper, feature, phase):
graph_wrapper: 一个图容器,用于存储图信息,并可以迭代训练与预测
feature:图的节点特征
phase:指令--train or eval or test等
功能:
首先根据运行模式,确定edge_drop率
然后进入网络叠加的循环中,进行pgl.sample.edge_drop后的子图获取,接着通过一个gat的layer--头尾8,输出大小为8,得到可叠加的特征输出
循环结束后,再通过一个头为1,输出大小为num_class的gat,得到输出结果
根据相应的处理得到需要的预测结果。
如:softmax进行一个类别处理,利用argmax的到分类的类别 【具体过程详见build_model.py】
if phase == "train": # 训练模式才会进行边drop
edge_dropout = self.edge_dropout
else:
edge_dropout = 0
# 在GAT中,只需要简单进行遍历层叠加即可
# GAT这个layer的返回值:张量shape:(num_nodes,hidden_size * num_heads)
for i in range(self.num_layers): # 遍历num_layers层网络
ngw = pgl.sample.edge_drop(graph_wrapper, edge_dropout) # 随机边drop
# gat网络layer
feature = conv.gat(ngw, # 传入图容器--传入模型中的都不是简单的图,而是经过pgl中对应的图容器(不是pgl.Graph哦)
feature, # 特征参数--节点特征
self.hidden_size, # 输出大小
activation="elu", # 激活函数
name="gat_layer_%s" % i, # nameed
num_heads=self.num_heads, # 头数
feat_drop=self.feat_dropout, # 特征drop率
attn_drop=self.attn_dropout) # 参数drop率
# 最后再通过一层实现结果输出
ngw = pgl.sample.edge_drop(graph_wrapper, edge_dropout)
feature = conv.gat(ngw, # 图
feature, # 特征参数--节点特征
self.num_class, # 输出大小为类别数--用于预测
num_heads=1, # 头数变为1
activation=None, # 不需要激活函数
feat_drop=self.feat_dropout, # 特征drop率
attn_drop=self.attn_dropout, # 参数drop率
name="output")
return feature # 返回预测结果
2.2.3 APPNP模型代码讲解
#新网络学习-APPNP
class APPNP(object):
"""Implement of APPNP"""
def __init__(self, config, num_class):
self.num_class = num_class # 类别数
self.num_layers = config.get("num_layers", 1) # 层数
self.hidden_size = config.get("hidden_size", 64) # 中间层输出大小--不一定只有一层中间层哈--跟num_layers有关
self.dropout = config.get("dropout", 0.5) # drop率——指的是fc层中用到的dopr率
self.alpha = config.get("alpha", 0.1) # alpha值---用于公式计算_论文中的超参数
self.k_hop = config.get("k_hop", 10) # k_hop值---网络传播次数
self.edge_dropout = config.get("edge_dropout", 0.0) # 边drop率
def forward(self, graph_wrapper, feature, phase):
'''
graph_wrapper: 一个图容器,用于存储图信息,并可以迭代训练与预测
feature:图的节点特征
phase:指令--train or eval or test等
功能:
首先根据运行模式,确定edge_drop率
然后进入循环遍历叠加网络层,这里不同于之前的网络---这里叠加的是fc层和drop操作--先drop,后fc
APPNP仅仅一个--并且由于APPNP层无法改变中间层大小,所以在传入前要把对应的feature转换为跟num_class相关的大小
根据相应的处理得到需要的预测结果。
如:softmax进行一个类别处理,利用argmax的到分类的类别 【具体过程详见build_model.py】
'''
if phase == "train": # 训练模式才会进行边drop
edge_dropout = self.edge_dropout
else:
edge_dropout = 0
# APPNP比较特殊,这里的num_layers层数是指前层网络fc的深度,而不是直接叠加APPNP层
for i in range(self.num_layers):
feature = L.dropout(
feature, # 需要drop的特征
self.dropout, # drop率
dropout_implementation='upscale_in_train') # 训练时drop,非训练不drop
feature = L.fc(feature, self.hidden_size, act="relu", name="lin%s" % i)
# 完成上述操作后,再重复一次相同的操作,最后调整输出为num_class
feature = L.dropout(
feature,
self.dropout,
dropout_implementation='upscale_in_train')
feature = L.fc(feature, self.num_class, act=None, name="output") # 为appnp做好准备
# APPNP这个layer的返回值:张量:shape(num_nodes,hidden_size)
# 不能修改输出的new_hidden_size,只能使用传入的feature的数据形状hidden_size(num_class)
feature = conv.appnp(graph_wrapper, # 传入图容器
feature=feature, # 特征--节点特征
edge_dropout=edge_dropout, # 边drop率
alpha=self.alpha, # alpha值_论文中的超参数
k_hop=self.k_hop) # 传播次数————这个部分太大,会显存爆炸哈
return feature
2.2.4 SGC模型代码讲解——(APPNP模型补充)
#单APPNP网络
class SGC(object):
"""Implement of SGC"""
def __init__(self, config, num_class):
self.num_class = num_class # 类别数
self.num_layers = config.get("num_layers", 1) # 层数
def forward(self, graph_wrapper, feature, phase):
'''
graph_wrapper: 一个图容器,用于存储图信息,并可以迭代训练与预测
feature:图的节点特征
phase:指令--train or eval or test等
功能:
直接将图容器传入appnp层中,不经过任何处理,也不进行任何drop
然后再经过fc层得到合适形状的输出
根据相应的处理得到需要的预测结果。
如:softmax进行一个类别处理,利用argmax的到分类的类别 【具体过程详见build_model.py】
'''
# APPNP这个layer的返回值:张量:shape(num_nodes,hidden_size)
# 这里的hidden_size是输入feature的最低维度大小
feature = conv.appnp(graph_wrapper,
feature=feature,
edge_dropout=0, # drop为零
alpha=0, # 论文中的超参数
k_hop=self.num_layers)
feature.stop_gradient=True # 在这里停止梯度计算--也就是之后的运算计算相应的梯度,用于优化
feature = L.fc(feature, self.num_class, act=None, bias_attr=False, name="output") # 转换形状输出即可
return feature
2.2.5 GCNII模型代码讲解
#新网络模型学习——GCNII
class GCNII(object):
"""Implement of GCNII"""
def __init__(self, config, num_class):
self.num_class = num_class # 类别数
self.num_layers = config.get("num_layers", 1) # 层数
self.hidden_size = config.get("hidden_size", 64) # 中间层输出大小--不一定只有一层中间层哈--跟num_layers有关
self.dropout = config.get("dropout", 0.6) # drop率——既是fc的,也是GCNII的drop
self.alpha = config.get("alpha", 0.1) # alpha值——论文中的超参数
self.lambda_l = config.get("lambda_l", 0.5) # labda_l值——论文中的超参数
self.k_hop = config.get("k_hop", 64) # 传播次数
self.edge_dropout = config.get("edge_dropout", 0.0) # 边drop率
def forward(self, graph_wrapper, feature, phase):
'''
graph_wrapper: 一个图容器,用于存储图信息,并可以迭代训练与预测
feature:图的节点特征
phase:指令--train or eval or test等
功能:
首先根据运行模式,确定edge_drop率
然后进入循环遍历叠加网络层,这里不同于之前的网络---这里叠加的是fc层和drop操作--先fc,再drop
GCNII仅仅一个--并且由于GCNII层无法改变中间层大小,所以计算后要把对应的feature转换为跟num_class相关的大小--又要再次利用fc来完成
根据相应的处理得到需要的预测结果。
如:softmax进行一个类别处理,利用argmax的到分类的类别 【具体过程详见build_model.py】
'''
if phase == "train": # 训练模式才会进行边drop
edge_dropout = self.edge_dropout
else:
edge_dropout = 0
# GCNII也比较特殊,这里的num_layers层数指的是前层网络fc的深度,而不是直接叠加GCNII层
for i in range(self.num_layers):
feature = L.fc(feature, self.hidden_size, act="relu", name="lin%s" % i) # 跟APPNP相比--GCNII先经过fc再通过dropout
feature = L.dropout(
feature,
self.dropout,
dropout_implementation='upscale_in_train') # 训练时drop,否则不drop
# GCNII这个layer的返回值:张量shape: (num_nodes, hidden_size)
# GCNII也不能改变特征输出的大小
feature = conv.gcnii(graph_wrapper, # 图容器
feature=feature, # 特征数据
name="gcnii", # named
activation="relu", # 激活函数
lambda_l=self.lambda_l, # 论文中的超参数--用于内部公式计算
alpha=self.alpha, # 论文中的超参数
dropout=self.dropout, # drop率
k_hop=self.k_hop) # 传播次数
feature = L.fc(feature, self.num_class, act=None, name="output") # 再经过fc获得指定大小的输出
return feature
2.3 build_model.py的内容解析——可以学习的重点
这样的方式搭建加载模型和算子,能使后边的工作轻松不少,值得学习哦!
import pgl
import model
from pgl import data_loader
import paddle.fluid as fluid
import numpy as np
import time
'''build_model整个流程的说明:
1. 首先明确传入参数(dataset, config, phase, main_prog)
1. dataset: 一个简单的图
2. config: 配置参数
1. 包括模型名称,以及相关的初始化参数--根据自己的模型配置就好
3. phase: 工作指令--train-训练模式,其它为非训练模式
2. 主要工作流程
1. 首先将传入的图放入一个图容器,此时传入图和节点特征即可
2. 利用python自带的getattr读取model.py中的类,并返回这个类
3. 利用返回的类实例一个模型
这后边就涉及静态的参数创建了:
4. 将图容器传入以及其它对于模型的forward必须的参数--得到一个返回值--logits,这个输出信息用于预测等 -- logits是经过模型层返回的,也是一个data
5. 创建一些训练和预测所必须的参数--node_index: 节点索引集【需回到notebook中对照理解】;node_label,用于计算acc,loss等
【注意,这里涉及到模型返回的参数也好,其它的loss以及node_index、node_label都是一个静态图下的data,要通过build_model返回之后,经过执行器运行时才会有实际的值】
6. 接着创建loss方法以及返回loss_data----以及添加acc方法,计算acc_data
7. 添加一个softmax获取实际类别
8. 接着平均化损失
9. 如果是训练模式,还会单独添加优化器,返回优化器对象,并优化参数
**: 切记,这里使用方法创建的变量都是静态图中的data,需要放入执行器中运行才有实际的意义
'''
def build_model(dataset, config, phase, main_prog):
'''
dataset: 就是一个图
config: 来自以下代码
from easydict import EasyDict as edict
config =
"model_name": "APPNP",
"num_layers": 3,
"dropout": 0.5,
"learning_rate": 0.0002,
"weight_decay": 0.0005,
"edge_dropout": 0.00,
config = edict(config)
main_prog:执行器对象(program)
'''
gw = pgl.graph_wrapper.GraphWrapper(
name="graph",
node_feat=dataset.graph.node_feat_info()) # 创建图容器
GraphModel = getattr(model, config.model_name) # 获取model中关于config.model_name指定的模型配置--即在model.py中,getattr获取的对象属性就是相应的模型类
m = GraphModel(config=config, num_class=dataset.num_classes) # 利用返回的模型类,实例一个对象--传入配置信息,以及节点类别数(用于预测分类)
logits = m.forward(gw, gw.node_feat["feat"], phase) # 调用模型对象,进行前向计算--传入图,节点特征,执行指令--phase为train或者false
# 补充说明:m.forward得到的是一个shape为[batch, num_class]的序列--后边用于softmax处理再进行类别获取
# Take the last
# 创建节点data
node_index = fluid.layers.data(
"node_index",
shape=[None, 1],
dtype="int64",
append_batch_size=False)
# 创建节点标签data
node_label = fluid.layers.data(
"node_label",
shape=[None, 1], # 【batch,1】
dtype="int64",
append_batch_size=False)
# 根据索引 node_index 获取输入logits的最外层维度的条目,并将它们拼接在一起
# 即: eg: node_index=[1, 2], logits=[[1, 2], [2, 3], [3, 4]]
# 那么拼接的对象就是——[1, 2], [2, 3], [3, 4]
# 然后根据node_index索引拼接,选择[2, 3], [3, 4]进行拼接,然后维数不变的返回[[2, 3], [3, 4]]
pred = fluid.layers.gather(logits, node_index) # node_index是一个data,暂时是不作用的,要等exe执行器运行时才会传入信息---这里最后作用的结果就是根据index索引相应的值
loss, pred = fluid.layers.softmax_with_cross_entropy(
logits=pred, label=node_label, return_softmax=True) # 输入pred, 与node_label,进行交叉熵计算--并返回通过sortmax的pred数据和loss
acc = fluid.layers.accuracy(input=pred, label=node_label, k=1) # 准确率计算
pred = fluid.layers.argmax(pred, -1) # 利用argmax确定具体的类别
loss = fluid.layers.mean(loss) # 计算平均损失
if phase == "train": # 训练模式才进行优化
# Adam优化器:利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率
adam = fluid.optimizer.Adam(
learning_rate=config.learning_rate, # 学习率
regularization=fluid.regularizer.L2DecayRegularizer( # L2权重衰减正则化
regularization_coeff=config.weight_decay)) # 正则化系数--就是我们在notbook中config设置的weight_decay
adam.minimize(loss) # 通过minimize获取实际损失--即loss_all / batchsize
return gw, loss, acc, pred # 返回训练后的图、损失、精度、预测data
3.Res_Unimp_Large算法实现
#导入相关包
!pip install --upgrade python-dateutil
!pip install easydict
!pip install pgl==1.2.1
!pip install pandas>=0.25
# !pip install pyarrow==0.13.0
!pip install chardet==3.0.4
import sys
import pgl
import paddle.fluid as fluid
import numpy as np
import time
import pandas as pd
3.1图网络配置
这里已经有很多强大的模型配置了,你可以尝试简单的改一下config的字段。
例如,换成GAT的配置
config =
"model_name": "GAT",
"num_layers": 1,
"dropout": 0.5,
"learning_rate": 0.01,
"weight_decay": 0.0005,
"edge_dropout": 0.00,
from easydict import EasyDict as edict
config =
"model_name": "res_unimp_large",
"num_layers": 3,
"hidden_size": 64,
"heads": 2,
"learning_rate": 0.001,
"dropout": 0.3,
"weight_decay": 0.0005,
"edge_dropout": 0.3,
"use_label_e": True
config = edict(config)
3.2数据加载模块
这里主要是用于读取数据集,包括读取图数据构图,以及训练集的划分。
from collections import namedtuple
Dataset = namedtuple("Dataset",
["graph", "num_classes", "train_index",
"train_label", "valid_index", "valid_label", "test_index"])
def load_edges(num_nodes, self_loop=True, add_inverse_edge=True):
# 从数据中读取边
edges = pd.read_csv("work/edges.csv", header=None, names=["src", "dst"]).values
if add_inverse_edge:
edges = np.vstack([edges, edges[:, ::-1]])
if self_loop:
src = np.arange(0, num_nodes)
dst = np.arange(0, num_nodes)
self_loop = np.vstack([src, dst]).T
edges = np.vstack([edges, self_loop])
return edges
def load():
# 从数据中读取点特征和边,以及数据划分
node_feat = np.load("work/feat.npy")
num_nodes = node_feat.shape[0]
edges = load_edges(num_nodes=num_nodes, self_loop=True, add_inverse_edge=True)
graph = pgl.graph.Graph(num_nodes=num_nodes, edges=edges, node_feat="feat": node_feat)
indegree = graph.indegree()
norm = np.maximum(indegree.astype("float32"), 1)
norm = np.power(norm, -0.5)
graph.node_feat["norm"] = np.expand_dims(norm, -1)
df = pd.read_csv("work/train.csv")
# 打乱顺序
df.sample(frac=1.0)
node_index = df["nid"].values
node_label = df["label"].values
train_part = int(len(node_index) * 0.8)
train_index = node_index[:train_part]
train_label = node_label[:train_part]
valid_index = node_index[train_part:]
valid_label = node_label[train_part:]
test_index = pd.read_csv("work/test.csv")["nid"].values
dataset = Dataset(graph=graph,
train_label=train_label,
train_index=train_index,
valid_index=valid_index,
valid_label=valid_label,
test_index=test_index, num_classes=35)
return dataset
dataset = load()
train_index = dataset.train_index
train_label = np.reshape(dataset.train_label, [-1 , 1])
train_index = np.expand_dims(train_index, -1)
val_index = dataset.valid_index
val_label = np.reshape(dataset.valid_label, [-1, 1])
val_index = np.expand_dims(val_index, -1)
test_index = dataset.test_index
test_index = np.expand_dims(test_index, -1)
test_label = np.zeros((len(test_index), 1), dtype="int64")
3.3 组网模块
这里是组网模块,目前已经提供了一些预定义的模型,包括GCN, GAT, APPNP等。可以通过简单的配置,设定模型的层数,hidden_size等。你也可以深入到model.py里面,去奇思妙想,写自己的图神经网络。
import pgl
import model
import paddle.fluid as fluid
import numpy as np
import time
from build_model import build_model
import paddle
# # 使用CPU
# place = fluid.CPUPlace()
# 使用GPU
place = fluid.CUDAPlace(0)
train_program = fluid.default_main_program()
startup_program = fluid.default_startup_program()
with fluid.program_guard(train_program, startup_program):
with fluid.unique_name.guard():
gw, loss, acc, pred = build_model(dataset,
config=config,
phase="train",
main_prog=train_program)
test_program = fluid.Program()
with fluid.program_guard(test_program, startup_program):
with fluid.unique_name.guard():
_gw, v_loss, v_acc, v_pred = build_model(dataset,
config=config,
phase="test",
main_prog=test_program)
test_program = test_program.clone(for_test=True)
exe = fluid.Executor(place)
3.4 开始训练过程
图神经网络采用FullBatch的训练方式,每一步训练就会把所有整张图训练样本全部训练一遍。
import os
use_label_e = True
label_rate = 0.625
epoch = 1000
exe.run(startup_program)
max_val_acc = 0
# 这里可以恢复训练
pretrained = False
if pretrained:
def name_filter(var):
res = var.name in os.listdir('./output')
return res
fluid.io.load_vars(exe, './output',predicate=name_filter)
max_val_acc = 0.756
earlystop = 0
# 将图数据变成 feed_dict 用于传入Paddle Excecutor
feed_dict = gw.to_feed(dataset.graph)
for epoch in range(epoch):
# Full Batch 训练
# 设定图上面那些节点要获取
# node_index: 未知label节点的nid
# node_label: 未知label
# label_idx: 已知label节点的nid
# label: 已知label
if use_label_e:
# 在训练集中抽取部分数据,其Label已知,并可以输入网络训练
train_idx_temp = np.array(train_index, dtype="int64")
train_lab_temp = np.array(train_label, dtype="int64")
state = np.random.get_state()
np.random.shuffle(train_idx_temp)
np.random.set_state(state)
np.random.shuffle(train_lab_temp)
label_idx=train_idx_temp[:int(label_rate*len(train_idx_temp))]
unlabel_idx=train_idx_temp[int(label_rate*len(train_idx_temp)):]
label=train_lab_temp[:int(label_rate*len(train_idx_temp))]
unlabel=train_lab_temp[int(label_rate*len(train_idx_temp)):]
feed_dict["node_index"] = unlabel_idx
feed_dict["node_label"] = unlabel
feed_dict['label_idx']= label_idx
feed_dict['label']= label
else:
feed_dict["node_label"] = np.array(train_label, dtype="int64")
feed_dict["node_index"] = np.array(train_index, dtype="int64")
train_loss, train_acc = exe.run(train_program,
feed=feed_dict,
fetch_list=[loss, acc],
return_numpy=True)
# Full Batch 验证
# 设定图上面那些节点要获取
# node_index: 未知label节点的nid
# node_label: 未知label
# label_idx: 已知label节点的nid
# label: 已知label
feed_dict["node_index"] = np.array(val_index, dtype="int64")
feed_dict["node_label"] = np.array(val_label, dtype="int64")
if use_label_e:
feed_dict['label_idx'] = np.array(train_index, dtype="int64")
feed_dict['label'] = np.array(train_label, dtype="int64")
val_loss, val_acc = exe.run(test_program,
feed=feed_dict,
fetch_list=[v_loss, v_acc],
return_numpy=True)
print("Epoch", epoch, "Train Acc", train_acc[0], "Valid Acc", val_acc[0])
# 保存历史最优验证精度对应的模型
if val_acc[0] > max_val_acc:
max_val_acc = val_acc[0]
print(val_acc[0])
fluid.io.save_persistables(exe, './output', train_program)
# 训练精度持续大于验证精度,结束训练
if train_acc[0] > val_acc[0]:
earlystop += 1
if earlystop == 40:
break
else:
earlystop = 0
部分结果展示:
Epoch 987 Train Acc 0.7554459 Valid Acc 0.7546095
Epoch 988 Train Acc 0.7537374 Valid Acc 0.75717235
Epoch 989 Train Acc 0.75497127 Valid Acc 0.7573859
Epoch 990 Train Acc 0.7611409 Valid Acc 0.75653166
Epoch 991 Train Acc 0.75316787 Valid Acc 0.75489426
Epoch 992 Train Acc 0.749561 Valid Acc 0.7547519
Epoch 993 Train Acc 0.7571544 Valid Acc 0.7551079
Epoch 994 Train Acc 0.7516492 Valid Acc 0.75581974
Epoch 995 Train Acc 0.7563476 Valid Acc 0.7563181
Epoch 996 Train Acc 0.7504627 Valid Acc 0.7538976
Epoch 997 Train Acc 0.7476152 Valid Acc 0.75439596
Epoch 998 Train Acc 0.7539272 Valid Acc 0.7528298
Epoch 999 Train Acc 0.7532153 Valid Acc 0.75396883
3.5对测试集进行预测-生成提交文件
训练完成后,我们对测试集进行预测。预测的时候,由于不知道测试集合的标签,我们随意给一些测试label。最终我们获得测试数据的预测结果。
feed_dict["node_index"] = np.array(test_index, dtype="int64")
feed_dict["node_label"] = np.array(test_label, dtype="int64") #假标签
test_prediction = exe.run(test_program,
feed=feed_dict,
fetch_list=[v_pred],
return_numpy=True)[0]
submission = pd.DataFrame(data=
"nid": test_index.reshape(-1),
"label": test_prediction.reshape(-1)
)
submission.to_csv("submission.csv", index=False)
4.方案优化
主要改进思路嘛是在对预测结果进行简单投票和绝对多数投票下了点功夫,我只用了10个预测样本进行融合,预测的样本更多的话,提交结果的分数可能也越高,具体流程如下图所示。
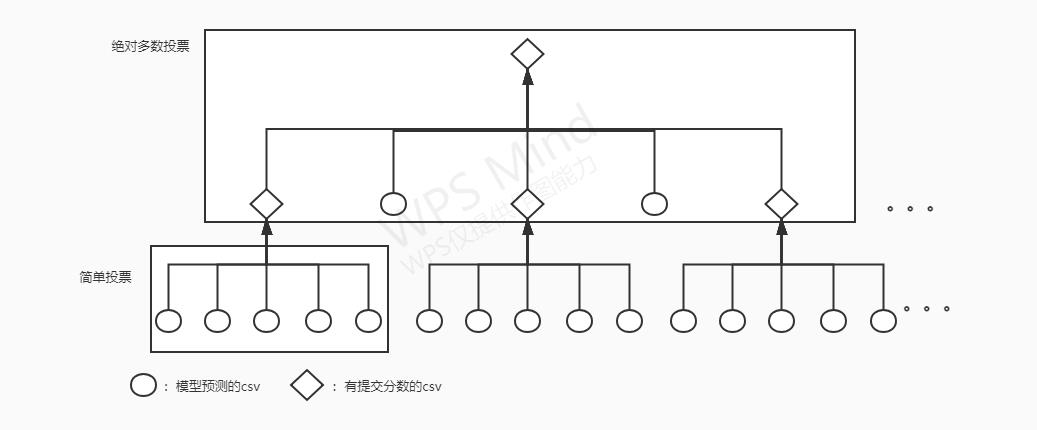
注意图中简单投票和绝对多数投票的样本是任意数目
优秀方案参考:
创新点:
1.对node_feat进行循环处理;
2.增加标签节点
https://aistudio.baidu.com/aistudio/projectdetail/1626857
https://aistudio.baidu.com/aistudio/projectdetail/1642136
https://aistudio.baidu.com/aistudio/projectdetail/2148792
4.2 简单投票(本地)
这里将训练出来的文件进行简单投票
import csv
from collections import Counter
def vote_merge(filelst):
result =
fw = open('D:/subexl/76/merge.csv', encoding='utf-8', mode='w', newline='')
csv_writer = csv.writer(fw)
csv_writer.writerow(['nid', 'label'])
for filepath in filelst:
cr = open(filepath, encoding='utf-8', mode='r')
csv_reader = csv.reader(cr)
for i, row in enumerate(csv_reader):
if i == 0:
continue
idx, cls = row
if idx not in result:
result[idx] = []
result[idx].append(cls)
for nid, clss in result.items():
counter = Counter(clss)
true_cls = counter.most_common(1)
csv_writer.writerow([nid, true_cls[0][0]])
if __name__ == '__main__':
vote_merge([
# "D:/subexl/75/0.76436.csv",
# "D:/subexl/75/0.7635.csv",
# "D:/subexl/75/0.75666.csv",
# "D:/subexl/75/0.75736.csv",
# "D:/subexl/75/0.75755.csv",
# "D:/subexl/75/0.75801.csv",
# "D:/subexl/75/0.75868.csv",
# "D:/subexl/75/0.75978.csv",
# "D:/subexl/75/0.76171.csv",
# "D:/subexl/75/0.76288.csv",
# "D:/subexl/75/0.76412.csv",
# "D:/subexl/75/0.759664.csv",
# "D:/subexl/75/0.75973517.csv",
# "D:/subexl/75/0.75980633.csv",
# "D:/subexl/75/0.76322347.csv",
# "D:/subexl/75/0.763223471.csv",
"D:/subexl/76/0.75736.csv",
"D:/subexl/76/0.75755.csv",
"D:/subexl/76/0.75801.csv",
"D:/subexl/76/0.75868.csv",
"D:/subexl/76/0.75978.csv",
"D:/subexl/76/0.76436.csv",
"D:/subexl/76/0.759664.csv",
"D:/subexl/76/0.75973517.csv",
"D:/subexl/76/0.75980633.csv",
"D:/subexl/76/0.76322347.csv",
"D:/subexl/76/0.763223471.csv",
"D:/subexl/76/submission.csv",
])
4.3 绝对多数投票(本地)
绝对多数投票法很简单,分类器的投票数超过半数便认可预测结果,否则拒绝。将简单投票后的结果再与新训练出来的文件进行绝对多数投票。
在这里,我将所有提交文件的名称改为“测试精度.csv”,例如0.76087.csv;然后按照精度大小排序,首先使用绝对多数投票法进行投票,若某一投票不过半数,直接取精度最高csv的预测结果。
import os
import numpy as np
from scipy import stats
import pandas as pd
#path放的是你以上是关于PGL图学习之基于UniMP算法的论文引用网络节点分类任务[系列九]的主要内容,如果未能解决你的问题,请参考以下文章
PGL图学习之图神经网络ERNIESageUniMP进阶模型[系列八]
PGL图学习之图神经网络ERNIESageUniMP进阶模型[系列八]