shell三剑客-awk总结-基础
Posted EbowTang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了shell三剑客-awk总结-基础相关的知识,希望对你有一定的参考价值。
说明:
1,本文反复阅读、参考和总结自《AWK程序设计语言》第一章节,且对原文语句进行了不少精炼
2,目的为熟练使用awk或者有朝一日快速捡起awk的使用方法
3,本文所有原件获取方式:阿里云盘下载链接保留本文所有涉及总结源文件和文档「awk」https://www.aliyundrive.com/s/7gow7qwJnZ3
awk快速一纸通
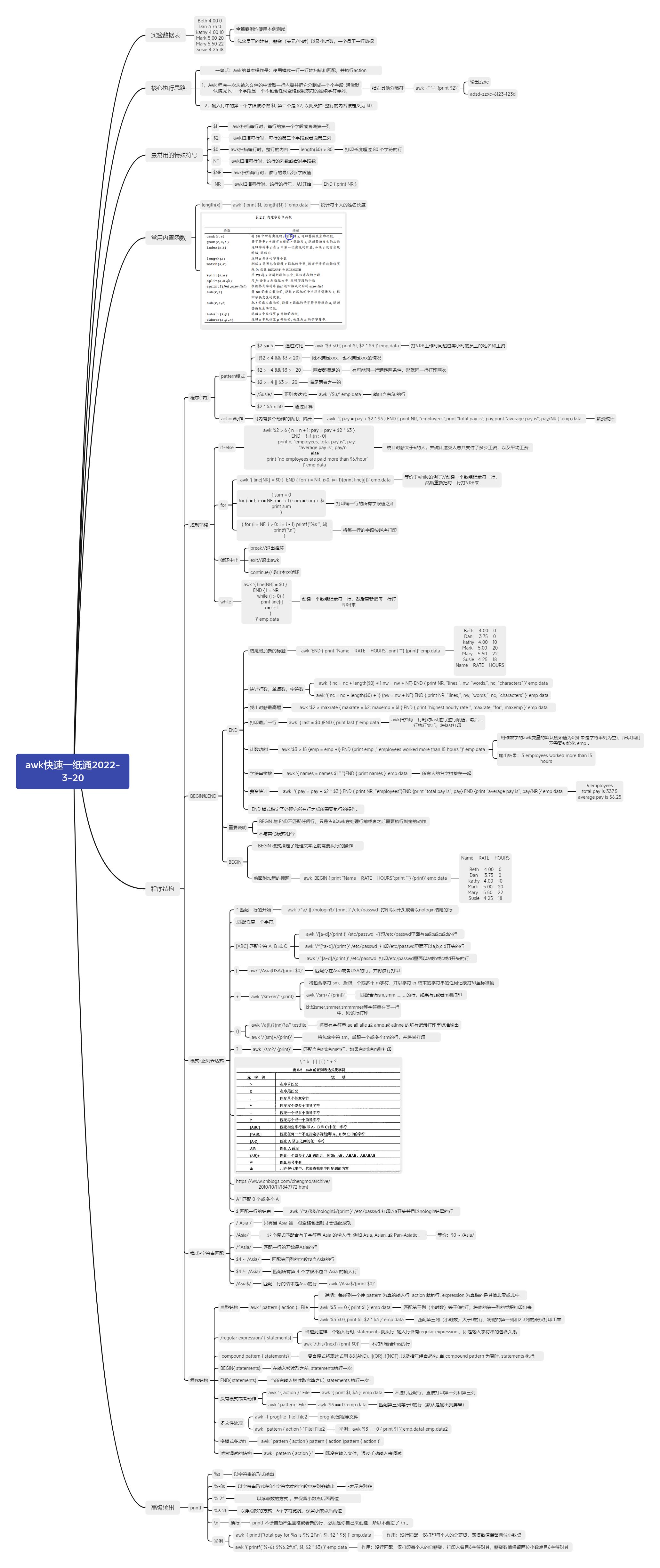
目录
一. AWK指南
1 起步
有用的awk程序往往很简短,仅仅一两行。假设有一个名为 emp.data 的文件,其中包含员工的姓名、薪资(美元/小时)以及小时数,一个员工一行数据,如下所示:
| Beth | 4.00 | 0 |
| Dan | 3.75 | 0 |
| kathy | 4.00 | 10 |
| Mark | 5.00 | 20 |
| Mary | 5.50 | 22 |
| Susie | 4.25 | 18 |
1.1 简单示例1:
现在打印出工作时间超过零小时的员工的姓名和工资(薪资乘以时间),输入这个命令行就可以了:
awk '$3 >0 print $1, $2 * $3 ' emp.data
会得到如下输出:
Kathy 40
Mark 100
Mary 121
Susie 76.5
该命令行告诉系统执行引号内的awk程序,从输入文件emp.data 获取程序所需的数据。引号内的部分是个完整的awk程序,包含单个模式-动作语句。
模式: $3>0 用于匹配每行第三列大于0的输入行,
动作: 打印每个匹配行的第一个字段以及第二第三字段的乘积。
1.2 简单示例2:
如果想打印出还没工作过的员工的姓名,则输入命令行::
awk '$3 == 0 print $1 ' emp.data
模式:$3 == 0 匹配每行第三个字段等于0的行,
动作: 打印该行的第一个字段。
1.3 程序结构
上述的两个示例命令行中,引号之间的部分是awk编程语言写的程序,即程序就是有模式和动作组成(可以只有其中一个)。本章中的每个awk程序都是一个或多个模式-动作语句的序列,实际上awk的结构灵活,可以是:
Awk ‘pattern action ’#标准的awk形式
Awk ‘ action ’ #没有模式的动作
Awk ‘pattern action pattern action …’
Awk ‘pattern || pattern action …’
Awk ‘pattern && pattern action;action …’
Awk ‘pattern action ’Flie1 File2 #标准的awk形式执行多个file
Awk ‘pattern,pattern action ’#匹配两个模式
- 由于模式和动作两者任一都是可选的,所以需要使用大括号包围动作以区分模式, 命令行中的程序是用单引号包围着的。这会防止shell解释程序中$这样的字符,也允许程序的长度超过一行。
- 当程序较长,涉及多行时,将程序写到一个单独的文件中会更加方便。假设存在程序 progfile ,输入命令行:
- Pattern与pattern之间用,隔开的话表示分别匹配两个pattern
- Action与action需要使用;隔开
awk -f progfile optional list of input files
其中-f选项指示awk从指定文件中获取程序。可以使用任意文件名替换progfile
1.4 执行程序
awk的基本操作是一行一行地扫描输入,通过模式匹配每行并且按照action执行预期目的。
- 词语“匹配”的准确意义是视具体的模式而言,对于模式 $3 >0 来说,意思是“条件为真”。
- 每个模式依次测试每个输入行。对于匹配到行的模式,其对应的动作(也许包含多步)得到执行,然后读取下一行并继续匹配,直到所有的输入读取完毕。
执行awk程序的方式有多种。可以执行多个文件,可以输入:
awk '$3 == 0 print $1 ' file1 file2
打印file1和file2文件中第三个字段为0的每一行的第一个字段。
你可以省略命令行中的输入文件,仅输入:
awk ‘pattern action ’
这种情况下,awk会将program应用于你在终端中接着输入的任意数据行,直到你输入一个文件结束信号(Unix系统上为ctrl+d)。如下是Unix系统的一个会话示例:
$ awk ‘$3 == 0 print $1 ’
Beth 4.00 0
Beth
Dan 3.75 0
Dan
Kathy 3.75 10
Kathy 3.75 0
Kathy
...加粗的字符是计算机打印的。
这个动作非常便于调试awk:输入awk程序,然后输入数据,观察发生了什么。
1.5 错误诊断
如果awk程序存在错误,awk会给诊断信息。例如,如果打错了大括号,如下所示::
awk '$3 == 0 [ print $1 ' emp.data
会得到如下信息:
awk: syntax error at source line 1
context is
$3 == 0 >>> [ <<<
extra
missing ]
awk: bailing out at source line 1
“Syntax error”意味着在 >>> <<< 标记的地方检测到语法错误。
“Bailing out”意味着没有试图恢复。有时你会得到更多的帮助-关于错误是什么,比如大括号或括弧不匹配。因为存在句法错误,awk就不会尝试执行这个程序。然而,有些错误,直到你的程序被执行才会检测出来。例如,如果你试图用零去除某个数,awk会在这个除法的地方停止处理并报告输入行的行号以及在程序中的行号
2 简单输出print
Awk 程序一次从输入文件的中读取一行内容并把它分割成一个个字段, 通常默认情况下, 一个字段是一个不包含任何空格或制表符的连续字符序列. 输入行中的第一个字段被称做$1,第二个是$2, 以此类推.整行的内容被定义为$0.每一行的字段数量可以不同.通常, 我们要做的仅仅只是打印出每一行中的某些字段, 也许还要做一些计算. 这一节的程序基本上都是这种形式.
2.1 内建符号$0
$0该行整段内容
打印满足条件的每一行,由于 $0 表示整行,下列就表示打印第三字段大于0的所有行
awk '$3 >0 print $0 ' emp.data
也会做一样的事情.
打印特定字段
使用一个 print 语句可以在同一行中输出不止一个字段. 下面的程序输出了每行输入中的第一和第三个字段
Awk ‘ print $1, $3 ’ emp.data
使用 emp.data 作为输入, 它将会得到
Beth 0
Dan 0
Kathy 10
Mark 20
Mary 22
Susie 18
在 print 语句中被逗号分割的表达式, 在默认情况下他们将会用一个空格分割来输出. 每一行 print 生成的内容都会以一个换行符作为结束. 但这些默认行为都可以自定义; 我们将在第二章中介绍具体的方法.
2.2 内建符号NF, $NF
NF该行字段数量,$NF该行最后一个字段值
很显然你可能会发现你总是需要通过$1,$2 这样来指定不同的字段,但任何表达式都可以使用在$之后来表达一个字段的序号;表达式会被求值并用于表示字段序号.Awk会对当前输入的行有多少个字段进行计数,并且将当前行的字段数量存储在一个内建的称作NF的变量中. 因此下面的程序
print NF, $1, $NF
会依次打印出每一行的字段数量, 第一个字段的值, 该行最后一个字段值.
2.3 内建符号NR
NR,该行行号;$0 该行整行内容
如何让输出看起来更漂亮?打印行号
Awk提供了另一个内建变量,叫做NR, 它会存储当前已经读取了多少行的计数. 我们可以使用 NR 和 $0 给 emp.data 的没一行加上行号:
print NR, $0
打印的输出看起来会是这样:
1 Beth 4.00 0
2 Dan 3.75 0
3 Kathy 4.00 10
4 Mark 5.00 20
5 Mary 5.50 22
6 Susie 4.25 1 8
在输出中添加内容
你当然也可以在字段中间或者计算的值中间打印输出想要的内容:
print "total pay for", $1, "is", $2 * $3
输出
total pay for Beth is 0
total pay for Dan is 0
total pay for Kathy is 40
total pay for Mark is 100
total pay for Mary is 121
total pay for Susie is 76.5
在打印语句中, 双引号内的文字将会在字段和计算的值中插入输出.
3 高级输出printf
print 语句可用于快速而简单的输出。若要严格按照你所想的格式化输出,则需要使用 printf 语句。正如我将在2.4节所见, printf 几乎可以产生任何形式的输出,但在本节中,我们仅展示其部分功能。
3.1 按照格式要求输出
printf 语句的形式如下::
printf(format, value1, value2, ..., valuen)
其中format是字符串格式,在format之后的每个值该如何打印的格式。一个格式必定有%符,后面跟着一些字符,用来控制特定value的格式。第一个格式用于如何打印value1,第二个格式用于说明如何打印value2,... 因此,有多少value要打印,在format中就要有多少个%格式。
这里有个程序使用printf打印每位员工的总薪酬:
printf("total pay for %s is $%.2f\\n", $1, $2 * $3)
printf语句中的格式字符串包含两个%格式。
第一个是%s,说明以字符串的方式打印第一个值$1。
第二个是%.2f,说明以浮点数的方式打印第二个值$2*$3,并保留小数点后面两位。
格式字符串中其他东西,包括美元符号,仅逐字打印。字符串尾部的\\n代表开始新的一行,使得后续输出将从下一行开始。以emp.data为输入,该程序产生:
total pay for Beth is $0.00
total pay for Dan is $0.00
total pay for Kathy is $40.00
total pay for Mark is $100.00
total pay for Mary is $121.00
total pay for Susie is $76.50
printf不会自动产生空格或者换行,必须是你自己来创建,所以不要忘了\\n 。
另一个程序是打印每位员工的姓名与薪酬::
printf("%-8s $%6.2f\\n", $1, $2 * $3)
第一个规格%-8s将一个姓名以字符串形式,8个字符宽度,左对齐输出(-的作用)。
第二个规格%6.2f将薪酬以数字的形式,保留小数点后两位,在6个字符宽度的字段中输出。
Beth $ 0.00
Dan $ 0.00
Kathy $ 40.00
Mark $100.00
Mary $121.00
Susie $ 76.50
3.2 排序输出
假设你想打印每位员工的所有数据,包括他或她的薪酬,并以薪酬递增的方式进行排序输出。最简单的方式是使用awk将每位员工的总薪酬置于其记录之前,然后利用一个排序程序来处理awk的输出。Unix上,命令行如下(未测试成功):
awk ' printf("%6.2f %s\\n", $2 * $3, $0) ' emp.data | sort -n
将awk的输出通过管道传给 sort 命令,输出为:
0.00 Beth 4.00 0
0.00 Dan 3.75 0
40.00 Kathy 4.00 10
76.50 Susie 4.25 18
100.00 Mark 5.00 20
121.00 Mary 5.50 22
4 多样化模式匹配
Awk的模式适合用于为进一步的处理从输入中选择相关的数据行。由于不带动作的模式会打印所有匹配模式的行,所以很多awk程序仅包含一个模式。本节将给出一些有用的模式示例。
4.1 通过对比选择
这个程序使用一个对比模式来选择每小时赚5美元或更多的员工,也就是第二个字段大于等于5的行:
awk '$2 >= 5print $0' emp.data
从 emp.data 中选出这些行::
Mark 5.00 20
Mary 5.50 22
4.2 通过计算选择
awk '$2 * $3 > 50 printf("$%.2f for %s\\n", $2 * $3, $1) ' emp.data
打印出总薪资超过50美元的员工的薪酬。
4.3 通过文本内容选择
除了数值测试,你还可以选择包含特定单词或短语的输入行。这个程序会打印所有第一个字段为 Susie 的行::
$1 == "Susie"
操作符 == 用于测试相等性。你也可以使用称为 正则表达式 的模式查找包含任意字母组合,单词或短语的文本。这个程序打印任意位置包含 Susie 的行::
/Susie/
输出为这一行::
Susie 4.25 18
正则表达式可用于指定复杂的多的模式;2.1节将会有全面的论述。
4.4 模式组合
可以使用括号和逻辑操作符与&&(两个条件都满足),或||(满足其中一个或者两个),以及非!(不满足)对模式进行组合。程序:
$2 >= 4 || $3 >= 20 #两个条件都满足的行只打印一次
会打印 $2 (第二个字段) 大于等于 4 或者 $3 (第三个字段) 大于等于 20 的行::
Beth 4.00 0
kathy 4.00 10
Mark 5.00 20
Mary 5.50 22
Susie 4.25 18
与如下包含两个模式程序相比::
awk '$2 >=4, $3 >= 50print $0' emp.data
如果某个输入行两个条件都满足,这个程序会打印它两遍::
Beth 4.00 0
Kathy 4.00 10
Mark 5.00 20
Mark 5.00 20
Mary 5.50 22
Mary 5.50 22
Susie 4.25 18
注意如下程序:
!($2 < 4 && $3 < 20)
会打印既不满足$2小于4也不满足$3小于20的行;这个条件与上面第一个模式组合等价,虽然也许可读性差了点。
4.5 数据验证
实际的数据中总是会存在错误的。在数据验证-检查数据的值是否合理以及格式是否正确-方面,Awk是个优秀的工具。
数据验证本质上是否定的:不是打印具备期望属性的行,而是打印可疑的行。如下程序使用对比模式 将5个数据合理性测试应用于emp.data的每一行::
NF != 3 print $0, "number of fields is not equal to 3"
$2 < 3.35 print $0, "rate is below minimum wage"
$2 > 10 print $0, "rate exceeds $10 per hour"
$3 < 0 print $0, "negative hours worked"
$3 > 60 print $0, "too many hours worked"
如果没有错误,则没有输出。
4.6 BEGIN与END
特殊模式BEGIN 模式指定了处理文本之前需要执行的操作,END模式指定了处理文本之后需要执行的操作。这个程序使用BEGIN来 以上是关于shell三剑客-awk总结-基础的主要内容,如果未能解决你的问题,请参考以下文章